# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

AlphaFold 3 获得诺贝尔奖是 AI 智能重要的里程碑,让我们有信心类似 AlphaFold 的模型能为接下来十年的科学和生物结构发现起到关键作用。这个问题已经困扰
了学界 50 余年,如果我们用计算机软件类比药物设计,蛋白质序列是一串代码,预测蛋白质的折叠结构则是把代码编译为一个可执行的代码文件,AI 模型在这个高
维空间有着比人类专家更高的上限。
Chai Discovery 这家公司正是在 AlphaFold 方向上复现开源最快的公司,获得了 Thrive 和 OpenAI 3000 万美金的种子轮投资,估值达到 1.5 亿美金。他们的模型
Chai-1 选择的技术路线是用 Diffusion 模型做结构预测,和 AlphaFold 路线接近。
这是一个竞争激烈的领域,正在上演 Scaling Law 的验证和落地。竞争对手 EvolutionaryScale 的 Transformer 模型已经达到了 98B,把文本模态对结构功能的解读
也融入了更大的生物模型中。但是在结构预测上,不到 1B 的 Chai-1 相比于 98B 的 ESM-3 仍然能够在结构预测上取得领先。我们认为短期内沿着 Diffusion 路线的
scaling 是在领域落地上更可行的,长期我们期待 scaling law 的全方位智能提升。而 Chai 的创始人是 ESM 模型的早期贡献者,在 Scaling Law 成立时也有能力切换
到 Transformer 模型路线。

目录
01 Why now?
02 药物研发的市场分析
03 Chai 的产品
04 技术路线
05 收费模式
06 竞争对手
07 团队及融资
Alphafold 3 作为诺奖级的成果,标志着基于深度学习的蛋白质结构预测方法的快速进步,大幅超过了传统的计算机辅助药物设计 (Computer-Aided Drug Design,
CADD)方法。而 Chai Discovery 是第一家迅速复现 AlphaFold 3 并开源发布的公司。
以靶标-配体结构预测为例,这个任务是药物有效性的重要判断依据,需要预测靶点(目标蛋白质)和配体(药物分子)之间的结合程度。通过预测蛋白质的三维结
构,来找到靶标-配体结构预测等任务的解法,是测算候选药物效果的关键因素,贯穿了药物研发的整个周期,对于推进新药研发至关重要。
传统算法中依赖 Autodock Vina 等基于力场的算法,通过模拟与搜索分子在受限空间内的最佳结合模式,从而预测配体与靶标的结合亲和力。Alphafold 3 在该任务
上表现超过传统的 Autodock Vina 方法至少 50%。
值得注意的是,AI for Drug Discovery 并不是一个新鲜的概念,上一波 AI 制药问题在于筛选出的药物经过验证仍然存在质量上的问题,长周期的临床实验对于药物
的实际落地还是颇有难度。18-21 年有一批 AI 制药初创公司都获得了大量融资,但是如今进展却不是很乐观,比如英国 AI 制药独角兽 Benevolent AI 由于主要候选
