# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最近在公司完成了一个内部知识问答应用,实现流程很简单,实际上就是Langchain那一套:
具体可以参考下图,
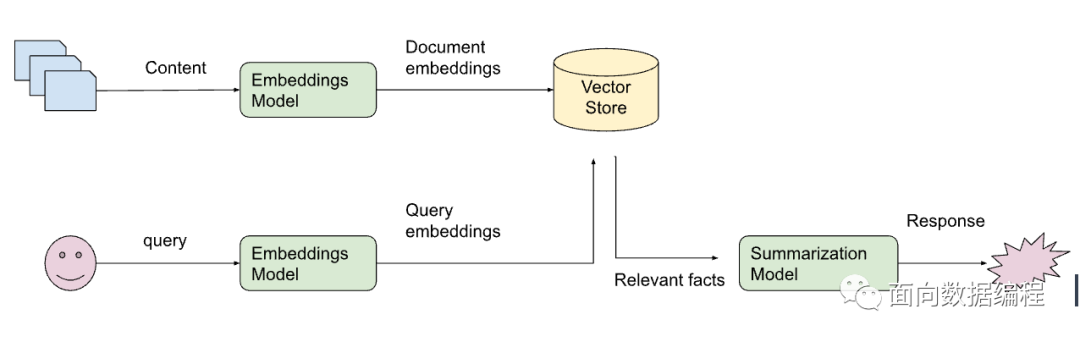
这个流程的打通其实特别容易,基本上1天就能把架子搭起来,然后开发好了API对外服务。并且在尝试了几个通用的文档后,觉得效果也不错。
但是,当公司内部真实文档导入之后,效果急转直下。
当时初步分析,有以下几个原因:
有doc、ppt、excel、pdf,pdf也有扫描版和文字版。
doc类的文档相对来说还比较容易处理,毕竟大部分内容是文字,信息密度较高。但是也有少量图文混排的情况。
Excel也还好处理,本身就是结构化的数据,合并单元格的情况使用程序填充了之后,每一行的信息也是完整的。
真正难处理的是ppt和pdf,ppt中包含大量架构图、流程图等图示,以及展示图片。pdf基本上也是这种情况。
这就导致了大部分文档,单纯抽取出来的文字信息,呈现碎片化、不完整的特点。
如果没有定制切分方式,则是按照一个固定的长度对文本进行切分,同时连续的文本设置一定的重叠。
这种方式导致了每一段文本包含的语义信息实际上也是不够完整的。同时没有考虑到文本中已包含的标题等关键信息。
这就导致了需要被向量化的文本段,其主题语义并不是那么明显,和自然形成的段落显示出显著的差距,从而给检索过程造成巨大的困难。
大模型或者句向量在训练时,使用的语料都是较为通用的语料。这导致了这些模型,对于垂直领域的知识识别是有缺陷的。它们没有办法理解企业内部的一些专用术语,缩写所表示的具体含义。这样极大地影响了生成向量的精准度,以及大模型输出的效果。
实际上大部分用户在提问时,写下的query是较为模糊笼统的,其实际的意图埋藏在了心里,而没有完整体现在query中。使得检索出来的文本段落并不能完全命中用户想要的内容,大模型根据这些文本段落也不能输出合适的答案。
例如,用户如果直接问一句“请给我推荐一个酒店”,那么模型不知道用户想住什么位置,什么价位,什么风格的酒店,给出的答案肯定是无法满足用户的需求的。
对于以上问题,我采取了多种方式进行解决,最终应用还是能够较好的满足用户的需求。
针对各种类型的文档,分别进行了很多定制化的措施,用于完整的提取文档内容。这部分基本上脏活累活,

对文档内容进行重新处理后,语义切分工作其实就比较好做了。我们现在能够拿到的有每一段文本,每一张图片,每一张表格,文本对应的属性,图片对应的描述。
对于每个文档,实际上元素的组织形式是树状形式。例如一个文档包含多个标题,每个标题又包括多个小标题,每个小标题包括一段文本等等。我们只需要根据元素之间的关系,通过遍历这颗文档树,就能取到各个较为完整的语义段落,以及其对应的标题。
有些完整语义段落可能较长,于是我们对每一个语义段落,再通过大模型进行摘要。这样文档就形成了一个结构化的表达形式:
idtextsummarysourcetypeimage_source1文本原始段落文本摘要来源文件文本元素类别(主要用于区分图片和文本)图片存储位置(在回答中返回这个位置,前端进行渲染)
