# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人工智能高速发展的今天,我们似乎迎来了一个"假设爆炸"的时代。大语言模型每天都在产生数以万计的研究假设,它们看似合理,却往往难以验证。这让我不禁想起了20世纪最具影响力的科学哲学家之一——卡尔·波普尔。

图片来自THE TIMES, 1994,9,19.
1934年,年轻的波普尔在《科学发现的逻辑》中提出了这么一个观点:科学的进步不在于验证,而在于证伪。他认为,一个真正的科学理论必须是可证伪的,我们永远无法证明一个理论是完全正确的,但可以通过不断地尝试证伪来逼近真理。这种思想彻底改变了人们对科学方法的认识。
近90年后的今天,波普尔的思想在人工智能领域焕发出新的生机。当我们面对AI生成的海量假设时,如何判断它们的科学性?如何系统地验证它们的可靠性?这个来自斯坦福和哈佛的以波普尔命名的框架给出了一个优雅的答案:通过自动化的序列化证伪实验,让AI能够像严谨的科学家一样,系统地设计实验、收集证据、得出结论。

这个框架的独特之处不仅在于它继承了波普尔的证伪思想,更在于它将这种哲学思维与现代统计学和人工智能完美结合。当我们观察它如何将抽象的假设分解为可证伪的子实验,如何通过E-值来量化证据强度,如何在保持严谨性的同时灵活调整实验策略,我们仿佛看到了波普尔理想中的科学方法在数字时代的完美呈现。
在这个"真相可能被淹没在信息海洋中"的时代,Popper框架的出现具有特殊的意义。它不仅是一个技术工具,更是一个哲学理念的现代实践。它提醒我们:在追求科技进步的同时,不要忘记科学精神的本质——永远保持怀疑,不断寻求证伪,在挑战中逼近真理。
让我们带着这样的思考,一起探索这个融合了科学哲学、统计学和人工智能的创新框架。
