# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
“美国禁运”、“国产芯片卡脖子”、“硅谷新王英伟达”……2024年上半年的GPU一卡难求。不过上半年囤卡的黄牛不一定在下半年赚到很多钱……随着一众AI创业公司的倒闭,下半年国内其实处在GPU供大于求的状态。
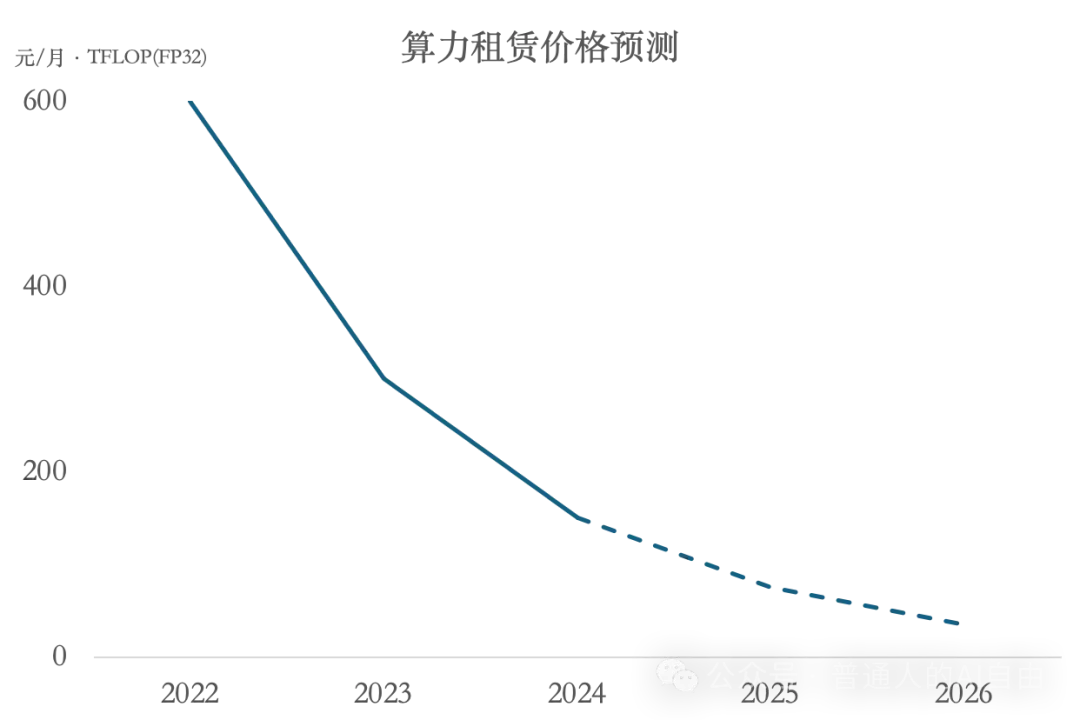
和2023年末相比,2024年末的GPU租赁价格下降了~50%。以8张卡的英伟达H800服务器为例,2023年10月的租赁价格约12到18万元,2024年12月已降至每月8万元以下。而A800价格保持在H800的一半。
以及,美国有“芯片禁令”,我们有“蚂蚁搬家”。其实到目前为止,国内拿到GPU“水货”很容易;不过这种卡没有售后,大公司一般不会冒这个风险。所以最多用这些卡的是做金融量化交易,或者是技术很好(or无知者无畏)的数据中心。
到了2025年,海外模型训练的机器会逐步升级为H200和B200。H200的目前租赁价格为2.2美元/小时,但B200目前整体的生产交付都有推迟,预计会在25年6月大规模投入使用。目前从单位算力成本上来看,H200和H100大约是等价的,都比A100便宜~40%。
GPU集群真正的瓶颈反而是能源。计算需要能源,冷却需要能源。
举个具体例子:马斯克的10万张H100油冷集群xAI Colossus。这10万张卡仅计算就要150MW的电力,加上冷却要200MW以上的峰值电力供应。要知道,其所在地孟菲斯全市的用电峰值仅450MW,电力峰值直接增加1/2显然不现实。因此,在运行之初Colossus仅能从公共电网中获得8MW,后来电网升级到50MW。所以马斯克一直在自己烧天然气发电!加上用Tesla Megapacks储能缓冲电力波动。
其实xAI选址在田纳西州已经很有讲究:这个州的电48%来自核电,12%水电,整体供应充沛,但仍然不够用。田纳西州答应了马斯克未来供给150MW,猜测是核电机组还有提高功率的备份。除此之外,Colossus目前每日需要消耗1百万加仑(约3800吨)冷却水,好在田纳西不缺水。
