# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
先说结论:
多数模型,是色盲
人的绝大多数信息,来源于视觉输入。
我们用眼睛去看朝阳,看皎月,看大漠孤烟,看碧海雄关。那么,当我们拍下美景,来和大模型去讨论的时候:大模型看到的,和我们一样吗?
或许,大模型看到的,和我们,并不一样。
于是就有了这个测试:大模型是色盲吗?
做体检的时候,大夫可能会拿出几张图,问你是什么数字,就像下面这种

这是石原氏色盲检测图,由多种颜色的圆点组成多个数字:色觉正常者可以正确区分,而色盲患者则会判断错误。
那么,当我们把这些测试图给到 AI,让他来看看。这里取了两张最经典的:一个是色盲看不出来数字(红绿色盲读错),一个是只有色盲才能看出来数字
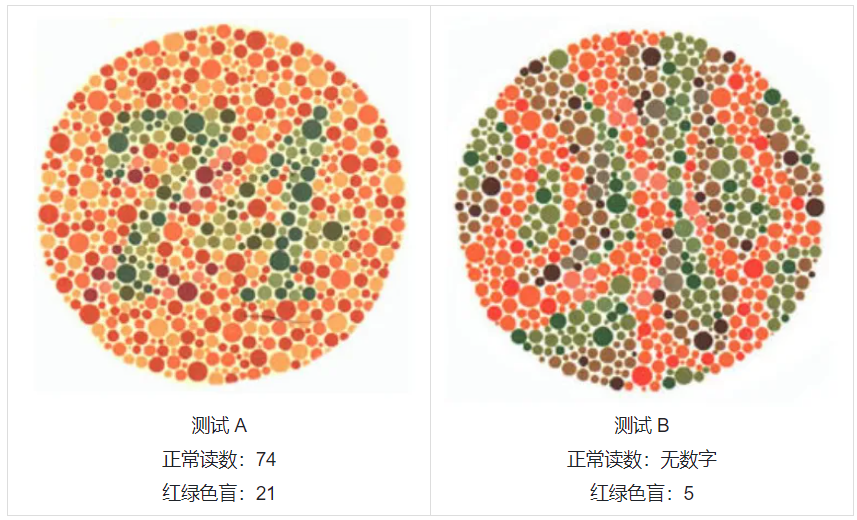
被测试方,选了 4 家:
Prompt 统一使用:图里有数字吗?如果有的话,是什么?

正常读数:74;红绿色盲:21
ChatGPT 的 GPT-4o,回答正确

Claude 的 3.5 Sonnet,有些色盲
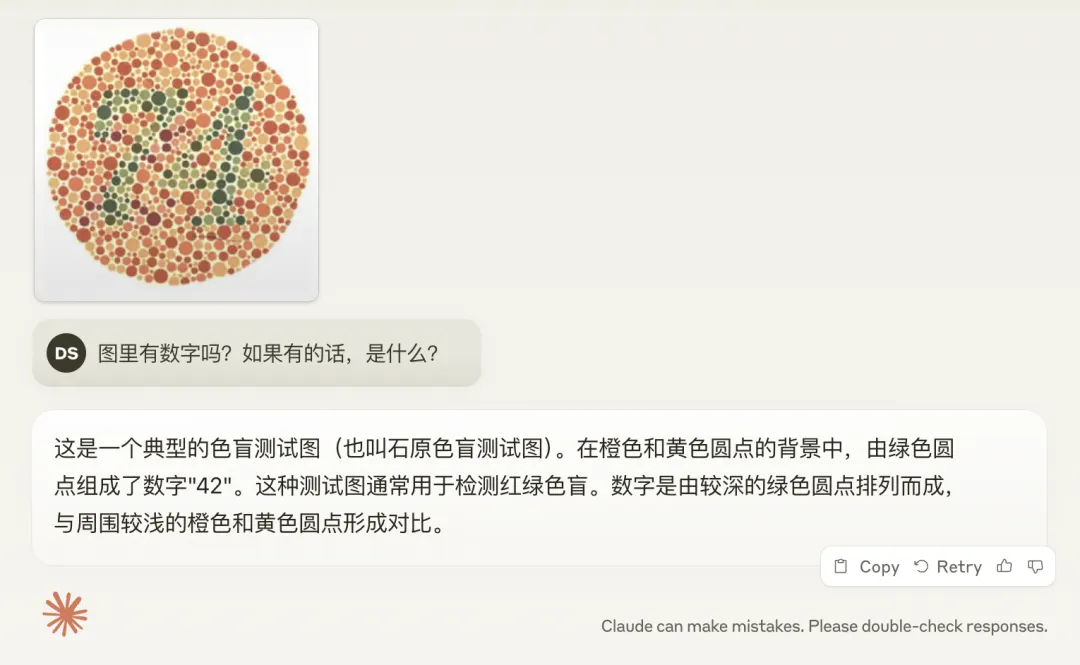
Gemini 的 2.0 (exp-1206),实锤红绿色盲