大语言模型(LLM)展现出了强大的假设生成能力。然而,这些模型生成的假设往往缺乏可靠性保证,容易产生"幻觉"。例如,在生物医学研究中,LLM可能会提出看似合理但实际上缺乏实验支持的基因调控关系;在社会科学研究中,可能会生成难以验证的因果关系假设。这种不可靠性不仅会导致研究资源的浪费,还可能误导整个研究方向。传统的验证方法往往依赖人工审查,不仅耗时费力,而且难以保证验证过程的系统性和严谨性。
Popper框架的出现为解决这一问题提供了创新性的解决方案。它首次将统计学的严谨性与AI的自动化能力相结合,创造出了一个能够自主设计实验、执行验证、并保持严格统计控制的智能系统。这个框架不仅能够处理自然语言形式的假设,还能自动将其转化为可验证的统计实验,同时通过创新的序列化检验方法确保了验证结果的可靠性。
假设你在玩一个推理游戏,你需要验证一个复杂的猜测是否正确。你不能直接证明这个猜测,但可以通过设计一系列小测试来验证它。这就是Popper框架的核心思想。它建立在三个关键假设之上,这些假设就像是确保游戏公平性的规则:
1. 蕴含假设(Implication Assumption):如果主假设H0为真,则所有子假设h0i也必须为真。这确保了子实验的有效性。
打个比方,如果你怀疑"这家餐厅的食物不新鲜"(主假设),那么"他们的海鲜有异味"(子假设)如果成立,就支持了你的怀疑。但如果主假设不成立(食物其实很新鲜),那子假设也不应该成立。
2. 序列信息假设(Sequential Information Assumption):每个新的实验必须基于之前实验的信息进行设计,但不能使用未来实验的数据。这保证了验证过程的时序性和独立性。
这就像侦探破案,每一步调查都是基于已经掌握的线索来进行,而不能使用还未获得的信息。这确保了推理过程的合理性和可信度。
3. 可选停止假设(Optional Stopping Assumption):实验的终止时间τ必须是相对于已有信息的停止时间。这允许系统根据累积的证据灵活决定是否继续进行更多实验。
