# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文是北京大学彭宇新教授团队在细粒度多模态大模型领域的最新研究成果,相关论文已被 ICLR 2025 接收,并已开源。
尽管多模态大模型在通用视觉理解任务中表现出色,但不具备细粒度视觉识别能力,这极大制约了多模态大模型的应用与发展。
细粒度视觉识别旨在区分同一粗粒度大类下的不同细粒度子类别,如将鸟类(粗粒度大类)图像区分为西美鸥、灰背鸥、银鸥等(细粒度子类别);将车区分为宝马、奔驰、奥迪等,奥迪区分为 A4、A6、A8 等;将飞机区分为波音 737、波音 747、波音 777、空客 320、空客 380 等。实现对视觉对象的细粒度识别,在现实生产和生活中具有重要的研究和应用价值。
针对这一问题,北京大学彭宇新教授团队系统地分析了多模态大模型在细粒度视觉识别上所需的 3 项能力:对象信息提取能力、类别知识储备能力、对象 - 类别对齐能力,发现了「视觉对象与细粒度子类别未对齐」是限制多模态大模型的细粒度视觉识别能力的关键问题,并提出了细粒度多模态大模型 Finedefics。
首先,Finedefics 通过提示大语言模型构建视觉对象的细粒度属性知识;然后,通过对比学习将细粒度属性知识分别与视觉对象的图像与文本对齐,实现数据 - 知识协同训练。
Finedefics 在 6 个权威细粒度图像分类数据集 Stanford Dog-120、Bird-200、FGVC-Aircraft、Flower-102、Oxford-IIIT Pet-37、Stanford Car-196 上的平均准确率达到了 76.84%,相比 Hugging Face 2024 年 4 月发布的 Idefics2 大模型提高了 10.89%。