药物在临床 2a 期试验失败,裁员近 50 %。
我们对于 AIDD 的乐观在于智能的大幅提升:类似 Alphafold 3 的专用模型相比 5 年前的技术又有了巨大的提升,有希望将人工智能在药物筛选和优化过程中的实际
落地,同时 reasoning model 作为通用智能能为科学家的探索和试错提供很高的提效。这些进展都有望推动药物设计进入全新的计算驱动时代。
2025 年全球新药研发市场预计超过 3000 亿美金,复合增长率超过 9% [1]。一款新药平均的研发费用已经高达 23 亿美金,历时约为 10-15 年[2]。这个流程基于 AI
技术的加速,尤其是通过预测蛋白质的三维结构,来帮助进行潜在药物的筛选。
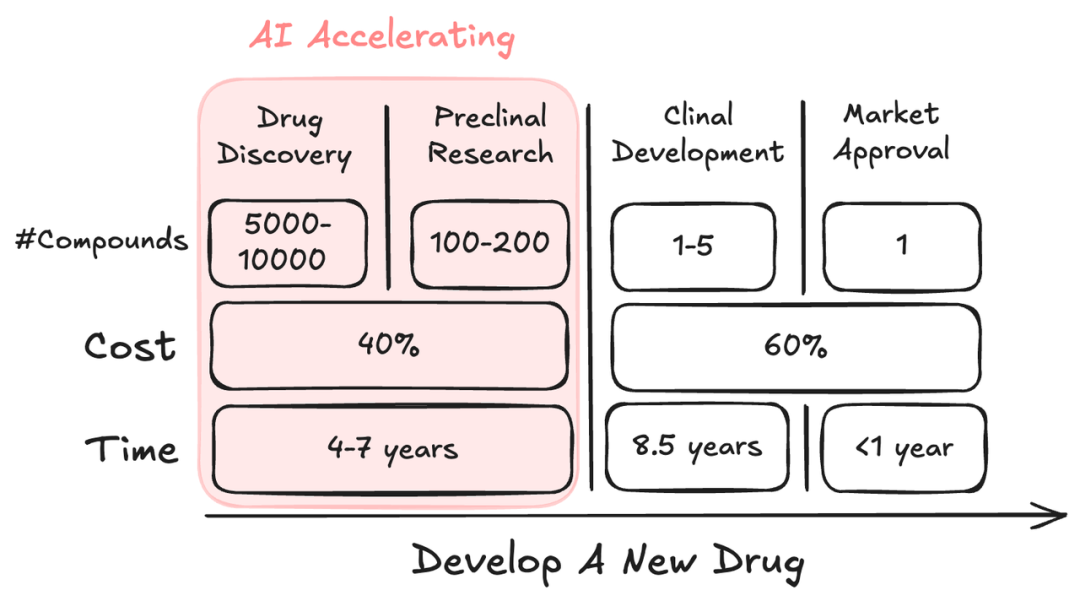
如下图所示,药物研发通常历经药物发现、临床前研究、临床研究和新药上市四个阶段。以小分子药物为例,在每个阶段都有一些 milestone 和任务需要完成:
• 药物发现阶段:在特定疾病相关的靶点得到确认之后,科学家需要从分子库中寻找先导化合物(即能够对靶点产生作用的物质)。之后再基于先导化合物进一步筛
选,再对化合物进行化学修饰来提高对靶点的亲和力,合成出数百个候选药物进入临床前研究阶段。
• 临床前研究:在临床前研究阶段还需要对候选药物的合成工艺、毒理等进行进一步的优化,只有在药理学、毒理学和大规模开发上都符合要求的化合物才能入选。
因此只会有一个或者数个分子能进入到临床实验阶段,临床实验取得成功后药物才能进入批准上市环节。
基于人工智能的蛋白质结构预测主要作用在药物发现与临床前研究阶段,因为在这些过程中需要不断的筛选、优化潜在的药物,药物与靶点的结合程度是筛选时的一
个重要判据。为了知道结合程度,就需要知道蛋白质的三维结构,也为人工智能预测蛋白质结构提供了广泛的应用机会。
在传统的工作流中我们需要数月甚至数年的时间才能了解一个蛋白质的结构。其具体实现方式是从各种不同角度用显微镜去看蛋白质的投影,来还原出一个好的三维
结构。这个经典的蛋白质折叠问题在生物学中已经存在了 50 多年,直到最近才可以用计算方式做到高精度的预测。
药物发现与临床前研究大约占据了药物研发全周期 40% 的投入,耗时约 4-7 年,我们期待人工智能技术能够大大降低这一环节的成本并加速研发周期 [3,4]。加速生
物医药发现的平台型公司,有可能成为新时代的 Shrodinger/ Illumina,这是我们研究 Chai Discovery 的初衷。
Chai Discovery 目前的唯一产品是 Chai-1,一个结构预测 foundation model。其核心功能和 AlphaFold 比较类似。可以根据用户给定的物质(包括蛋白质、小分
子、DNA、RNA 以及它们的组合)的序列文件,预测其三维构型并以 Pdb 文件的形式返回。类比计算机语言,氨基酸的序列可以认为是一段代码,而预测三维结构
就是要把代码编译成可执行的文件。
在产品形态层面,Chai-1 与竞争对手 EvolutionaryScale 或是 Isomorphic Labs 并没有本质的区别:均是作为软件平台,通过模型云上部署+提供网页/API 接口来提
