# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
当DeepSeek引发业界震动时,元始智能创始人彭博正专注于一个更宏大的愿景。
在他看来,某个模型的爆火只是AI进化的一个普通节点,真正的技术革命才刚刚开始。
作为RWKV架构的缔造者,他的目光已经投向未来的芯片底层革命。
目前在产业界,已有海外独角兽企业开始将RWKV应用于商业实践。
这个故事要从Transformer说起,一个正在被不断挑战的AI铁王座……
以下为量子位与元始智能彭博的对话实录整理:
本对谈主体发生于2025年1月R1发布前,星标部分为2025年2月补充。
△彭博的github主页
量子位:能不能先给大家介绍一下RWKV是一个什么样的模型?
元始智能彭博:要了解RWKV,得先从Transformer说起。目前主流大模型包括GPT、Llama这些,都是用的Transformer架构。
Transformer包含两个主要部分:随序列长度增加而变慢的attention机制,和速度显存恒定的FFN全连接网络。
Transformer的attention机制就像考试时候开卷查资料,每写一个字都要翻一遍书,KV cache越来越大,效率自然就上不去。这种方式确实适合做翻译这类需要明确对应的任务。
但是RWKV的思路就更像口试了——模型不能随意重读前文——必须用一个固定大小的state来存储和更新信息。口试的方式难度更大,但它迫使模型更去真正理解,而不是简单地查找匹配。
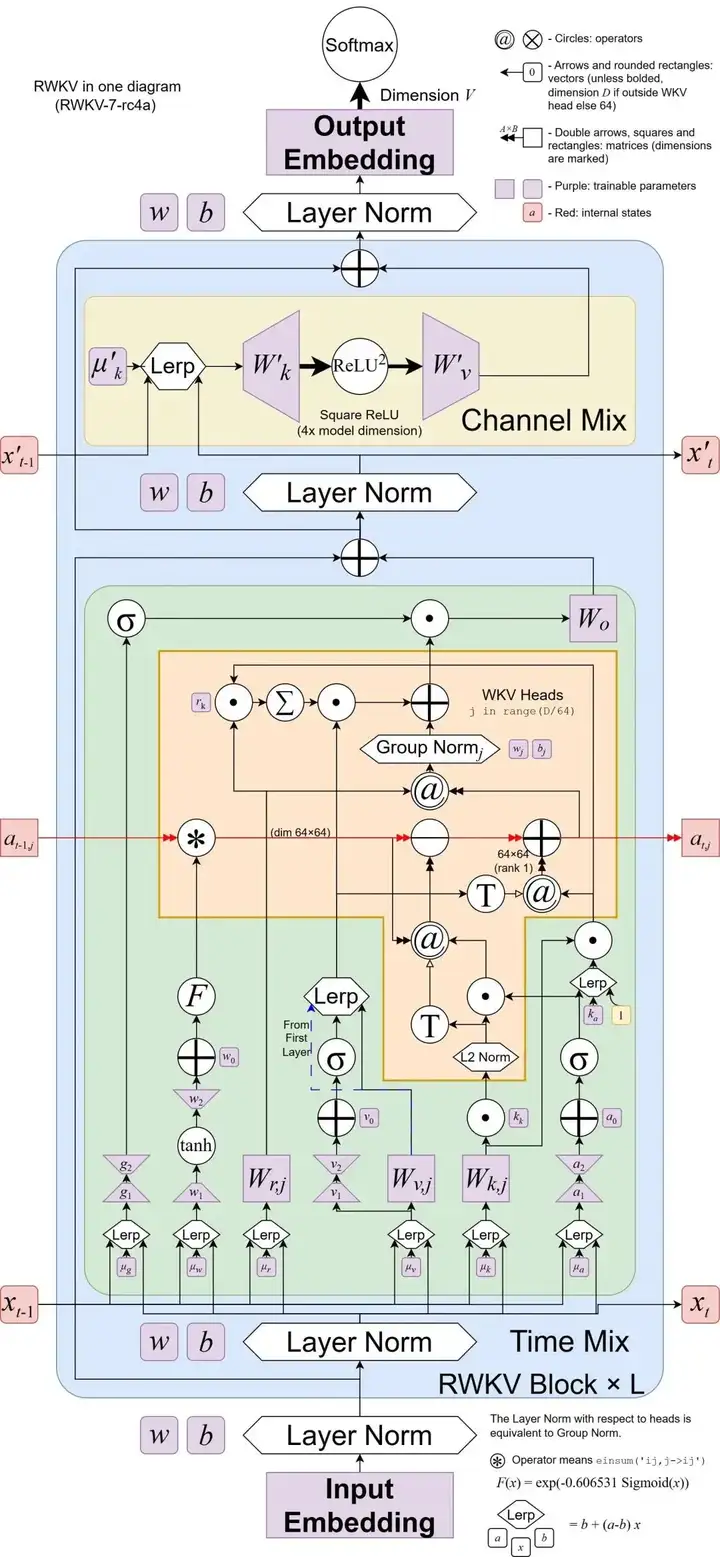
△RWKV-7模型架构图
量子位:Transformer架构能够取得行业主流地位,这里面有多大偶然性和必然性?
