# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在过去的两年里,城市场景生成技术迎来了飞速发展,一个全新的概念 ——世界模型(World Model)也随之崛起。当前的世界模型大多依赖 Video Diffusion Models(视频扩散模型)强大的生成能力,在城市场景合成方面取得了令人瞩目的突破。然而,这些方法始终面临一个关键挑战:如何在视频生成过程中保持多视角一致性?
而在 3D 生成模型的世界里,这一问题根本不是问题 —— 它天然支持多视角一致性。基于这一洞察,南洋理工大学 S-Lab 的研究者们提出了一种全新的框架:CityDreamer4D。它突破了现有视频生成的局限,不再简单地「合成画面」,而是直接建模城市场景背后的运行规律,从而创造出一个真正无边界的 4D 世界。
如果世界模型的终极目标是打造一个真实、可交互的虚拟城市,那么我们真的还需要依赖视频生成模型吗?不妨直接看看 CityDreamer4D 如何突破现有方案,构建出一个真正无边界、自由探索的 4D 城市世界——请欣赏它的生成效果!

想深入了解 CityDreamer4D 的技术细节?我们已经为你准备好了完整的论文、项目主页和代码仓库!

过去两年,城市场景生成技术取得了突破性进展,生成质量达到了前所未有的高度。这一进步伴随着 “元宇宙” 和 “世界模型” 等概念的兴起,推动了对更真实、更连贯虚拟世界的探索。其中,“世界模型” 致力于在生成的场景中融入物理世界的运行规律,为更具沉浸感的虚拟环境奠定基础。当前主流的世界模型可大致分为四类:
而 CityDreamer4D 正是为了解决这一难题而生。它打破了视频扩散模型的固有瓶颈,不仅仅是 “合成” 城市影像,而是直接建模城市场景背后的运行规律,打造一个真正无边界、可自由探索的 4D 世界。我们的核心洞见如下:(1)4D 城市生成应当将动态物体(如车辆)与静态场景(如建筑和道路)解耦;(2)4D 场景中的所有物体应由不同类型的神经场组成,包括建筑、车辆和背景环境。
具体而言,我们提出了交通场景生成器(Traffic Scenario Generator)和 无边界布局生成器(Unbounded Layout Generator),分别用于生成动态交通场景和静态城市布局。它们基于高度紧凑的鸟瞰视角(BEV)表示进行建模,使得场景生成更加高效。在 4D 城市中,所有物体的生成依赖于背景环境、建筑物和车辆的神经场表示,其中结合了基于事物(Stuff-oriented)和基于实例(Instance-oriented)的神经场。为了适配背景环境与实例物体的不同特性,我们采用了自适应生成哈希网格(Generative Hash Grids)和 周期位置编码(Periodic Positional Embeddings)进行场景参数化,确保生成的城市既具备丰富的细节,又能保持时空一致性。
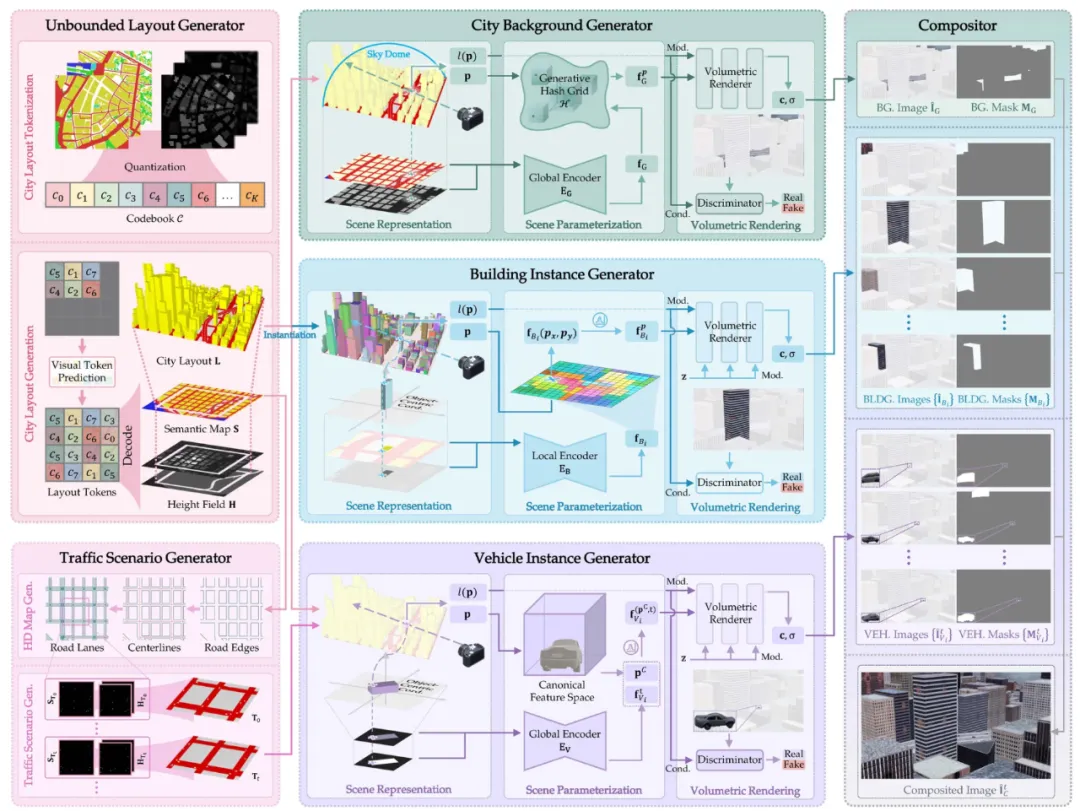
