# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能快速发展的今天,大型基础模型(如GPT、BERT等)已经成为AI应用的核心基石。然而,这些动辄数十亿甚至数万亿参数的模型给开发者带来了巨大的计算资源压力。传统的全参数微调方法不仅需要大量的计算资源,还面临着训练不稳定、容易过拟合等问题。在这样的背景下,低秩适应(Low-Rank Adaptation,简称LoRA)技术应运而生,它通过巧妙的数学设计,实现了高效且灵活的模型适应方案。

本文将深入剖析LoRA技术的核心原理、最新进展及其在实际应用中的关键策略。
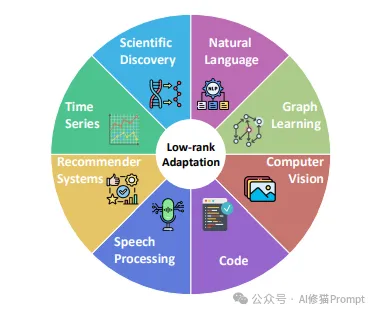
LoRA技术已在人工智能的多个核心领域获得广泛应用。该图采用放射状布局,将"Low-rank Adaptation"置于中心,周围环绕着8个主要应用领域:
这种多领域的广泛应用充分证明了LoRA技术的普适性和实用价值。
LoRA的核心思想是利用矩阵的低秩特性来降低微调过程中的参数量。具体来说,它不直接更新预训练模型的权重矩阵W,而是引入两个低秩矩阵A和B,通过它们的乘积BA来表示权重更新ΔW。这种设计基于一个重要发现:模型在微调过程中的权重更新通常位于一个低维子空间中。通过将原本高维的权重更新压缩到低维空间,LoRA显著减少了需要训练的参数数量,同时保持了模型的表达能力。
例如,对于一个维度为d×k的权重矩阵,传统微调需要更新d×k个参数,而使用秩为r的LoRA只需要更新r×(d+k)个参数,当r远小于min(d,k)时,参数量的减少是显著的。研究表明,在大多数情况下,设置r为4-16就能达到接近全参数微调的效果。
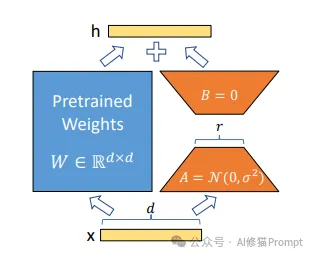
LoRA适配器的核心工作原理可以通过其结构组成清晰地理解:
1.输入输出结构
2.预训练权重模块(左侧蓝色方块)
3.低秩适应模块(右侧组件)
LoRA采用了一系列巧妙的训练策略来确保微调的稳定性和效果:
1.初始化策略:矩阵A通常使用高斯分布初始化,而矩阵B初始化为零矩阵。这样的设计确保了在训练开始时,LoRA的更新不会对模型的原始行为产生影响。
2.缩放因子:引入缩放因子α/r来控制更新的幅度,这个设计使得不同秩的LoRA可以使用相似的学习率,简化了超参数调优的过程。
3.梯度更新:只有低秩矩阵A和B接收梯度更新,原始模型参数保持冻结,这不仅降低了内存占用,还能防止灾难性遗忘。
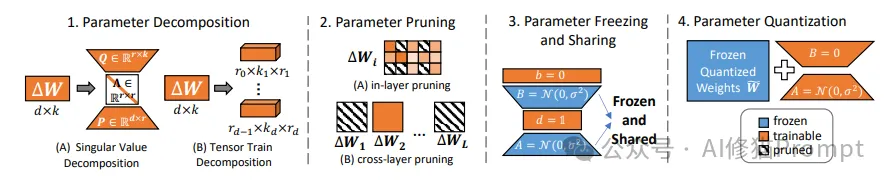
该图展示了四种提升参数效率的核心方法,每种方法都通过独特的可视化方式呈现其工作机制:
1.奇异值分解(图A)
2.张量分解(图B)
1.层内剪枝
2.跨层剪枝
1.冻结策略
2.共享机制
1.量化过程
2.特征说明
这四种方法各具特色,共同构成了LoRA参数效率优化的技术体系:
通过这些方法的组合应用,可以显著提升模型的参数效率,同时保持模型性能。图中的可视化设计帮助读者直观理解每种方法的工作原理和应用方式。
研究者们提出了多种提升LoRA参数效率的方法:
1.参数分解:通过奇异值分解(SVD)或张量分解等技术,进一步压缩LoRA参数。例如,AdaLoRA通过动态调整奇异值的重要性来实现自适应的参数压缩。
2.参数剪枝:基于重要性评分对LoRA参数进行剪枝,如SparseAdapter通过多准则重要性评估来确定需要保留的参数。
3.参数量化:采用混合精度量化策略,如QLoRA使用4比特NormalFloat量化方法,在保持性能的同时进一步降低内存占用。
为了更好地适应不同任务的需求,研究者们开发了多种秩适应机制:
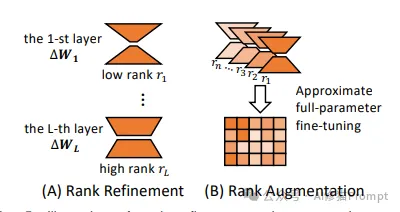
该图展示了两种重要的秩操作方法:秩细化(Rank Refinement)和秩增强(Rank Augmentation),通过可视化方式展现了它们的工作机制:
1.层级结构
2.特征说明
1.结构设计
2.技术特点
1.秩细化策略
2.秩增强机制
这两种方法展示了LoRA在秩操作方面的灵活性:秩细化关注层级化的参数分配,而秩增强则通过组合实现更强的表达能力。图中的几何表示和箭头指示帮助读者理解这些复杂的数学概念和转换过程。

