# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

Paper link:https://arxiv.org/pdf/2501.03841
Project link:https://omnimanip.github.io
Author:Mingjie Pan, Jiyao Zhang, Tianshu Wu, Yinghao Zhao, Wenlong Gao, Hao Dong

继标志着具身智能领域“ImageNet时刻”到来的开源项目AgiBot World后,智元机器人(AgiBot)提出OmniManip,一个基于对象的规范化交互原语与先进的双闭环规划执行系统,结合RRC(重采样、渲染与检查)自我校正机制,有效提升了效率与稳定性,并缓解了大模型的幻觉问题。
2024年,智元机器人与北大成立联合实验室,8月发布“远征”与“灵犀”两大系列共五款商用人形机器人新品,10月旗下灵犀X1人形机器人官宣开源,12月宣布正式开启通用机器人量产,不断拓展应用场景。
Z Highlights:
由于真实世界的复杂多变,开发通用机器人操控系统一直是一项极具挑战性的任务。受到大语言模型(LLM)和视觉语言模型(VLM)在海量数据中获取通用知识的启发,研究员们开始探索模型在机器人领域的应用。现有研究主要关注如何利用这些知识进行语义推理一类的高层次任务规划,尽管取得了一些进展,但当前的VLM模型主要基于大量二维视觉数据进行训练,缺乏对精确、低层次操控任务所需的三维空间理解能力。这一局限使得机器人在非结构化环境中的操控面临巨大挑战。
一种克服这一局限的方法是通过在大规模机器人数据集上微调VLM,将其转化为视觉语言动作模型(VLA)。然而,这种方法面临两大挑战:
• 获取多样化且高质量的机器人数据既昂贵又耗时
• 将VLM微调为VLA会导致生成特定于某些机器人的表示,这些表示针对特定机器人进行了优化,从而限制了其泛化能力
一种可行的替代方案是将机器人动作抽象为交互基元,例如点或向量,并利用VLM的推理能力来定义这些基元的空间约束,同时由传统的规划算法负责执行。然而,现有的基元定义和使用方法存在多个局限性:基元生成的过程与具体任务无关,这可能导致缺乏合适的基元;此外,依赖人工设计的规则来对基元进行后处理也会引入不稳定性。这自然引出了一个重要问题:如何开发更加高效且具有泛化能力的表示方法,以弥合VLM的高层次推理与精确低层次机器人操控之间的差距?
为了解决这一难题,团队提出了一种以对象为中心的中间表示方法OmniManip,该方法在对象的规范空间中融入了交互方向和交互点。这种表示方式弥合了VLM高层次常识推理与精确三维空间理解之间的差距。核心观点为,对象的规范空间定义为以其功能可供性为基础。因此,可以在规范空间中以更有条理、语义更丰富的方式描述对象的功能。同时,近年来在通用对象姿态估计领域的进展,使得对各种对象进行规范化成为可能。
具体来说,团队采用了一个通用的6D对象姿态估计模型来对对象进行规范化,并描述其在交互过程中发生的刚体变换。同时,利用单视角3D生成网络生成详细的对象网格模型。在规范空间中,交互方向最初沿对象的主轴进行采样,提供一组粗略的交互可能性。同时,VLM预测交互点的位置。随后,VLM会识别与任务相关的交互基元,并估计它们之间的空间约束。
