# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DeepSeek-R1这样的推理模型有着强大的深度思考能力,但也有着一些不同于通用模型的特点与用法,比如不支持函数调用,不支持结构化输出,o1甚至不支持系统提示(System Prompt)等。尽管这和它们的使用场景有关,但有时也会带来不便。今天我们就来说说结构化输出这个常见的问题。
【什么是结构化输出】
结构化输出就是大模型在生成响应时,以一种有结构的规范化形式呈现,而不是自由文本。这种结构化的输出通常包括预定义的字段、标签、列表、表格、或者其他形式的组织化数据,而最常见也是最灵活的一种表达形式就是JSON。比如输出一个结构化的用户信息可能如下:

【为什么需要结构化输出】
结构化输出的最大意义在于:提供一种更易于程序处理的标准化数据交换格式,极大地方便应用的后续解析与处理。这些后续处理比如:
这种能力对于企业级的应用,特别是在多步骤任务的Agent中,可以极大方便后续步骤的处理,并减少LLM带来的不确定性。举一个例子:
在一个自主学术研究的Agent中,希望借助DeepSeek-R1的深度思考能力,首先生成完善的研究大纲,后续再根据大纲对每一个子主题借助搜索引擎、RAG等获取参考资料,并做进一步研究。
在这个例子中,我们希望DeepSeek输出的大纲如下:
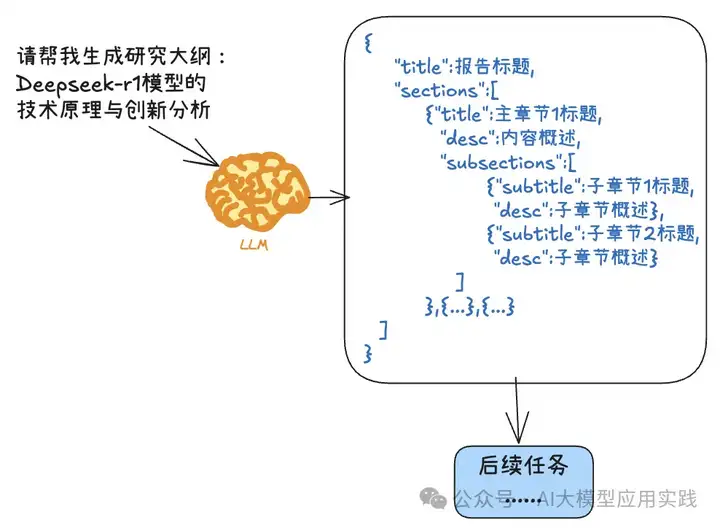
很显然,这样的输出会更方便后续程序的理解与处理。
【结构化输出的常见方式】
对于目前的很多通用模型来说,结构化输出已经不再是一个障碍,你可以通过模型提供的API参数进行强制。比如gpt-4o目前支持几种主要的结构化输出方式:
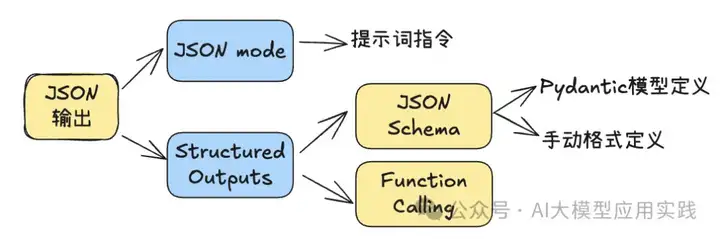
除了Function Calling(这必然会产生结构化输出)外:
# 数据模型定义
class Subsection(BaseModel):
"""子章节"""
subsection_title: str = Field(..., description="子章节的标题")
description: str = Field(..., description="子章节的详细内容描述")
class Section(BaseModel):
"""主要章节及其包含的子章节"""
section_title: str = Field(..., description="章节标题")
description: str = Field(..., description="章节内容概述")
subsections: Optional[List[Subsection]] = Field(
default=None,
description="本章节中的子章节",
)
class Outline(BaseModel):
"""完整大纲"""
page_title: str = Field(..., description="报告标题")
sections: List[Section] = Field(
default_factory=list,
description="文章的主要章节",
)
