# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
OpenAI GPT-4V 和 Google Gemini 都展现了非常强的多模态理解能力,推动了多模态大模型(MLLM)快速发展,MLLM 成为了现在业界最热的研究方向。
MLLM 在多种视觉-语言开放任务中取得了出色的指令跟随能力。尽管以往多模态学习的研究表明不同模态之间能够相互协同和促进,但是现有的 MLLM 的研究主要关注提升多模态任务的能力,如何平衡模态协作的收益与模态干扰的影响仍然是一个亟待解决的重要问题。

针对这一问题,阿里多模态大模型 mPLUG-Owl 迎来大升级,通过模态协同同时提升纯文本和多模态性能,超过 LLaVA1.5,MiniGPT4,Qwen-VL 等模型,取得多种任务 SOTA。
具体的,mPLUG-Owl2 利用共享的功能模块来促进不同模态之间的协作,并引入模态自适应模块来保留各个模态自身的特征。通过简洁有效的设计,mPLUG-Owl2 在包括纯文本和多模态在内的多种任务上取得了 SOTA 性能,对模态协作现象的研究也有助于启发未来多模态大模型的发展。
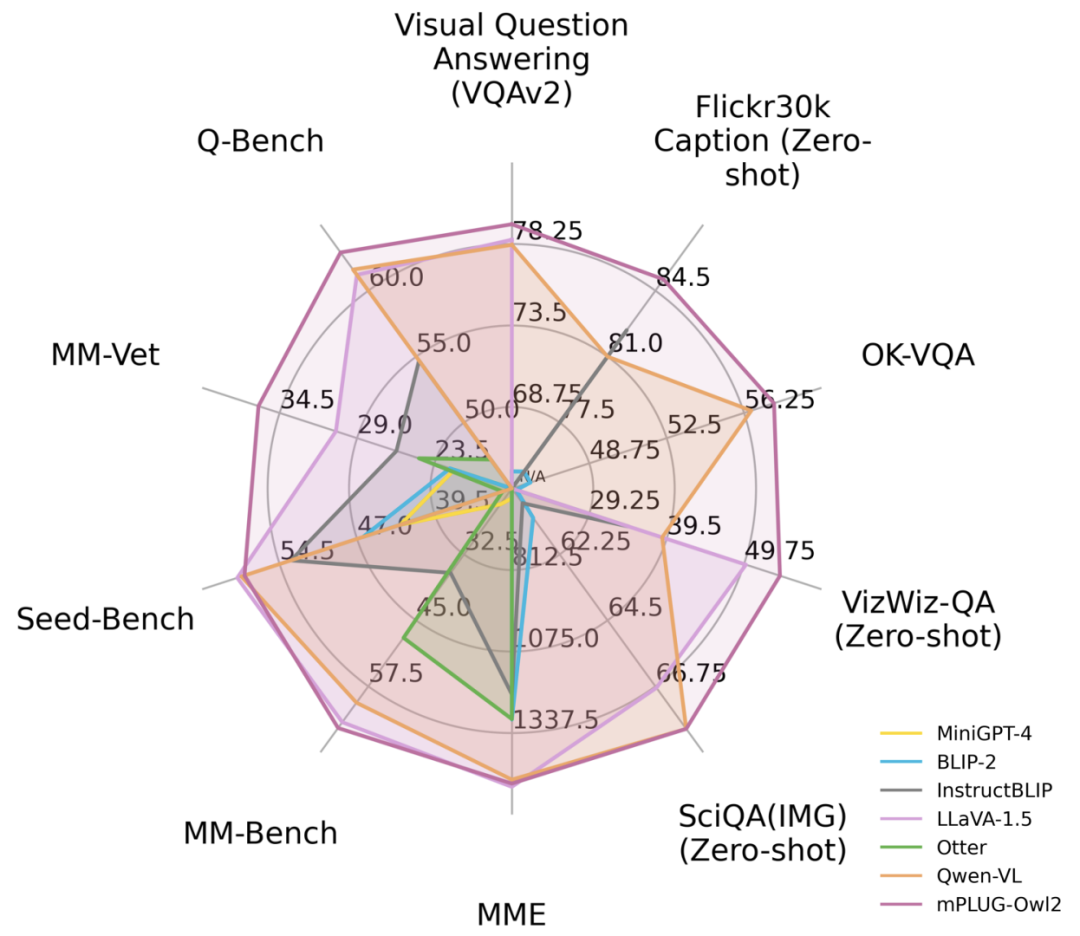
图 1 与现有 MLLM 模型性能对比
mPLUG-Owl2 模型主要由三部分组成:
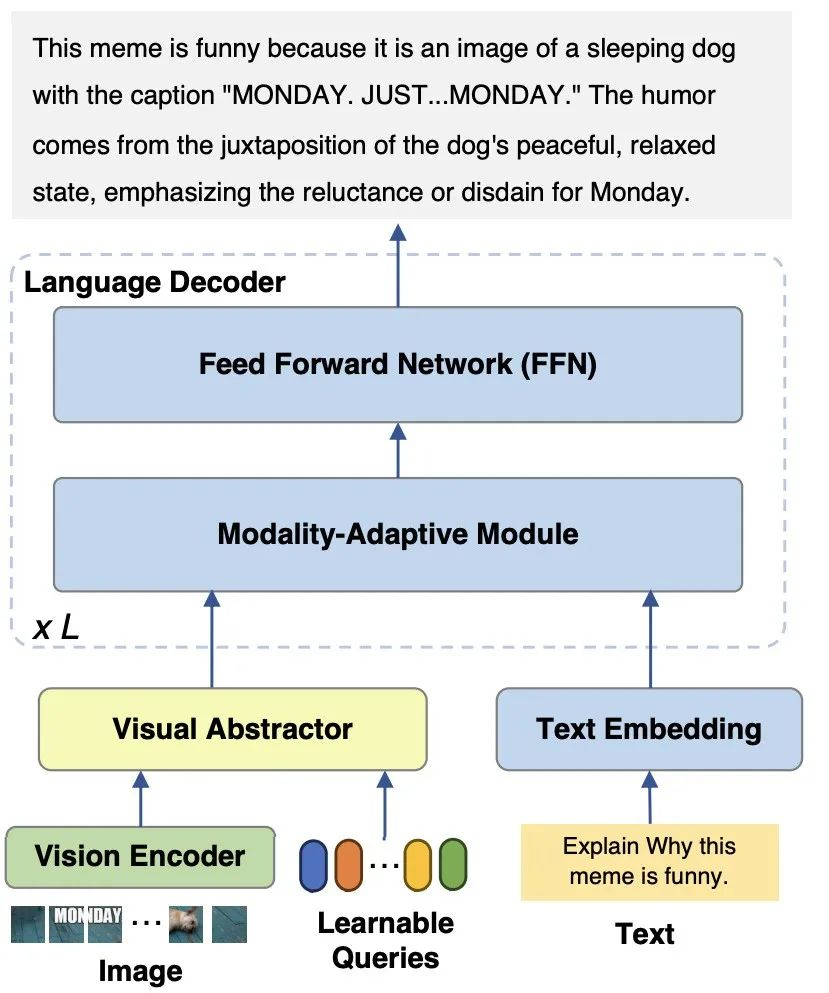
图 2 mPLUG-Owl2 模型结构
为了对齐视觉和语言模态,现有的工作通常是将视觉特征映射到文本的语义空间中,然而这样的做法忽视了视觉和文本信息各自的特性,可能由于语义粒度的不匹配影响模型的性能。为了解决这一问题,本文提出模态自适应模块 (Modality-adaptive Module, MAM),来将视觉和文本特征映射到共享的语义空间,同时解耦视觉 - 语言表征以保留模态各自的独特属性。