为了解决VLM推理过程中可能出现的虚假推断问题,团队引入了一种自我修正机制,通过交互渲染和基元重采样实现闭环推理。一旦确定最终策略,动作将通过约束优化计算得出,并在执行阶段通过姿态跟踪实现稳健的实时闭环控制。
此方法具有以下两个关键优势:
• 高效且有效的交互基元采样:通过利用对象的规范空间,团队的方法能够高效且有效地采样交互基元,增强系统的推理能力。
• 双闭环开放词汇机器人操控系统:得益于所提出的以对象为中心的中间表示,新方法实现了一个双闭环系统。渲染和重采样过程驱动推理闭环以支持决策,而姿态跟踪则确保动作执行的闭环控制。
团队设计了12个任务以评估模型在真实场景中的操控能力。其中6个任务涉及刚体对象的操控(例如倒茶),其余任务专注于关节化操作(例如打开抽屉)。这些任务涵盖了多种类型的对象,旨在评估模型在复杂环境中泛化与适应的能力。每个任务对每种方法进行了10次试验,并记录成功率。每次试验后,都会重新配置对象布局,以确保评估的稳健性。
将方法与以下三种Baseline进行比较:
• VoxPoser :使用LLM和视觉语言模型VLM生成3D value map,用于合成机器人轨迹,在零样本学习和闭环控制方面表现出色;
• CoPa:引入对象部件的空间约束,结合VLM实现开放词汇操控;
• ReKep:采用关系关键点约束和分层优化,从自然语言指令生成实时动作。
使用GPT4作为视觉语言模型,通过一小组交互示例作为提示,引导模型推理操控任务。对于六自由度通用抓取任务,并采用GenPose++进行通用6D姿态估计。

12种任务
对OmniManip在12项开放词汇操控任务中进行了全面评估,任务涵盖从简单的抓取与放置(pick-and-place)到更复杂的任务,例如具有方向约束的对象间交互以及关节化对象的操作。如表所示,OmniManip在无需任务特定训练的情况下表现出强大的零样本泛化能力,并在各项任务中表现出色。这种泛化能力主要得益于以下两点:在VLM中嵌入的常识知识,提供了广泛的任务理解能力;高效的基于对象的交互原语,提高了3D感知和任务执行的精度。
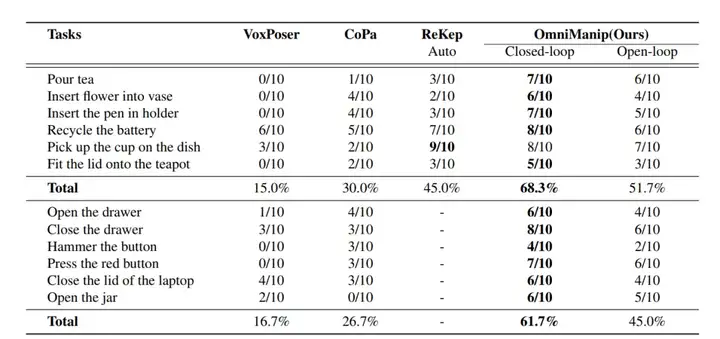
12项真实场景操控任务的量化结果 前六项任务聚焦于刚体对象操控,后六项任务则涉及关节化对象操控。“-” 表示该方法由于其底层原理无法完成对应任务。
与Baseline方法相比,OmniManip展现了显著的性能优势,主要源于以下两个关键因素:所提出的基于对象的规范化交互原语的效率与稳定性和用于规划和执行的先进双闭环系统。通过结合基于 RRC(重采样、渲染与检查) 的新型自我校正机制,系统有效缓解了大模型中的幻觉问题。如表所示,这种闭环规划在刚体与关节化对象操控任务中将性能提升了15%以上。
团队研究框架将复杂的机器人任务分解为多个阶段,每个阶段都由对象的交互基元及其空间约束定义。这种结构化的方法能够精确界定任务需求,并为复杂操控任务的执行提供清晰的指导,实现无需特定任务训练,交互基元作为空间约束的基础,从而实现稳定且高效的操控。