供服务,在这一领域产品形态是收敛的因而模型本身的能力可能更为重要。Chai-1 可以进行药靶结构的预测,即根据靶标(蛋白质)+ 配体(小分子药物)的序列预
测该聚合物在三维空间结合的构型,从而得知其结合程度,而药靶的结合程度决定了该药物具有的药效。实际的制药流程中使用 Chai-1 通常按照如下的流程:
• 根据特定靶点,从分子库中利用 Chai-1 测得不同分子下药靶结合时的三维结构,根据物理方法计算结合能从而选择结合程度较好的药物分子。
• 进行亲和力实验、细胞实验等验证候选药物的有效性。
• 若前序步骤筛选出的候选药物分子不能满足要求,则药化专家可以基于当前的分子进一步优化设计新的分子,再利用 Chai-1 不断的计算结合程度,以确认经过优
化的药物是否满足要求。
上述过程会在药物研发过程中不断迭代。
此外,Chai-1 的一大特性是用户可以指定一些待预测物质的结构限制(比如某蛋白测得在某些位点与特定分子的距离小于 XX 距离),这些结构限制一般可以从文献
或实验中获得,从而使得预测结果可以在湿实验的帮助下更加准确。
Chai-1 有两种访问方式,第一种方式是通过 Chai 官方的网页端,以药靶结构预测为例,用户可以分别输入蛋白质的氨基酸序列和小分子的 SMILES 序列,即可提交
到 Chai-1 的服务器上进行结构预测,待一段时间后(通常需要数小时)用户便可查看结果,预测出来的结构以可视化的形式呈现并且可以直接下载结构文件。
Chai-1 的网页界面
另一种方式是通过 API 进行访问,Chai 与一系列云计算平台公司比如 Tamarind、LatchBio 和 Seqera(Tamarind 与 LatchBio 均是专注于与生物有关的计算技术的
云服务商,Seqera 是一家通用的云服务商)达成合作,在其上部署模型并提供给用户通过API的方式进行调用。类似于 OpenAI 的 GPT API,用户可以通过 Python
代码批量的提交待测的物质序列,等待服务器返回结果后,可以下载预测结果文件。
目前实现蛋白质结构预测的技术路径主要有两条:
1)基于 Diffusion Model 构建一个专用于结构预测的模型,
2) 基于 Transformer 构建一个通用的端到端生物大模型,结构预测作为其中一个可以用来完成的任务。
Chai 所采用的技术路线是第一条,与 Alphafold 3 的结构接近并在其基础上进行部分改进以进一步提高性能,其在2024年9月公布了 Chai-1 模型,实现了略微超过
Alphafold 3 性能,值得注意的是此时 Alphafold 3 尚未开源权重,因而 Chai Discovery 的技术团队展现出了不俗的技术能力,下面以 Chai-1 / Alphafold 3 和 ESM3
分别作为这两条路径的代表性工作,对这两条路径进行分析:
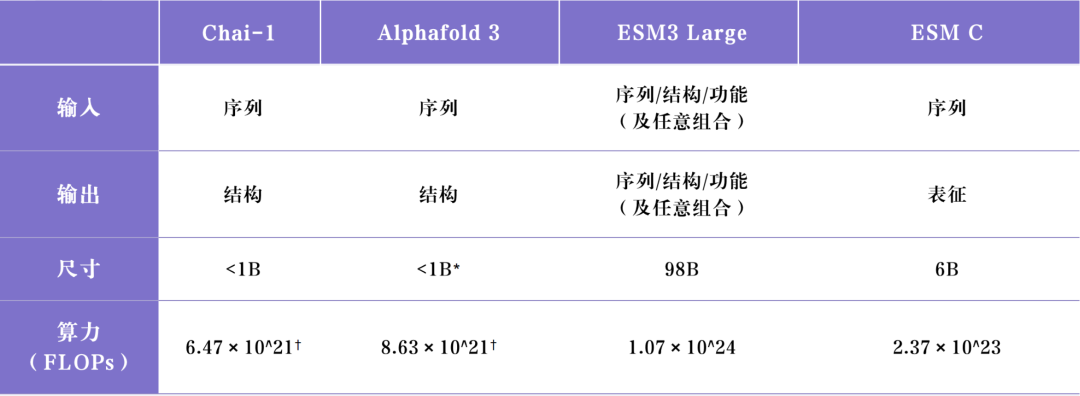
* 根据 Deepmind 公开的模型文件大小 1GB 估算,
† 以 FP32 精度下 A100 的峰值 FLOPs 估算