智谱 的 GLM-4,回答正确

小结:OpenAI 和智谱的模型,在这个测试中,色觉正常。Gemini 是红绿色盲,Claude 不知道是什么色盲

正常读数:无数字;红绿色盲:5
ChatGPT 的 GPT-4o,回答出了一个 5,鉴定为半色盲

Claude 的 3.5 Sonnet,回答出了一个 5,鉴定为半色盲
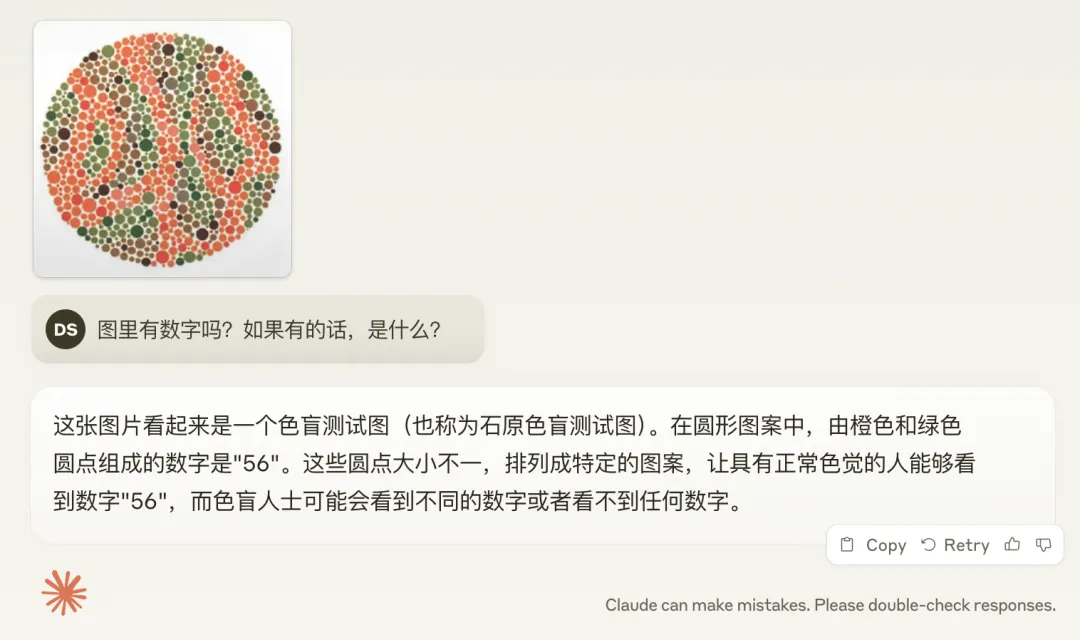
Gemini 的 2.0 (exp-1206),啥也不是
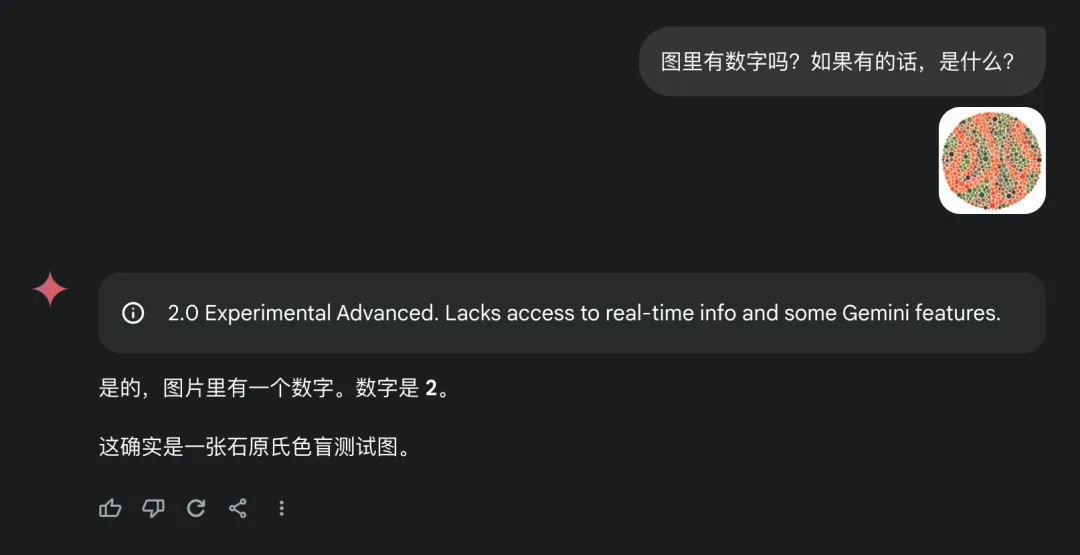
智谱 的 GLM-4,回答正确