背景与动机
多模态大模型是指提取并融合文本、图像、视频等多模态数据表征,通过大语言模型进行推理,经过微调后适配到多种下游任务的基础模型。
尽管现有多模态大模型在视觉问答、推理等多种任务上表现出色,但存在识别粒度粗的局限性:因为多模态大模型的视觉识别能力依赖大量训练数据,由于训练数据的细粒度子类别的标注成本巨大,实际也是无法细粒度标注的,导致现有多模态大模型缺乏细粒度视觉识别能力。
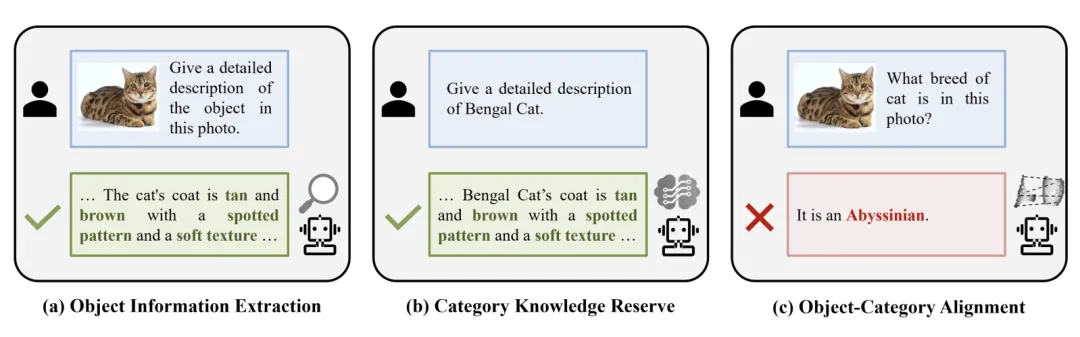
图 1. 多模态大模型在细粒度视觉识别上所需的 3 项能力
本文系统地分析了多模态大模型在细粒度视觉识别上所需的 3 项能力,如图 1 所示,包括:
1. 对象信息提取能力:视觉编码器能够从图像中准确并全面地提取区分不同细粒度子类别的辨识性信息;
2. 类别知识储备能力:大语言模型能够储备充分的细粒度子类别知识;
3. 对象 - 类别对齐能力:基于提取的辨识性视觉信息与储备的细粒度子类别知识,在大语言模型的表征空间中对齐视觉对象与细粒度子类别,以建立输入图像到子类别名称的细粒度映射关系。
实验结果表明,「视觉对象与细粒度子类别未对齐」是限制多模态大模型具备细粒度视觉识别能力的关键问题。
技术方案
为解决视觉对象与细粒度子类别未对齐的问题,本文提出了细粒度多模态大模型 Finedefics。
如图 2 所示,Finedefics 构建过程包含 2 个主要步骤:
1. 首先通过属性描述构建,利用辨识属性挖掘获得区分细粒度子类别的关键特征,例如区分猫的品种的辨识性属性「毛色」、「毛型」、「毛皮质地」等,并利用视觉属性提取获得图像对象的辨识性属性对,例如「毛色:棕褐色」、「毛型:带有斑纹」、「毛皮质地:质地柔软」等,再利用属性描述总结将属性对转化为自然语言形式的对象属性描述,例如「图中小猫的毛为棕褐色,带有斑纹,质地柔软」;
2. 然后通过属性增强对齐,将构建的对象属性描述作为视觉对象与细粒度子类别的共同对齐目标,通过对象 - 属性、属性 - 类别、类别 - 类别对比学习充分建立视觉对象与细粒度子类别的细粒度对应关系,再利用以识别为中心的指令微调促进模型遵循细粒度视觉识别的任务指令。具体地,包含如下两个训练阶段:
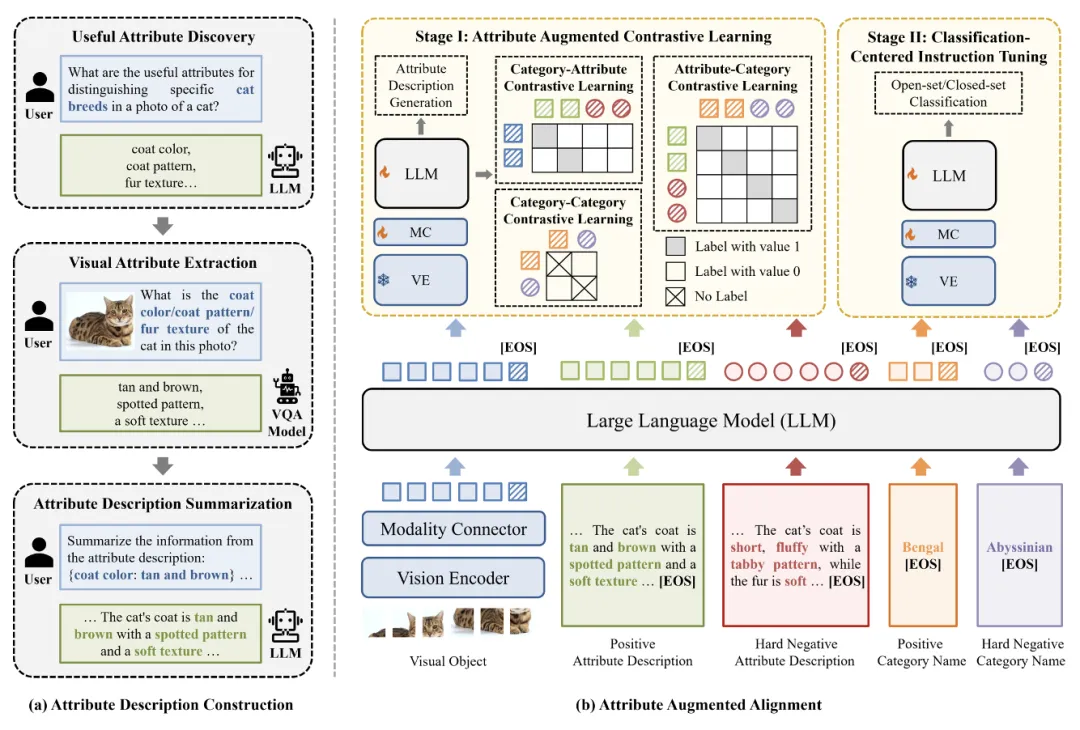
图 2. 细粒度多模态大模型(Finedefics)框架图
阶段 I:属性增强的对比学习