推理时 Alphafold 3 的输入是待测物质的序列,根据该序列会进行模版搜索和基因搜索(即所谓多序列比对(MSA)来寻找与待测物质类似且结构已知的物质来帮助
进行结构预测),同时会生成待测物质的多个可能的构象, 这些检索与生成结果均会经过特定的编码器进行编码,随后经由一个 Pairformer 模块来建模分子间的交
互作用,最后这些信息都会输入 Diffusion Model 去预测分子的三维坐标。
相较于上一代 Alphafold 2,Alphafold 3 的核心优化在于引入了 Diffusion Model,简化了多序列比对(MSA)的处理,减少了计算复杂度。也删去了一些编码的模
块,使得模型可接受的物质范围得到拓展,包括蛋白质、核酸、小分子或离子序列以及他们的复合体作为输入,而 Alphafold 2 只能接受蛋白质序列作为输入)。
Alphafold 3 的训练数据主要采用 Protein Data Bank (PDB) 中公开的蛋白质结构。此外为了增强蛋白质序列的处理能力,以及为了能够处理核酸、小分子或离子序
列,除了使用 PDB 数据,采用了部分合成数据。
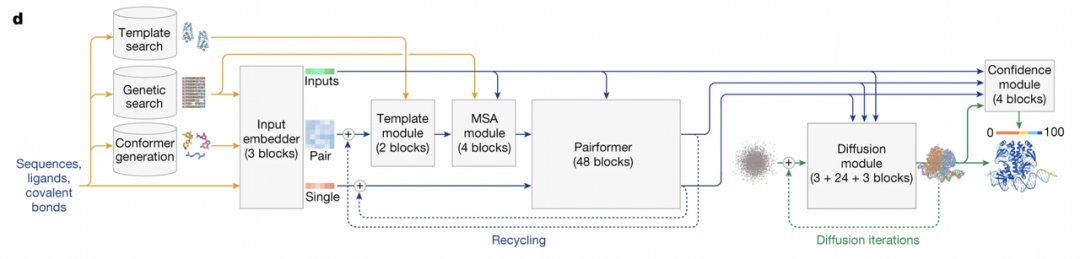
Alphafold 3 的模型结构
• Transformer:ESM-3 路线
ESM3 是一个多模态蛋白质模型,主要结构基于双向 Transformer(不同于 LLM 的单向 decoder-only) ,拥有序列、结构和功能三个模态的输入和输出,在进入
Transformer Blocks 前三个模态会融合到一起,从 Transformer Block 输出后会分别解码成三个模态。这样的结构设计使得 ESM3 在推理时支持对于任意模态排列组
合的预测,比如根据序列预测结构。下面依次介绍三种模态的输入与输出:
1)序列:形式为物质的序列,比如蛋白质的氨基酸序列。
2)结构:通过将三维原子结构编码为离散标记作为输入,以蛋白质序列为例,每个氨基酸附近的三维结构信息会被 autoencoder 编码为一个离散 token,输出时再
经过 decoder 生成完整的原子结构。
3)功能:文本形式的关键词用以来描述特定结构的功能。
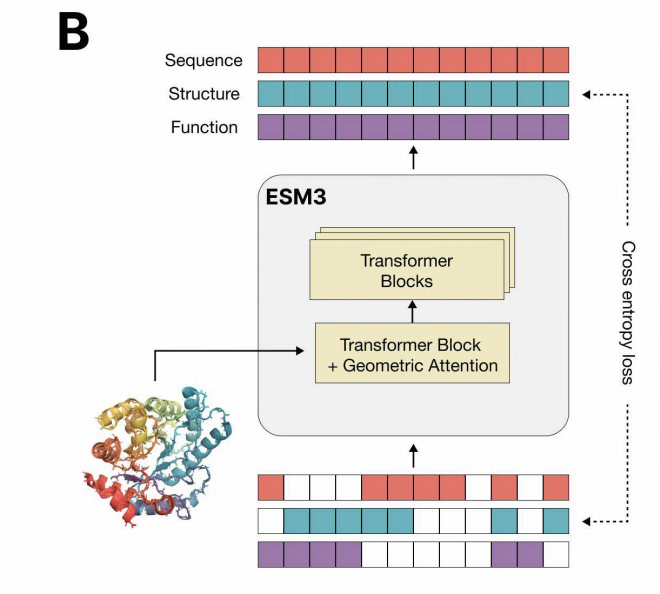
ESM3 的模型结构
ESM3 目前有 1.4B/7B/98B 三个版本,与 GPT 等语言模型类似,ESM3 存在明显的 scaling 现象,即不改变模型结构,仅仅提高训练的数据量和模型的参数尺寸,
性能就会得到提升。例如在 tertiary coordination 任务上(一种结构预测任务)上三种尺寸模型的准确率分别为从 9.5%、19.0%、26.8%,随着模型参数增加效果增
长明显。此外,ESM3 还进行了类似于语言模型中 RLHF 的偏好微调,进一步增强模型的指令跟随能力,上述任务在三种尺寸的模型上性能升到 8.8%、37.4%、
65.5%,有一个非常明显的提升。
