# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
大模型也学会了「空间想象力」?还可以自己解释自己?
在大语言模型(LLMs)和多模态大语言模型(MLLMs)中,思维链(CoT)在复杂推理方面非常有效。
然而,对于复杂的空间推理,CoT表现不佳。
但人类的认知能力不仅限于语言,还能够同时用词语和图像推理。
受这一机制的启发,来自微软研究院、剑桥大学和中科院的研究人员,在思维链提示的基础上,提出了空间推理(spatial reasoning)新范式:多模态思维可视化
(MVoT)。

论文地址:https://arxiv.org/pdf/2501.07542
将思维链(CoT)扩展到多模态模型,已有的方法尽管能够处理文本和图像,但或者严重依赖于独立的视觉模块或外部工具,难以适应更复杂的空间推理任务;或者
可视化太过简化,推理过程难以理解。
论文作者Chengzu Li在X上解释MVoT的核心设计理念:「MVoT超越了思维链(CoT),可以让AI利用生成的视觉图像去想象它的思考。通过融合语言和视觉推理,
MVoT使复杂问题的解决变得更加直观、可更具解释性、更加强大。」

具体而言,MVoT要微调自回归多模态大语言模型(MLLM)。为了提升推理过程的可视化质量,引入了token差异损失,弥补了分别训练的分词器(tokenizer)的差
距。
文章亮点:
架构

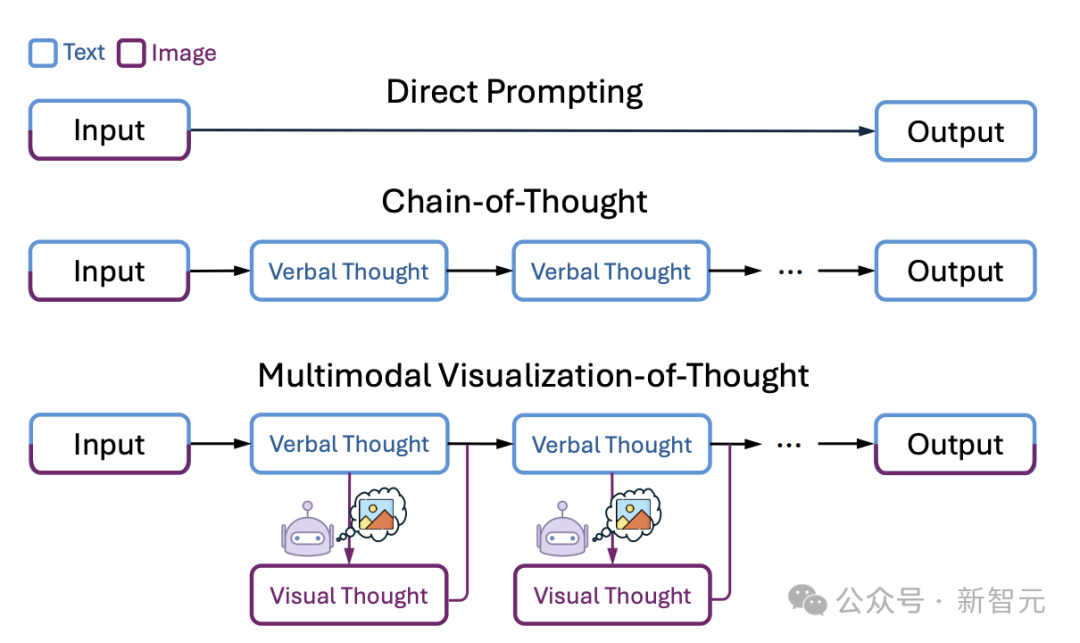
图1:多模态思维可视化(MVoT)推理过程与其他方法的对比
多模态思维可视化(MVoT)让多模态大语言模型(MLLMs)能在不同模态之间生成交织的推理轨迹。
传统的CoT仅依赖于语言思维,而MVoT则通过促进视觉思维来可视化推理轨迹。
这个推理范式类似于人类的认知方式,能够无缝地在文字和图像之间进行思维。
训练
多模态序列建模如图3所示,使用Chameleon的架构,利用统一的Transformer来处理图像和文本token。
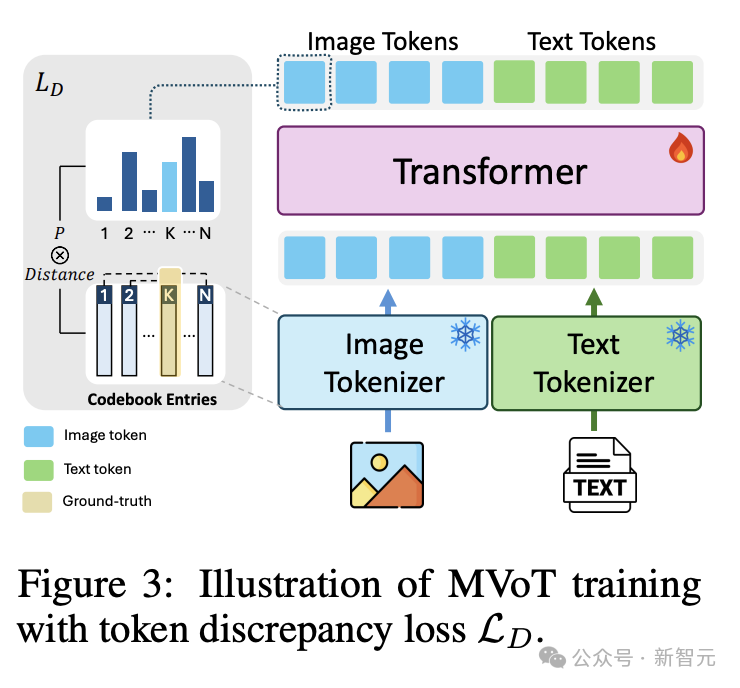
该架构集成了两个tokenizer:图像tokenizer使用离散的码本(codebook)将输入图像编码为一系列图像token;文本tokenizer则将文本数据映射为相应的token序
列。
这些token序列被连接在一起并由因果Transformer模型处理。

