# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一文读懂数据标注及最佳实践
国家发展改革委等部门2025年1月13年发布了关于促进数据标签产业高质量发展的实施(发改数据〔2024〕1822号)的文件。那么如何为数据打标签,如何进行数据标注呢?下面我们一起了解关于数据标注的知识。
特斯拉在自动驾驶领域的进步展示了数据标注工具的关键作用,使他们的车辆能够准确地解读和驾驭复杂的环境。随着机器学习成为跨行业运营现代化的关键因素,数据标注工具对于将原始数据转化为推动AI性能的有意义的见解至关重要。
以Netflix为例,这家OTT巨头通过个性化内容推荐大幅降低了用户流失率,这不仅仅是因为他们先进的算法,更是得益于精心标记的数据。每个AI成功案例的背后都有无数小时的数据标注,
全球数据注释和标签市场预计将经历快速增长,从2022年的8亿美元增长到2027年的36亿美元,复合年增长率(CAGR)为33.2%。这些工具在各种应用中都至关重要,从增强医疗诊断中的图像识别到改进自然语言处理以实现卓越的客户服务互动。
了解并实施正确的数据标注工具和最佳实践可以显著提高机器学习项目的效率。在本指南中,我们将探索需要了解的有关数据标注工具的所有信息,确保AI计划取得最佳效果。
数据标注是对数据进行归因、标记或标记的过程,以帮助机器学习算法理解和分类它们处理的信息。此过程对于训练AI模型至关重要,使它们能够准确理解各种数据类型,例如图像、音频文件、视频片段或文本。
数据标注工具是一种专用软件平台,可帮助组织对机器学习训练的原始数据进行注释、标记和分类。这些工具通过添加有意义的标签、分类或注释,帮助将非结构化数据(如图像、文本、视频或音频)转换为结构化的带标签的数据集。
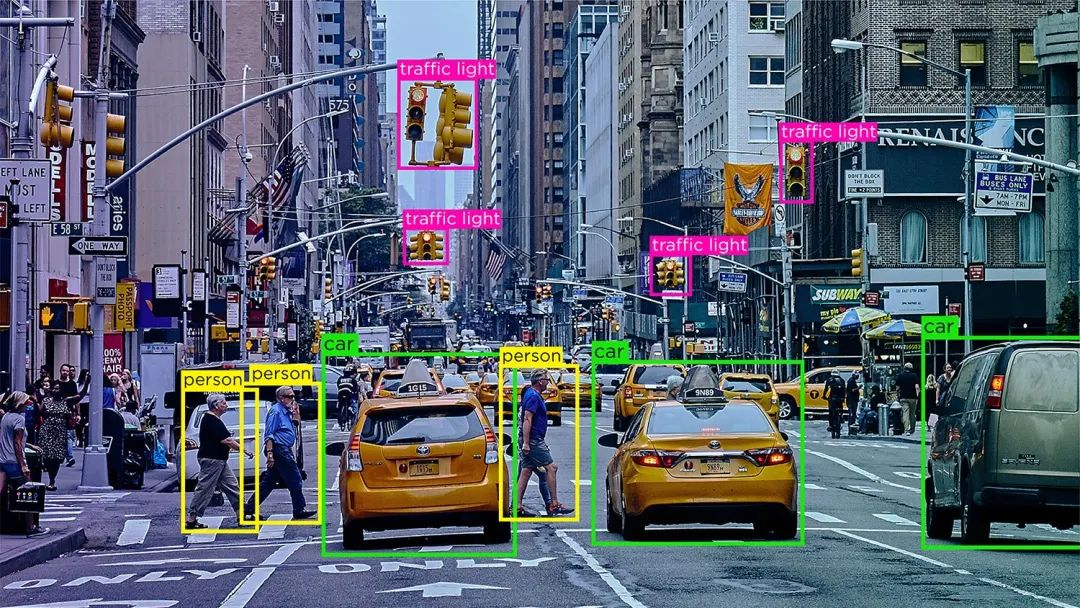
可以将它们视为复杂的数字荧光笔,标记数据中的特定特征、对象或模式,使AI模型能够理解并进行学习。从简单的文本分类到复杂的图像分割,这些工具提供了为机器学习算法准备高质量训练数据所需的界面和功能。
文本注释涉及标记和分类书面内容,以帮助AI模型理解语言模式和上下文。此过程可以包括识别词性、情绪或文本中的特定信息。无论是帮助聊天机器人理解客户查询还是训练模型来分析文档,文本注释都是自然语言处理应用程序的支柱。

将文档分类为新闻、垃圾邮件或技术内容等类别
在客户评论和社交媒体帖子中标记情绪基调或情绪
识别文件中的姓名、地点和组织
突出显示不同文本之间的关系
图像注释是标记和标注图片内特定元素的过程。它可以帮助计算机视觉模型识别视觉数据中的物体、人物和场景。从帮助自动驾驶汽车识别路标到使医学成像系统检测异常,图像注释可以创建视觉理解,为许多现代AI应用程序提供支持。

在照片中的汽车、人物或产品等物体周围绘制框
使用多边形勾勒出物体的精确形状
标记特定兴趣点,如面部特征或地标
标记图像的不同部分以理解场景
视频注释将图像标记扩展到时间维度,标记视频帧中移动和变化的对象和事件。这种标记可帮助AI系统理解运动、跟踪对象并解释视频内容中的活动。对于从安全系统到体育分析等各种应用来说,它都是必不可少的。
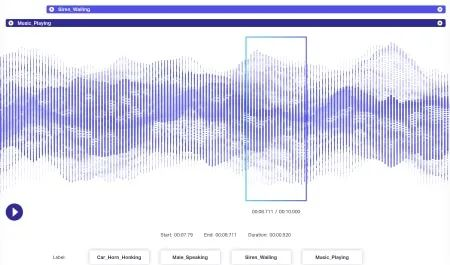
通过视频逐帧跟踪移动物体
标记镜头中发生特定动作或事件的时间
标记场景或环境随时间的变化
识别不同物体或人之间的相互作用
音频标记涉及将语音转换为文本并标记录音中的不同元素。此过程有助于创建能够理解口语、识别不同说话者或识别特定声音的AI系统。这对于开发语音助手、创建字幕和构建音频分析工具至关重要。
