# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Transformer 很成功,更一般而言,我们甚至可以将(仅编码器)Transformer 视为学习可交换数据的通用引擎。由于大多数经典的统计学任务都是基于独立同分布
(iid)采用假设构建的,因此很自然可以尝试将 Transformer 用于它们。
针对经典统计问题训练 Transformer 的好处有两个:
近日,MIT 的三位研究者 Anzo Teh、Mark Jabbour 和 Yury Polyanskiy 宣称找到了一个可以满足这种需求 「可能存在的最简单的这类统计任务」,即 empirical
Bayes (EB) mean estimation(经验贝叶斯均值估计)。

该团队表示:「我们认为 Transformer 适用于 EB,因为 EB 估计器会自然表现出收缩效应(即让均值估计偏向先验的最近模式),而 Transformer 也是如此,注意
力机制会倾向于关注聚类 token。」对注意力机制的相关研究可参阅论文《The emergence of clusters in self-attention dynamics》。
此外,该团队还发现,EB 均值估计问题具有置换不变性,无需位置编码。
另一方面,人们非常需要这一问题的估计器,但麻烦的是最好的经典估计器(非参数最大似然 / NPMLE)也存在收敛速度缓慢的问题。
MIT 这个三人团队的研究表明 Transformer 不仅性能表现胜过 NPMLE,同时还能以其近 100 倍的速度运行!
总之,本文证明了即使对于经典的统计问题,Transformer 也提供了一种优秀的替代方案(在运行时间和性能方面)。对于简单的 1D 泊松 - EB 任务,本文还发现,即使是参数规模非常小的 Transformer(< 10 万参数)也能表现出色。
泊松 - EB 任务:通过一个两步式过程以独立同分布(iid)方式生成 n 个样本 X_1, . . . , X_n.
第一步,从某个位于实数域 ℝ 的未知先验 π 采样 θ_1, . . . , θ_n。这里的 π 的作用是作为一个未曾见过的(非参数)隐变量,并且对其不做任何假设(设置没有连
续性和平滑性假设)。
第二步,给定 θ_i,通过 X_i ∼ Poi (θ_i) 以 iid 方式有条件地对 X_i 进行采样。

通过 Transformer 求解泊松 - EB
简单来说,该团队求解泊松 - EB 的方式如下:首先,生成合成数据并使用这些数据训练 Transformer;然后,冻结它们的权重并提供要估计的新数据。
该团队表示,这应该是首个使用神经网络模型来估计经验贝叶斯的研究工作。
理解 Transformer 是如何工作的
论文第四章试图解释 Transformer 是如何工作的,并从两个角度来实现这一目标。首先,他们建立了关于 Transformer 在解决经验贝叶斯任务中的表达能力的理论结
果。其次,他们使用线性探针来研究 Transformer 的预测机制。
本文从 clipped Robbins 估计器开始,其定义如下:
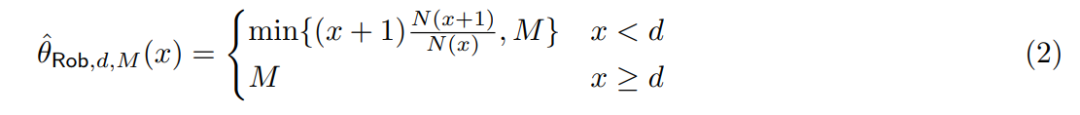
得出:transformer 可以学习到任意精度的 clipped Robbins 估计器。即:

类似地,本文证明了 transformer 还可以近似 NPMLE。即:
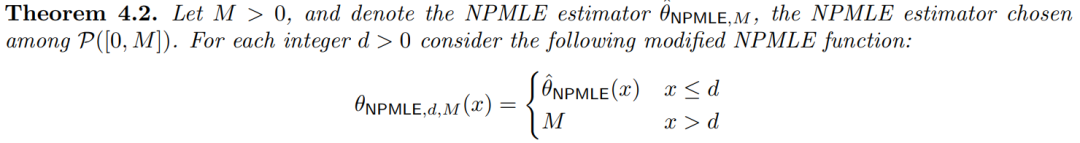
完整的证明过程在附录 B 中,论文正文只提供了一个大致的概述。
接下来,研究者探讨了 Transformer 模型是如何学习的。他们通过线性探针(linear probe)技术来研究 Transformer 学习机制。