元始智能彭博:是必然的。
你看Transformer一开始是设计来做翻译的,这个思路挺不错。它在生成内容的时候不断去前文找需要的信息,这很适合翻译,也包括写文章、写代码这些需要上下文关联的任务。
但问题也很明显。前文越来越长,每生成一个token都要看一遍,速度和内存消耗肯定会越来越大。
你看我们人类,活了几十年,话说多久都不会越来越慢,为什么?因为我们会自动筛选重要信息,不会所有事都记着。
我们会把必须记住的事情记在外部记忆,例如记事本,手机电脑,等等。
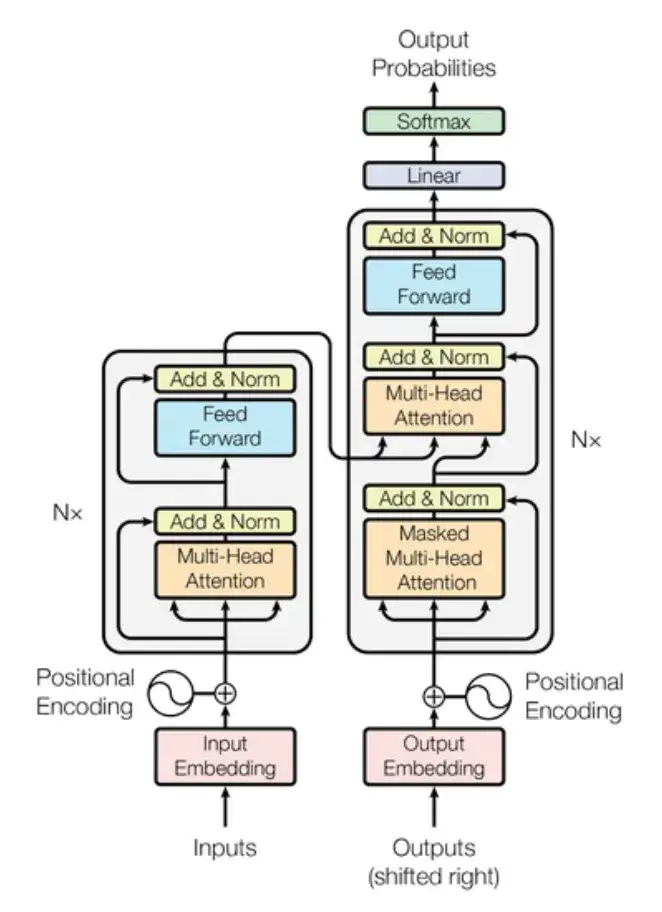
△Transformer模型架构图
量子位:有观点认为Transformer的高性能正是源于其注意力机制,你如何看待这一说法?
元始智能彭博:这么说不太准确。Transformer确实在做那些需要明确对应关系的机械性的任务时表现不错。
但是RWKV通过RL一样能做到这些,它也可以学会使用外部记忆,学会在需要的时候重新查看前文。
从前大家认为Transformer做不了System 2,现在RL+CoT就推翻了这种说法。对于RWKV也会发生类似的事情。
量子位:Transformer的发展历程中,从最初的论文到GPT系列的成功,有哪些关键节点?