将口头语言转换成书面文字
在对话中标记不同的说话者
识别背景噪音和音乐
注意言语中的情绪基调
实体注释侧重于识别和分类数据中的特定元素,无论是文本、图像还是其他格式。它可以帮助AI系统理解不同信息之间的关系并识别重要概念。这种类型的标记对于搜索引擎、推荐系统和知识数据库至关重要。
在目录描述中标记产品名称和属性
识别技术文档中的关键术语和概念
在不同内容之间链接相关项目
将实体分类为层次结构
边界框是围绕图像或视频帧中的对象绘制的简单矩形框。这些框标记特定项目的位置和大小,创建基本轮廓,告诉AI模型要查看的位置。这种简单的方法通常用于对象检测任务,从在商店货架上发现产品到在交通摄像头中识别车辆。
在人物、汽车或动物等物体周围绘制矩形
在照片中标记物品的位置和大小
为对象检测系统创建训练数据
跨视频帧跟踪移动物体
语义分割涉及将图像划分为不同的区域,并根据每个像素所代表的内容对其进行标记。这种方法不仅仅是画出方框,而是创建物体及其边界的详细轮廓。这种方法有助于AI模型了解图像中不同元素的精确形状和位置。
根据图像中不同部分的含义对其进行着色
为对象和背景创建像素级蒙版
标记不同物体之间的精确边界
在一幅图像中识别多个相同类型的物体
命名实体识别侧重于查找和标记文本中的特定术语和短语。此方法有助于识别书面内容中的重要信息,例如姓名、日期、地点和组织。它对于从大量文本中组织和提取关键信息特别有用。
在文件中标记人员和公司的名称
在书面内容中查找日期和地点
识别产品名称和技术术语
标记专业头衔和角色
分类涉及将数据分类到预定义的类别或组中。这种基本但强大的方法有助于以AI模型可以理解和学习的方式组织信息。无论是将电子邮件分类为垃圾邮件和非垃圾邮件,还是对在线商店中的产品进行分类,分类都可以从各种数据中创建秩序。
根据项目特征将其分类
按主题或主题标记内容
根据图片内容进行标记
根据目的或语气对文本进行分类
多边形注释使用多个连接点创建物体的精确轮廓。与简单的框相比,此方法可以更准确地捕捉不规则形状和复杂物体。当物体的精确形状很重要时,这种方法尤其有用,例如在医学成像或详细的产品摄影中。
在形状不规则的物体周围绘制详细的轮廓
为复杂形状创建精确的边界
在较大的图像中标记特定区域
准确捕捉弯曲和非矩形物体
精心设计的界面让技术和非技术团队成员都能够轻松进行数据标注。拖放功能、键盘快捷键和清晰的导航菜单等功能可帮助标记人员高效工作。良好的界面还包括可自定义的工作区和直观的注释工具,可缩短学习时间。
现代数据标注工具可处理多种数据格式,包括图像、视频、文本、音频文件和文档。它们为每种类型的数据提供特定的注释工具,并能够在格式之间无缝切换。这种多功能性使组织能够在单个平台内管理各种标记项目。
这些工具提供任务分配、进度跟踪和实时协作等功能,使团队成员能够高效协作。它们包括项目管理功能,允许主管分配工作、监控团队绩效并在多个注释者之间保持一致的标记标准。
质量控制功能通过共识投票、自动验证检查和审核工作流程确保标记数据的准确性。它们包括用于发现不一致之处、衡量注释者之间的一致性以及实施多个审核阶段以保持高数据质量标准的工具。
集成功能允许数据标注工具与现有系统和工作流程连接。这包括API访问、对常见数据格式的支持以及轻松导入/导出数据的能力。良好的集成有助于实现流程自动化并保持不同平台之间的无缝数据流。
可扩展的工具可以处理不断增长的数据集和团队规模,而不会影响性能。它们提供批处理、分布式工作负载和云存储选项等功能。这确保标记过程可以随项目一起扩展,同时保持效率和质量。