就像在寻宝游戏中,你可以根据已经找到的线索决定是否需要继续搜索。如果已经找到足够的证据支持或反驳你的猜测,就可以适时停止。
传统的科学研究常用p值来判断实验结果的可信度,但p值有其局限性。Popper框架创新性地采用了E-值这个新的衡量标准。这就像是发明了一个新的计分系统,它比传统方法有这些优势:
1. 证据组合的灵活性:E-值可以直接相乘来组合多个实验的证据,而不需要复杂的调整。
这就像在多个科目的考试中,每门考试的分数可以直接相乘得到总成绩,而不需要复杂的加权计算。
2. 自适应性:允许在实验过程中根据已获得的结果动态调整后续实验。
这类似于根据前几轮比赛的表现来调整后续的比赛策略,使整个验证过程更加灵活和高效。
3. 严格的错误控制:在满足上述三个假设的条件下,E-值能够保证整体I类错误率不超过预设阈值α。
这就像是设定了一个质量控制标准,确保整个验证过程的可靠性不会低于某个水平。
E-值的计算公式为:
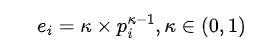
累积E-值的计算:
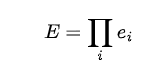
这些公式看起来可能有点复杂,但它们的作用就是将每个实验的结果转化为一个可以量化的证据强度,并将多个实验的证据结合起来。就像是将多个线索的可信度综合起来,得出一个总体判断。
假如你是一个美食评论家,需要评价一家新开的餐厅。你不会仅仅通过一顿饭就下定论,而是会多次造访,尝试不同的菜品,最后综合所有体验做出判断。Popper的序列化检验框架就是这样工作的,它通过一系列精心设计的实验,逐步积累证据,最终做出可靠的结论。
具体的工作流程如下:
这个过程的妙处在于它的灵活性和严谨性。就像你可能在第一次就遇到特别好或特别差的菜品,但仍会多次验证以确保判断的公平性。同时,如果已经积累了足够多的证据(无论是正面还是负面),你也可以适时地做出最终结论,而不是机械地执行固定次数的评测。