CityDreamer 通过无边界布局生成器(Unbounded Layout Generator)生成静态场景的城市布局,并利用城市背景生成器(City Background Generator和建筑实例生成器(Building Instance Generator)对城市中的背景环境和建筑进行建模。相比之下,CityDreamer4D在此基础上进一步引入交通场景生成器(Traffic Scenario Generator)和车辆实例生成器(Vehicle Instance Generator),专门用于建模 4D 场景中的动态物体,使生成的城市更加生动且符合物理规律。
城市布局生成
CityDreamer4D将无限扩展的城市布局生成问题转化为可扩展的语义地图和高度场建模,从而实现更灵活的城市生成。为此,它采用了基于 MaskGIT 的无边界布局生成器(Unbounded Layout Generator, ULG),这一方法天然支持Inpainting 和 Outpainting ,使得场景可在任意方向拓展。
具体而言,ULG 先通过 VQVAE 对语义图和高度场的图像切片进行编码,将其映射到离散潜在空间,并构建 Codebook 。在推理过程中,ULG 以自回归方式生成 Codebook 索引,并利用 VQVAE 解码器生成一对语义图和高度场。值得一提的是,高度场由俯视高度图和仰视高度图组成,这一设计使得 ULG 能够精准建模场景中的镂空结构(如桥梁等)。
由于 VQVAE 生成的语义图和高度场尺寸固定,ULG 通过图像 Outpainting 进行扩展,以支持任意规模的城市布局。在此过程中,它采用滑动窗口策略逐步预测局部 Codebook 索引,每次滑动时窗口之间保持25% 的重叠,确保生成区域的平滑衔接和连贯性。
在 CityDreamer4D 中, 交通场景生成器(Traffic Scenario Generator)负责在静态城市布局上生成合理的动态交通流,以建模真实的城市动态。

为了使交通流合理且符合物理规律,我们引入高清交通地图(HD Map)作为约束。HD Map 在城市布局(City Layout)的基础上,额外提供车道中心线、交叉口、道路标志、交通信号灯等关键信息。具体而言,我们将 City Layout 转换为图结构(Graph Representation),通过边缘检测和向量化技术提取道路边界,并进一步解析车道中心线及其拓扑关系。结合 Bézier 曲线,我们推导车道的数量、宽度及其交叉口连接方式,以生成完整的 HD Map。
基于 HD Map,我们采用现有的交通模拟模型逐帧生成动态物体的边界框(Bounding Boxes),然后将其转换为语义图和高度场,确保车辆始终出现在合适的位置,并遵循合理的行驶路径。最终,所有动态物体的轨迹被合成为 4D 交通流 ,使得 CityDreamer4D 能够高效建模复杂的城市交通动态。
城市背景生成器(City Background Generator, CBG)负责生成城市的背景元素,包括道路、绿化和水域。为了高效表示大规模三维场景,CBG 采用鸟瞰视角(BEV)作为场景的基本表征,该表征由语义图和高度图共同构成,使得背景结构清晰、层次分明。