灵活的开源数据标注工具,支持多种数据类型。因其易于设置和可扩展的架构而闻名。
主要特点:多用户支持、可定制的标签界面、RESTfulAPI、与ML框架集成
用例:文本分类、图像分割、文档注释、音频转录
英特尔开发的计算机视觉注释工具。专注于计算机视觉任务,具有强大的视频注释功能。
主要功能:帧插值、AI辅助注释、协作工作区、视频中的多边形跟踪
用例:视频注释、自动驾驶汽车数据标注、零售物体检测
Microsoft的可视化对象标记工具。简单但有效的图像和视频注释工具,支持跨平台。
主要特点:跨平台兼容性、导出为多种格式、键盘快捷键、连接到云存储
用例:物体检测项目、图像分类、安全摄像机镜头分析
描述:macOS特定工具,专注于为计算机视觉创建边界框和分割。
主要特点:快捷键、自动保存、支持PASCALVOC格式、像素级注释
用例:对象检测、实例分割、医学图像注释
企业级平台,提供数据标注软件和托管劳动力。以高质量注释而闻名。
主要特点:API优先方法、质量保证工作流程、管理标签团队、自定义工作流程
使用案例:自动驾驶汽车、机器人、文档处理、地图创建
拥有全球员工和全面项目管理的大型数据注释平台。
主要特点:管理劳动力、多语言支持、自定义本体、企业安全
用例:搜索相关性、语音识别、情感分析、图像分类
现代数据标注平台专注于协作和机器学习驱动的自动化。
主要功能:自动标记、性能分析、API访问、模型辅助标记
用例:医学成像、农业分析、零售自动化、文档处理
将数据标注与模型训练和部署功能相结合的端到端平台。
主要特点:神经网络集成、自动标记、团队协作、内置模型训练
用例:医学成像、卫星图像、制造质量控制
AWS的数据标注集成解决方案,结合了自动化和人工标记工作流程。
主要特点:内置工作流程、私人劳动力管理、自动标记、AWS集成
用例:内容审核、文本分析、视频对象跟踪、文档处理
了解项目需求是选择合适的数据标注工具的基础步骤。不同的机器学习项目需要不同级别的精度、注释类型和工作流程复杂性。例如,专注于图像识别的项目可能需要支持边界框和分割的工具,而自然语言处理(NLP)项目可能会优先考虑文本注释功能。明确定义项目的目标和具体需求可确保所选工具与期望的结果完美匹配。
打算标记的数据种类和数量在确定最适合需求的数据标注工具时起着重要作用。不同的工具针对不同的数据类型进行了优化,例如图像、文本、音频或视频。例如,一些工具专门用于处理具有自动标记和高级图像分割等功能的大规模图像数据集,而其他工具则擅长注释复杂的文本数据,具有实体识别和情感分析功能。确保选择的工具支持项目所需的特定数据格式和注释类型对于无缝数据处理至关重要。
在选择数据标注工具时,预算是一个重要的考虑因素,因为成本会因功能、可扩展性和许可模式的不同而有很大差异。评估总体拥有成本非常重要,包括订阅费、每次注释费用以及高级功能或集成的任何额外费用。了解预算限制有助于优先考虑需要的基本功能和可有可无的功能,确保投资的工具能够提供最佳价值,而不会超出财务限额。
团队规模和专业知识是选择合适数据标注工具的重要因素。大型团队可能需要提供强大协作功能(例如基于角色的访问、任务分配和实时更新)的工具,以确保顺利协调和提高工作效率。另一方面,小型团队可能会优先考虑用户友好的界面和易于设置,以最大限度地缩短学习曲线并最大限度地提高效率,而无需进行大量培训。
选择数据标注工具时,集成功能至关重要,因为与现有技术堆栈的无缝连接可以显著提高工作流程效率。能够轻松与数据存储解决方案、机器学习框架和其他软件应用程序集成的工具可确保数据传输顺畅并减少人工干预的需要。与TensorFlow、PyTorch等流行平台以及AWS或Azure等云服务的兼容性可以简化机器学习流程并促进自动化流程。
