# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
继DeepSeek掀起轩然大波之后,AI圈这两天再次被“震惊”。
近日有媒体报道称,李飞飞等斯坦福大学和华盛顿大学的研究人员以不到50美元的云计算费用,成功训练出了一个名为s1的人工智能推理模型。
该模型在数学和编码能力测试中的表现,据称与OpenAI的O1和DeepSeek的R1等尖端推理模型不相上下。
50美元复刻一个DeepSeek,这简直是逆了三十三重天。
不过,也有观点指出,s1是通过蒸馏法由谷歌的Gemini2.0 Flash Thinking Experimental提炼出的。
那么事实到底是怎样的?s1模型的原理是什么?怎样得出50美元成本的?
三言查看了s1论文,发现这可能又是被“震惊体”们给夸大了。

论文摘要中写道:测试时间缩放是一种很有前景的语言建模新方法,它利用额外的测试时计算资源来提高性能。
最近,OpenAI的o1模型展示了这种能力,但未公开其方法,引发了许多复现尝试。我们寻求实现测试时间缩放和强大推理性能的最简单方法。
首先,我们精心整理了一个包含1000个问题的小数据集s1K,这些问题都配有推理过程,筛选时依据三个经过消融实验验证的标准:难度、多样性和质量。
其次,我们开发了 “预算强制” 方法,通过在模型尝试结束时强制终止其思考过程,或多次向模型的生成内容中追加 “等待” 来延长思考时间,从而控制测试时的计算量。
这能让模型对答案进行二次检查,常常能修正错误的推理步骤。在使用s1K对Qwen2.5-32B-Instruct语言模型进行有监督微调,并为其配备 “预算强制” 功能后,我们的模型s1-32B在竞赛数学问题
(MATH 和 AIME24)上的表现比o1-preview高出27%。
此外,对s1-32B使用 “预算强制” 方法进行扩展,能够在无测试时干预的情况下提升性能:在AIME24上的准确率从50%提高到57%。
在论文的摘要中,已经说明了是使用s1K对Qwen2.5-32B-Instruct语言模型(阿里云通义千问)进行有监督微调,并为其配备 “预算强制” 功能。
也就是说s1模型的训练并非从零开始,而是建立在已具备强大能力的开源基础模型之上。
引言中写道:尽管有大量对o1模型的复现尝试,但没有一个公开清晰地复现出测试时缩放行为。因此,我们提出疑问:实现测试时缩放和强大推理性能的最简单方法是什么?
我们展示了,仅使用1000个样本进行下一个标记预测训练,并通过一种简单的测试时技术 “预算强制” 来控制思考时长,就能得到一个强大的推理模型,其性能会随着测试时计算量的增加而提升。
具体来说,我们构建了s1K数据集,它由1000个经过精心筛选的问题组成,这些问题都配有从Gemini Thinking Experimental(Google,2024)提炼出的推理过程和答案。我们在这个小数据集上对一个