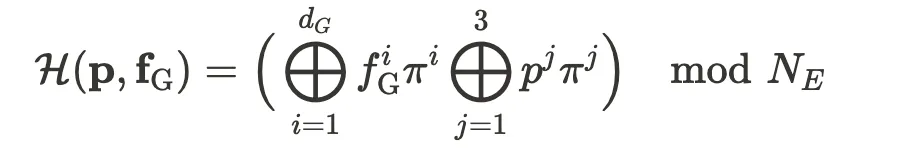
为了保证背景渲染的 3D 一致性,CBG 采用基于体积渲染的神经网络,将三维特征映射到二维图像。具体而言,对于相机光线上的任意采样点,系统首先查询生成式哈希网格以获取对应的特征表示,随后使用风格噪声调制的多层感知机(MLP)计算其颜色和体密度,并通过体渲染(Volumetric Rendering)积分得到最终像素的颜色值。
建筑实例生成器(Building Instance Generator, BIG) 专门用于生成城市中的建筑结构。与城市背景生成类似,BIG 采用鸟瞰视角(BEV)作为场景的基本表征,并利用基于体积渲染的神经网络将三维特征映射到二维图像,从而确保建筑在不同视角下的稳定呈现。考虑到建筑立面与屋顶在外观和分布上的显著差异,BIG 采用独立的类别标签对两者进行建模,使生成结果更加精准且符合现实规律。

这一策略不仅优化了建筑立面的建模效率,还确保了生成结果在大尺度城市环境中的结构合理性,使得建筑在不同高度、角度下都能保持稳定的视觉表现。

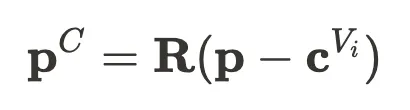
这一参数化方式能够捕捉车辆前后、侧面的结构差异,同时提升不同车辆实例间的特征一致性。
在渲染过程中,VIG 采用体渲染进行 3D 生成,并使用风格编码(Style Code)控制车辆外观的变化,以增强生成结果的多样性和真实感。最终,VIG 通过全局编码器提取车辆实例的局部特征,并利用标准化特征空间进行 4D 场景建模,使得 CityDreamer4D 能够高效生成时空一致的动态交通环境。

