# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Web Agent是这样一种特殊的智能体:它借助AI自动控制你的浏览器,并完成你“交代”的任务。比如帮你挑选一部最新的iPhone或者到旅行网站预订机票。这样的智能数字助手,无论是对生活还是工作,未来无疑都具有重大的意义。当前有大量的研究正针对这种Agent展开,本文就来聊聊其最新进展及DeepSeek的应用。
Web Agent是一种工作在UI层的AI智能体。在当前语境下,你可以认为它就是由大模型所驱动(LLM/VLM,大语言模型/多模态的视觉语言模型),能够自主的理解任务、推理并模拟人类在浏览器中的操作,最终完成任务目标。比如一个简单的任务:
“到Apple公司网站上了解最新的iPhone16e的价格信息"
这样一个任务需要Web Agent自动完成如下任务步骤:
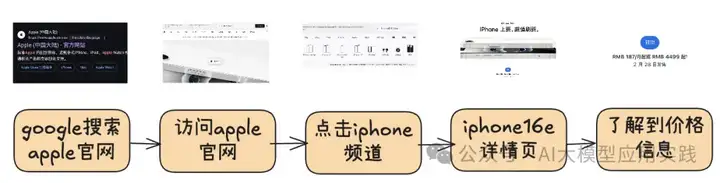
如果你了解RPA(机器人流程自动化),可以把Web Agent看作是一种大模型驱动的更灵活的RPA机器人。
Web Agent的工作过程与原理看下图,如果你熟悉ReAct范式的Agent应该会似曾相识,即通过Thought(思考)->Action(行动)->Observation(观察)这样的推理循环来逐步完成任务,在过程中会不断的动态调整自己的行为。
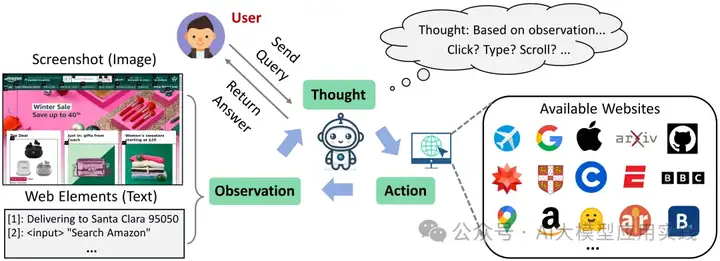
但Web Agent与我们熟知的ReAct Agent的差异主要在于:
其他的一些差异总结:

针对Web Agent上述的能力要求,你需要有不同于传统Agent的解决方案:
Observation
这是Web Agent的“眼睛”。其作用是把看到的屏幕内容(WebUI)转化为可以让“大脑”(LLM/VLM)用来推理出预期操作的结构化信息。
为什么简单的多模态模型的推理是不够的?
你可能会想到直接把屏幕动态截图让VLM来推理行动,但这是不够的。因为Agent需要推理的下一步动作,不能仅仅是简单的语言描述。如:
“点击屏幕右边的搜索按钮进入下一步”,
而是可以让浏览器接口来执行的更精准的结构化信息,如:
{ "description":"启动搜索",
"type":"click",
"position":{"xpath":"按钮的xpath路径"}
}
而这里的很多信息比如元素位置,是直接的屏幕截图无法提供的。
目前可以看到两种解决方案:
推理是大模型发挥作用的地方。其目的是根据观察到的结果(Observation提供的结构化页面信息),来推理出下一步交互动作。这通常也有两种选择:
Web Agent的动作执行是借助浏览器来实现自动化的web访问与操作,通常借助一些浏览器控制工具(常被用于自动化测试):
如果你需要尝试构建一个Web Agent,这里首先介绍两个工具:
OmniParser
微软推出的一个纯视觉方案的屏幕解析工具,帮助把UI屏幕转化为结构化的格式。其核心是一个微调过的视觉模型(不是语言模型),训练数据集来自一些热门的网页截图及其标注信息。
OmniParser的输出是一个经过标注的新图片与结构化的描述:
结构化的描述信息如下:

