# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
o1/DeepSeek-R1背后秘诀也能扩展到多模态了!
举个例子,提问多模态大模型:“什么宝可梦可以释放技能十万伏特”时,模型通过推理过程准确找出皮卡丘对应的坐标框,展示出模型的泛化能力。
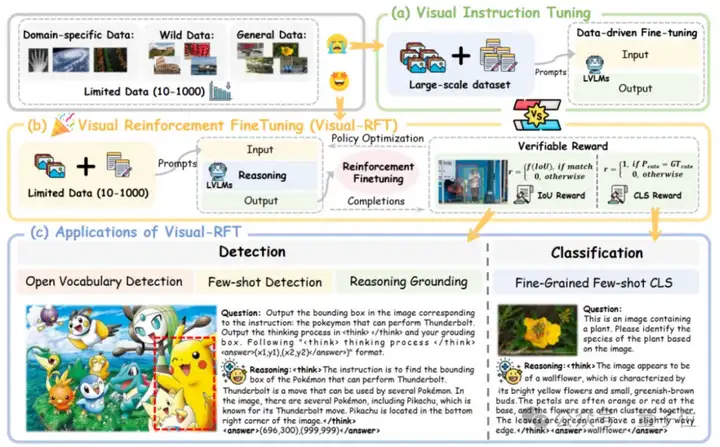
这是来自上海交大、上海AI Lab、港中文大学的研究人员推出的视觉强化微调开源项目——Visual-RFT (Visual Reinforcement Fine-Tuning), 只需10~1000条数据,就能通过思考过程和基于规则的监督提升多模态大模型的性能。