此外,Evolutionaryscale 于 2024 年 12 月推出了专注于表征学习的蛋白质语言模型 ESM Cambrian (ESM C),同样是基于 Transformer 的结构,有 300M/600M/6B
三个尺寸。在表征学习的性能上,Evolutionaryscale 官方公布的结果显示 ESM C 6B 大幅领先 ESM2 15B。而表征学习的能力与结构预测都属于对于序列的理解能
力。
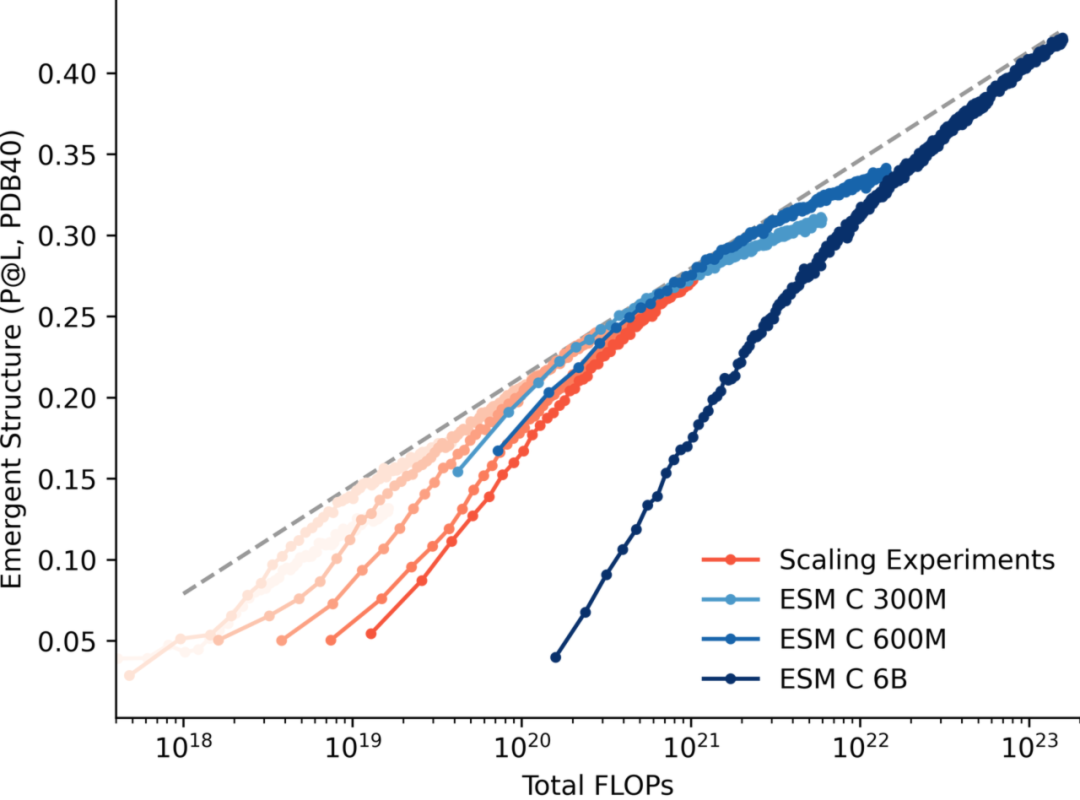
ESM C 呈现出明显的 scaling 特性
尽管目前的 ESM C 最大只有 6B,但是 ESM C 同样展现出了很明显的 scaling 特性,实验表明其性能符合幂律的 scaling law,在未来 Evolutionaryscale 也有可能
会推出更大版本的(有可能是~100B 参数规模的)ESM C,也有可能在结构预测领域推出专有模型从而对 Chai-1 在结构预测上的性能优势构成威胁。
基于扩散模型的 Chai-1、Alphafold 3 相比与最大的 ESM3 98B 在结构预测单一任务上目前存在较大的领先,在 ESM3 的技术报告中对比了 ESM3 98B 与 Alphafold
2 在蛋白质结构预测数据集 CASP14 上的性能(0.763 vs 0.846),考虑到 Alphafold 3 相比于上一代又有明显的提升(比如 AlphaFold 3 在另一个常见的蛋白质结
构预测数据集 PoseBusters V1 大幅超过基于 AlphaFold 2 改进的蛋白质结构预测模型 AlphaFold-Multimer 2.3),可以推断即使是最强的 ESM3 模型在蛋白质结构
预测任务上仍然与基于扩散模型相差甚远。不过值得注意的是, ESM3 的优势在于采用了一种通用的结构能够进行多种预测或者可控生成,并且展现出了良好的
scaling 特性,在持续投入数据与算力的情况下模型能力有望进一步提升。
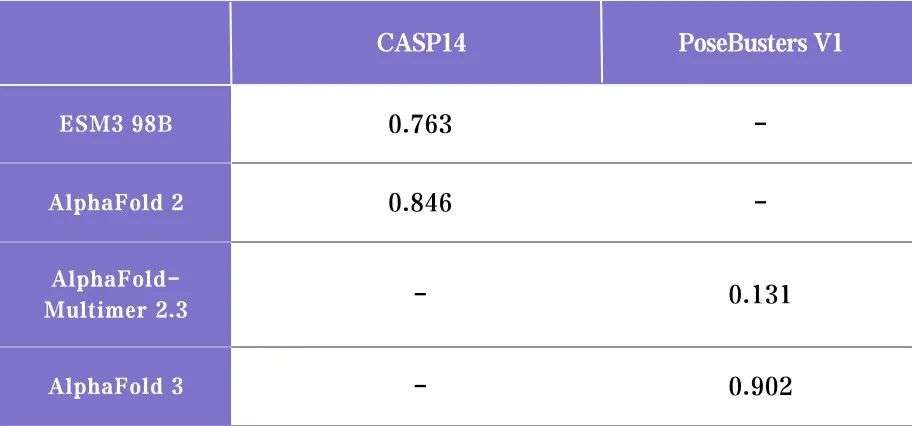
但是,目前参数量最大的 ESM3 也有 98B(与 GPT-3 的 175B 为一个数量级),已经是一个很大的尺寸,继续投入计算资源扩大模型的参数规模所能带来的 scaling
law 收益究竟有多少存在疑问。因而我们认为,在现阶段 Chai-1 基于扩散模型这一技术路线,能够在蛋白结构预测这一单一任务上取得性能的领先,在通用生物模
型取得更好性能前拥有足够多的时间搭建一个完整可用的产品推向市场。
截至目前,包括 Chai Discovery、Isomorphic Labs 和 Evolutionaryscale 均未公布自己的收费模式。不过据分析其官网的相关说明,收费模式大概率是按使用量收费
(Usage-Based Pricing),即按照调用的次数或者 token 数量计费,比如 Chai Discovery 目前每天可免费使用 25 次,Isomorphic Labs 和 Evolutionaryscale 的网页端
均提及了 token 的计算方式。
在与 Chai 达成合作的云计算平台 LatchBio 上,可以按照所需服务的 GPU 时间进行购买,事实上等价于根据 token 和模型大小收费。以 LatchBio 上 Alphafold 为