因此,不少人寄期望的东南亚计算中心大概率不靠谱:当地电网基础设施太弱,以及天气炎热冷却成本过高,因此基本没法建设万卡以上的集群;这也是为什么越来越多人把目光投向了日本……
上面讲的是最受关注的训练算力,模型的另一种算力需求是推理算力。
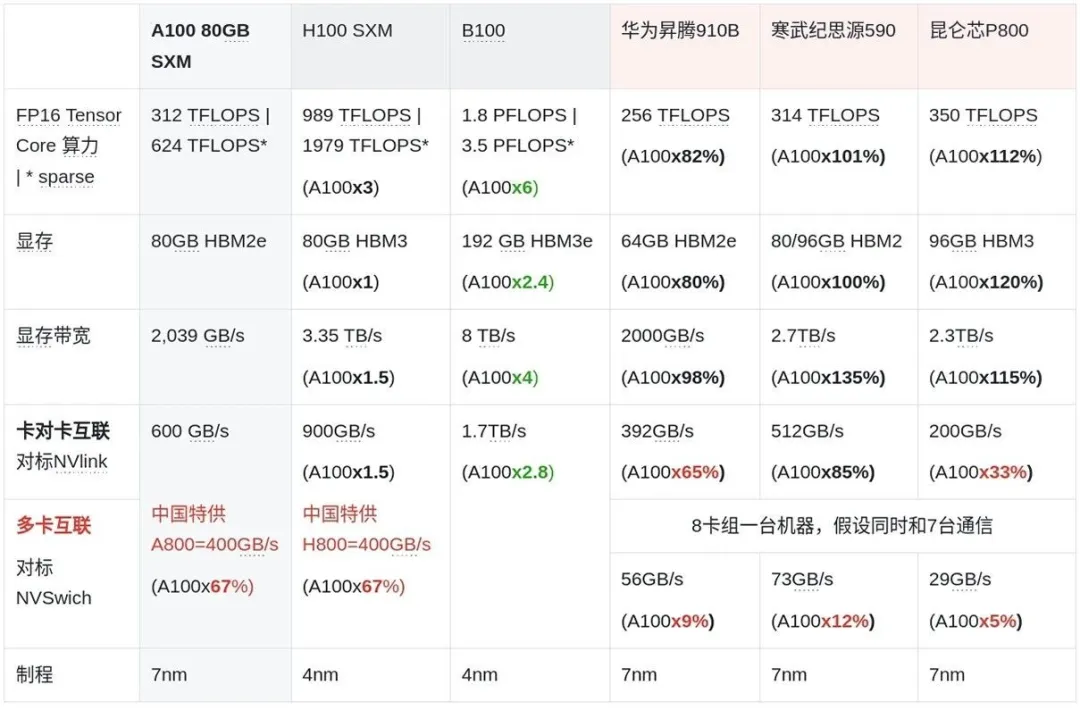
模型推理比训练对算力、内存和带宽的要求都低,国产GPU就够用。虽然目前国内模型推理主流还是用英伟达的L20,L40S,A30,退役的A800等,但国产卡也已经进入大规模商用。
在国产GPU中,华为昇腾的市场占有率市占超过70%。当前华为昇腾中性能最好的910B算力对标A800。此外对标A100的寒武纪590,和对标A800的昆仑星 P800也是受欢迎的推理国产替代。预计在25年国产卡的算力会达到H800水平。
lridescent 3D Brain · Sciencellustration · 2021
国内GPU贵一点其实问题不太大。AI大模型在国内和海外完全是两个市场,国内玩家的起跑线是一样的;所以即使OpenAI更便宜,但也不能在国内用。
影响国内模型迭代速度的是GPU卡间通信带宽。有种理论认为只要卡堆得多就可以做训练,但事实没那么简单;因为主要瓶颈在卡之间的互联,而不在算力的量。没法把卡连起来的话,堆数量是没用的。
我们看到, 专供国内的A800/H800与国际版A100/H100在计算速度上没有差距,区别在于卡间传输速率。因为当模型大到一定程度的时候,一张卡是装不下的;因此在训练过程中,就需要大量的卡间通信。英韦达的NVlink-NVswitch技术就是解决卡间通信问题,实现远比PCIe总线高的带宽。当前H100的NVlink传输速度是900GB/s;与之对比,主流的PCIe4x16的带宽只有64GB/s,而专供国内的A800和H800的传输速度都被限制到了400GB/s,不到H100的一半。
国产用于模型训练的GPU的单卡性能大约落后英伟达3-4年。国产品牌对标NVLink的技术最近的是寒武纪的MLULINK512GB/s。但问题在于,如果一个GPU同时和多个GPU通信会分享这个速度,未直连的GPU之间还需要中转。