给定一个操控任务τ (例如,将茶倒入杯中),GroundingDINO和SAM两个视觉基础模型,对场景中的所有前景对象进行标注,将其作为视觉提示。随后,采用VLM进一步筛选与任务相关的目标对象。
任务被分解为多个阶段S={S1,S2,S3,...,Sn} ,其中每个阶段Si可以化为Si={Ai,Oi_active,Oi_passive}。Ai表示需要执行的操作(例如抓取、倒入),Oi_active,Oi_passive分别表示发起交互的主动对象和被操作的被动对象。例如,在图2中,抓取茶壶的阶段中,茶壶是被动对象;而在将茶倒入杯子的阶段中,茶壶是主动对象,而杯子是被动对象。
团队提出了一种新颖的以对象为中心的表示方法,通过标准交互原语来描述对象在操作任务中的交互方式。具体来说,对象的交互原语由其交互点和在标准空间中的交互方向来定义。
•交互点p :指对象上发生交互的关键位置。
•交互方向v :代表与任务相关的主要轴线方向。
•两者共同构成了交互原语O={p,v} ,浓缩了完成任务所需的几何特性和功能特性。
在每个阶段Si,一组空间约束Ci控制着主动对象和被动对象之间的空间关系。这些约束分为两类:距离约束di,用于调节交互点之间的距离;以及角度约束θi,用于确保交互方向的正确对齐。这些约束共同定义了精确空间对齐和任务执行所需的几何规则。每个阶段Si的总体空间约束由下式给出:
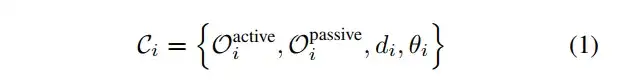
一旦定义了约束Ci,任务执行就可以被表述为一个优化问题。
如下图所示,首先通过单视图3D生成技术获取任务相关的主动对象和被动对象的3D网格模型,并使用Omni6DPose进行姿态估计,对对象进行标准化。接着,提取与任务相关的交互原语及其对应的空间约束。
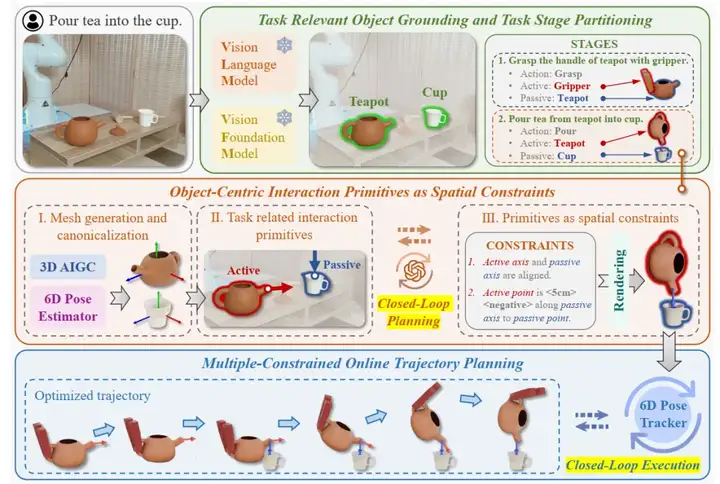
在接收到指令和通过VFM标注的RGB-D观测后,VLM首先筛选出与任务相关的目标对象,并将任务划分为多个阶段。在每个阶段,VLM以闭环方式提取以对象为中心的规范交互基元,将其作为空间约束。在执行过程中,运动轨迹基于这些空间约束进行优化,并通过6D姿态跟踪器以闭环方式进行实时更新。
之后进行交互点选取,交互点分为可见且可触碰的交互点(如茶壶的把手)和可见或不可触碰的交互点(如茶壶开口的中心)两类。
为了增强交互点定位的准确性,采用SCAFFOLD的视觉提示机制,将笛卡尔网格叠加在输入图像上。对于可见交互点,直接在图像平面中进行定位。对于不可见交互点,通过基于标准化对象表示的多视图推理进行推断。推理从主要视角开始,当存在歧义时,切换到正交视角进行解读。这种方法使交互点的定位更加灵活可靠。对于抓取任务,系统会从多个交互点生成热力图,从而提升抓取模型的鲁棒性和准确性。
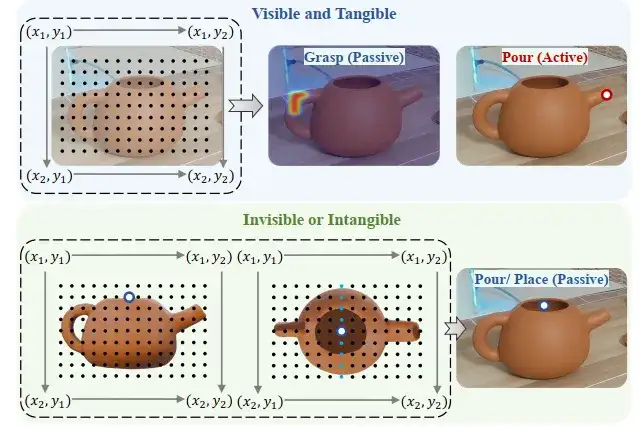
交互点生成
交互方向提取。在标准空间中,对象的主轴通常具有功能上的相关性。如图所示,将主轴视为候选的交互方向。然而,由于当前VLM对空间理解能力的限制,评估这些方向与任务的相关性具有一定挑战性。
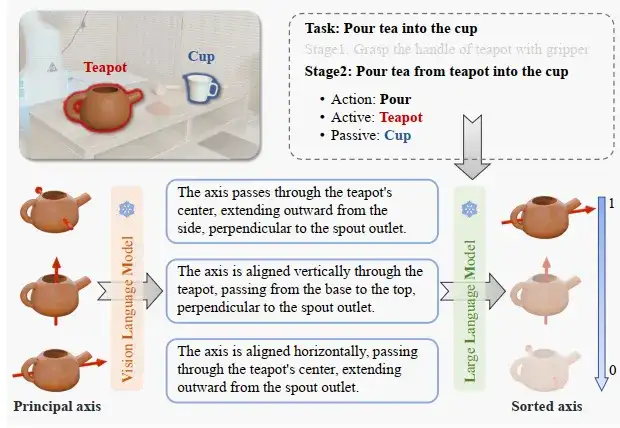
交互方向提取