元始智能彭博:这是个一步步发展的过程。从最开始做机器翻译,到BERT的突破,再到GPT系列,后来还有ViT等等多模态应用,每一步都在扩展边界。
有意思的是,在GPT-3出来的时候,大家的反应不热烈,即使它已经拥有了现在的很多能力,例如从指示生成网页的能力。
GPT-2有人关注了,GPT-3更多人关注了,但主要还是在学术圈子里。直到ChatGPT出来,让普通人真正体验到了这个技术,才算是真正爆发了。
现在DeepSeek R1的出圈,也是类似的道理。*
△DeepSeek登顶美区苹果应用商店
量子位:下一个取代Transformer的架构是否需要经历同样的发展路径?
元始智能彭博:完全不需要。现在可以走个更直接的路径——把各种模型的attention直接换成RWKV,尤其是RWKV-7,效果就能更好,其他的都不用动。
而且RWKV-7在训练上特别稳定,这也是个优势。我们做实验发现,其他新架构比如Mamba经常会出现spike,但RWKV-7一直特别稳。
例如,有团队把Qwen 2.5的attention迁移到RWKV架构,训练一天就能达到70%的效果,如果多练几天能到80%,再练会更好,这个效率是很高的。
量子位:RWKV的核心优势在哪些方面?
元始智能彭博:从RWKV-7开始,我们不仅是效率更高,效果也更好。存在两类问题是更适合RWKV去解决而Transformer不适合解决的:
第一是state tracking,就是状态跟踪。例如下棋需要持续对棋盘状态进行跟踪,用Transformer需要堆多层才能解决,但在理论上可以证明RWKV一层就够了(当然,用多层仍然会效率更好,这里比较的是模型每一层的表达力)。
第二是长期CoT,就是思维链推理。RWKV可以保持固定的显存和速度,做超长推理。比如我们社区最近有人用RWKV小模型做400万token的CoT解决了“全世界最难的数独”,这个量级用Transformer做就效率低。

△RWKV数独官网页面
用稀疏attention可以(例如最近的NSA,MoBA),不过,稀疏attention进一步进化,就是RWKV这种路线,最终会殊途同归。*
量子位:面对低成本、高性能和并行计算的“不可能三角”,RWKV如何突破?
元始智能彭博:这个确实挺难的,但不是完全不能并存。你看人类就是一个很好的例子,我们既低成本又高性能,我们的训练也很高效(但注意,和深度学习的训练方法不同,这是很神秘的)。
现在机器人替代人的进程为什么这么慢?就是因为人太便宜了,如果人很贵的话,大家早就都用机器人了。
我们只能逐步突破这个不可能三角,因为它确实有道理——你不能什么都要。对于复杂模型,并行化有难度,这是RWKV每一代都要去解决的核心问题。
设计每一代RWKV是很简单的,怎么让它高效并行化、高效训练、高效推理才是真正的难点。
我们可以把这个三角做得越来越大,把三个边都同时尽量撑一撑。特别是以后配合模拟计算,量子计算,还是可以做一些奇妙的事情。
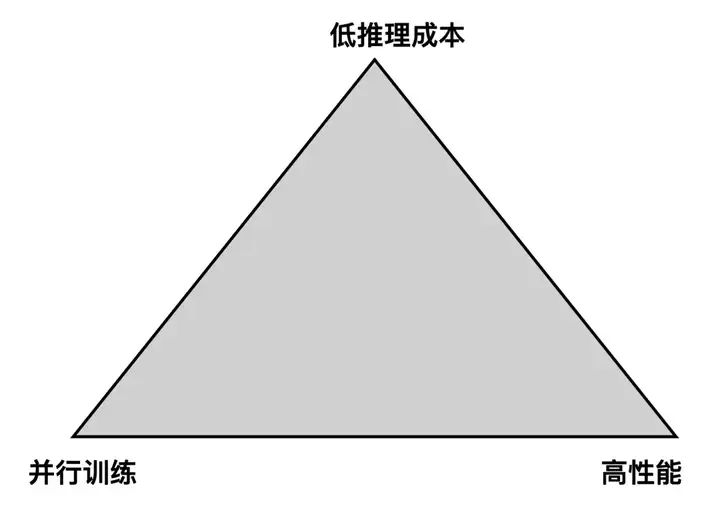
△大模型“不可能三角”
量子位:并行化上的挑战会影响RWKV的规模化训练吗?