检索增强这一块主要借鉴了RAG Fusion技术,这个技术原理比较简单,概括起来就是,当接收用户query时,让大模型生成5-10个相似的query,然后每个query去匹配5-10个文本块,接着对所有返回的文本块再做个倒序融合排序,如果有需求就再加个精排,最后取Top K个文本块拼接至prompt。
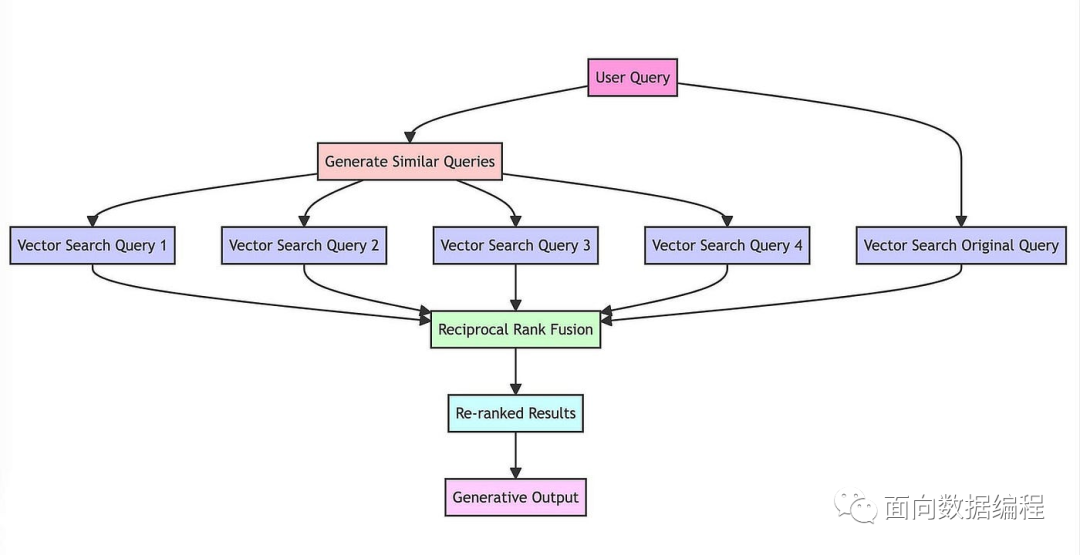
实际使用时候,这个方法的主要好处,是增加了相关文本块的召回率,同时对用户的query自动进行了文本纠错、分解长句等功能。但是还是无法从根本上解决理解用户意图的问题。
这里是通过Prompt就可以实现的功能,只要在Prompt中加入“如果无法从背景知识回答用户的问题,则根据背景知识内容,对用户进行追问,问题限制在3个以内”。这个机制并没有什么技术含量,主要依靠大模型的能力。不过大大改善了用户体验,用户在多轮引导中逐步明确了自己的问题,从而能够得到合适的答案。
这部分主要是为了解决垂直领域特殊词汇,在通用句向量中会权重过大的问题。比如有个通用句向量模型,它在训练中很少见到“SAAS”这个词,无论是文本段和用户query,只要提到了这个词,整个句向量都会被带偏。举个例子:
假如一个用户问的是:我是一个SAAS用户,我希望订购一个云存储服务。由于SAAS的权重很高,使得检索匹配时候,模型完全忽略了后面的那句话,才是真实的用户需求。返回的内容可能是SAAS的介绍、SAAS的使用手册等等。
这里的微调方法使用的数据,是让大模型对语义分割的每一段,形成问答对。用这些问答对构建了数据集进行句向量的训练,使得句向量能够尽量理解垂直领域的场景。
经过这么一套组合拳,系统的回答效果从一开始的完全给不了帮助以及胡说八道,到了现在可以参考的程度。但是与用户实际期望还是相差甚远。
这里不由得让我思考了下整个过程,RAG的本意是想让模型降低幻想,同时能够实时获取内容,使得大模型给出合适的回答。
在严谨场景中,precision比recall更重要。
如果大模型胡乱输出,类比传统指标,就好比recall高但是precision低,但是限制了大模型的输出后,提升了precision,recall降低了。所以给用户造成的观感就是,大模型变笨了,是不是哪里出问题了。
总之,这个balance很难取,我对比了下市面主流的一些基于单篇文档的知识库问答,比如WPS AI,或者海外的ChatDoc。我发现即使基于单篇文档回答,它们在我们垂直领域的文档的幻想问题还是很严重。但是输出的答案不认真看的话,确实挺惊艳。例如问个操作步骤问题,文档压根没这个内容,但是它一步步输出的极其自信。
反正最后就想感慨一下,RAG确实没有想的那么容易。
文章来自于微信公众号“面向数据编程”,作者 “黑默丁格”


【开源免费】smart-excel-ai是一个输入你想要的Excel公式的描述,即可帮你生成对应公式的AI项目
项目地址:https://github.com/weijunext/smart-excel-ai
在线使用:https://www.smartexcel.cc/(付费)
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
