# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
2 月 18 日,月之暗面发布了一篇关于稀疏注意力框架 MoBA 的论文。MoBA 框架借鉴了 Mixture of Experts(MoE)的理念,提升了处理长文本的效率,它的上下文长度可扩展至 10M。并且,MoBA 支持在全注意力和稀疏注意力之间无缝切换,使得与现有的预训练模型兼容性大幅提升。
本文作者是 MoBA 框架的开发者之一,他分享了开发 MoBA 过程的心路历程,将这一过程形象地称为 “三入思过崖”。
MoBA 这个项目的开始的非常早,在 23 年 5 月底月之暗面刚建立不久的时候,入职报到当天就被 Tim@周昕宇拉到了小房间里,和裘老师@未明秋衣(MoBAidea 的提出者)以及 Dylan 一起开始搞 Long Context Training。这里首先要感谢一下 Tim 的耐心和教导,对一个 LLM 新手给予厚望并乐意培养,研发各种上线模型和模型相关技术的诸位大佬里面,很多人和我一样基本是从零开始接触 LLM 并提供了大量的高效产出。
当时业界普遍水平也不是很高,大家都在 4 K pretrain,项目一开始叫 16K on 16B,意思是在 16B 上做 16K 长度的 pretrain 即可,当然后来很快的这个需求在 8 月变成了需要支持 128K 下 pretrain。这也是 MoBA 设计时的第一个要求,能 From Scratch 快速的训练出一个能支持 128K 长度下的模型,此时还不需要 Continue Training。
这里也引申出一个有趣的问题,23 年 5/6 月的时候,业界普遍认为训长得长,端到端训练长文本的效果好于训练一个较短的模型再想办法搞长它。这种认知到 23 年下半年 long Llama 出现的时候才发生了转变。我们自己也进行了严格的验证,实际上短文本训练 + 长度激活具有更好的 Token Efficiency。自然 MoBA 设计中的第一个功能就成了时代的眼泪。
在这个时期,MoBA 的结构设计也是更为 “激进” 的,相较于现在的 “极简化” 结果,初提出的 MoBA 是一个带 cross attention 的两层注意力机制串行方案,gate 本身是一个无参的结构,但是为了更好的学习历史的 Token,我们在每个 Transformer 层加了一个机器间的 cross attention 以及对应的参数。
此时的 MoBA 设计已经结合了后面为大家熟知的 Context Parallel 思想(完整的上下文序列被存放到不同节点上,在需要计算的时候才集中在一起),我们将整个上下文序列平铺在数据并行节点之间,将每个数据并行节点内的 context 看成是一个 MoE 中的 expert,将需要 attention 的 Token 发送到对应 expert 上进行 cross attention 再把结果通信回来。我们将 fmoe(一种早期 MoE 训练的框架)的工作整合进了 Megatron-LM(来自 Nvidia 的现在通用大模型训练框架)来支持 expert 间通讯能力。
这个思路我们称之为 MoBA v0.5。
随着时间推进到 23 年 8 月初,主模型 pretrain 已经训练了大量 Token,再来一次成本不低,显著改变了结构并增加了额外参数的 MoBA 至此,第一次进入思过崖。
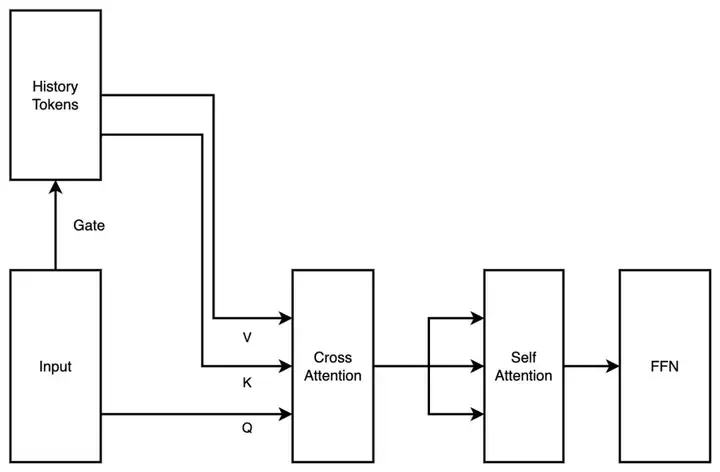
一个非常简单的 MoBA v0.5 的示意图
进入思过崖当然是一种戏称,是停下来寻找改进方案的时间,也是深入理解新结构的时间。第一次进思过崖悟道,进去的快,出来的也快。Tim 作为月之暗面点子王掏出了新的改进思路,将 MoBA 从串行两层注意力方案改并行的单层注意力方案。
MoBA 不再增加额外的模型参数,而是利用现有注意力机制参数,同步学习一个序列里面的所有信息,这样就可以尽可能不变动当前结构进行 Continue Training。