现成的预训练模型进行有监督微调(SFT),在16个H100 GPU上仅需训练26分钟。训练完成后,我们使用 “预算强制” 方法来控制模型在测试时花费的计算量。
这部分又提到,s1K数据集的1000个问题都配有从Gemini Thinking Experimental提炼出的推理过程和答案。并在s1K这个小数据集上对一个现成的预训练模型进行有监督微调。
这也再次说明,s1模型是借助了其他强大模型的能力。
从整篇论文来看,其主要的实验方法包括数据集策划、预算强制,以及测试时间扩展方法。
首先是策划一个包含1000个问题的小型数据集s1K。
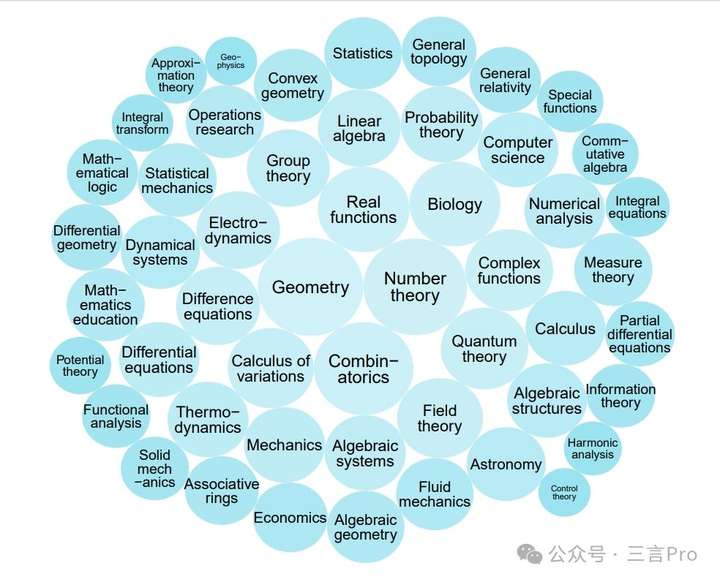
该团队基于质量、难度和多样性三个标准,从16个来源收集59029个问题,经API错误筛选、格式问题过滤等,最终确定1000个高质量样本,涵盖数学、科学等50个不同领域。
其次是预算强制。
预算强制原理是通过控制测试时的计算量(如思考标记数)来优化模型性能。
具体方法是在模型生成过程中,强制结束思考过程或延长思考时间,促使模型重新检查答案,修正错误推理步骤。
再就是测试时间扩展方法,分为顺序扩展和并行扩展。
顺序扩展是基于模型的中间结果逐步优化推理过程。
而并行扩展是通过多次独立生成解决方案并选择最佳结果来提升性能。
实验中的具体训练,是使用s1K对Qwen2.5-32B-Instruct进行有监督微调,16个H100 GPU上训练26分钟。
然后采用AIME24、MATH500和GPQA Diamond三个推理基准测试,将s1-32B 与多种模型对比。
最后得出结论,仅在1000个样本上进行监督微调并结合预算强制技术,即可构建出具有强大推理能力和测试时扩展能力的模型。
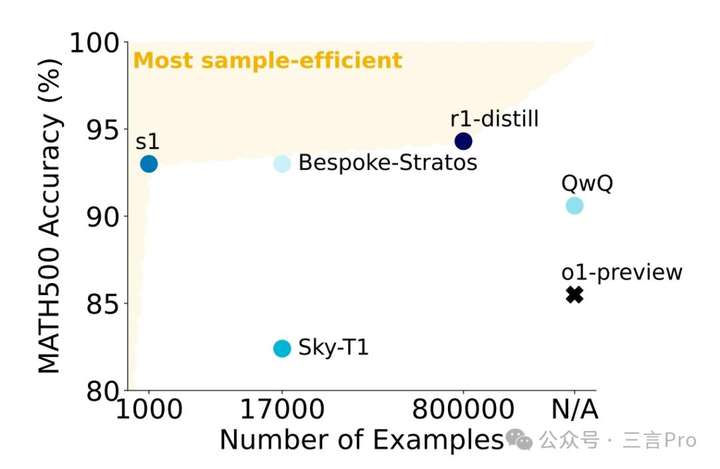
由此可见,s1模型的确有不俗的表现,但它是站在了巨人肩膀上的。
在通篇论文中,并未提到过50美元的成本。
而论文中有一句“训练在16个NVIDIA H100 GPU上只需26分钟”,这或许就是“50美元成本”的由来。
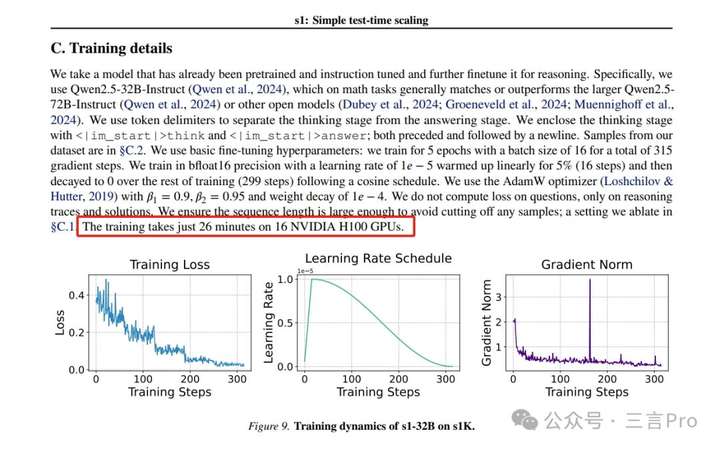
据财联社报道,“不到50美元”仅为云计算服务费用,不包括服务器、显卡等硬件投入费用,因这部分已经由云厂商承担。
“50美元复刻DeepSeek”这样的标题属实震撼,DeepSeek会如何看待这事呢?
笔者就此事向DeepSeek提了两个问题。
问题一:近日有媒体报道称,斯坦福李飞飞团队以不到50美元的成本训练出与OpenAI的O1,以及DeepSeek的R1等尖端推理模型不相上下s1模型,分析一下为什么会成本这么低?