为了解决这一问题,团队提出了一个结合VLM生成与LLM评分的机制:VLM生成语义描述:首先,使用VLM为每个候选主轴生成语义描述。其次,大语言模型(LLM)推断这些描述与任务的相关性并进行评分。通过这一过程,团队得到了一个按任务相关性排序的候选方向集合。这些方向最符合任务需求。最终,结合空间约束生成交互原语,形成每个阶段 的有序约束交互原语列表,表示为:
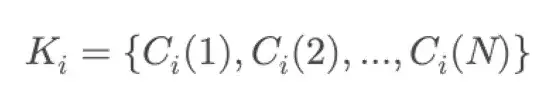
OmniManip的可靠性:为了有效连接视觉语VLM与底层操控操作,可靠的交互原语至关重要,团队从两个关键维度对其进行了评估:稳定性和视角一致性。
稳定性反映了任务相关交互原语的可靠提取能力。如图所示:
•ReKep通过语义聚类提取关键点,但对空间几何和任务敏感性不足,难以生成足够任务相关的关键点。
•CoPa通过显式像素分割提取零部件,虽然对图像纹理和部件形状敏感,但在复杂任务中易受干扰。
•OmniManip则采用基于对象的交互原语,在与对象功能对齐的规范化空间中采样交互点,确保了鲁棒性和任务特定的精确性。

交互原语的稳定性分析:该图展示了使用“倒茶”任务作为案例,通过不同方法进行的规划和对应执行结果的可视化。分析了不同方法在执行过程中提取和应用交互原语的稳定性,并比较了它们在处理复杂任务时的表现。
视角一致性。在不同视角下交互原语提取的一致性对操控稳定性至关重要。由于依赖直接从对象表面采样点,ReKep和CoPa在这一方面表现较差。例如,在“回收电池”任务中,ReKep在90°俯视视角下可以成功识别交互点,但在0°正面视角下则失败,目标点漂浮在空中。相比之下,OmniManip采用了基于对象的规范化空间交互原语表示,确保了视角不变性。表中提供了量化对比结果,显示OmniManip在不同视角下的性能几乎不变,而ReKep的性能则因视角变化而显著下降。

视角对性能影响的定性分析:该图使用“回收电池”任务作为案例,展示了不同视角下各方法的表现。通过定性分析,比较了在不同视角下各方法的交互原语提取和任务执行结果,揭示了OmniManip如何通过规范化空间的对象中心交互原语,确保在不同视角下的一致性和稳定性。

视角对性能影响的量化分析:该表使用“回收电池”任务作为案例,展示了不同视角下各方法的性能对比分析。通过量化评估,分析了视角变化如何影响各方法在执行任务时的稳定性和准确性,进一步验证了OmniManip 在不同视角下的视角不变性和可靠性。
OmniManip的效率,OmniManip中的交互方向提案是通过有针对性的采样策略驱动的。与SO(3)中的均匀采样相比,OmniManip沿着对象规范化空间的主轴进行采样。由于规范化空间与对象的功能对齐,这确保了采样的高效性和有效性。为了评估这一效率,团队将OmniManip的采样策略与SO(3)中的均匀采样进行了比较,使用了两个关键指标:迭代次数和相应的任务成功率。OmniManip不仅需要更少的迭代次数,而且任务表现更为优秀,证明了将采样过程与对象功能对齐能减少采样开销,同时提升整体性能。
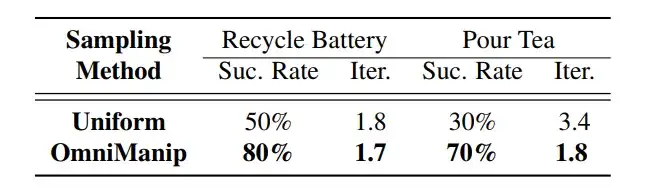
原语采样效率量化分析