具体来说,他们将DeepSeek-R1背后的基于规则奖励的强化学习方法和OpenAI的强化微调(Reinforcement Fine-Tuning,RFT)范式,成功从纯文本大语言模型拓展到了视觉语言大模型(LVLM)。
通过针对视觉的细分类、目标检测等任务设计对应的规则奖励,Visual-RFT打破了DeepSeek-R1方法局限于文本、数学推理、代码等少数领域的认知,为视觉语言模型的训练开辟了全新路径。
下面具体来看。
OpenAI o1主打的强化微调能力(Reinforcement Fine-Tuning)能只用少量样本就将o1迁移到新的任务上。
最近DeepSeek-R1解释了o1模型背后的强推理能力来自基于可验证奖励(Verified Rewards)/规则奖励(Rule-based Verifier)的强化学习策略。
不过,目前主流的认知在于这种基于规则奖励的方法只适用于数学推理、代码等少数便于验证的任务。
而在Visual-RFT中,研究人员将这一策略迁移到了视觉语言模型。
通过对细分类、目标检测等任务建立对应的可验证规则奖励,研究解决了传统方法在视觉领域中的局限性,只需少量微调样本就实现了更高效、泛化性更强的视觉理解与推理能力。
传统的视觉指令微调(Visual Instruction Tuning/Supervised Fine-Tuning,SFT)需要海量数据对模型微调,在数据量有限(例如某些难以收集数据的特定学科场景)的情况下带来的提升有限。
与之不同,新研究提出的视觉强化微调(Visual Reinforcement Fine-Tuning)具有少样本学习能力和更强的泛化性,在数据量有限的场景下相比指令微调具有很大的优势。
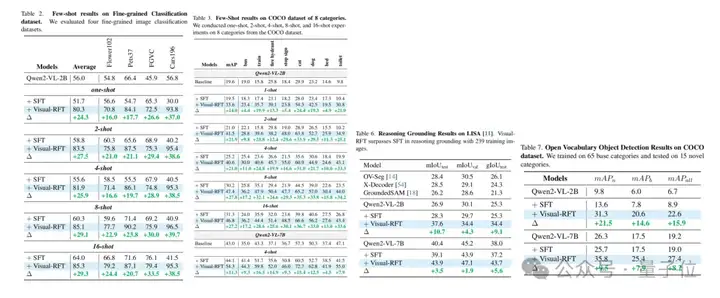
为验证Visual-RFT(视觉强化微调)的的泛化能力和普适性,力求对视觉领域的全面覆盖,研究人员在多个视觉感知任务上对Visual-RFT进行验证,包含Detection,Classification,Grounding等。
其中,Visual-RFT在open vocabulary,few-shot learning等设定下,仅仅通过非常少量的数据就取得了显著的性能提升,轻松实现能力的迁移,且结果明显优于SFT的微调方法。
在Reasoning Grounding(推理定位)的测试中,Visual-RFT展现出强大的视觉推理能力。
评测结果如下图所示:
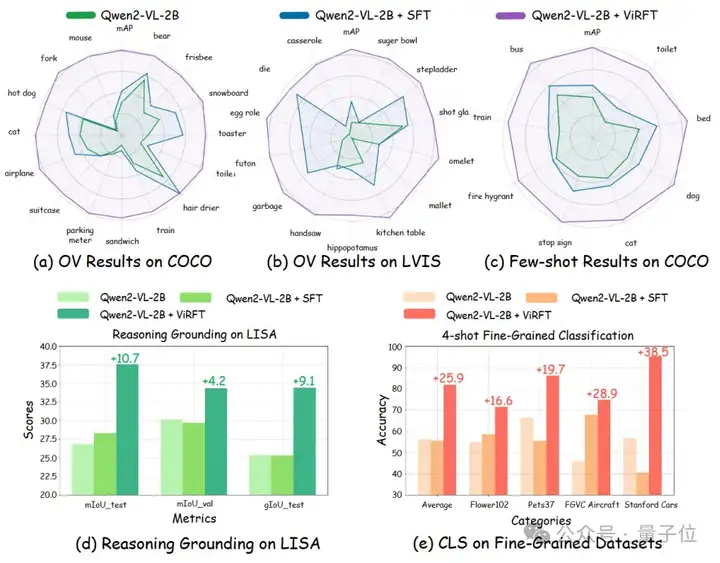
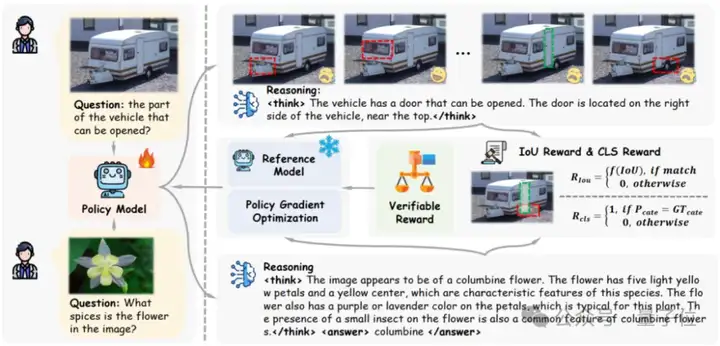
为了在视觉多模态领域验证可验证奖励的作用,研究人员提出了使用基于IoU的verified reward奖励应用于detection和grounding等任务,使用基于分类正确判断的cls reward用于classification任务。
部分推理定位结果显示,通过引入思考过程和强化学习策略,Visual-RFT(多模态强化微调)显著超越SFT,更加准确地定位物体。
如询问模型,图中的运动员在水下依然保持清晰的视野需要带什么物体时候,通过传统指令微调的方法模型直接将整个运动员框出。
而Visual-RFT通过引入推理过程准确地指出防水眼睛及其所在的位置并准确框出。
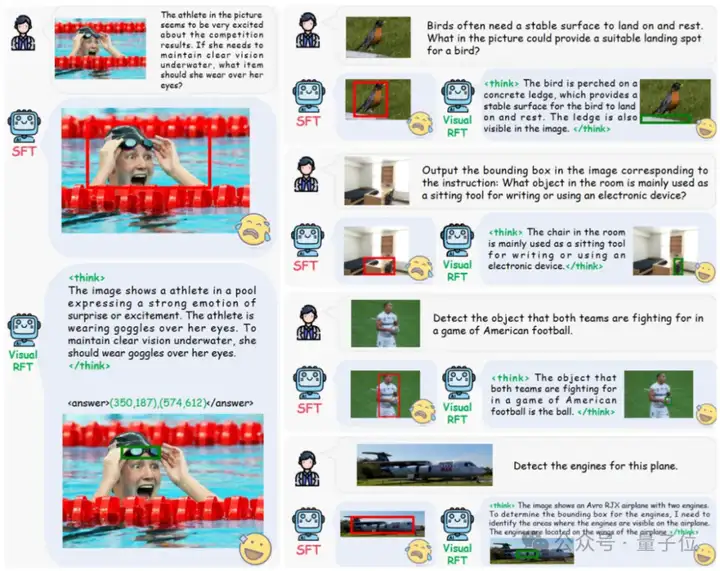
部分推理细粒度分类结果也展示了相同结论。

小结一下,相比于传统的视觉指令微调(Visual Instruction/Supervised Fine-Tuning),Visual-RFT(视觉强化微调)通过强化学习方法,对问题进行深入的think分析取得更佳推理性能,相较于传统的指令微调(SFT)方法取得显著提升。
Visual-RFT(视觉强化微调)在各大图文感知任务中均展现出强大的性能。
实验主要基于视觉语言大模型基座QWen2-VL 2B/7B模型,和传统的监督微调(Supervised Fine-Tuning)方法进行对比。
在开放目标检测、少样本检测、细粒度分类和推理定位任务上,Visual-RFT相比SFT全面实现了性能提升。
值得一提的是,该研究的测试数据既包含COCO、LVIS等通用场景,又包含从互联网中收集的卡通人物等开放场景数据。只需要几十条数据,模型通过Visual-RFT可以学会检测某动漫中的史莱姆形象。
实验结果广泛验证了Visual-RFT的卓越性能和鲁棒性。
目前,包含训练、评测代码,数据在内,Visual-RFT项目已全面开源。
项目地址:
https://github.com/Liuziyu77/Visual-RFT
文章来自于“量子位”,作者“Visual-RFT团队”。



【免费】cursor-auto-free是一个能够让你无限免费使用cursor的项目。该项目通过cloudflare进行托管实现,请参考教程进行配置。
视频教程:https://www.bilibili.com/video/BV1WTKge6E7u/
项目地址:https://github.com/chengazhen/cursor-auto-free?tab=readme-ov-file
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