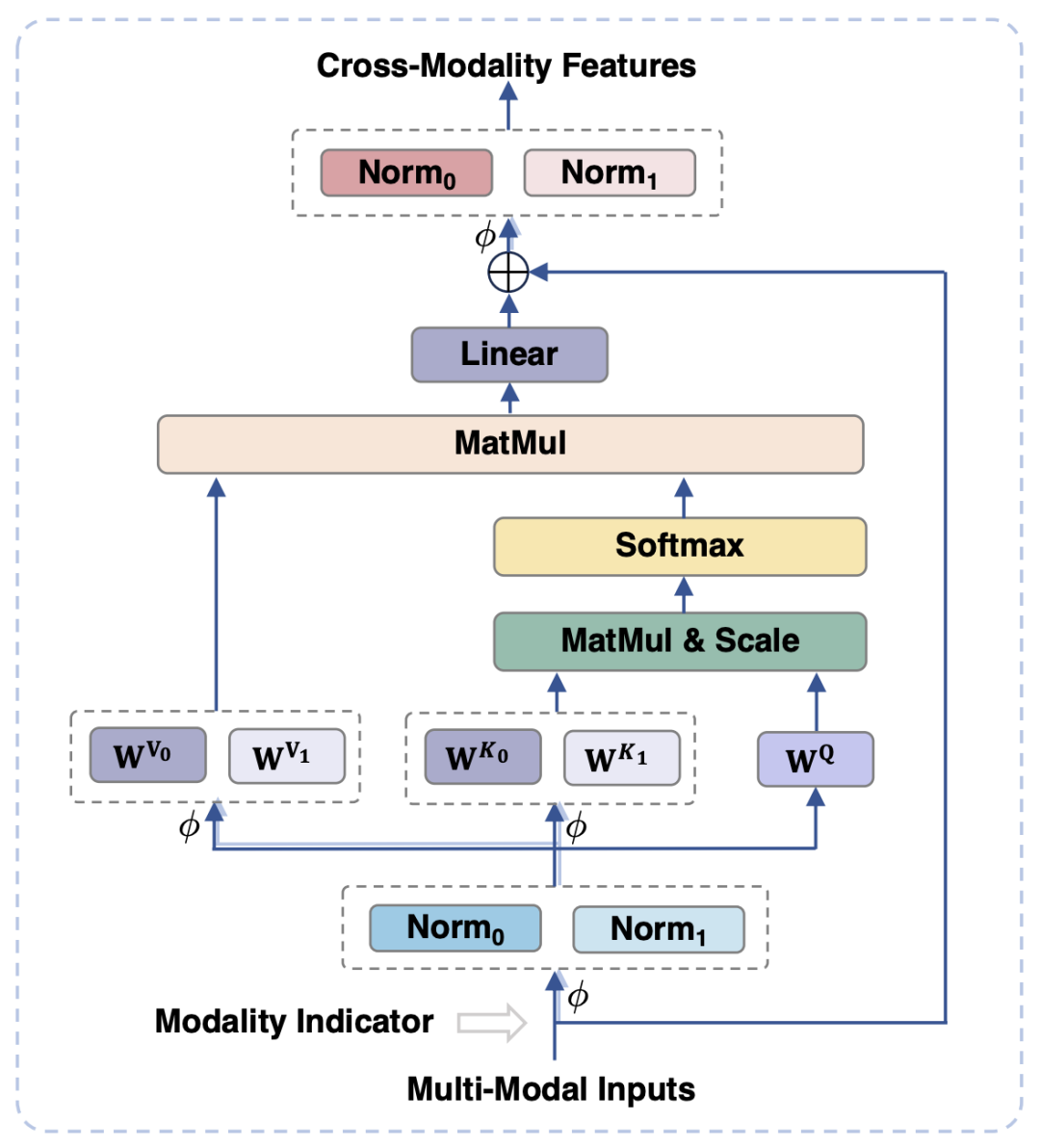
图 3 Modality-adaptive 模块示意图
如图 3 所示,与传统 Transformer 相比,模态自适应模块的主要设计在于:
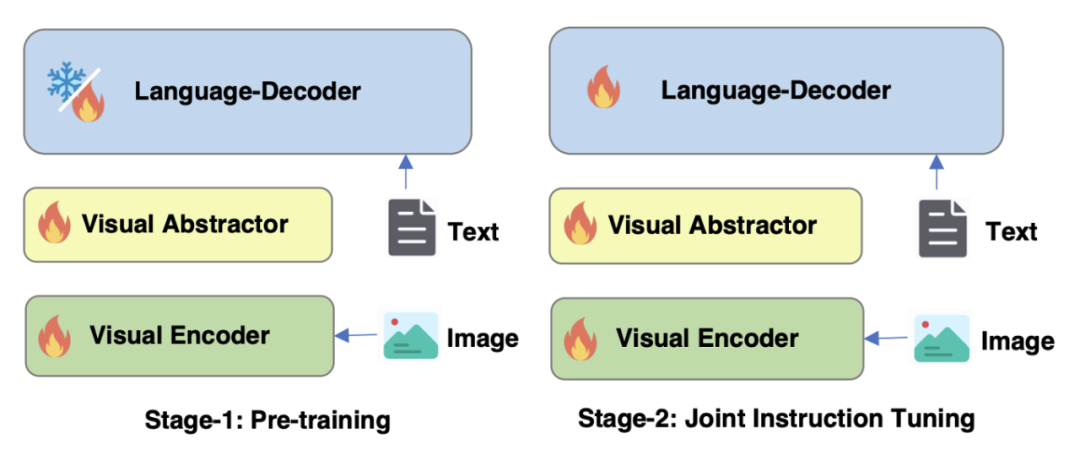
图 4 mPLUG-Owl2 训练策略
如图 4 所示,mPLUG-Owl2 的训练包含预训练和指令微调两个阶段。预训练阶段主要是为了实现视觉编码器和语言模型的对齐,在这一阶段,Visual Encoder、Visual Abstractor 都是可训练的,语言模型中则只对 Modality Adaptive Module 新增的视觉相关的模型权重进行更新。在指令微调阶段,结合文本和多模态指令数据(如图 5 所示)对模型的全部参数进行微调,以提升模型的指令跟随能力。