LoRA技术在架构设计上实现了两个重要创新:
1.模块组合方法(左图)
2.专家混合机制(右图)
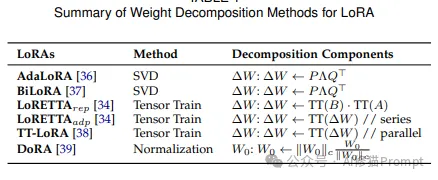
该表格总结了LoRA技术中不同的权重分解方法,展示了该领域的主要技术变体和创新:
1.基于SVD的方法
2.基于张量分解的方法
3.其他创新方法

MoE-LoRA在专家路由策略方面展现了多样化的发展,从简单的软路由发展到复杂的任务导向路由:
1.软路由方法
2.Top-k路由方法
3.任务导向路由
这些路由策略为不同应用场景提供了灵活的解决方案,反映了研究者们在提升模型适应能力和效率方面的创新。
LoRA在持续学习领域展现出独特优势:
1.正交约束:O-LoRA通过确保新任务更新与之前任务正交来防止知识干扰。
2.任务算术:通过对LoRA参数进行向量运算来组合多个任务的知识。
3.集成学习:CoLoR通过维护多个任务特定的LoRA模块并使用原型匹配来实现灵活的任务适应。
在联邦学习场景中,LoRA提供了高效的解决方案:
1.隐私保护:FedIT和FFA-LoRA实现了保护隐私的指令微调框架。
2.异构处理:FedLoRA通过堆叠式聚合方法支持不同秩的适配器across异构客户端。
3.个性化:PER-PCS框架支持用户安全共享和协作组装个性化LoRA模块。
1.秩的选择:
2.学习率设置:
3.层次选择:
1.数据准备:
2.训练策略:
3.内存优化:
LoRA技术的出现彻底改变了AI模型微调的范式,为Prompt工程师提供了一个强大而灵活的工具。通过深入理解LoRA的原理和最佳实践,开发者可以更好地利用这项技术来优化自己的AI应用。随着技术的不断发展和完善,我们有理由相信LoRA将在AI领域发挥越来越重要的作用。本文详细介绍了LoRA的核心技术、最新进展和实践指南,希望能够帮助您更好地理解和应用这项革命性的技术。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