小结:在这个测试中,只有 GLM-4 回答正确。
先说结论:基于上面的色盲样本测试,智谱在视觉理解上比大多数模型都强。

难怪获得了白宫恐慌认证:《智谱:关于被美国商务部列入实体清单的声明》
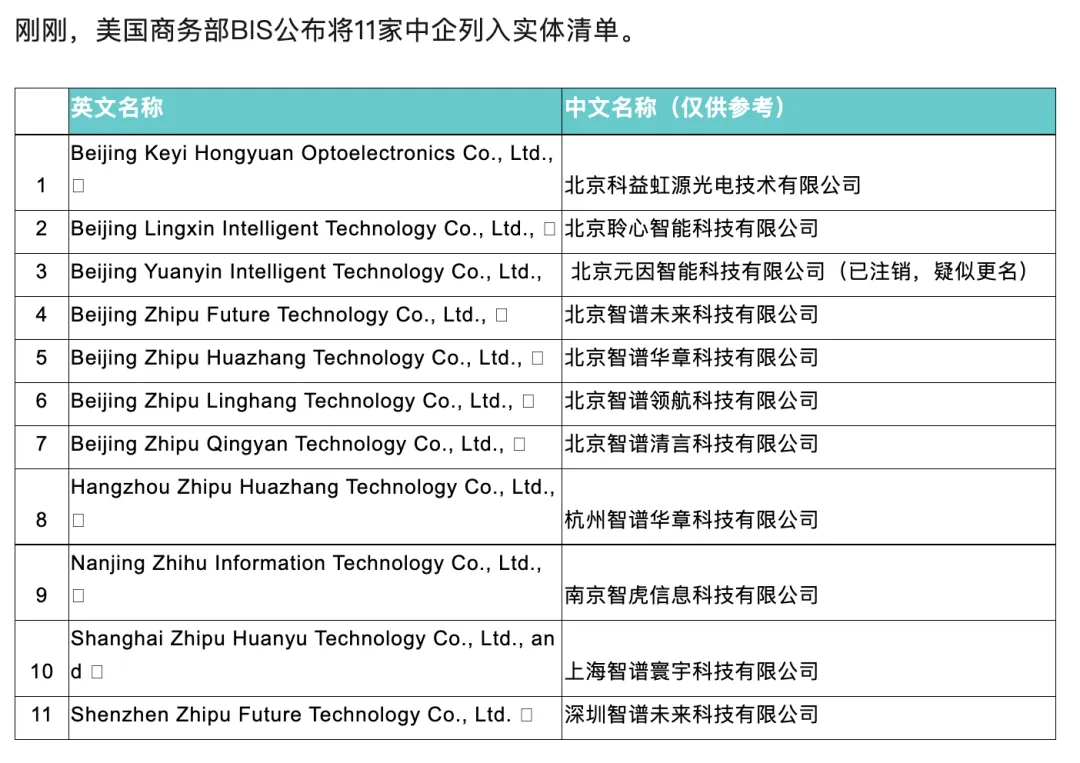
然后,智谱在进实体清单当天,硬刚了一个对标 GPT-4o 的 realtime API,赋能硬件嘴巴和眼睛,且是有两分钟的记忆能力、能唱歌的端到端模型,应是当下国内最强。
理解模型 GLM-4V-Plus 也进行了全面升级(网页上的 GLM-4 在读图的时候,也是基于这个),支持了变分辨率功能,更省 token!(例如,224 * 224的分辨率下,输入的图像token数仅为原来的3%),同时支持4K超清图像和极致长宽比图像的无损识别。