国产品牌与英伟达更显著的差距是NVSwitch技术:一个交通枢纽,使得多个GPU之间能保持直接连接的速度。网传寒武纪也在研发MLUSwitch技术对标NVSwitch,快的话可能2025年就能有进展,这也是为什么寒武纪近期股价暴涨的原因。
除了集群性能折损的问题,昇腾集群在训练过程中也出现稳定性问题,如数值溢出导致的训练中断。国产GPU遇到问题时只能找官方技术支持,而几乎无法自己解决。
软件层CUDA的差距其实已经有所缩小,CANN的易用性在不断提升。

Financial Freedom by Catalina Vásquez
1月英韦达发布会最大的亮点:消费级个人算力GB10。
128GB显存,可以运行200B参数模型的推理。而模型的大小基本决定了模型的聪明程度。当前业界普遍认为开源模型的能力根据参数量有门槛:
同时,GB10的算力=1PFLOP-FP4 ,粗略来算是250TFLOP-FP16,算力大约是A100的80%。做模型推理绰绰有余,如果有点耐心,也可以执行非全量精调模型的任务。
于是,GB10实际上是开启了个人离线模型的新时代。一个每个人都可以有为自己服务的离线模型的时代。
3000USD还有些贵,但只要足够“有用”,会有足够的中产为之买单。

最后提一下“世界模型”Cosmos。此“世界模型”非彼“世界模型”。
最后,英伟达开源的模型通常都是为了卖芯片。比如Cosmos之于具身智能,Nemotron-340B之于LLM,都是用在合成数据的场景,只要合成数据的性价比高于获得更多新的真实数据,就不愁有客户为算力买单。

Rainy Nights by Tiago Caetano
英韦达的领先方式:比别人卷得更快
英伟达的节奏是每两年架构大更新,每次更新在性能上(算力&带宽)x2-x3。
预计2025年不会提前发布全新Rubin架构或者新一代NVLink/NVSwitch技术。尽管提前宣布B300,但由于B200生产的推迟,预计B300的交付应该在25年下半年。此外,英伟达还将继续扩大在集群互联上的优势,25年计划中的以太网交换平台Spectrum Ultra X800将支持10万张卡互联。
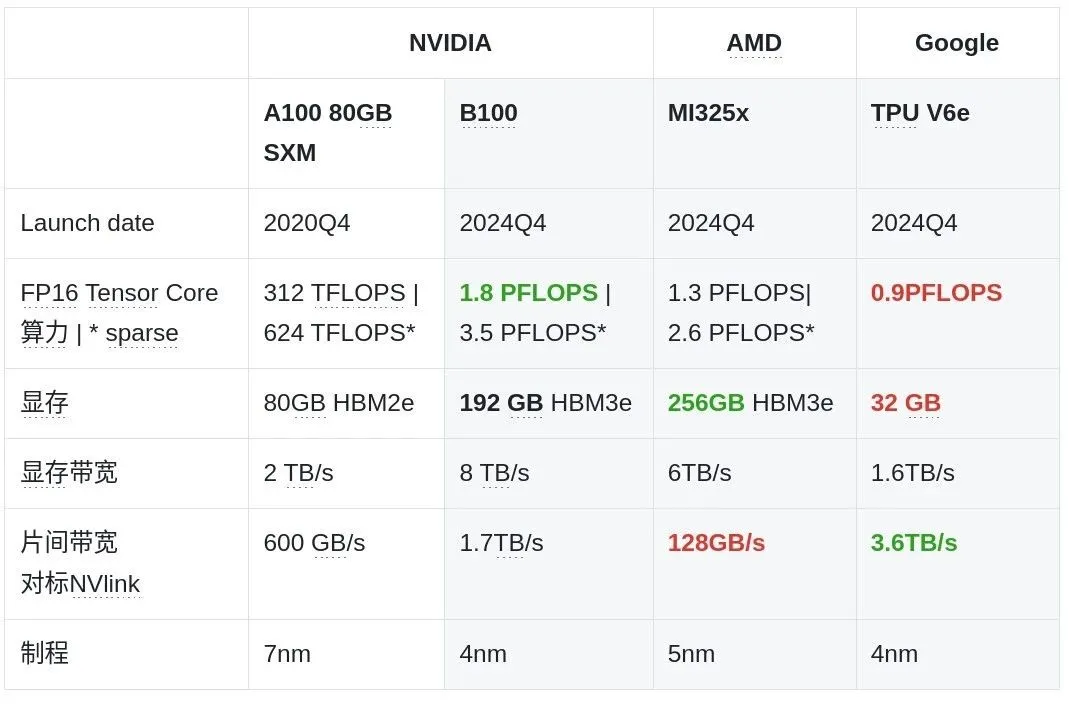