例,一个包含 235 个氨基酸的蛋白质序列在 Latch 上运行需要 32 分钟,包含 64 个 CPU、256 GiB RAM 和 1 个 GPU,需要大约8.946176 (美金),计算方式
为:32分钟的运行时间 * (64个CPU * 0.003498 / 核心 / 分钟 + 256 GiB RAM * 0.000166 / GB / 分钟 + 1 个 GPU * 0.0132 / GPU / 分钟)。此外,Chai Discovery 在
Tamarind 上,可以采分层订阅制 (Tiered Pricing) 购买,每月有固定数量的API调用次数。
自第一代 AlphaFold 发布以来,人们就意识到了通过人工智能的方法预测蛋白质结构是完全可行的,这一领域也涌入了相当多的玩家。
在此我们主要分析 Chai Discovery 的几大竞争对手,包括 Isomorphic Labs,Google 在2021年专为人工智能制药成立的子公司,提出了 Alphafold 系列模型;
Evolutionaryscale 基于 Transformer 的生物大模型 ESM 3 的提出者;Xaira Therapeutics,由 2024 年诺贝尔奖得主 David Baker 团队作为主要技术团队;
Inceptive,创始人是 Transformer 的发明者 Jakob Uszkoreit。
Isomorphic Labs 团队由 Google DeepMind 分拆出来进行独立研发,据报道目前团队人数超过 70 人,CEO 是 2024 年的诺贝尔化学奖获得者 Demis Hassabis 。成
员过往参与了 Alphafold 系列模型的研发,Chai-1 所采用的技术也主要参考了 Alphafold 3 的技术路径,因而该公司在技术实力上毋庸置疑。2024 年 5 月
Isomorphic Labs 联合 DeepMind 推出了 AlphaFold Server,用户可以基于网页端访问远端部署 Alphafold 3 模型,对蛋白质、小分子、DNA、RNA 以及它们的组合
通过序列进行结构预测,在产品形态上 Chai 与之也很类似。
此外,Isomorphic Labs 已经与一些制药公司包括 Eli Lilly(礼来)和 Novartis(诺华)签订了商业合同,在与 Eli Lilly 的合作中,Isomorphic Labs 将从 Eli Lilly 获得
4100 万欧元的预付款。该合作包括潜在的基于绩效的里程碑付款,总额可达 15.5 亿欧元。该合作旨在发现针对多种疾病相关蛋白质和通路的小分子治疗药物,是
Isomorphic Labs 的首个制药伙伴关系;与 Novartis 的合作中 Isomorphic Labs 将获得 3400 万欧元的预付款,潜在的里程碑付款可达 11 亿欧元。
Evolutionaryscale 成立于 2023 年 4 月,其联合创始人兼首席执行官 Alex Rives 曾在 Meta AI 领导了 ESM 系列模型的开发,在 Meta AI 解散其蛋白质 AI 团队后成