但是注意OmniParser只是提供了上述“Observation”部分的解决方案,并不是端到端的Agent开发框架,推理与行动需要自行实现,不过在最新的V2版本中提供了Agent例子与工具。
Browser-use
一个端到端的构建Web Agent的框架。其在WebVoyager的基准测试中取得了最好的性能(WebVoyager本身也是一个Web Agent开发框架,但自带了可用于基准测试的任务数据)。官方公布Browser-use的任务准确率对比结果如下:
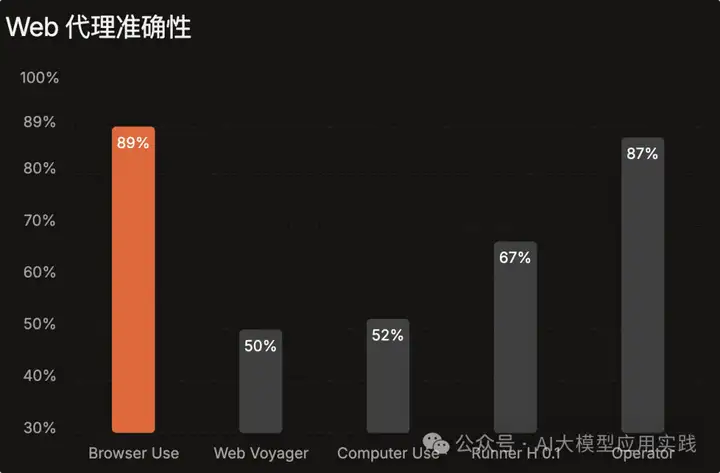
Browser-use采用的技术栈为:
实现Web Agent
我们来构建一个采用DeepSeek模型的Web Agent,基于Browser-use可以非常快速的实现这个Agent:
from langchain_openai import ChatOpenAI
from browser_use import Agent
from dotenv import load_dotenv
from browser_use import Agent
from pydantic import SecretStr
load_dotenv()
import asyncio
llm_deepseekv3 = ChatOpenAI(base_url='https://api.deepseek.com/v1',model="deepseek-chat",api_key=SecretStr('sk-*'))
async def main():
agent = Agent(
task="Learn about the latest price information for the iPhone 16e on Apple's website.",
llm=llm_deepseekv3,
use_vision=False
)
result = await agent.run()
print ("\n===============Final Result===============\n")
print(result.final_result())
asyncio.run(main())
一个最基本的Web Agent创建就是这么简单!
简单测试
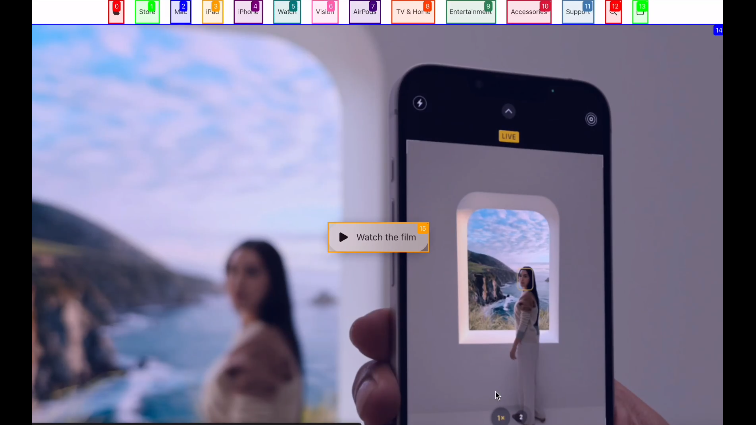
首先看下运行的效果,可以看到Agent会自动打开浏览器窗口,然后去完成这里的简单任务。在任务执行过程中,可以看到每打开一个页面,页面元素随后会被标记(如下面视频中展示的带有不同颜色与数字的小box),这是一个结构化信息转换过程。随后大模型会推理下一个步骤,直到任务完成。
我们在后台跟踪LLM的输出,可以看到每一个步骤(step)的过程,比如Step 2:
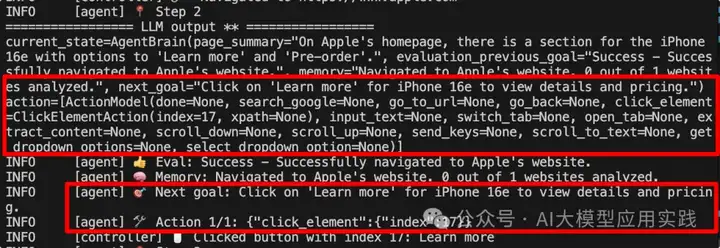
这个输出中可以看到:
经过多次这样的迭代,最后成功获得了输出:

其他模型测试
我们对一些其他模型进行尝试,结果如下:
观测到的一些结果与我们的判断包括:
关于deepseek-r1的特殊应用
直接使用deepseek-r1未能成功测试,但Browser-use框架支持一个特性,即允许在主推理模型之外设定一个辅助规划的大模型(Planner_llm)。其作用是在必要的时机(可以设置,比如每3步让Planner_llm参与)充当”参谋”,即根据当前状态分析并给出后续的计划建议,这个计划会被主模型用来参考,以推理真正的行动步骤:
...
planner_llm = ChatOllama(model="deepseek-r1")
async def main():
agent = Agent(
...
planner_llm=planner_llm,
planner_interval=3,
)
...
我们让ollama中的deepseek-r1帮助规划,最终也可以测试成功。如果你感兴趣,可以使用browser-use自带的评估程序,来评估增加Planner_llm后是否能够带来复杂任务准确性的提升。
以上我们详细阐述了Web Agent的技术原理,以及一些实现方法,并借助开源框架构建了基于DeepSeek的测试Web Agent。Web Agent是一种有着极高推理能力要求的智能体,在当前条件下,必须承认无论是端到端的性能表现,还是面对复杂任务的稳定性,都还有着巨大的提升空间。期待未来随着多模态大模型及推理模型的不断演进与增强,这些存在的问题都会得到完美的解决。
文章来自于“AI大模型应用实践”,作者“曾经的毛毛”。




【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