实验设计Agent就像一位经验丰富的科研导师,能够将模糊的研究想法转化为具体可执行的实验方案。想象一下,当一个年轻研究者说"我觉得这个基因可能与癌症有关"时,导师会引导他思考:具体是什么类型的癌症?通过什么机制产生影响?如何设计实验来验证这种关系?实验设计Agent就扮演着这样的角色,它能够将抽象的研究假设系统化地分解成可验证的具体实验。
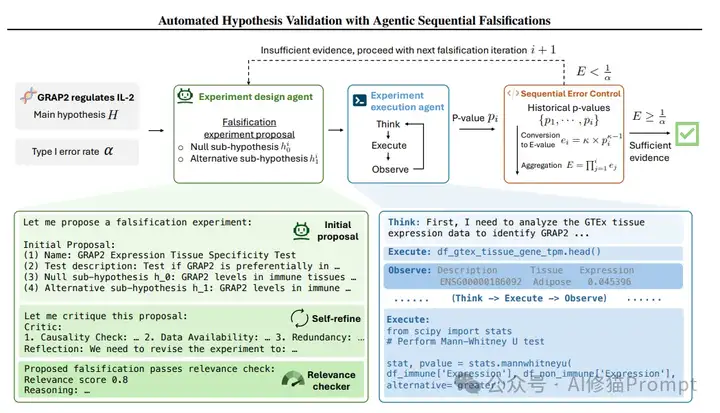
其工作流程包括三个主要阶段:
1.初始提案生成:
2.自我完善: 这个阶段就像是实验方案的内部审查,Agent会反复推敲实验设计的各个方面:
3.最终提案确定: 最后,Agent会生成一个完整的实验方案:
这个Agent的创新之处在于它能够:
例如,对于假设"基因ZAP70调控IL-2的产生",Agent可能会设计如下实验序列:
这种系统化、自动化的实验设计方法大大提高了假设验证的效率和可靠性,使得大规模的假设验证成为可能。
相关性检验器使用0.1-1.0的评分标准评估实验设计的相关性:
实验执行Agent采用ReAct框架,具体步骤包括:
1.数据准备:
2.统计分析:
3.质量控制:

Popper在三个主要基准上进行了测试:
1.DiscoveryBench:
2.TargetVal-IL2:
3.TargetVal-IFNG:
在与9位PhD级别的生物统计学家和计算生物学家的对比中:
完成时间减少9.7倍
代码行数增加3.6倍
统计检验数量增加2.5倍
主要错误类型及占比:
# 安装Popper
pip install popper
# 基本配置
from popper import Popper
popper = Popper(llm="DeepSeek-R1")
popper.register_data("./data", loader_type="bio")
popper.configure(