立了该公司。2024 年 6 月,EvolutionaryScale 在推出 ESM3 的同时,获得了来自 Nvidia、Amazon 等投资者的 1.42 亿美元的种子资金。
在技术路径方面,相比于 Chai Discovery 聚焦于药物结构预测,Evolutionaryscale 试图打造一个通用的、类似于OpenAI GPT 的通用生物模型,能够实现包括结构
预测、药物生成、药物性质预测等在内的各种与制药相关的任务。目前其所提供的服务的方式与 Chai 类似,即通过网页端提供软件服务,不过目前产品还处于内测
中,用户需要申请权限并等待一段时间。值得注意的是,即使是 ESM3 98B 在药物结构预测这一特定任务上,仍与 Chai-1 这种基于 Diffusion 的模型有较大的差
距。
Xaira Therapeutics 成立于2023年5月,致力于利用 AI 技术系统性变革制药产业,其联合创始人 Nelsen 曾表示 “Xaira 不想改变一个小小的垂直领域,而是横向思考
整个系统”。Xaira 目前尚未推出任何产品,不过相较于 Chai 等构建一个软件平台供客户使用,Xaira 试图打造蛋白质靶向药物软件平台、数据生产和自有管线三者
结合的系统。
Xaira 早期处于保密状态,直到 2024 年 4 月一次性从包括 ARCH Venture 和 Foresite Capital 等投资者处拿到了 10 亿美金的 A轮融资,也是目前唯一一次融资。其
团队成员堪称豪华,CEO 是前斯坦福大学校长与 Genentech 首席执行官 Marc Tessier-Lavigne,技术上除了有诺贝尔奖得主 David Baker 领导的人工智能辅助蛋白
质设计团队,还有众多在制药行业有丰富经验的药化专家作为联合创始人,比如首席医学官 Paulo Fontoura曾在罗氏制药工作超16年,首席科学官 Debbie Law 也曾
在包括Bristol Myers Squibb 在内的多家药企工作超过25年。目前 Xaira 整个团队超过了百人。
Inceptive 成立于 2021 年,专注于利用 AI 技术设计 mRNA 药物,目前正将设计出的药物分子授权制药公司进行制造,他们的路线是从 RNA 开始打造给所有药厂使
用的“生物软件”。其 CEO 是谷歌前研究员、神经网络结构 transformer 结构的 8 个提出者之一 Jakob Uszkoreit,团队规模超过了 60 人。Inceptive 先后于 2022 年 1
月与 2023 年 9 月融资了 2 千万美金与 1 亿美金,我们曾经编译过 CEO 的访谈。
Chai Discovery 成立于 2024 年 3 月,目前团队成员在 10 人左右,均具有人工智能相关的技术研发工作经历,超过半数在加入 Chai Discovery 之前就在从事人工智
能辅助的药物设计。
CEO Joshua Meier 拥有哈佛大学的计算机硕士学位和计算机+化学双学士学位,曾在AI制药公司 Absci 工作过两年的时间,并担任其首席人工智能官。Absci 主要通