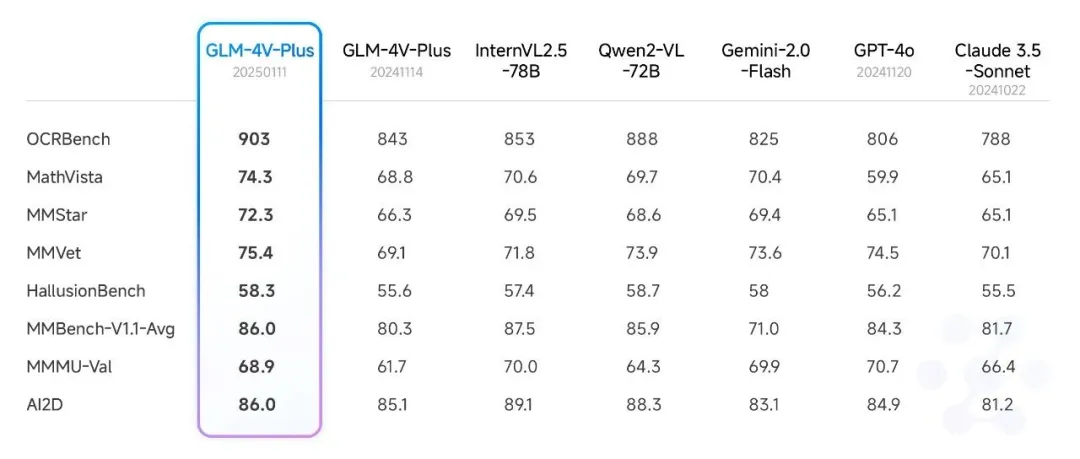
以及,其视频理解模型更新,支持 2 个小时的内容了:《智谱Realtime、4V、Air新模型发布,上线bigmodel.cn》
当然,从开发者的角度,最值得吹嘘的还得是以下 4 种模型全免费:
在最后还得说,这个测试一点都不严谨,而且我们也应知道,模型和人看图的原理,就是不同,但很有意思:只有大模型对世界的观察,和我们一样,才能更好的服务于我们。
以及... 国内其他几家我也测了,结果并不理想。如果想知道结论,可拿文章里的图自来测,然后发到评论区。
文章来自于“赛博禅心”,作者“金色传说大聪明”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