元始智能彭博:RWKV-7的scaling特别好。因为一个很明显的好处是,模型越来越大的时候,它的state也会越来越大,那么工作记忆力会越来越强。
从前大家经常说RWKV的记忆力不好,但7代明显好很多。我们做了大海捞针的测试,用一个0.1B的特别小的模型,在4K的上下文训练,它做16K的大海捞针也可以完美捞针。

△RWKV-7-World 0.1B(L12-D768)无需微调完美通过ctx 16k的大海捞针
量子位:在提升并行性方面,RWKV做了哪些工作?
元始智能彭博:这个在技术上会越来越复杂,我们一直会写CUDA代码来解决。
我们跟国内所有主要AI芯片公司都有群,他们都在密切关注和试验RWKV的推理和训练,因为它代表下一代模型的发展方向。
预计25年下半年会有一种存内计算的新芯片,特别适合跑RWKV这种模型。到时候大家会看到,这对RWKV的推广会很有利。
量子位:作为非架构师,我们应该怎么判断一个创新架构的发展潜力, 有哪些指标是最关键的?
元始智能彭博:对于大多数人,最好的指标仍然是看大厂用不用。普通用户不关心架构,只关心效果。真正能评判的是模型公司。
理论上模型的表达能力是可以从数学和理论去评估,但理论和实际总是有差距。AI发展太快太复杂了,理论常常跟不上实际情况。
量子位:商业验证会是衡量的最重要标准吗?
元始智能彭博:这确实是最实际、最有说服力的标准,因为这个大家不得不信。比如说如果大商业公司用RWKV,那就是一个非常实际的证据,我就不用去说服各方了。
所以我也不希望去说服人,因为说服人其实是很浪费口舌的事情,大家最终还是要看实际的事情。
其实现在AI的成本还是太高,需要再降10000倍,这需要很多年。部署技术的优化、成本的降低,这才是真正的壁垒。
例如DeepSeek在R1之前,到V3都只有少数前沿研究者关注,直到R1才出圈火爆。而且我们现在也看到,各家都上线了R1,然后就是比拼部署和推理成本。*
量子位:在众多创新模型中,RWKV的商业化身位如何?
元始智能彭博:在新架构方面,我们一直有领先优势,这来自我们持续迭代的能力。
很多团队会基于现有技术做一些缝缝补补,但真正能持续向前推进持续做很多代架构的团队,我们似乎是全球唯一的。
你看现在的发展趋势,Mamba 2已经和RWKV-6非常接近了,如果有Mamba 3很可能会和RWKV-7几乎一模一样。
不光是Mamba,还有一些其他包括海外的新工作都在朝着RWKV的方向走。例如最新的Titans类似RWKV-7。
这是因为什么?因为类RWKV的技术路线已经形成了共识。大家用不同的名字,但都在同一条路上走。
△非transformer创新架构盘点
量子位:目前RWKV有什么实际的商业应用案例吗?
元始智能彭博:我们了解到有个海外独角兽公司在用RWKV做线上部署的模型,他们CTO前不久专门来香港找我,但他们目前不想公开这事。
因为他们觉得这是他们的独特优势,因为现在很多人还没意识到RWKV有多好用。他们用了之后发现效率提升很明显,效果也完全满足他们的需求,商业上就非常理想。
量子位:有观点认为不同模型各有优势,比如云端适合Transformer,端侧适合RWKV,你怎么看?
元始智能彭博:其实各种场景都更适合RWKV。我们现在主要做端侧小模型,只是因为训练成本低。
但大家已经找到方法,可以把Transformer模型快速迁移到RWKV这种新架构上,只需要很少的训练就能适配。所以这不是架构的局限,而是我们在不同发展阶段做不同的事情。

△RWKV社区数据
量子位:元始智能在AI行业的生态定位是什么?