当你指定这里的Outline为输出格式时,API将会直接返回你Outline类型的对象,极大的方便了后续处理。
注意这里的结构化输出是在API层的支持,并非简单的通过Prompt进行输出格式的限定。当然,你也可以通过提示词要求deepseek生成json格式的字符串,但存在较大的不确定性(比如内容多了个```json```,或者"这是你要求的json字符串"),从而导致后续解析失败。
那么现在我们需要deepseek来帮助完成Agent的某个步骤,同时希望获得稳定的结构化输出,应该如何处理呢?接下来介绍两种方式。
这种方法融合DeepSeek-R1的深度思考能力与通用模型的结构化输出能力(如GPT-4o):将R1的推理结果借助一个“辅助”模型进行“格式化”后输出,概念流程如下:
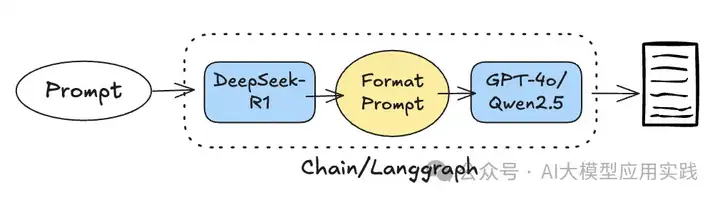
具体到LangChain框架中,实现这种顺序流的方式又有两种,这里依次介绍。
【Chain链】
Chain是LangChain中最核心的概念。它将多个步骤或组件连接在一起,实现复杂的处理任务。借助LCEL(Langchain表达式语言)可以快速构建这个Chain:
......
# deepseek提示
system_prompt_deepseek = ChatPromptTemplate.from_template("""
针对用户提供的主题, 撰写一篇研究报告的大纲。要求全面且具体。我的主题:{topic}
""")
# 内容格式化提示
system_prompt_format = ChatPromptTemplate.from_template("""
你是一个内容格式化专家, 只负责将输入内容转化为结构化输出, 不要做额外思考。我的内容:{draft}
""")
# deepseek模型
llm_ollama_deepseek = ChatOllama(model='deepseek-r1:1.5b')
# openai模型:使用with_structured_output强制结构化输出
llm_openai = ChatOpenAI(model='gpt-4o-mini').with_structured_output(Outline)
# 创建 LangChain 的 chain
chain = system_prompt_deepseek | llm_ollama_deepseek | system_prompt_format | llm_openai
我们对这个Chain进行测试:
......
response = await chain.ainvoke({"topic":"deepseek-r1的技术原理与创新分析"})
print("\n生成的大纲:")
print(response.as_str)
输出如下,我们可以得到一个非常干净的结构化输出的大纲(这里输出的response实际是一个上面定义的Outline对象,这里通过一个简单的as_str进行转化打印):

【LangGraph工作流】
既然是一个流式任务,当然也可以通过LangGraph来实现,构建这样一个简单的Graph即可:
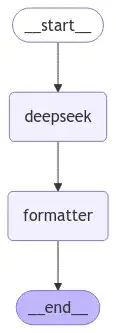
这里核心的state与node定义如下:
...
