# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
一些推理模型的使用技巧和启示
大家好,我是很帅的狐狸🦊
最近玩了一波DeepSeek‑R1等推理模型,竟然发现它们有潜力颠覆我们的沟通、工作、甚至投资的方式——

今天我打算跟大家唠唠,如何高效驾驭R1这类模型,同时让它们启发我们在工作、沟通和投资上的新思维。
前阵子,一个创业的朋友跟我吐槽:员工老是一通微信轰炸,信息没头没尾,重点模糊。
她跟我一样,曾在外企/专业服务机构混过,邮件沟通那种条理和仪式感让人舒服。
而现实中,大部分打工人还是习惯用微信/飞书/钉钉——
据2017年企鹅智库对2万人的调研,80%+的人用微信办公,而用邮件的却只有22.6%。
这也造就了我们短平快、高频的沟通习惯。
这种沟通的单次信息密度很低,很像我们之前跟GPT-4o/豆包/Kimi们的对话——
你给了点背景知识,让AI出个方案或图表,它立马就有输出。
如果有哪里不满意,就让它一遍遍改,改到咱满意为止。
而DeepSeek-R1等推理模型要是也这么「对话式交互」的话,效率就大打折扣了——
每次提问都要深度思考,哪怕问个「2022年中国GDP是多少」,也得等上16秒。


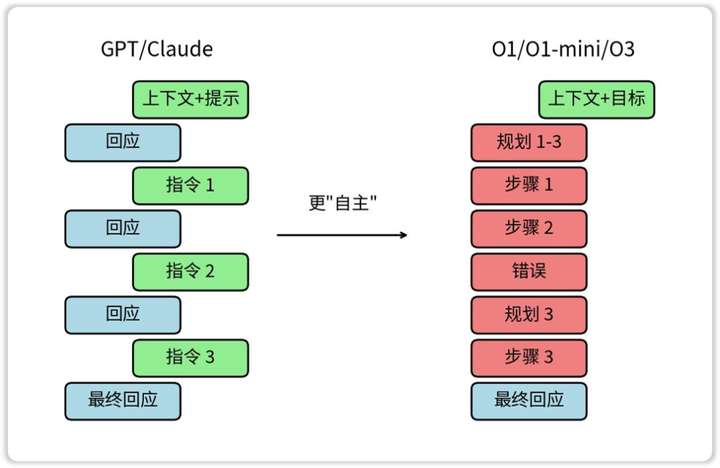
所以针对R1等推理模型,更适合的做法是更清晰的「邮件式交互」。
我们需要在长邮件中,把你要完成的任务描述得尽可能清楚。
截图/
前几天我看了技术播客Latent.Space的一期节目《o1不是一个聊天模型(o1 isn’t a chat model)》(OpenAI的o1是第一个会深度思考的推理模型)。
播客节目里头介绍了一种o1的提问模板——
目标:你的目标是什么?
格式:你期待的是什么交付格式?
注意要点:解决过程中有哪些坑是必须避开的?
背景信息:所有你认为可能会影响答案的背景都得给上!

截图/
顺带一提,根据OpenAI官方的提示词指导,如果给提问加上XML标签会提高表现。
比如可以这么提问——
<目标>给我推荐5个可以稳健增值财富的资产类别,并帮我分配好投资比例。</目标>
<格式>请以通俗易懂的语言、以表格的形式给到我方案。</格式>
<注意要点>我希望可以不影响目前的生活水平。</注意要点>
<背景信息>目前我是一个生活在中国的单亲妈妈,我手头上有100万人民币,每个月收入1万人民币、支出9千人民币,是个什么都不懂的理财小白,我的风险偏好很低。投资周期我希望可以在10年内,因为10年后我想把这笔钱留给女儿。</背景信息>
「邮件式交互」的沟通方式也适用于同事间的沟通(即使仍是在微信/钉钉/飞书上)——
毕竟AI任劳任怨可以24小时随时回复,但对其他同事也一来一回地「对话式交互」的话,那对方的工作会被频频打断。

o1和R1等推理模型有一个先天缺陷——脑补能力过强。

推理模型很擅长的是「自包含问题」,比如数学、代码之类的理工科题目——题面里所有已知条件都有了,它只要负责思考就可以了。
但如果我们的问题还需要很多额外的背景知识,最好一次性都丢给它。