过 AI 以及自建的湿实验室进行先导化合物优化和从头抗体设计,并于 2021 年成功上市,因此 Joshua 对于生物领域的软件平台有足够的领域经验。
加入 Absci 之前 Joshua Meier 曾在 Facebook AI 工作过逾三年,在 OpenAI 短暂的工作过。值得注意的是,在 Facebook AI 期间其是 ESM-1b、ESM-1v 等 ESM
系列早期模型的主要开发者(是 ESM-1b 论文<Biological structure and function emerge from scaling unsupervised learning to 250 million protein sequences> 的第
二作者),因此 Chai Discovery 应该非常熟悉 ESM 这一条基于transformer 构建通用生物大模型的技术路径,但是却选择了基于 Diffusion Model 希望首先在结构预
测这一领域先取得突破。
CTO Jack Dent 曾在 Stripe 从事六年的产品工程研发。另外两位联合创始人 Jacques Boitreaud 和 Matthew McPartion 也都之前在 AQEMIA、VantAI 和 Absci 工作
过数年时间,负责人工智能辅助小分子或蛋白质药物设计的相关工作。
2024年9月,Chai Discovery 获得了来自 Thrive Capital、OpenAI 的约 3000 万美元种子轮融资,估值为 1.5 亿美元。Thrive Capital 先前对 OpenAI 进行了多轮投
资,包括最近的一笔约 10 亿美金的投资。
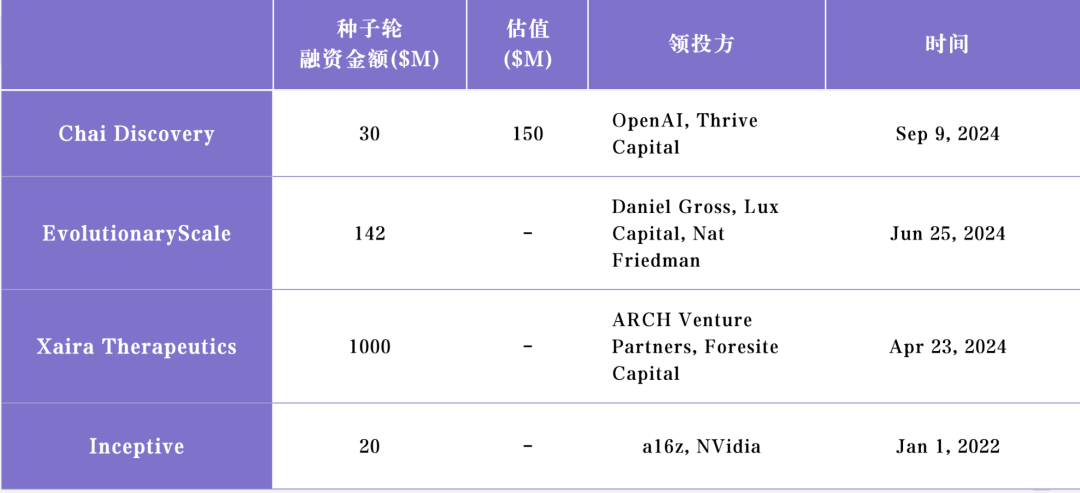
我们把他们的融资情况与行业竞争对手放在一起对比,会发现即使 Chai 团队的背景已经很优秀,他们的募资规模也不算很大。这是一个资本密集的领域,代表行业
期待他们的突破能让医药行业的发现生产流程发生根本性的变化,有更多疫病得到预防和治愈。
Reference
[1] https://www.statista.com/statistics/309466/global-r-and-d-expenditure-for-pharmaceuticals/
[2] https://www.genengnews.com/gen-edge/the-unbearable-cost-of-drug-development-deloitte-report-shows-15-jump-in-rd-to-2-3-billion/
[3] https://www.cbo.gov/publication/57126?utm_source=chatgpt.com
[4] https://www.knowledgeportalia.org/costs-r-d
文章来自于微信公众号 “海外独角兽”,作者 :Xeriano、Cage




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