class State(TypedDict):
"""图的状态类型"""
topic: str
draft: str | None
output: Outline | None
def deepseek_node(state: State) -> State:
"""使用deepseek模型处理输入任务"""
ollama = ChatOllama(model="deepseek-r1:1.5b")
messages = [SystemMessage(content='针对用户提供的主题,撰写一篇研究报告的大纲。要求全面且具体'),
HumanMessage(content=state["topic"])]
response = ollama.invoke(messages)
state["draft"] = response.content
return state
def formatter_node(state: State) -> State:
"""使用GPT-4o处理并格式化输出"""
llm = ChatOpenAI(model="gpt-4o-mini").with_structured_output(Outline)
messages = [SystemMessage(content='你是一个内容格式化专家,只负责将输入内容转化为结构化输出,不要做额外思考'),
HumanMessage(content=f'我的内容: {state["draft"]}')]
response = llm.invoke(messages)
state["output"] = response
return state
剩下的工作就是创建Graph并测试,交给读者们自行完成。
以上的两种方法(Chain或者Graph)都可以达到相同的目的,Chain实现相对简洁,适合在普通的应用中使用;而如果你本身就是一个需要使用LangGraph来实现的复杂Agent应用,那么可以参考第二种:增加一个专门的formatter节点即可。
这种方法的思想是借助Agent的思想,让deepseek的深度思考作为一个Agent可以使用的工具,在这个工具(使用deepseek模型)获得思考结果后,再通过结构化输出的模型进行格式化(使用gpt-4o模型)。概念如下图:
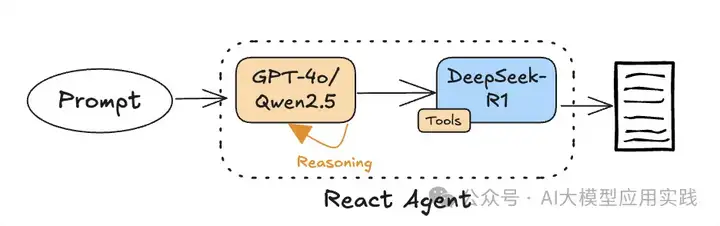
由于这是一个React类型的Agent,因此其更适合在多Agent应用环境中使用,让其与其他Agent通过协作完成更复杂的任务。
【构建Tool】
首先创建一个使用deepseek-r1进行思考的工具,输入是研究主题,输出则是思考结果(自由文本表达的研究大纲)。
@tool
def deepseek_research(prompt: str) -> str:
"""
对输入的研究任务进行思考,并生成研究大纲的草稿
args:
prompt(str): 输入的研究任务描述
return:
result(str): 思考结果
"""
print('start think...')
messages = [HumanMessage(content=f'针对用户提供的主题,撰写一篇研究报告的大纲。要求全面且具体。我的主题:{prompt}')]
result = llm_ollama_deepseek.invoke(messages)
print(result.content)
return result.content
【创建ReAct Agent】
借助LangChain的prebuilt函数快速的构建一个ReAct Agent来使用这个Tool。为了让这个Agent必须使用这个Tool,可能需要在提示词上适当调优。参考如下代码:
...
llm = ChatOpenAI(model='gpt-4o-mini')
agent = create_react_agent(llm, response_format=Outline, tools=[deepseek_research])
response = agent.invoke({"messages":[
SystemMessage(content="请首先使用工具(deepseek_research)来生成研究大纲草稿,然后对草稿进行格式化输出。请注意把输入主题直接交给工具,不要做思考与加工。以下是我的研究主题。"),
HumanMessage(content="deepseek-r1技术原理与创新分析")]})
last_message = response["structured_response"]
print(last_message.as_str)
注意这里与上面两种方法的不同之处在于:不直接调用llm的with_structured_output方法,而是在create_react_agent方法中指定response_format参数(本质上一样)。
以上展示了两种方法来给DeepSeek-R1这样的推理模型“嫁接”上稳定的结构化输出的能力,以帮助在复杂的企业级应用中对接其他流程或任务。
这里还有最后一个问题:如果我的辅助模型不是gpt-4o这样具备便捷的结构化输出接口的模型怎么办(即不支持使用JSON Schema或者Pydantic模型定义输出格式)?方法就是借助JSON mode,以qwen模型为例,通常包括几个步骤:
1. 在API调用时指定JSON mode,比如qwen系列模型中:
response_format={"type": "json_object"}
2. 在提示词中明确要求进行JSON结构化输出,并指定格式。
3. 由于这种方式的API不会直接输出对象,因此你需要对结果字符串做解析:
json_object = json.loads(result)
OK,借助以上介绍的几种方法,现在你可以把DeepSeek更加如鱼得水接入到你的应用中,感受其强大的威力。
文章来自微信公众号 “ AI大模型应用实践 “,作者 秋山墨客



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