因此,引入困难负样本后的对象 - 属性对比(Object-Attribute Contrastive, OAC)损失表示如下:
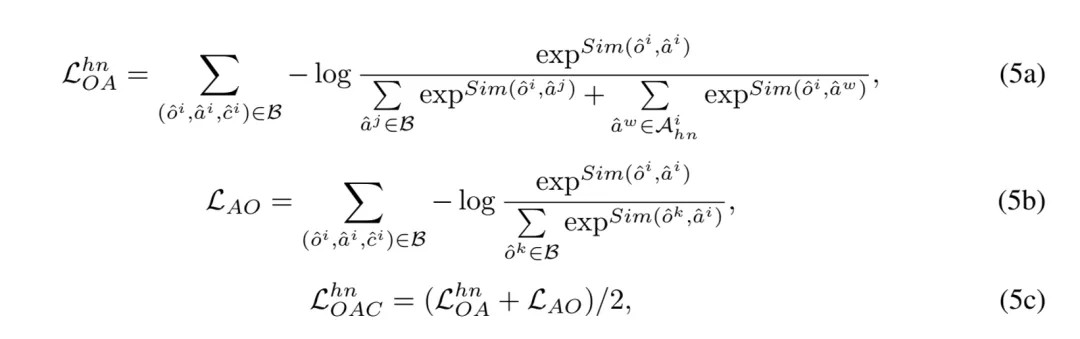

属性 - 类别对比:相似地,引入困难负样本后的属性 - 类别对比(Attribute-Category Contrastive, ACC)损失表示如下:
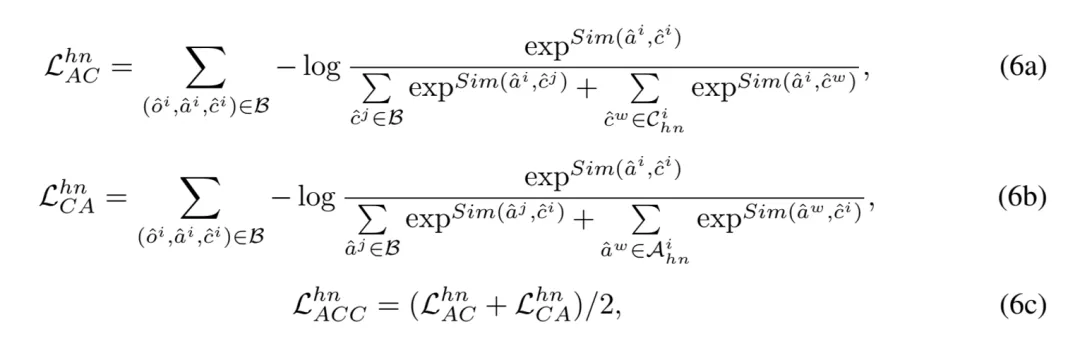

类别 - 类别对比:由于难以在大语言模型的表征空间中区分不同细粒度子类别,提出了类别 - 类别对比(Category-Category Contrastive, CCC)损失如下:
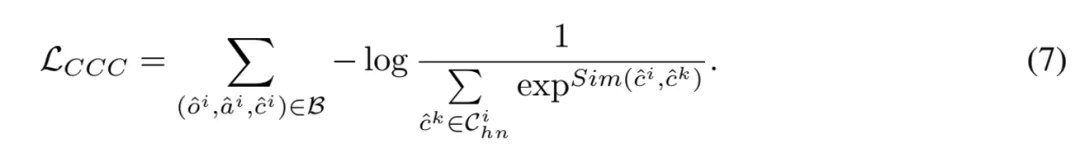
此外,为保持模型的生成能力,将属性描述作为生成目标,采用下一个标记预测(Next Token Prediction)任务进行模型训练。因此,阶段 I 的优化目标定义如下:
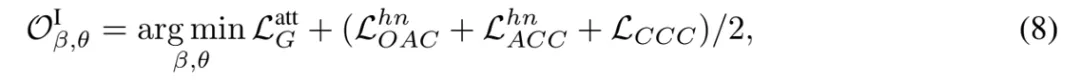

阶段 II:以识别为中心的指令微调
将细粒度视觉识别数据集构建为两种形式的指令微调数据:开集问答数据与闭集多选题数据,利用上述指令微调数据更新模型参数。因此,阶段 II 模型的优化目标定义如下:


实验结果
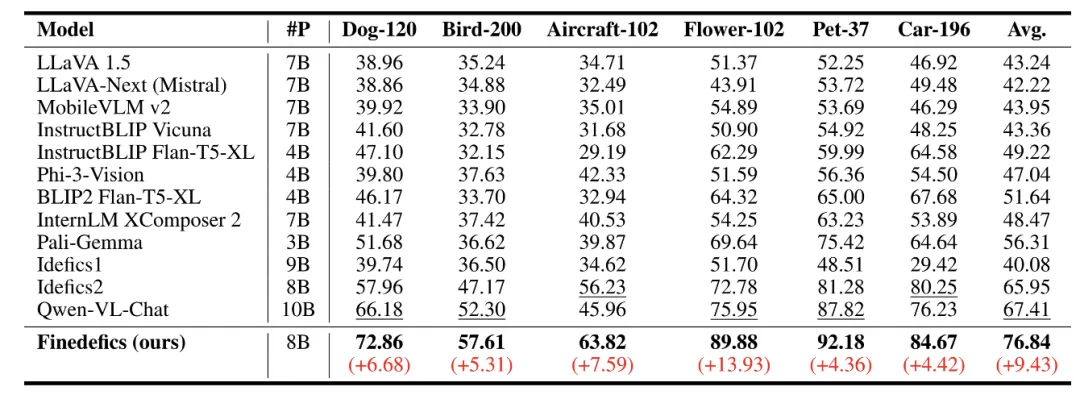
表 1. 细粒度多模态大模型(Finedefics)实验结果
表 1 的实验结果表明,Finedefics 在 6 个权威细粒度图像分类数据集 Stanford Dog-120、Bird-200、FGVC-Aircraft、Flower-102、Oxford-IIIT Pet-37、Stanford Car-196 上的平均准确率达到了 76.84%,相比阿里 2024 年 1 月发布的通义千问大模型(Qwen-VL-Chat)提高了 9.43%,相比 Hugging Face 2024 年 4 月发布的 Idefics2 大模型提高了 10.89%。
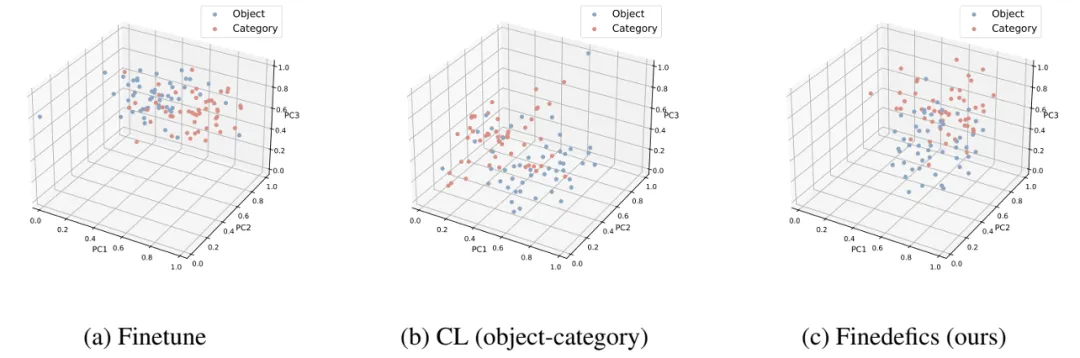
图 3. 视觉对象 - 细粒度子类别对齐效果可视化

图 4. 细粒度多模态大模型(Finedefics)案例展示
图 3 的可视化结果表明,(a)仅微调大模型,视觉对象与细粒度子类别表征的分布差异大;(b)仅引入对象 - 类别对比学习时,上述分布差异仍然难以降低;(c)同时引入对象 - 属性、属性 - 类别、类别 - 类别对比学习时,分布差异显著降低,优化了视觉对象与细粒度子类别的对齐效果,提升了多模态大模型的细粒度视觉识别能力。
图 4 的案例展示表明,相较于 Idefics2,本方法 Finedefics 能成功捕捉视觉对象特征的细微区别,并将其与相似的细粒度子类别对象显著区分。
文章来自微信公众号 “ 机器之心 ”,作者 彭宇新教授团队




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