可扩展性是一个需要考虑的关键因素,特别是对于规模和复杂性预计会随着时间的推移而增长的项目。可扩展的数据标注工具可以容纳不断增加的数据量和不断扩大的注释要求,而不会影响性能或可靠性。这可确保工具在项目发展过程中保持有效,避免频繁更换工具,从而避免中断工作流程并产生额外成本。
1.定义清晰的注释指南
制定清晰全面的注释指南对于确保数据标注工作的一致性和准确性至关重要。定义明确的指南可帮助注释者了解每个项目的具体要求和标准,从而减少歧义和错误。通过提供详细的说明,可以让团队能够生成符合机器学习目标的高质量标记数据。
创建详细文档:概述具体的注释规则和示例。
标准化标签定义:确保团队对每个标签的统一理解。
包括边缘情况:解决不常见的情况以有效地指导注释者。
定期更新指南:根据反馈和不断变化的项目需求修改指南。
2.有效地培训注释者
注释者的有效培训对于维护高质量的数据标注至关重要。适当的培训可确保团队精通注释指南并熟练使用数据标注工具。投入时间进行培训可增强注释者的信心并降低出现不一致和错误的可能性,从而获得更可靠的数据集。
开展全面的培训课程:提供初步和持续的培训,涵盖注释过程的所有方面。
使用交互式教程:结合实践练习和真实示例来强化学习。
提供反馈机制:允许注释者收到有关其工作的建设性反馈。
鼓励持续学习:通过先进的培训和资源促进技能发展。
3.实施质量保证流程
质量保证(QA)流程对于验证标记数据的准确性和一致性至关重要。实施强大的QA措施有助于在注释过程的早期识别和纠正错误,从而确保数据集的可靠性。定期进行QA检查有助于提高机器学习模型的整体完整性和有效性。
进行定期审计:定期审查注释数据的准确性和一致性。
使用注释者间一致性:测量不同注释者之间的一致性来评估可靠性。
实施自动质量检查:利用工具功能自动检测常见错误。
提供清晰的反馈:与注释者分享QA结果以指导改进。
4.优化工作流程效率
优化数据标注工作流程可提高工作效率并确保及时完成项目。简化的工作流程可减少瓶颈并使团队成员之间能够顺利协作。高效的流程不仅可以节省时间,还可以通过最大限度地减少干扰和冗余来提高注释质量。
自动执行重复任务:使用工具功能处理常规注释并减少手动工作量。
设定明确的里程碑和截止日期:定义项目时间表以确保团队按计划进行。
促进有效沟通:使用协作工具确保团队成员之间的无缝信息流。
定期监控进度:跟踪工作流程指标,以便及时发现和解决效率低下的问题。
5.利用自动化和人工智能辅助
将自动化和AI辅助功能融入数据标注流程可显著提高效率和准确性。自动化工具可以处理重复且耗时的任务,让注释者专注于更复杂、更细致的标记。AI驱动的功能可提高注释的速度和一致性,从而产生更高质量的数据集。
使用预注释功能:允许AI提供注释者可以审查和改进的初始标签。
实施智能建议:利用人工智能根据上下文和模式推荐标签。
自动化数据排序和分类:让工具组织数据以简化注释过程。
持续训练人工智能模型:通过提供高质量的注释数据来改进人工智能辅助。
6.确保数据安全和隐私
使用数据标注工具时,保护数据的完整性和机密性至关重要。实施强大的安全措施可保护敏感信息并确保遵守数据保护法规。优先考虑数据安全可与利益相关者建立信任,并防止可能危及项目的潜在违规行为。
使用安全平台:选择提供强加密和安全协议的数据标注工具。
实施访问控制:仅限授权人员访问数据。
定期更新安全措施:保持安全功能最新,以防范新出现的威胁。