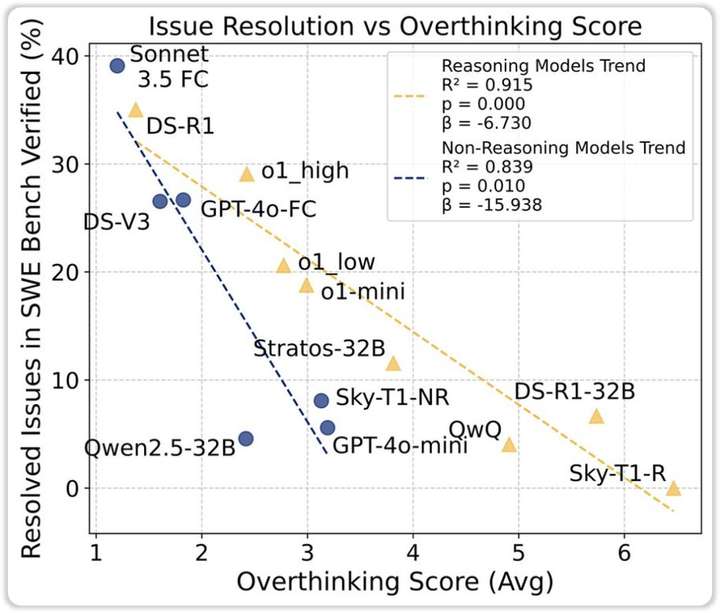
伯克利的Alejandro Cuadron等人在论文《过度思考的危险》(The Danger of Overthinking)里,把这个缺陷称为「推理-行动两难」——
他们让各个模型去尝试解决真实世界的代码问题(SWE-Bench测试集)。
要解决这些真实存在的代码问题,需要去搜集背景信息(比如看整个程序的所有相关代码,比如去阅读各个库的说明文档等等)。
而现实世界的问题,不是「已知XXX,求XXX」,很多信息需要自己去找。
而测试下来,推理模型会自己脑补各种背景信息,所以往往无法顺利解决真实世界的问题(因为脑补的信息跟真实需求对不上)。
所以就跟人类闭门造车一样,AI想得越多,表现越差。
截图/
换句话说,当你跟推理模型沟通时,如果不想它不受控地脑补,就把该给的所有背景信息都给到。
一个有意思的做法,是先用手机录音,碎碎念所有的背景信息,然后再把语音转文字,跟指令一起发给AI。
这有点像我们对待公司的新人——
可能会花一整个下午的时间,跟TA碎碎念公司做的业务、过各种数字……
而反过来,当我们融入一个新环境、接受一份新工作、迎接一个新客户时,在开始工作前,一定要尽可能地先搜集自己需要知道的各种背景信息。
以前我在麦肯锡的时候,有些领导会吐槽我「阳奉阴违」——
他们会比较micro-manage,会给我一套「标准流程」,让我照做。
而我总是秉承「只要结果一样work,怎么做不是很重要」的心态,用自己的方法把工作给做了。
类似的,我之前在某Fintech公司时,同事来自各行各业——有的之前在互联网大厂,有的之前在金融机构,有的之前在快消公司……
每个人的工作方式都非常不一样。
如果限制他们,要求只能咨询公司的工作方法,那影响产出效率是一方面,另一方面也不能发挥每个人的专长。

类似的,当我们让DeepSeek-R1等推理模型工作时,最好也把提问聚焦在「我要的结果是什么」上。
至于「如何实现我要的结果」,咱不用过度干预。
使用以前的GPT模型时,我们会习惯说「现在你是一个资深的基金经理」之类的提示词,这个提示词现在放在R1或o1上,效果反而不一定有以前好。

这一点主要是为了应对R1比较严重的「幻觉问题」。
所谓「幻觉」,也就是AI「一本正经地胡说八道」。
比如虎嗅就提到,让DeepSeek制定成都游玩攻略时,它推荐了在杜甫草堂旁边的「川纳万海」咖啡馆,不过实际上这家咖啡馆距离杜甫草堂8.8公里。
R1的幻觉有多严重呢?
根据休斯幻觉评估模型(HHEM)的评测,R1的幻觉率高达14.3%。
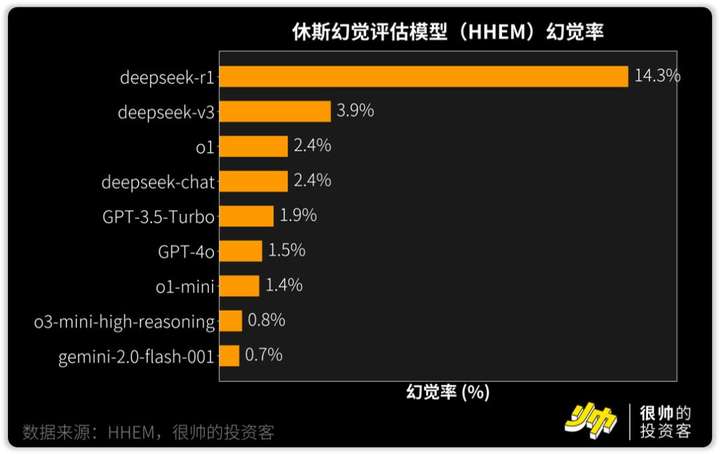
这个幻觉评估测试,主要是让模型对文本进行总结摘要。
有时候我让R1总结一些PDF报告,它也会说出一些报告里头没有的细节。

这跟R1的训练过程有关——
R1在训练理工科题目时,因为大多有标准答案,所以幻觉不严重。
但R1在训练文科题目时(写作/事实问答/自我认知/翻译),用的是V3模型的监督微调数据,也会让V3模型来生成一些数据。
目前看来,V3模型会鼓励创造性多一点。