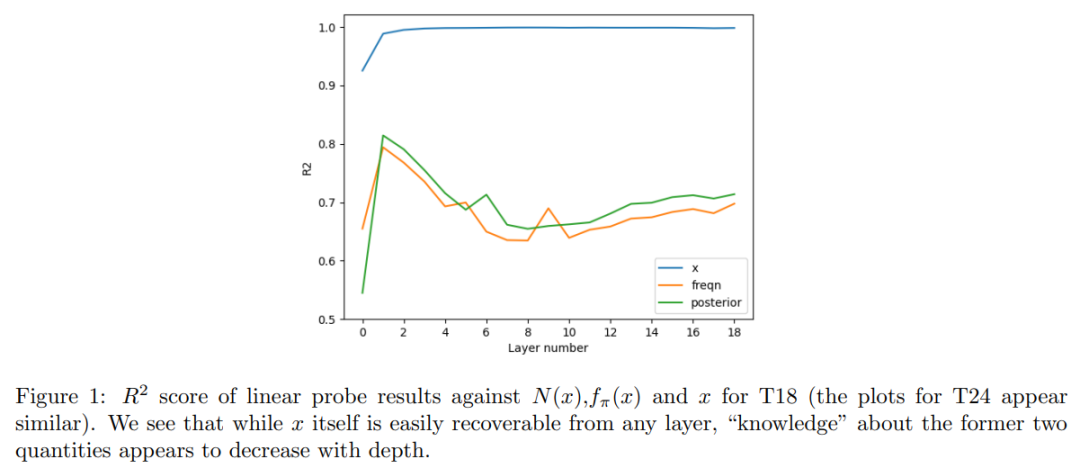
总结而言,本章证明了 Transformer 可以近似 Robbins 估计器和 NPMLE(非参数最大似然估计器)。
此外,本文还使用线性探针(linear probes)来证明,经过预训练的 Transformer 的工作方式与上述两种估计器不同。
合成数据实验与真实数据实验
表 1 为模型参数设置,本文选取了两个模型,并根据层数将它们命名为 T18 和 T24,两个模型都大约有 25.6k 个参数。此外,本文还定义了 T18r 和 T24r 两个模型。