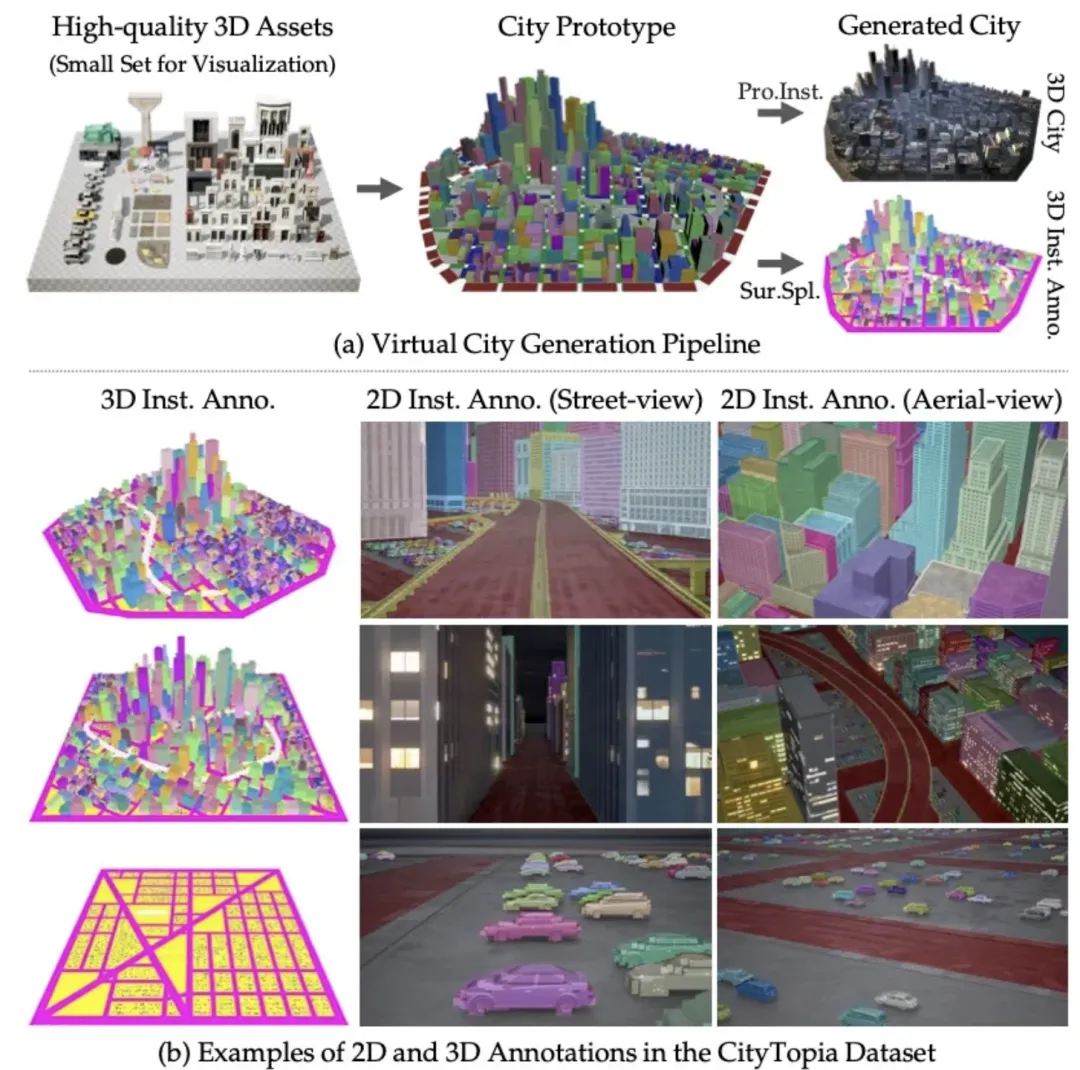
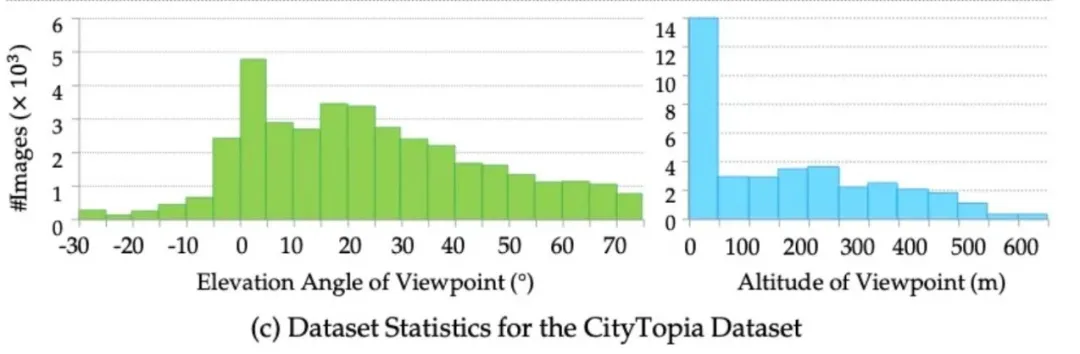
CityDreamer [7] 中所提出的 GoogleEarth 数据集尽管提供了密集的 3D 语义和实例标注,但仍存在诸多局限:缺乏街景视角、标注精度受限、以及高架道路等复杂结构未被完整标注。为解决这些问题,我们构建了 CityTopia—— 一个拥有高保真渲染、多视角覆盖、精准 3D 标注的数据集,专为城市生成与交通建模而设计。
虚拟城市构建:CityTopia 的城市场景基于 Houdini 和 Unreal Engine 构建,我们精心设计了 11 座虚拟城市,并利用 CitySample 项目的约 5000 个高质量 3D 资产生成完整的城市结构。城市的每个元素都存储了 6D 位姿信息,并通过表面采样(Surface Sampling)自动赋予语义与实例标签。这些城市在 Unreal Engine 中实例化后,可在不同光照条件下渲染出高质量的图像,为城市建模提供了更加灵活的实验环境。
数据采集:CityTopia 采用预设的相机轨迹进行数据采集,每座城市包含 3000-7500 张图像,涵盖白天与夜晚两种光照条件。相比 GoogleEarth,CityTopia 提供了更多的街景视角,并在低仰角航拍数据上有更广的覆盖。为保证图像质量,我们在渲染过程中采用 8× 空间超采样与 32× 时间超采样,有效减少渲染伪影,使得数据更加稳定。
2D + 3D 标注:CityTopia 的 3D 标注来自虚拟城市生成过程,所有 3D 物体的语义和实例信息均在数据构建时直接获得,无需额外的手工标注调整。2D 标注则通过相机投影从 3D 标注自动生成,并与街景图像、航拍图像 完美对齐。在车辆场景中,CityTopia 的实例标注与 3D 结构高度一致,使其在车辆生成、交通建模等任务上具备较高的参考价值。此外,由于数据生成流程完全可控,只需增加新的 3D 资产,即可进一步扩展数据集规模。
与其他世界模型方案的对比:下方视频对比了 CityDreamer4D 与 DimensionX [2](视频生成)、WonderJourney [3](图像生成) 和 CityX [6](程序化生成)。结果表明,CityDreamer4D 在多视角一致性上明显优于 DimensionX 和 WonderJourney,在场景多样性上显著优于 CityX。