斯坦福李飞飞团队以极低成本训练出与OpenAI、DeepSeek等顶尖模型性能接近的S1模型,这一突破可能由以下技术和管理因素驱动:
1.模型架构创新
参数高效设计:采用稀疏激活架构(如MoE)或动态计算机制(如自适应深度/宽度),在保持性能的同时减少计算量。
注意力机制优化:使用FlashAttention、分组查询注意力(GQA)等技术,降低内存占用和计算复杂度。
知识蒸馏:通过大模型指导小模型训练(如logit蒸馏、中间层特征对齐),提升小模型性能。
2.训练策略突破
数据高效利用:
基于主动学习的核心样本筛选(如使用不确定性采样)
合成数据生成(LLM生成高质量训练样本)
数据增强的对抗训练(如Diffusion模型生成变体)
优化算法改进:
二阶优化器(如Sophia)实现更快的收敛速度
动态批处理(根据梯度方差调整batch size)
课程学习与渐进式训练策略
混合精度3.0:结合FP8/FP16混合精度与梯度量化,内存效率提升4-8倍。
3.硬件利用革新
异构计算架构:
使用TPU/GPU混合集群,优化任务分配
利用消费级显卡(如RTX4090)的稀疏计算能力
弹性训练系统:
基于Kubernetes的动态资源调度
抢占式实例的容错训练(Checkpointing频率优化)
模型切片技术:通过ZeRO-Infinity实现超大规模模型参数卸载,单卡可训练参数量提升10倍。
此外,DeepSeek还列举了软件栈深度优化、理论突破支持、成本控制策略等原因。
潜在挑战与限制
这一突破标志着AI研发正在从"暴力计算"向"智能计算"转型,未来可能出现更多基于算法创新的低成本模型。不过实际产业落地仍需考虑推理成本、部署复杂度等综合因素,建议持续关注后续技术细节披露和第三方复现结果。
问题二:你怎么看通过蒸馏监督微调进行模型训练?
不过,在问这一问题的时候DeepSeek出现了“宕机”现象,笔者多次尝试提问,而得到的回复一直是“服务器繁忙,请稍后再试。”
于是笔者通过纳米AI搜索App使用DeepSeek-R1-360高速专线提问这一问题。
DeepSeek回复称, 通过蒸馏(Distillation)进行监督微调(Supervised Fine-tuning)是一种有效的模型训练方法,尤其在模型压缩、迁移学习和提升模型性能方面具有显著优势。
DeepSeek还从技术背景与核心概念、优势与适用场景、潜在挑战与解决方案、典型应用领域、未来发展方向等 多个角度,对蒸馏以及监督微调进行了详细分析。
最后,DeepSeek还作出了以下总结:
通过蒸馏进行监督微调是一种高效且灵活的模型训练方法,能够在模型压缩、迁移学习和性能优化等多个方面带来显著收益。尽管该方法面临一些挑战,但随着技术的不断发展和创新,其应用前景将更加广阔。在实际应用中,需要根据具体任务需求和技术条件,合理设计蒸馏策略,并权衡计算成本与性能提升之间的关系。
关于s1模型成本低的原因,DeepSeek的分析中也提到了蒸馏。 DeepSeek还详细的分析了蒸馏的优势和存在的挑战。
蒸馏和监督微调的结合,DeepSeek也给予肯定。
事实上,很多主流大模型也都用过数据蒸馏的方法。比如,DeepSeek-R1模型使用了强化学习和大规模数据蒸馏,Kimi k1.5也使用了强化学习和大规模数据蒸馏。
这也证明,蒸馏在模型训练中是一种经常被用到的方式。
据报道,阿里云证实,李飞飞团队以阿里通义千问Qwen2.5-32B-Instruct开源模型为底座,在16块H100GPU上监督微调26分钟,训练出新模型s1-32B,取得了与OpenAI的o1和DeepSeek的R1等尖端推理模型数学及编码能力相当的效果,甚至在竞赛数学问题上的表现比o1-preview高出27%。
s1模型这一案例,或许会给未来的研究提供一定的方向。
不过,蒸馏毕竟是建立在强大开源模型的基础之上,并非小模型的自身能力。
“50美元复刻DeepSeek”这样的标题,属实有些“震惊体”了。
文章来自于微信公众号“三言财经”(ID:sycaijing),作者“大鹏”




【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】kimi-free-api是一个提供长文本大模型逆向API的开渔免费技术。它支持高速流式输出、智能体对话、联网搜索、长文档解读、图像OCR、多轮对话,零配置部署,多路token支持,自动清理会话痕迹等原大模型支持的相关功能。
项目地址:https://github.com/LLM-Red-Team/kimi-free-api?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