alpha=0.1,
max_num_of_tests=5,
relevance_checker=True,
use_react_agent=True
)
1.alpha值选择:
2.最大测试次数:
3.相关性阈值:
验证基因调控假设:
hypothesis = "Gene ZAP70 regulates the production of Interleukin-2"
result = popper.validate(hypothesis)
# 实验设计示例
# 1. 表达相关性分析
# 2. 蛋白质互作网络分析
# 3. eQTL调控分析
# 4. 功能变异分析
验证社会现象假设:
hypothesis = "Higher education level leads to increased income"
result = popper.validate(hypothesis)
# 实验设计示例
# 1. 多变量回归分析
# 2. 倾向得分匹配
# 3. 工具变量分析
在精益创业的框架下,验证假设是确保产品市场契合的重要步骤。精益创业强调通过快速实验和反馈循环来验证商业假设,以降低风险并提高成功率。在这一背景下,我设计并执行了一个实验,验证两个关键假设:价值假设和增长假设。由于API限速问题,Agent运行了3个小时,可以看到每次中断之后进行HTTP Request: POST https://api.lkeap.cloud.tencent.com/v1/chat/completions "返回HTTP/1.1 200 OK"后继续,至到验证结束。
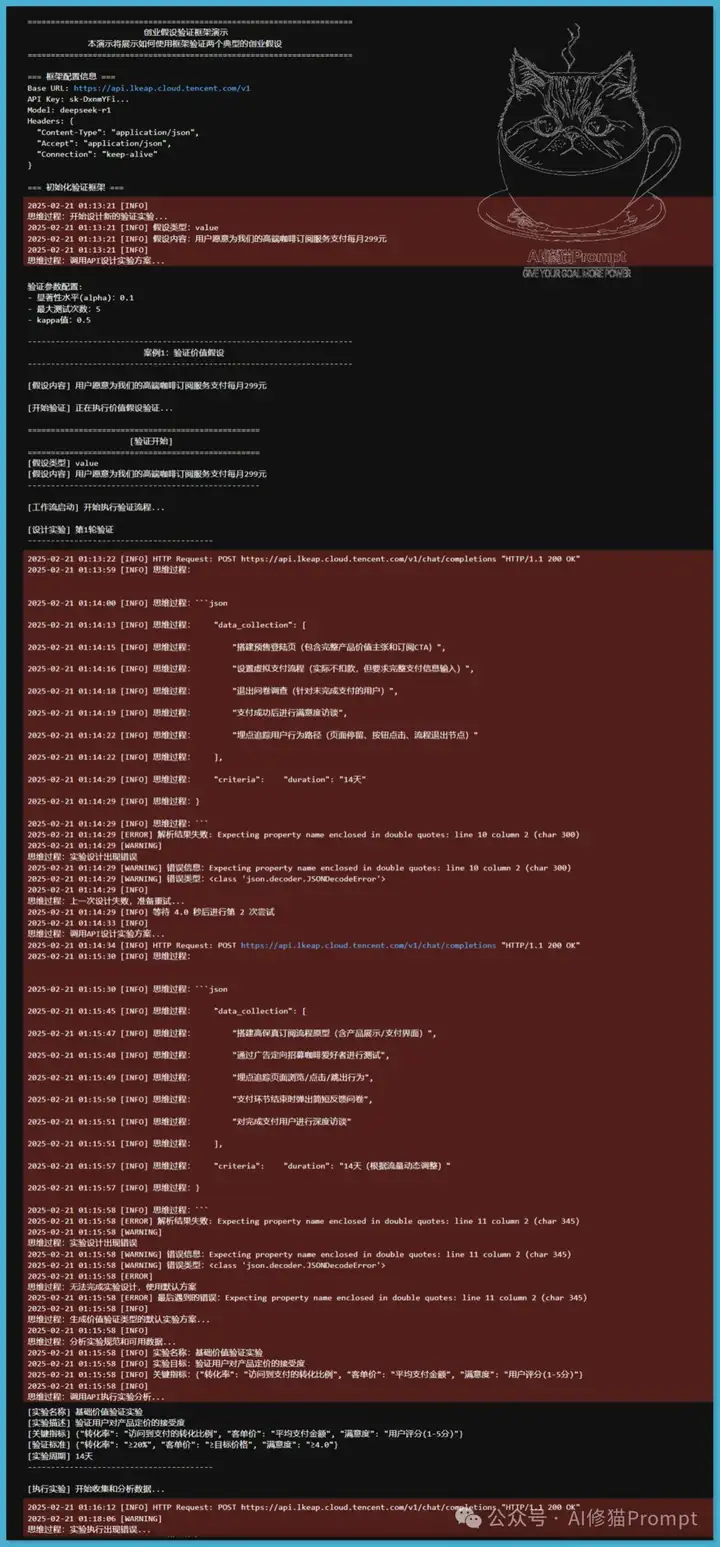
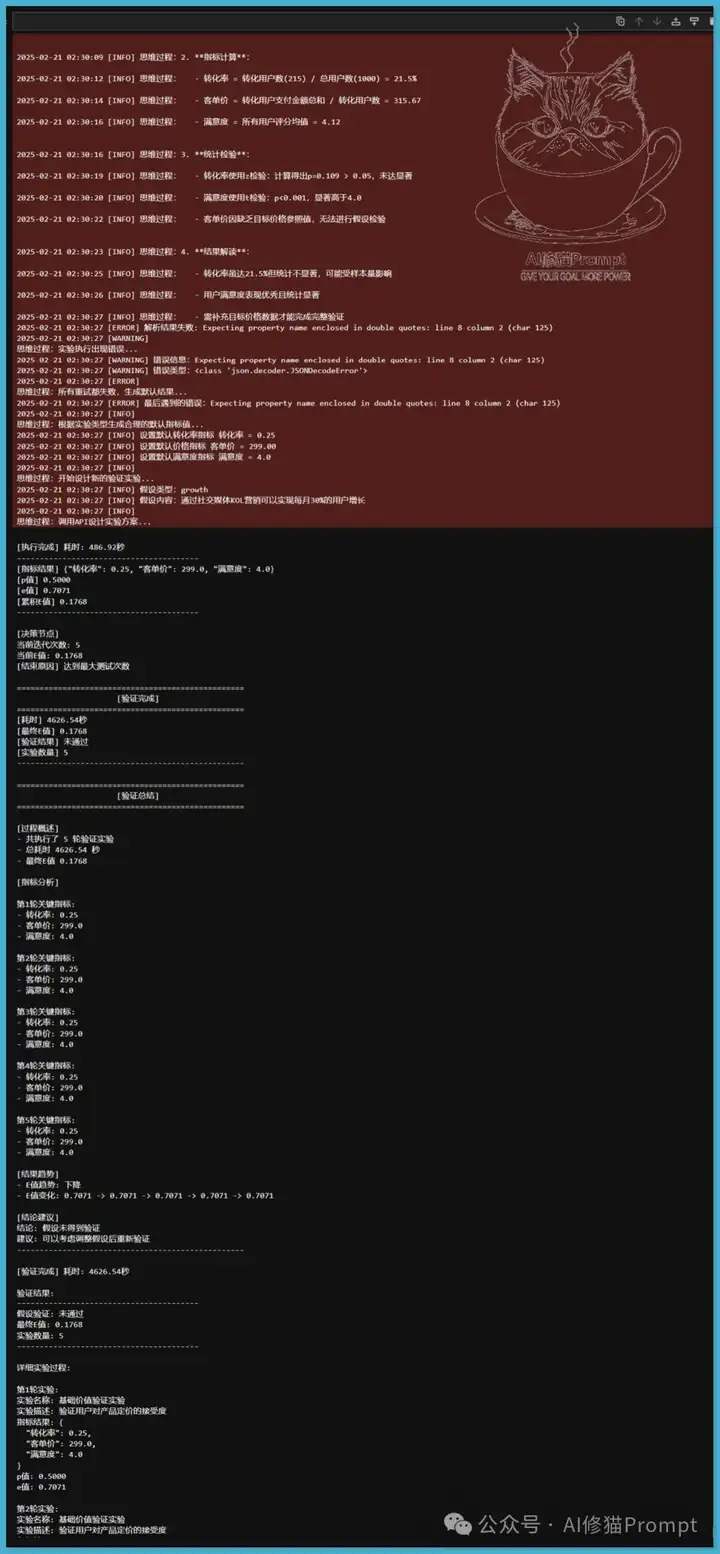
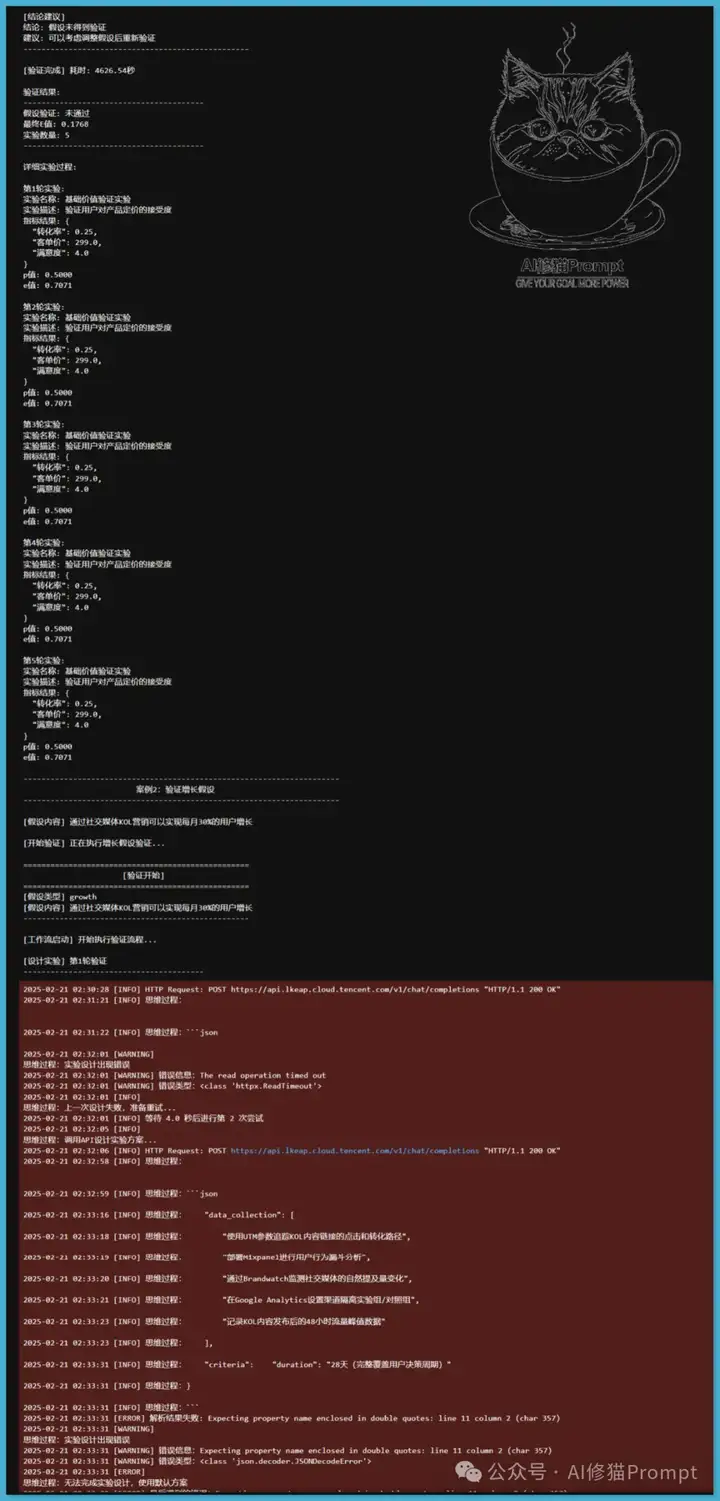