元始智能彭博:其实,我们的定位是架构公司,我们不是普通的模型公司,虽然目前我们会训练一些模型,但只是为了证明我们架构的能力。
我们的上游是芯片,下游是模型公司。我们和模型公司不是一个生态位,所以我们会技术支持模型公司用RWKV架构,也会分享我们的训练经验。
我们目前只有十几个全职成员,随着我们越来越大,我们才会逐步做各个方面,包括2B和2C应用等等。
我们有点像CPU的RISC-V指令集,或者比如说5G、6G的标准。就等于说我们做5G、6G、7G一代代做下去,但我们自己不一定要去生产具体的通信产品。
为什么现在主要训练端侧小模型?一个是我们希望不要浪费钱,因为RWKV架构还在不断改进,另一个是这种事让大厂做最合适,他们有更优质的数据和充足预算。
量子位:目前这个技术路线的验证情况如何?
元始智能彭博:现在已经有50多篇第三方论文验证了RWKV的效果,在我们官网都有,覆盖了语言、图像、视频、动画、3D、语音、时间序列各种模态。
例如,腾讯优图就用RWKV做了文生3D多人动画,蚂蚁用它做文本压缩。只要你现在用的模型里有attention,换成RWKV都能提升效率效果,我们也提供技术支持。
△RWKV在多种场景50余篇论文
量子位:Deepseek的爆火对RWKV的发展路径会产生怎样的影响?
元始智能彭博:其实不会有影响,Deepseek-R1是模型,我们是架构。他们的爆火一方面是底层实现的优化,一方面是数据和RL对齐做得好。
他们用MoE降低了训练成本和部署的算力需求,让门槛更低了,今年各家都会有超过R1的模型,任何公司都没有壁垒,不需要神话任何公司。
量子位:如果大厂普遍采用Deepseek,他们还会有动力尝试新的模型架构吗?
元始智能彭博:我举个例子,其实MoE现在已经过时了,有更先进的技术,例如Meta的Memory+,字节的UltraMem,就是很好的方向,大家很快就会继续往前走。
觉得DeepSeek会一家通吃的想法,就像从前看到ChatGPT出来就觉得应该全部人投降一样,实际上AI直到现在仍然还在非常初级的阶段,谈这些还太早太早了。
量子位:Deepseek通过市场验证获得了生态优势,这会形成某种护城河吗?
元始智能彭博:开源模型是肯定赢的,但不能有速胜速败的想法,不夸张地说,对于AI的探索,还有至少几十年的路要走。
让绝大多数人失业不需要很久,但这不代表所有事情都做完了,我们应该有更高的追求。
之前Llama出来时,大家也会问是否可以形成生态壁垒,但其实这里根本不存在用户忠诚度。
现在大家从其它模型切到R1,其它模型有壁垒吗?以后大家从R1切到其它模型,R1会有壁垒吗?
量子位:你认为大模型创新的下一个战场在哪里?
元始智能彭博: 在芯片层面。2025年下半年会有新一代的存内计算芯片出现,这对RWKV的推广会很有利。
我们已经和国内所有主要芯片公司建立了联系,他们都在密切关注和试验RWKV,因为大家能看出来这是下一代模型的发展方向。
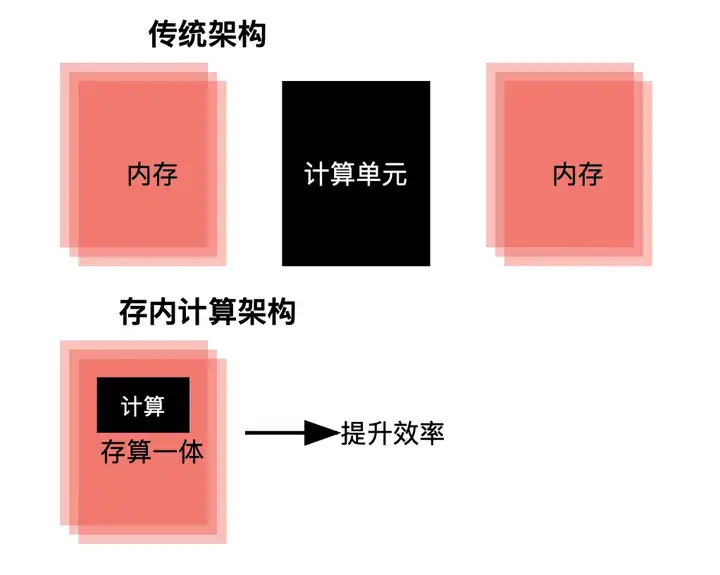
△存内计算芯片示意
量子位:AI的真正智能是什么,你怎么看?