团队使用OmniManip生成自动化演示数据。与之前依赖于特定任务特权信息的方法不同,OmniManip能够以zero-shot的方式收集新任务的演示轨迹,无需任务特定的细节或先前的对象知识。为了验证OmniManip生成数据的有效性,每个任务收集了150条轨迹来训练行为克隆策略。如表所示,这些策略实现了较高的成功率。
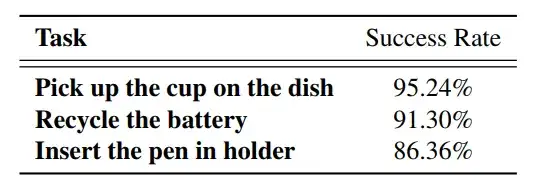
基于 OmniManip 生成的演示数据进行行为克隆
分析OmniManip如何通过闭环推理和闭环执行,实现高层次任务规划与低层次精确控制的有机结合。前文推理的交互基元的定义中已获取主动对象和被动对象的交互原语,分别表示为O_active, O_passive,以及定义它们空间关系的空间约束Lc。然而,这种方法属于开环推理,其固有局限性大模型的幻觉效应和真实环境的动态性削弱了系统的鲁棒性和适应性。为了解决这些问题,研究者提出了一种双闭环系统。
闭环规划,为了提高交互原语的准确性并缓解视觉语言模型(VLM)的幻觉问题,团队引入了一种基于重新采样、渲染和验证的自我纠正机制。该机制利用来自VLM的实时反馈检测并修正交互错误,从而确保任务执行的精确性。RRC过程分为两个阶段:初始阶段和优化阶段,其整体机制详见算法1。

算法1
在初始阶段,系统评估交互原语中定义的交互约束K ,这些约束指定了主动对象与被动对象之间的空间关系。对于每个约束Ci(k) ,系统根据当前配置渲染交互图像Ii,并将其提交给VLM进行验证。VLM返回三种可能的结果:
•成功(success):约束被接受,任务继续执行。
•失败(failure):评估下一个约束。
•优化(refinement):进入优化阶段以进一步调整。
在优化阶段,系统围绕预测的交互方向vi进行细粒度重新采样,修正对象功能轴与几何轴之间的偏差。系统在周围均匀采样六个优化方向vi(j) 并对其进行评估,最终选择最优方向以确保交互的准确性和任务的顺利完成。
闭环执行阶段,一旦为每个阶段定义了交互原语及其对应的空间约束C ,任务执行就可以被表述为一个优化问题。其目标是通过最小化损失函数,确定末端执行器的目标姿态 。这个优化问题可以表示为:
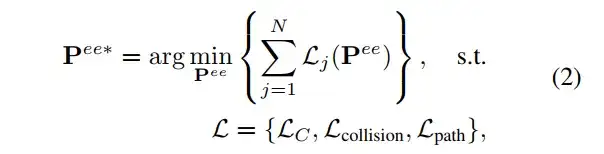
•Pee*是末端执行器的当前姿态;
•约束损失LC确保动作符合任务的空间约束C:
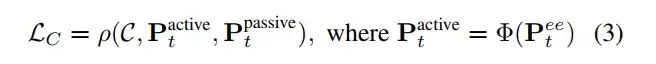
○ρ(·)用于衡量主动对象当前空间位置Pt_active与被动对象当前空间位置Pt_active偏离目标约束C的程度
○φ(i)将末端执行器的姿态映射到主动对象的姿态上
•碰撞损失Lcollision用于防止末端执行器与环境中的障碍物发生碰撞:
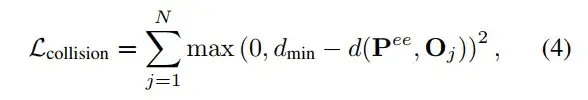
○Oj表示环境中的障碍物
○d(Pee,Oj)是末端执行器与障碍物Oj之间的距离
○dmin是安全距离阈值,确保执行器与障碍物保持足够的安全间隔
•路径损失Lpath用于确保路径动作的平滑性:
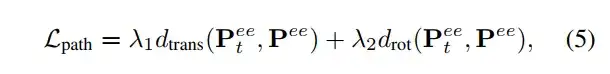
○dtrans(·)和drot(·)分别表示末端执行器的平移位移和旋转位移
○λ1和λ2是权重因子,表示用户平衡平移与旋转的影响