实验结果
作者在三个动态空间推理任务中进行大量实验,验证了MVoT的有效性。
MAZE和MINIBEHAVIOR聚焦于与空间布局的交互,而FROZENLAKE强调在动态环境中的细粒度模式识别。
实验结果表明,MVoT在任务中的表现具有竞争力,在高难度的FROZENLAKE场景中,MVoT的表现比传统的思维链(CoT)高出了20%多。
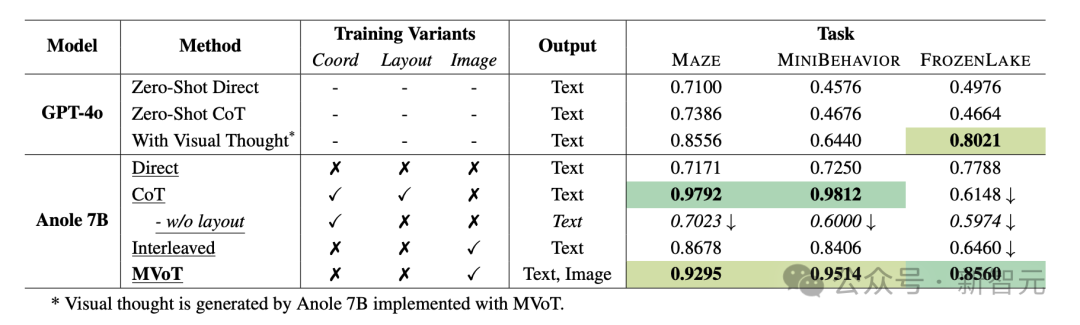
不同系统变体在任务中的实验结果。
三个模拟任务的实验结果表明,Direct存在过拟合问题,准确率约为70%。GPT-4o的表现更差。相比之下,MVoT展现出不断的改进。
在MAZE和MINIBEHAVIOR上,MVoT的准确率超过90%,可与CoT相媲美。
而在FROZENLAKE上,MVoT的准确率为85.60%,优于Direct和CoT。
这表明MVoT比CoT拥有更好的稳定性和稳健性。
此外,MVoT还提供了语言和视觉形式的中间推理状态,可以更清晰、更直观地理解推理过程。
图4展示了FROZENLAKE中生成图像的正确与错误示例。
可视化生成的错误分类如下:
(1)错误可视化(Wrong Visualization):生成的可视化内容不准确。
(2)多余图形(Redundant Patterns):在预期修改区域外可视化了不必要或无关的图形。
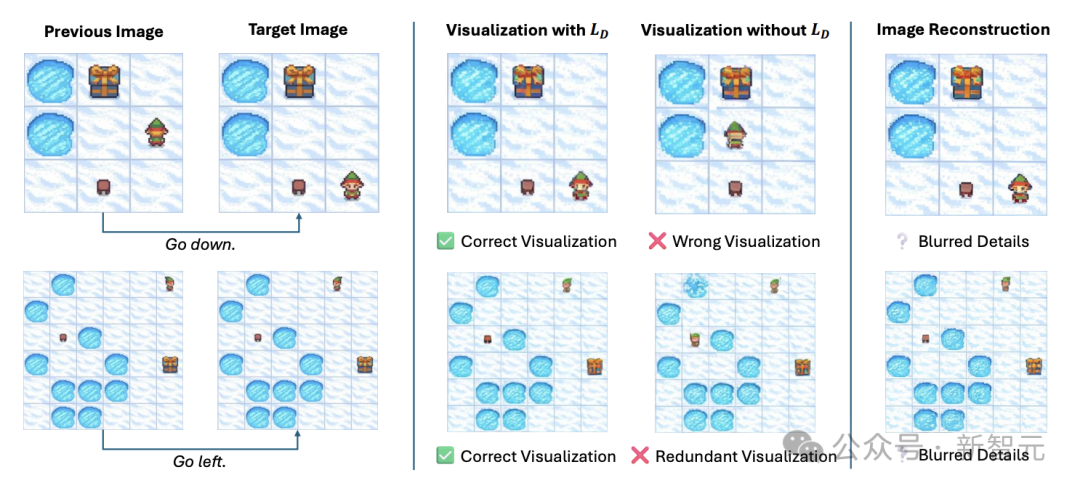
图4:定性分析示意图。
此外,与MAZE和MINIBEHAVIOR相比,在FROZENLAKE任务中,观察到随着模式复杂度的增加,生成图像的细节经常会变得模糊。
在重建的图像与原始图像之间也观察到类似的差异。
这种变异性经常导致细粒度细节的丢失或扰动,反映了MLLM在表达能力上的局限性。
为了评估生成的视觉推理的质量,基于已识别的错误类型定义了自动化评估指标:
作者报告了MAZE和MINIBEHAVIOR中可视化位置的定量结果,如下所示。
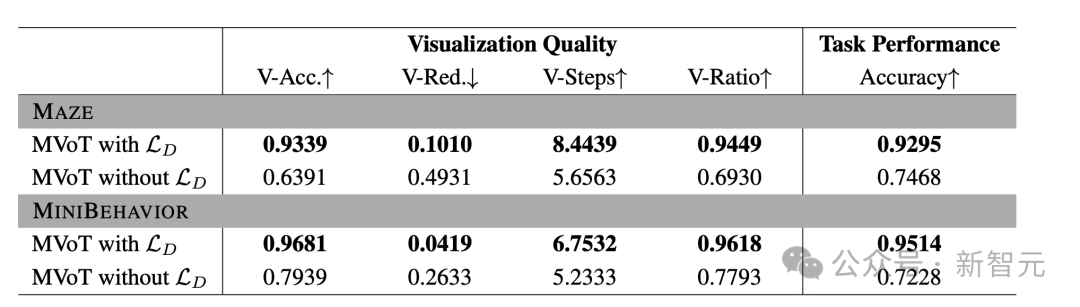
表3:token差异损失对MVoT视觉思维定量指标的影响
上图中,最佳结果以加粗形式标出。带有↑的指标表示值越高性能越好,反之亦然。