遵守数据保护法规:确保数据处理实践符合相关法律和标准。
7.促进有效合作
促进数据标注团队之间的协作可提高效率并确保注释的一致性。有效的协作工具和实践使团队成员能够无缝协作、分享见解并及时解决问题。协作环境可以培养一支有凝聚力的团队,从而有效地处理复杂的标记任务。
使用协作平台:选择支持实时协作和通信的工具。
分配明确的角色和职责:为每个团队成员定义具体的任务和角色。
鼓励知识共享:促进注释者之间的最佳实践和见解的交流。
促进定期团队会议:召开会议讨论进展、挑战和改进。
8.监控和分析绩效指标
跟踪绩效指标对于评估数据标注流程的有效性和确定需要改进的领域至关重要。通过分析注释速度、准确性和错误率等关键指标,可以做出明智的决策,以增强工作流程和培训计划。持续监控可确保数据标注工作与项目目标保持一致。
定义关键绩效指标(KPI):建立衡量注释质量和效率的标准。
使用分析工具:利用内置或外部分析来跟踪和可视化性能数据。
提供定期报告:与团队分享绩效见解,突出成就和需要改进的领域。
根据数据调整策略:使用指标分析来改进工作流程和培训计划。
9.保持注释的一致性
一致性在数据标注中至关重要,可确保机器学习模型收到可靠且统一的数据。保持一致的注释实践可防止出现可能对模型性能产生负面影响的差异。建立标准化程序并定期审查注释有助于在整个标记过程中保持一致性。
标准化注释程序:创建统一的方法来处理不同的数据类型和场景。
使用模板系统:实施模板来指导注释者并确保统一性。
定期审查注释:进行定期审查以确保整个数据集的一致性。
提供持续培训:不断教育注释者最佳实践和标准化方法。
10.持续改进注释流程
持续改进注释流程可确保数据标注工作始终保持高效和有效。通过定期评估和改进工作流程、指南和工具使用情况,可以适应不断变化的项目要求并采用新的最佳实践。秉持持续改进的心态可推动数据标注计划的持续质量和生产力。
征求注释者的反馈:收集有关工作流程挑战和潜在增强功能的意见。
随时了解工具功能:随时了解数据标注工具的新功能和更新。
实施迭代改进:根据反馈和性能数据进行增量更改。
以行业标准为基准:将流程与行业最佳实践进行比较,以确定改进机会。
数据标注过程涉及一系列明确定义的步骤,以确保为机器学习应用程序提供高质量且准确的数据标注流程。这些步骤涵盖了流程的各个方面,从非结构化数据收集到导出标注数据以供进一步使用。
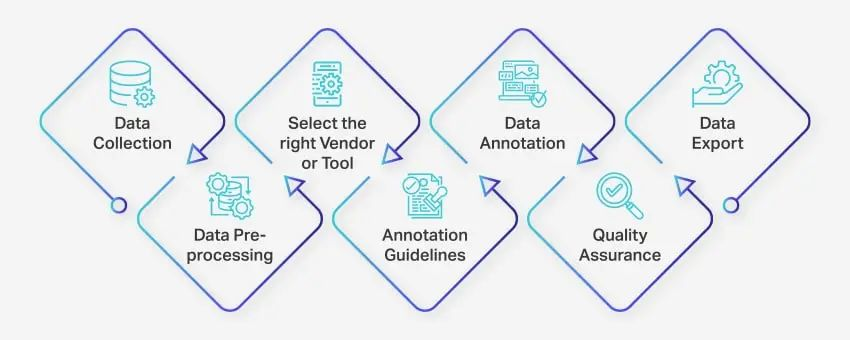
数据注释团队的工作方式如下:
数据采集:数据注释过程的第一步是在一个集中位置收集所有相关数据,例如图像、视频、录音或文本数据。
数据预处理:通过校正图像倾斜、格式化文本或转录视频内容来标准化和增强收集的数据。预处理可确保数据已准备好进行注释任务。
选择合适的供应商或工具:根据项目需求选择合适的数据注释工具或供应商。
注释指南:为注释器或注释工具建立明确的指南,以确保整个过程的一致性和准确性。
注解:按照既定的指导方针,使用人工注释者或数据注释平台对数据进行标记和标注。
质量保证(QA):查看注释数据以确保准确性和一致性。如有必要,使用多个盲注来验证结果的质量。
数据导出:完成数据标注后,将数据导出为需要的格式。Nanonets等平台可以将数据无缝导出到各种商业软件应用程序。
整个数据注释过程可能需要几天到几周的时间,具体取决于项目的规模、复杂性和可用资源。
文章来自于“数据驱动智能”,作者“晓晓”。




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