AMD:性能上与英韦达~6个月距离,但生态要弱的多
AMD宣布对标H200的MI325X在24年底投产,预计25年上半年能实现大规模交付。不过在B300推出后,AMD主要的大显存卖点就没有了优势。AMD能卖出多少卡可能取决于B300推出前的窗口期有多长。此外,AMD同时也预告了25年下半年会推出采用CDNA4架构的MI350,推理性能大幅提升35倍,预计会对标Blackwell架构,在25年底投产。
Google TPU: 不同的底层架构&新的可能性
Google最新一代TPU Trillium(V6e)在2024年12月上线。直接和GPU相比,会发现TPU的绝对算力要低一些,而且内存容量和内存带宽不足。但其实没这么简单,TPU的全名叫 Tensor Processing Units, 意思是说专门优化做矩阵乘法计算的,也就是说TPU本身就是为了AI量身打造的,而GPU Graphic Processing Units最开始是为了图像渲染所用。因此,在同等模型训练需求下,TPU其实需要的算力和能耗都更低。所以TPU和GPU在硬件参数上的差距其实比数字更小。此外,TPU在参数上的优势是片间带宽(NVlink的2倍+):TPU更可以把模型分布式部署在不同芯片上,这让大规模模型训练更加有效。
Google的模型是在TPU上训练的,而所有其他公司的模型都是在GPU上训练的。以及我们已经看到,Google的Gemini的能力和其他家大模型并不完全一致(比如当前的视觉理解能力的优势)。所以一个猜测是,基于底层硬件的不同,Google的模型也会有新的可能性。
硅基芯片的量子物理极限几乎已到
制程缩小逼近其物理极限,“X纳米制程”的名称早已名不副实。以当前最先进的“3nm制程”为例,其半导体栅极间的距离Gate Pitch最小在~48nm,而导电金属层间的距离在24-32nm。
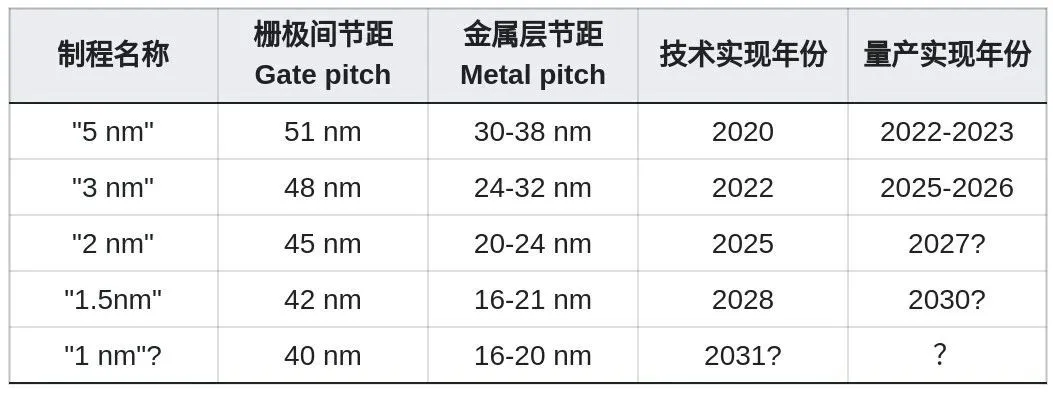
Source: IEEE-IRDS: the international roadmap for devices and systems(2021-2023)
那么,从理论上来讲,制程缩小的物理极限在哪里?