在这个实验中,本文评估了 Transformer 适应不同序列长度的能力。图 2 报告了 4096 个先验的平均后悔值。
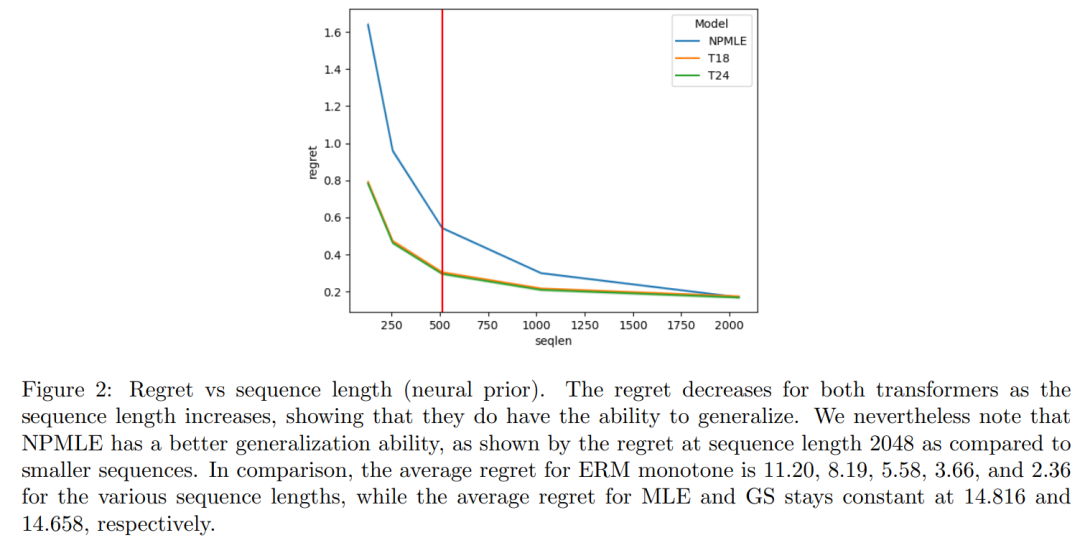
图 6 显示 transformer 的运行时间与 ERM 的运行时间相当。
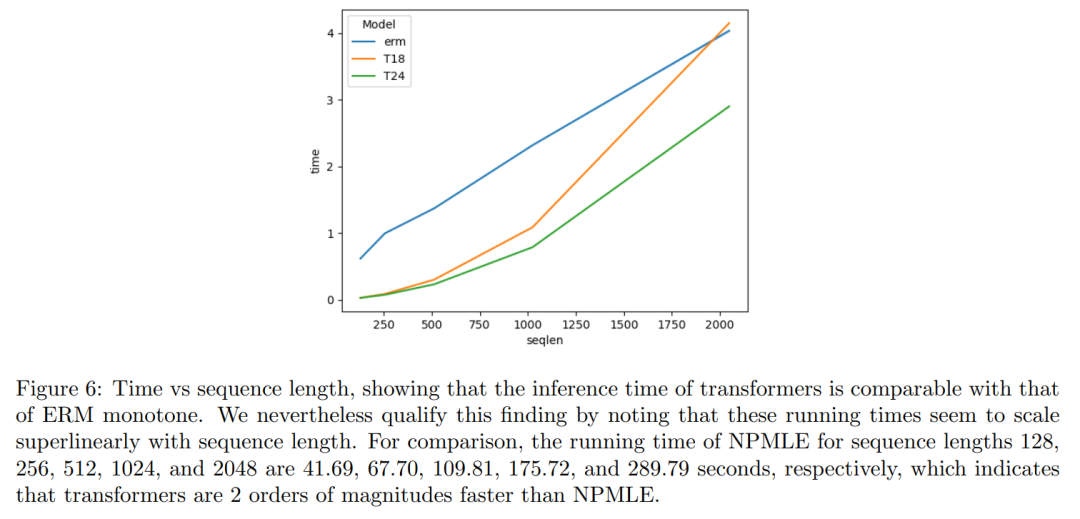
合成实验的一个重要意义在于,Transformer 展示了长度泛化能力:即使在未见过的先验分布上,当测试序列长度达到训练长度的 4 倍时,它们仍能实现更低的后悔
值。这一点尤为重要,因为多项研究表明 Transformer 在长度泛化方面的表现参差不齐 [ZAC+24, WJW+24, KPNR+24, AWA+22]。
最后,本文还在真实数据集上对这些 Transformer 模型进行了评估,以完成类似的预测任务,结果表明它们通常优于经典基线方法,并且在速度方面大幅领先。
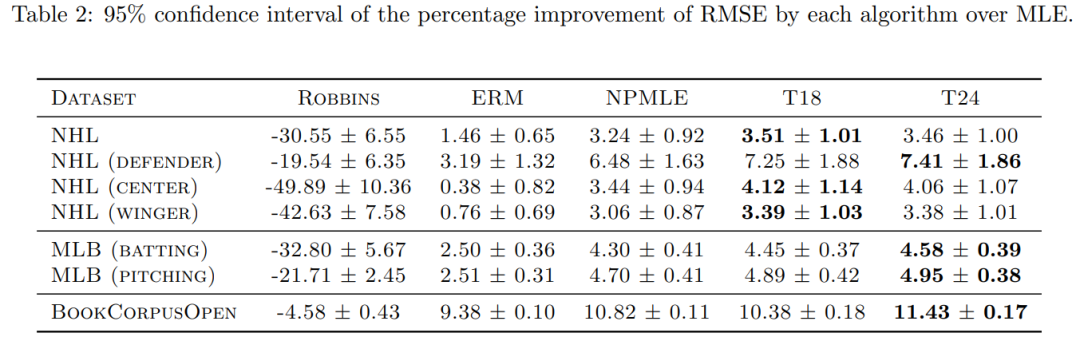
从表 3 可以看出,在大多数数据集中,Transformer 比传统方法有显著的改进。
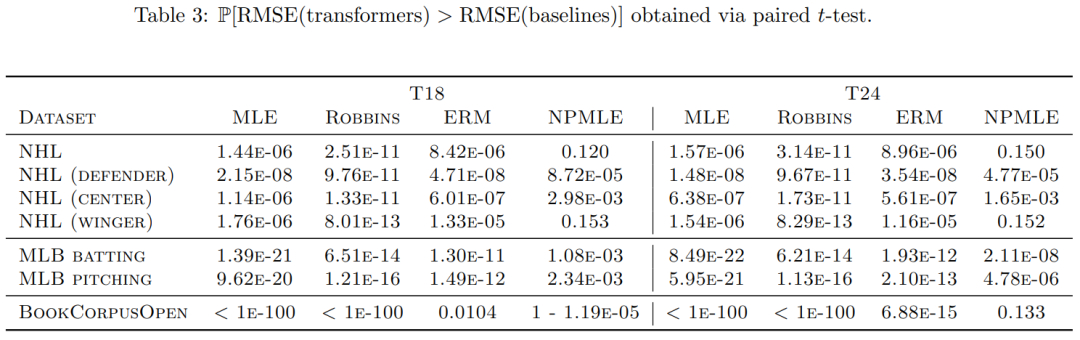
总之,本文证明了 Transformer 能够通过上下文学习(in-context learning)掌握 EB - 泊松问题。实验过程中,作者展示了随着序列长度的增加,Transformer 能够
实现后悔值的下降。在真实数据集上,本文证明了这些预训练的 Transformer 在大多数情况下能够超越经典基线方法。
文章来自于微信公众号 “机器之心”,作者 :机器之心编辑部