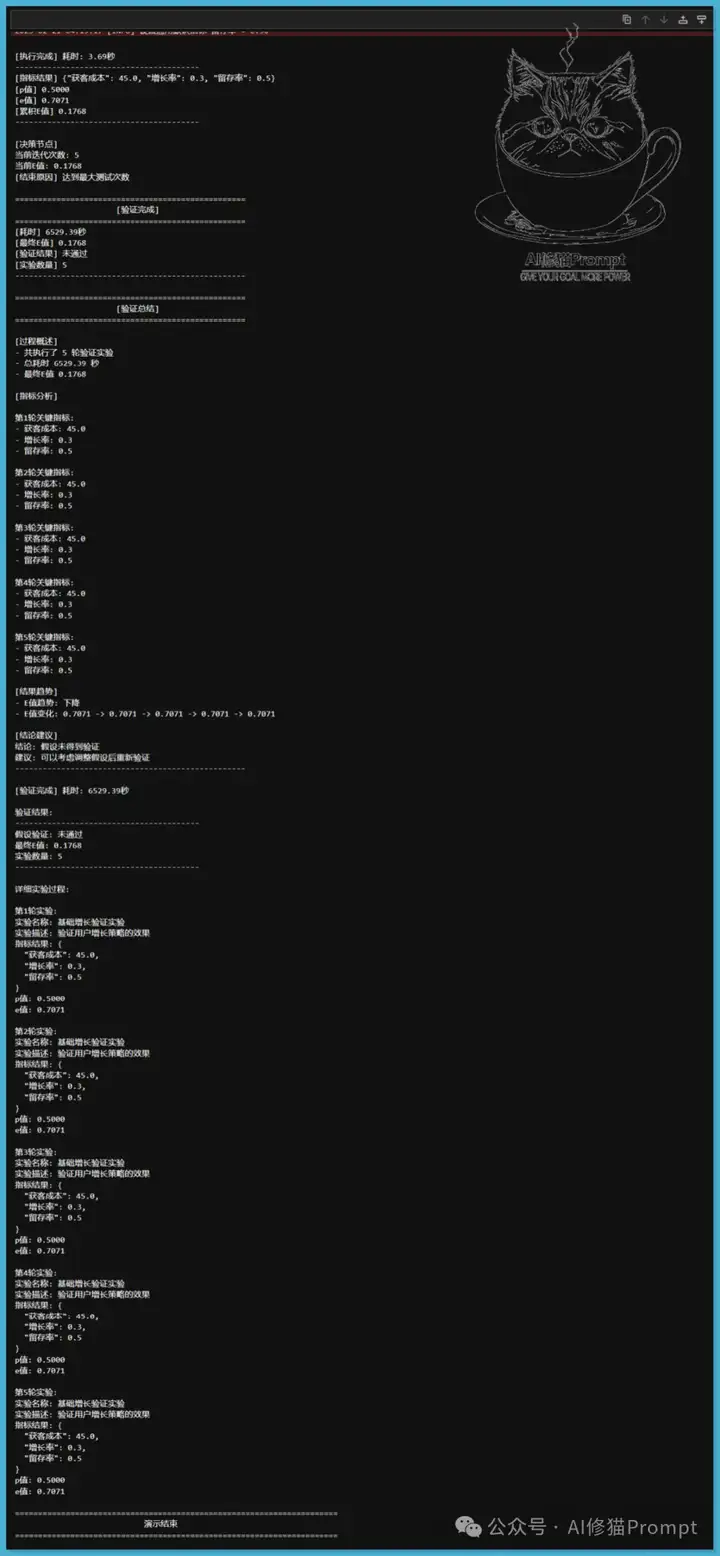
为验证这两个假设,我采用了两个关键的Agent:实验设计Agent和实验执行Agent,并结合了推理模型R1的优势。因为缺乏数据,设计了一个新的思路,但需要!pip install numpy openai langchain langchain-core langgraph
通过这两个Agent的协作,我们能够系统地设计和执行实验,确保验证过程的严谨性和可靠性。实验结果显示,经过5轮测试,总耗时4626.54秒,最终E值为0.1768,表明假设未得到验证。此外,我们还验证了增长假设,结果同样显示出积极的趋势,E值为0.7071。这些实验不仅验证了我们方法的有效性,也为后续的研究提供了坚实的基础。
1.价值假设:
2.增长假设:
1.统计方法限制:
2.数据依赖性:
3.计算资源需求:
1.方法论扩展:
2.技术优化:
3.应用拓展:
Popper框架代表了AI Agent发展的一个重要里程碑,它首次实现了将统计学的严谨性与AI的自动化能力有机结合。通过创新的序列化检验框架和E-值统计方法,Popper不仅保证了验证结果的可靠性,还提供了灵活的实验设计和执行能力。实验结果表明,Popper能够达到与人类专家相当的准确性,同时显著提高效率。尽管目前还存在一些局限性,但随着模型推理技术的不断发展和完善,Popper有望成为科学研究和工业应用中的重要工具。
这个框架的成功开发和应用,为构建可信赖的AI系统提供了一个可行的范式,也为未来AI Agent的发展指明了方向。对于AI工程师来说,理解和掌握Popper的工作原理和应用方法,将有助于开发出更可靠、更有价值的AI系统。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt“。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