○通过最小化这些损失函数,系统能够动态调整末端执行器的姿态Pee,确保任务成功执行,同时避免碰撞并保持动作的平滑性
虽然公式 (3) 阐明了如何利用交互原语及其对应的空间约束来优化末端执行器的可执行姿态,但实际任务执行中往往会受到显著的动态因素影响。例如,在抓取任务中,抓取姿态的偏差可能导致对象发生意外移动。此外,在某些动态环境中,目标对象可能会被移位。这些挑战突出了闭环执行在应对不确定性方面的重要性。
为了解决这些问题,团队的系统利用所提出的基于对象的交互原语,并直接应用现成的6D对象姿态跟踪算法,实时更新主动对象Ptactive和被动对象Ptpassive的位置姿态,如公式 (4) 。这种实时反馈机制使系统能够动态调整末端执行器的目标姿态,从而实现鲁棒且精确的闭环执行。
在现有方法中,VLM的规划组件通常以开环方式运行,这意味着它无法在执行前验证规划的正确性。尽管ReKep通过点跟踪实现了闭环控制,但这仅在执行阶段有效,且无法对VLM生成的规划结果提供反馈。相比之下,OmniManip引入了一种独特的自我校正机制,通过RRC实现闭环规划,从而显著减少由于VLM幻觉问题导致的规划失败。下表展示了禁用闭环规划的结果,其中rigid和articulated物体操作任务的成功率均下降超过15%,证明了闭环规划方法的有效性。下图中,团队以“将笔插入笔架”任务为例,定性展示了闭环规划结果:OmniManip能够有效地预渲染规划结果,并通过RRC过程实现自我校正,从而实现闭环规划。
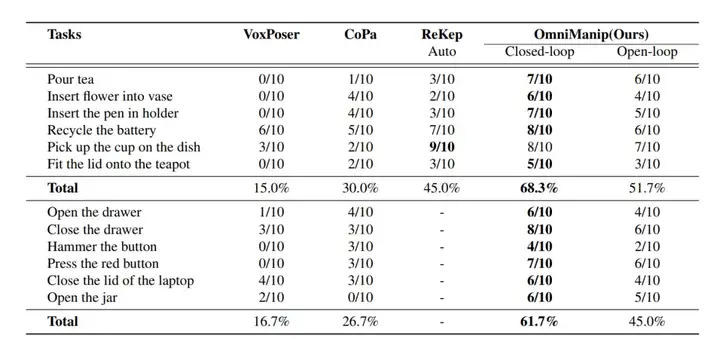
12项真实场景操控任务的量化结果
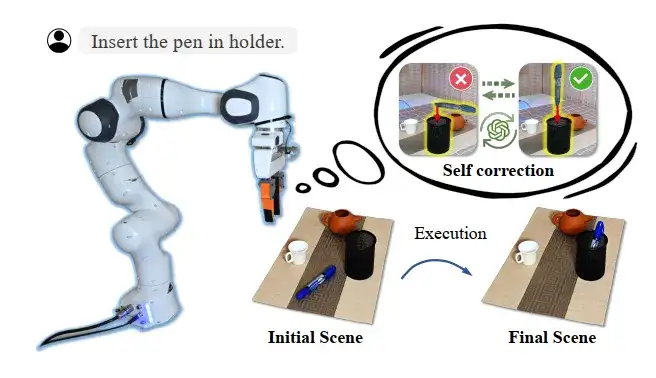
闭环规划,通过RRC实现自我校正机制
闭环执行。即使在完美规划的情况下,开环执行仍然可能导致任务失败。下图展示了两个典型的例子,其中规划成功,但开环执行导致失败。在下图的左侧图像中,夹爪与物体之间的相对姿态在交互过程中发生了变化,而下图的右侧图像展示了目标姿态是动态的场景,比如物体在任务过程中发生移动。为了应对这些挑战,OmniManip采用姿态追踪来实现实时闭环执行。近期的工作ReKep使用点追踪进行闭环控制,但遮挡问题导致了47%的失败率。相比之下,OmniManip在应对由物体移动引起的遮挡时表现出更强的鲁棒性。这得益于基于物体姿态的物体中心姿态追踪,能够在交互原语不再可见的情况下,继续追踪基于物体姿态的标准空间交互原语。

没有闭环执行的两个典型失败案例
尽管具有优势,OmniManip也存在一些局限性。由于姿态表示问题,它无法建模可变形物体。此外,它的有效性还依赖于3D AIGC网格质量,即便是并行处理,多次调用VLM也会带来计算上的挑战。
更多的实验结果及可视化展示详见论文和主页。
第一作者均来自智元机器人、北大计算机学院计算机前沿研究中心(CFCS)。
Mingjie Pan,北京大学计算机学院计算机前沿研究中心硕士研究生,研究聚焦3D与具身智能领域的自适应无监督学习方向。
文章来自微信公众号 “ Z Potentials ”




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