但过度创造就是「编造」了,所以如果用R1来做报告的话,查证事实方面要下点功夫。
类比投资,我们平时在各个社群会接收到大量未经验证的「小作文」。
只是盯着小作文进行投资,很容易就成了那个帮人抬轿子的工具人。
所以收集数据和信息时,千万要重视数据和事实的查证。
不然你的结论可能与事实相距甚远。
再多说几句投资——
就像美银说的,DeepSeek是中概股的「阿里IPO时刻」——2014年阿里上市带动了中国「新经济」板块的崛起,吸引了全球长期资本的流入。
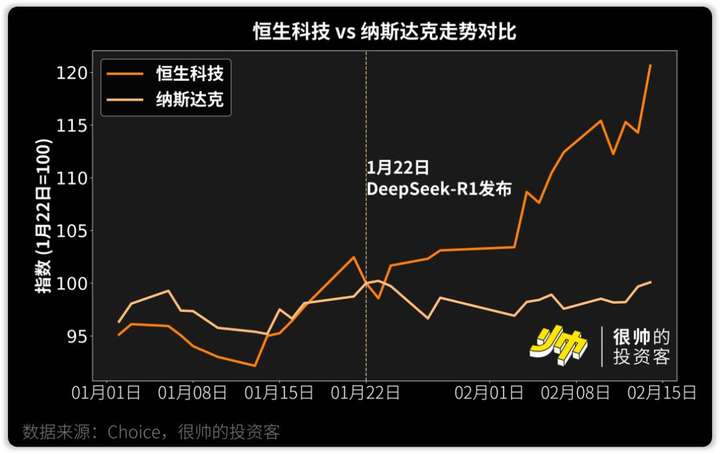
前几天看到华创证券还特意写了份报告,统计了ETF中的DeepSeek含量。
一级行业里头,像是计算机ETF南方(159586)追踪的指数就覆盖了最多DeepSeek概念股(47/90)。
宽基方面,像是科创50ETF南方(588150)追踪的指数也覆盖了19.8%,接下来是159780追踪的科创创业50(占比11.1%)和530580追踪的上证180(占比8.1%)。
有意思的是,微信接入DeepSeek后,甚至连腾讯也被当成DeepSeek概念股了。
今天刷雪球,也看到有人在困惑:同是接入DeepSeek,为啥腾讯涨了百度却跌了?
答案也很简单——
其实百模大战里,到尾声的时候,大模型能力已经没那么重要了(同质化很严重)。
就像Google之前对自己和OpenAI的评价——「我们没有护城河,OpenAI也没有。」
哪个大模型更好用,用户就会切换过去,而且并没有什么切换成本。
就算是Agent也是一样的——如果现在有比Perplexity和Cursor更好用的产品,那我也会瞬间切换过去。
在这个阶段,反而是场景和数据更重要。
像马化腾说的,工业革命早一个月把电灯泡拿出来,在长的时间跨度上来看是不那么重要,关键要把底层算法、算力和数据扎扎实实做好,而且更关键的是场景落地。
场景的机会,目前的坑都被大厂给占了,别人暂时也抢不走。
就像我 之前 说的,当你的「AI+」场景带来的价值增量,并没有高于迁移成本时,用户宁愿坐等现有APP厂商,看看过几个月它们能不能迭代出AI能力。
而微信拥有大量的公众号文章数据,在信息检索效率方面比错失了移动端机会的百度还是甩了几条街的。
类似的还有小红书和B站。
而且信息搜索本身是百度的基本盘,本来大家还指望着它靠文心一言等AI产品逆风翻盘,现在相当于这个故事也讲不通了。
《Google “We Have No Moat, And Neither Does OpenAI” – SemiAnalysis》
《逐浪AIGC丨腾讯大模型缘何慢半步?“混元”主打应用 - 21财经》
《#DeepSeek出... - @投中网的微博 - 微博》
《基于GitHub的大模型能力评估数据集:SWE-BENCH - 知乎》
《ETF中的DeepSeek含量|ETF_新浪财经_新浪网》
《DeepSeek R1 之后,重新理解推理模型》
《o1 不能用来 code 和 chat,那可以做什么》
《AI应用的前提,是解决DeepSeek的幻觉问题》
《HHEM Leaderboard - a Hugging Face Space by vectara》
《Reasoning with o1 - DeepLearning.AI》
《o1 isn’t a chat model (and that’s the point)》
《The Danger of Overthinking: Examining the Reasoning-Action Dilemma in Agentic Tasks》
《DeepSeek-R1超高幻觉率解析:为何大模型总“胡说八道”?- 华尔街见闻》
《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning》
《2017 WECHAT USER AND BUSINESS ECOSYSTEM REPORT》
《比起微信,西方人为何更喜欢用邮件沟通工作?|界面新闻》
文章来自于“狐狸君raphael”,作者“很帅的狐狸”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