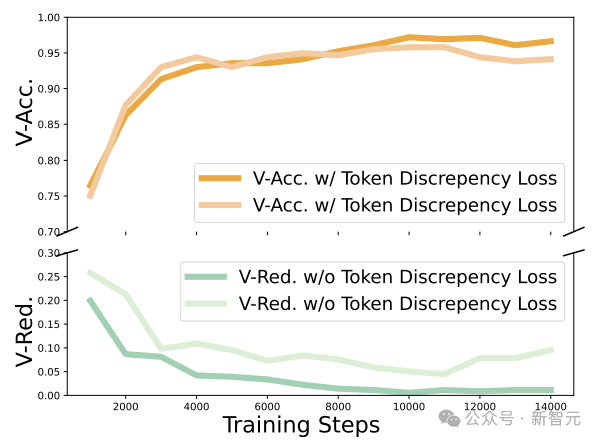
图5:MAZE在不同训练周期的定量指标
MVoT在推理中与CoT的能力可以互相补充。
正如作者Chengzu Li所言:「MVoT不会取代CoT,而是提升了CoT。通过组合MVoT和CoT,多模态推理和语言推理的协同作用解锁了性能上限,证明两种推理范式可能比一种更好!」

在两种方法的组合中,如果MVoT或CoT中的任一方法生成了正确的预测,则认为该数据点正确。
如表4所示,在MAZE和MINIBEHAVIOR上,上限性能达到了接近100%的准确率;在FROZENLAKE上,达到了92%的准确率。
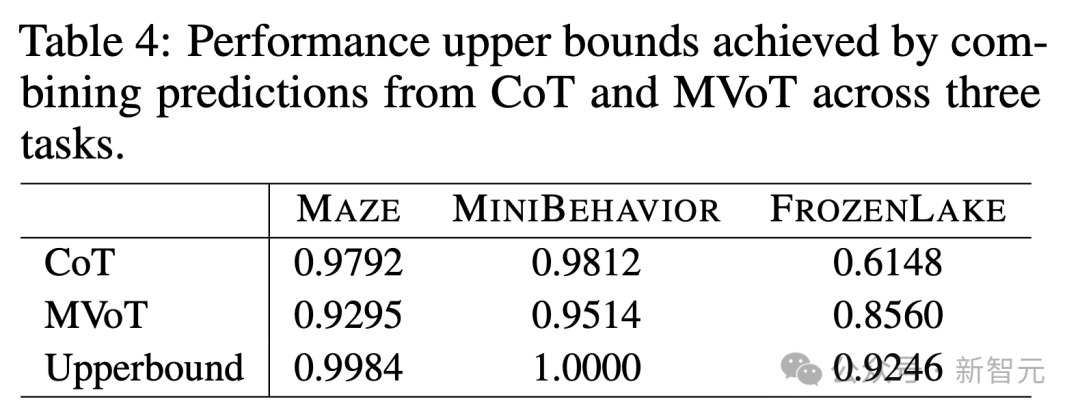
表4:通过组合CoT和MVoT在三个任务中的预测所达到的性能上限。
文中也讨论了消融实验,并在附录中给出了更多的实验细节。
当然,这项研究也有局限性,作者建议借鉴扩散模型中的图像生成技术,作为未来改进的方向。
此外,在推理过程中,显式生成可视化会引入计算开销。
为了解决这一问题,作者倡导进一步研究使用更少token的紧凑的图像表示,以降低可视化生成的计算成本。
作者介绍

共一作者Chengzu Li在微软研究院实习时参与了全程工作。目前,他是剑桥大学语言技术实验室的计算、认知与语言学博士生。在攻读博士学位之前,他在剑桥大学
计算机科学系获得了高级计算机科学硕士学位。他本科就读于西安交通大学自动化专业。

共一作者Wenshan Wu, 目前是微软亚洲研究院(MSRA)的高级研究软件开发工程师。之前,曾在腾讯担任软件工程师。她从中国科学院获得了硕士学位。
参考资料:
https://arxiv.org/abs/2501.07542
https://x.com/li_chengzu/status/1879168974988173573
文章来自于微信公众号 “新智元”,作者 :KingHZ



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