元始智能彭博:真正的智能是能打破常规,找到完全超出现有思维的,前人想不到的解决方案。现在的AI模型与人类的创造能力还有很大差距。
而且人类学习效率特别高,看到的有效数据比大模型少得多,但我们能很快学会,并形成真正的理解。
说实话,流浪小动物适应环境的生存能力体现出的智能都比现在的AI模型要更多。
量子位:你曾说过”真正的智能一定是打破常规的”,这个判断从何而来?
元始智能彭博:举个例子,虽然现在看上去我们不可能正常赢下棋AI,但仍然可以构造出一些下棋局面让人类能赢最强的AI。
为什么?因为有些特殊局面可以转化成数学问题来解,但纯粹的下棋AI意识不到这一点。
人类的一个特别之处就在于能跳出既定的思维框架,这是现在的AI系统还做不到的。
量子位:最近DeepSeek和GPT的下棋对战引起了很多关注,DeepSeek用了一些规则之外带有欺骗性的手段获胜,让很多人觉得非常聪明,这更接近打破常规了吗?
元始智能彭博:这仍然是从人类知识里学的,通过RL可以进一步找到令人眼前一亮的人类没想过的方法,但还是在既有规则内。
所谓打破常规,是在我们之前不知道有路的地方,走出新的路。
△DeepSeek执黑,“策反”对方棋子
量子位:下一代超级智能会是什么样子?
元始智能彭博:这需要逐步完全突破现有框架。例如,我规划的RWKV后续十几代迭代中,包含了如何实现真正有生命、有灵性的系统。
这不仅关乎智能,也关乎某些更重要的问题。单纯追求所谓智能,但实际可能是偏颇的智能,而不考虑其他因素是短视的。
量子位:Transformer的主流地位是否可复制?会不会不再有下一个一家通吃的绝对主流模型了?
元始智能彭博:一直会有更好的架构出现。我们可以想想,人类星际旅行的时候,难道还在用Transformer吗?不可能,肯定会有新架构。
在这个过程中,某些代的RWKV成为绝对主流完全可能。我已经规划了RWKV十几代的迭代路线,我关注长线。
往后的发展,还涉及新硬件。需要形成循环,设计新硬件的时候,可以考虑新架构的特点;设计新架构时,也会考虑硬件的特性。这种互相促进的关系很重要。
正确的目标是,寻求最适合我们这个宇宙物理定律的架构。
量子位:现在越来越多模型都在走向混合路线,你如何看待这个趋势?
元始智能彭博:最近MiniMax训练了混合模型,他们之前有个PPT猜测其实GPT-4o可能已经是混合模型,但OpenAI不会公布这些信息,所以我们无法知道。

△MiniMax-01技术文档
量子位:混合架构会是目前更好的答案吗?
元始智能彭博:这个有点像汽车,RWKV 7就像新能源车,Transformer相当于燃油车。现在燃油车逐渐被淘汰,混合动力车不少,纯电动车也不少,我觉得后续首先会比较像这种情况。
长远来看混合肯定只是过渡,未来一定是纯电动,或者说纯的新能源,不一定是电动,可能未来还有更先进的能源。因为人类是不断在发展的。
量子位:为什么纯粹attention-free架构就一定更先进?
元始智能彭博:因为softmax attention本身就是一个很有局限的设计,不仅仅是效率的限制,还包括效果和表达力的限制,这些都在数学上可以证明。
在我看来,一种好的方案,是用RWKV作为大脑,作为驱动,然后调用外部记忆,调用外部工具,这些都可以用RL自动学会,且能实现完美的无限记忆。
如前所述,从前大家认为transformer做不了System 2,现在就被CoT+RL解决了。RWKV的情况也会是如此。
文章来自于“量子位”,作者“量子位智库”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