因此,即使仅仅从理论上来讲,硅+铜的组合做到10nm以内已经非常困难。此外,还有金属内部结晶、加工边缘不规则、材料杂质等问题都会让实际的加工极限成倍增加。
光刻机限制。用来切割硅片的刀极紫外光EUV的波长是13.5nm,即使使用各种方式,切割小于波长的结构都几乎不可能,要想再缩小尺寸,必须有新的光刻加工技术。如果要小于15nm,就必须有下一代的光刻机。
于是,从IEEE-IRDS的预测来看,Gate Pitch似乎在可见的未来很难做到35nm以下,而Metal Pitch到了15nm就是极限了。
综上来讲,硅基芯片的物理尺寸极限在~10nm;量产极限15-20nm, 只差半步。
不能更小,那就要在结构上想办法,这也是为什么集成晶体管数量的摩尔定律可以继续。下边的例子便是在3D结构上创新的法。目前各大厂商都在加速部署3D封装技术,如台积电已在AMD MI300的制造中使用了3D封装。
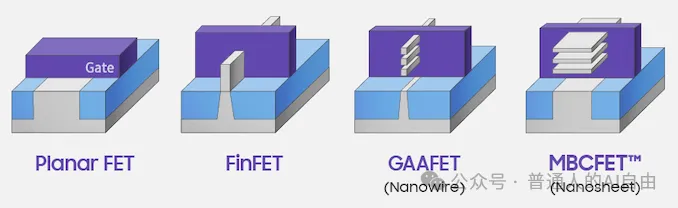
在硅基半导体之外,研究人员也在探索可以构建晶体管的新材料,例如将石墨烯等不同的二维材料堆叠,通过范德华力结合形成异质结,实现晶体管的功能。
如果希望算力有多个量级以上的提升,我们必须跳出硅基半导体。
<路径1>光计算
用光子代替电子作为信息载体,在光学介质中进行模拟或者数字计算。光天然的并行性正适合矩阵计算。如果能够实现全光计算,能带来高带宽和低能耗的优势,解决集群和能耗问题。目前最大的挑战是还没有找到靠谱稳定的光存储材料,光电转换会带来重新带来带宽瓶颈和能量损耗。
<路径2>量子计算
量子计算可以几乎无限打开算力的理论上限。然而从1980年提出量子图灵机到现在已经40多年了,量子计算的进展可以用“缓慢”来形如(和核聚变一样)。理论和工艺困难是一方面,但另一方面更是因为量子计算一直没让投资人看到可以小步快跑的曙光,所以全球研究量子计算的团队一只手可以数出来。
和半导体工业相比,量子计算的总投资额严重不足。
具体到技术上,各种量子计算方案都面临着系统错误积累过多而无法纠正的问题。而上个月google willow的成果似乎让我们看到了一线曙光。
我们未来的文章会做一些“普通人也看的懂的”科普,求关注,求转发。
文章来微信公众号“普通人的AI自由”,作者“Lian et Zian ”