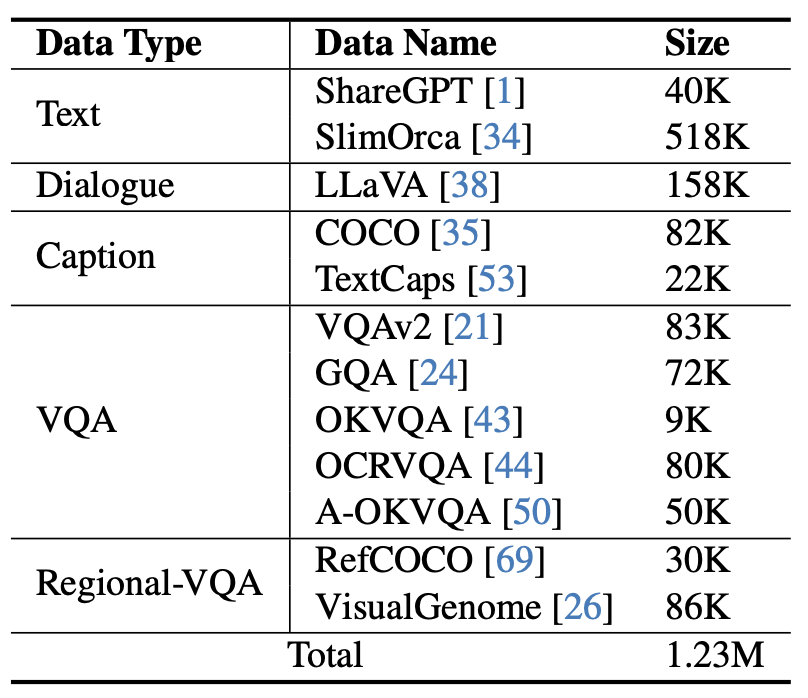
图 5 mPLUG-Owl2 使用的指令微调数据
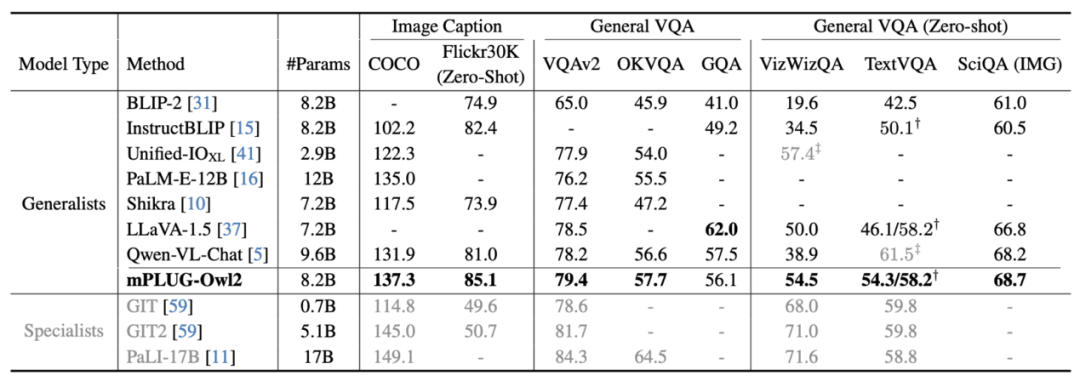
图 6 图像描述和 VQA 任务性能
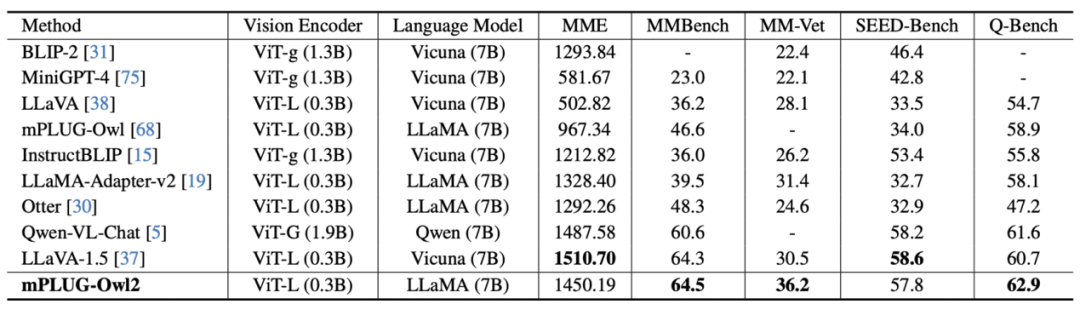
图 7 MLLM 基准测试性能
如图 6、图 7 所示,无论是传统的图像描述、VQA 等视觉 - 语言任务,还是 MMBench、Q-Bench 等面向多模态大模型的基准数据集上,mPLUG-Owl2 都取得了优于现有工作的性能。
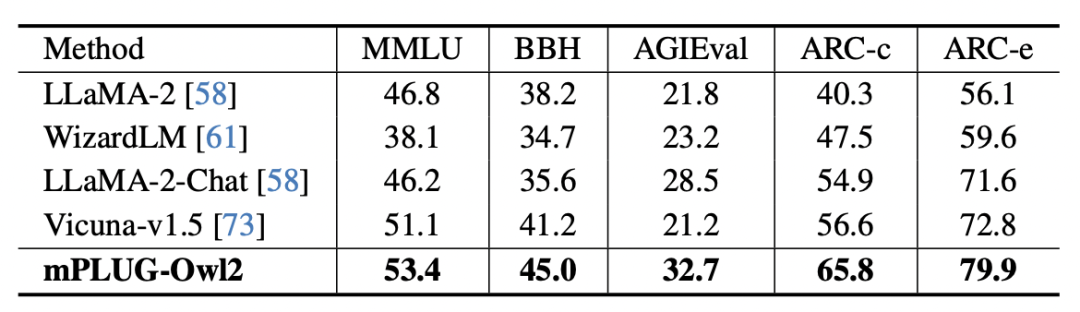
图 8 纯文本基准测试性能
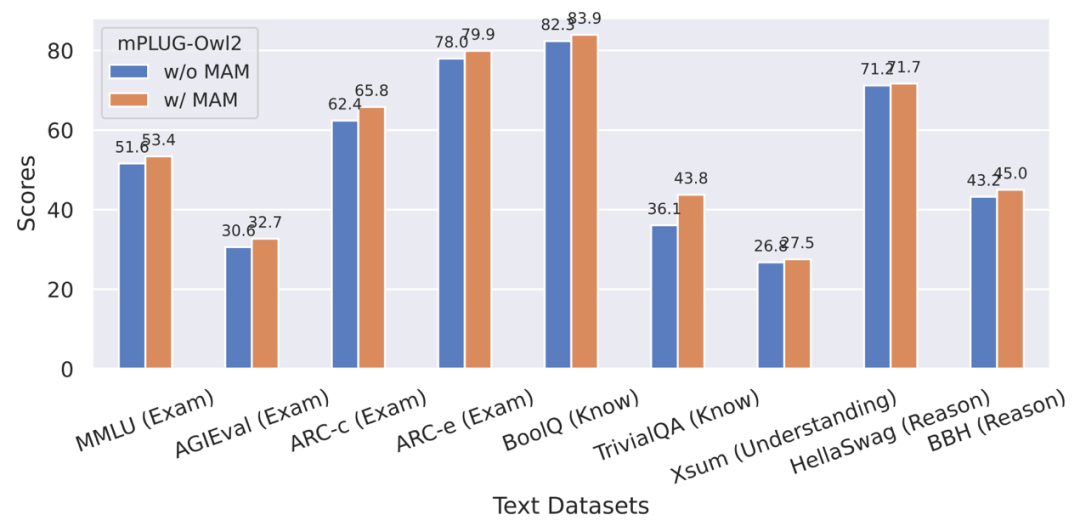
图 9 模态自适应模块对纯文本任务性能的影响
此外,为了评估模态协同对纯文本任务的影响,作者还测试了 mPLUG-Owl2 在自然语言理解和生成方面的表现。如图 8 所示,与其他指令微调的 LLM 相比,mPLUG-Owl2 取得了更好的性能。图 9 展示的纯文本任务上的性能可以看出,由于模态自适应模块促进了模态协作,模型的考试和知识能力都得到了显著提高。作者分析,这是由于多模态协作使得模型能够利用视觉信息来理解语言难以描述的概念,并通过图像中丰富的信息增强模型的推理能力,并间接强化文本的推理能力。


mPLUG-Owl2 展示了很强的多模态理解能力,有效的缓解多模态幻觉。相关多模态技术已应用于通义星尘、通义智文等核心通义产品,并已在 ModelScope,HuggingFace 开放 Demo。
文章来自于微信公众号“机器之心”



【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