这个思路我们称之为 MoBA v1。
MoBA v1 实际上是 Sparse Attention + Context Parallel 的产物,在当时 Context Parallel 并不是大行其道的时候,MoBA v1 提现了极高的端到端加速能力。我们在 3B、7B 上都验证了它非常 work 之后,在更大模型 scale 水平上撞墙了,训练过程中出现了非常大的 lossspike。
我们初版合并 blockattention output 的方式过于粗浅,只是简单累加,导致完全无法和 full attention 对分进行 debug 没有 ground truth 的 debug 是极其困难的,我们用尽了各种当时的稳定性手段都不能解决。由于在较大的模型上训练出了问题,MoBA 至此二入思过崖。
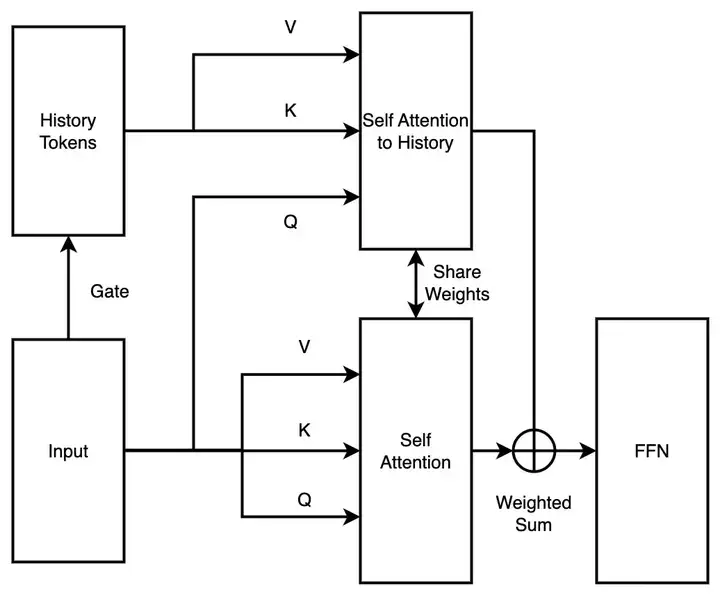
一个非常简单的 MoBA v1 示意图
第二次留在思过崖时间比较长,从 23 年 9 月开始,至出思过崖的时候已经到了 24 年初。但是在思过崖里并不意味着被放弃了,我得以体会到在月之暗面工作的第二大特色,饱和救援。
除了一直就在强力输出的 Tim 和裘老师,苏神、远哥以及各路大佬都参与进行激烈的讨论,开始拆解并修正 MoBA,首先被修正的就是那个简单的 Weighted Sum 叠加。
我们这里尝试过各种和 Gate Matrix 相乘相加的叠加搞法之后,Tim 从故纸堆里掏出了 Online Softmax,说这个应该能行。其中最大的一个好处是使用 Online Softmax 之后我们可以通过将稀疏度降低至 0 (全选所有的分块)来和一个数学等价的 Full Attention 进行严格对照 debug,这解决了大部分实现中遇到的难题。
但是上下文拆分在数据并行节点之间的这个设计依然会导致不均衡问题,一个数据 sample 在数据并行间平铺之后,第一个数据并行 rank 上的头部几个 token 会被后续茫茫多的 Q 发送进行 attend,带来极差的平衡性,进而拖慢加速效率。这个现象也有一个更广为人知的名字 -- Attention Sink。
此时章老师到访,听完我们的 idea 后提出了新的思路,将 Context Parallel 能力和 MoBA 切分开,Context Parallel 是 Context Parallel,MoBA 是 MoBA,MoBA 回归一个 Sparse Attention 本身而不是分布式 Sparse Attention 训练框架。
只要显存放得下,完全可以在单机上处理全部上下文,用 MoBA 来进行计算加速,通过 Context Parallel 的方式来组织和传递机器间的上下文。因此我们重新实现了 MoBA v2,基本已经是也是当前大家见到的 MoBA 的样子。
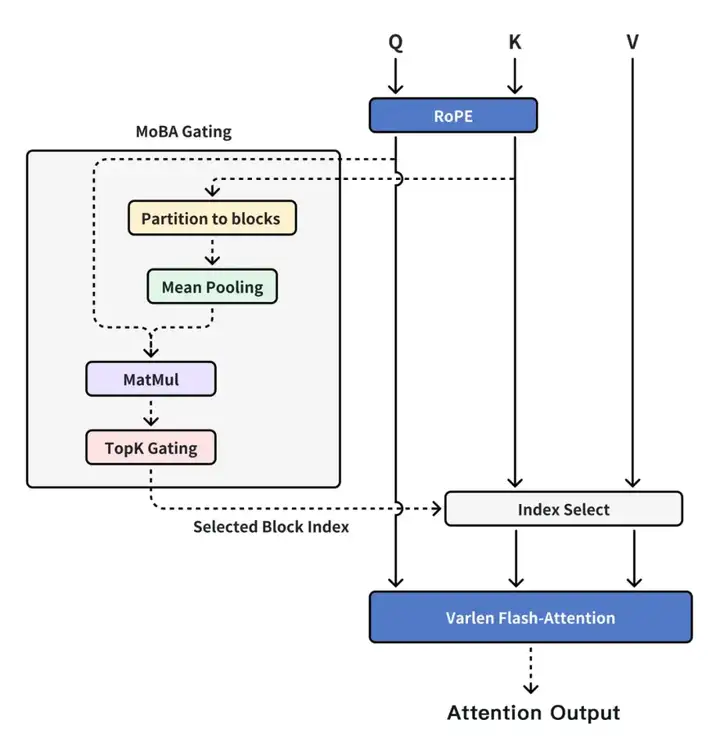
现在的 MoBA 设计
MoBA v2 稳定可训,短文本和 Ful Attention 可以完全对齐,Scaling Law 看起来非常可靠,而且比较丝滑的支持推广到线上模型上。我们因此 involve 了更多的资源进来,在经过了一系列的 debug 并消耗了 n 把 infra 组同学头发后,我们可以将经过 MoBA 激活后的 Pretrain 模型做到捞针测试全绿,在这一步我们已经觉得非常不错了,开始进行上线
但是最不意外的,只有意外。SFT 阶段部分数据带着非常稀疏的 loss mask(使得只有 1% 甚至更少的 Token 有训练用的梯度),这导致 MoBA 在大部分 SFT 任务上表现良好,但是越是长文总结类型任务,loss mask 越是稀疏,反应在出来的学习效率越是低下。MoBA 在准上线流程中被按下暂停键第三次进入思过崖。