与原生 3D 场景生成方法的对比:下方视频展示了 CityDreamer4D 与现有原生 3D 场景生成方法(包括 InfiniCity [9]、PersistentNature [10] 和 SceneDreamer [11])的对比。结果表明,CityDreamer4D 在生成质量上实现了显著提升。

城市风格化:CityDreamer4D 能够轻松扩展城市风格。通过引入 ControlNet 的先验,我们可以将 Minecraft、Cyberpunk 等不同风格无缝应用于整个城市,只需在 ControlNet 生成的图像上微调预训练模型,即可获得风格一致的 3D 城市场景。虽然 ControlNet 生成的图像缺乏 3D 一致性,但 CityDreamer4D 依托其高效的场景表示与参数化,能够确保风格化后的城市在不同视角下保持一致。

我们提出了 CityDreamer4D ,一个基于 3D 表征的 4D 城市生成框架,突破了现有 Video Diffusion 方法的多视角不一致问题 。相比传统视频生成,CityDreamer4D 直接在 3D 空间建模城市的动态变化,从而生成 空间和时间维度一致的 4D 场景。此外,我们构建了 CityTopia ,一个高精度 3D 城市数据集,涵盖多视角、多光照条件,并提供精确的 2D-3D 对齐标注。CityDreamer4D 提供了一种原生 3D 的世界模型,为 4D 城市生成提供了全新的解决方案。
参考文献:
[1] Streetscapes: Large-scale Consistent Street View Generation Using Autoregressive Video Diffusion. SIGGRAPH 2024.
[2] DimensionX: Create Any 3D and 4D Scenes from a Single Image with Controllable Video Diffusion. arXiv 2411.04928.
[3] WonderJourney: Going from Anywhere to Everywhere. CVPR 2024.
[4] WonderWorld: Interactive 3D Scene Generation from a Single Image. arXiv 2406.09394.
[5] SceneX: SceneX: Procedural Controllable Large-scale Scene Generation. arXiv 2403.15698.
[6] CityX: Controllable Procedural Content Generation for Unbounded 3D Cities. arXiv 2407.17572.
[7] CityDreamer: Compositional Generative Model of Unbounded 3D Cities. CVPR 2024.
[8] GaussianCity: Generative Gaussian Splatting for Unbounded 3D City Generation. arXiv 2406.06526.
[9] InfiniCity: Infinite-Scale City Synthesis. ICCV 2023.
[10] Persistent Nature: A Generative Model of Unbounded 3D Worlds. CVPR 2023.
[11] SceneDreamer: Unbounded 3D Scene Generation from 2D Image Collections. TPAMI 2023.
文章来自微信公众号 “ 机器之心 ”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