第三次进入思过崖的时候其实最紧张,此时整个项目已经有了巨大的沉没成本,公司付出了大量的计算资源和人力资源,如果端到端最后长文应用场景出现问题,那么前期研究接近于打水漂。
幸运的是,由于 MoBA 本身优秀的数学性质,在新一轮饱和救援的实验 ablation 中,我们发现去掉 lossmask 表现就非常良好,带上 loss mask 表现就不尽如人意,进而意识到是带有 gradient 的 Token 在 SFT 阶段过于稀疏,从而带来的学习效率低下的问题,因此通过将最后几层修改为 full attention 来提高反向传播时带 gradient token 的密度,改善特定任务的学习效率。
后续其它实验证明这种切换并不会显著影响切换回来的 Sparse Attention 效果,在 1M 长度上和同结构 Full attention 各项指标持平。MoBA 再次从思过崖回归,并成功上线服务用户。
最后的最后,感谢各路大神的拔刀相助,感谢公司的大力支持以及巨量显卡。现在我们开放的出来的就是我们在线上用的代码,是一个已经经过了长期验证,因为实际需求砍掉了各种额外设计,保持极简结构但同时具备足够效果的 Sparse Attention 结构。希望 MoBA 以及它诞生的 CoT 能给大家带来一些帮助和价值。
Report:https://arxiv.org/abs/2502.13189
Code:https://github.com/MoonshotAI/MoBA
顺带借地方回答一些这两天频繁被人问到的问题,这两天基本麻烦章老师和苏神当客服回答问题了,实在过意不去,这里提取了几个常见问题一并回答一下。
1、MoBA 对 Decoding 无效吗?
MoBA 对 Decoding 是有效的,对 MHA 很有效,对 GQA 效果降低,对 MQA 效果最差。原理其实很简单,MHA 的情况下,每个 Q 有一个自己对应的 KV cache,那么 MoBA 的 gate 在理想情况下是可以通过摊余计算在 prefill 算好并存储每个 block 的代表 token,这个 token 在后续都不会变动,因此所有的 IO 基本可以做到只来自 index select 之后的 KV cache,这种情况下 MoBA 的稀疏程度就决定了 IO 减少的程度。
但是对于 GQA 和 MQA,由于一组 Q Head 实际上在共享同样的 一份 KV cache,那么在每个 Qhead 能自由选择感兴趣 block 的情况下,很有可能填满了由稀疏性带来的 IO 优化。比如我们思考这么一个场景:16 个 QHead 的 MQA,MoBA 刚好切分整个序列到 16 份,这意味着当最坏情况每个 Q head 感兴趣的分别是序号从 1 到 16 的每个上下文块,节省 IO 的优势就会被磨平。能自由选择 KV Block 的 Q Head 越多,效果越差。
由于 “自由选择 KV Block 的 Q Head” 这么个现象存在,天然的改进想法就是合并,假设大家都选一样的 block,那不就净赚 IO 优化了么。对,但是在我们实际测试下,尤其是对于已经支付了大量成本的预训练模型,每个 Q head 都有自己独特的 “品味”,强行合并不如从头重新训练。
2、MoBA 默认是必选 self attention,那么 self 的邻居会必选吗?
不会必选,这个是已知会产生些许疑惑的地方,我们最后选择相信 SGD。现在的 MoBA gate 实现非常直接,有感兴趣的同学可以简单改造 gate 使其必选上一个 chunk,但我们自己测试这个改动带来的收益比较 margin。
3、MoBA 有 Triton 实现么?
我们实现过一个版本,端到端性能提升 10%+,但是 Triton 的实现想要持续维护跟上主线的成本比较高昂,我们因此多次迭代后暂缓进一步优化它。
原文链接:https://www.zhihu.com/question/12696635711
文章来自于“AI产品阿颖”,作者“Andrew Lu”。



