# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在春节的 DeepSeek 大热后,大模型也更多走进了大家的生活。我们越来越多看到各种模型在静态的做题榜单击败人类,解决各种复杂推理问题。但这些静态的测试与模型在现实中的应用还相去甚远。模型除了能进行对话,还在许多更复杂的场景中以各种各样的方式与人类产生互动。除了对话任务外,如何实现大模型与人的实时同步交互协作越来越重要。
像上周刚刚引爆社区的 Manus,就号称能够让 LLM Agent 能够与人实时协作交互完成任务。网上对 Manus 的吹捧很多,甚至 Manus 的一个内测码的价格在闲鱼上就被叫到了 6 万。但在实测视频中,我们可以看到 Manus 更像是回合制协作,用户输入一个指令后,Manus 进行规划,列出自己需要完成的任务,并逐步完成。用户只能在 Manus 完成任务的过程中静静等待,也无法修改 Manus 的计划,直到 Manus 完成它的计划才能开始新的交互。
但在现实生活中,我们与同伴互动协作完成一个任务时,并不是回合制互动的,人与人之间存在着更多频繁的互动以及对对方的观察与输入输出,这些互动带来了环境状态的改变以及对人即时反应能力的要求。
Manus 的交互形式仍然无法解决对人类的实时响应问题。用户在出现临时的想法变化,或希望和模型协作共同工作时,Agent 仍然面临无法快速响应,以及难以推断用户意图的挑战。
如何让模型实现真正的人机实时同步协作?在 Claude-3.7-sonnet 游玩宝可梦,模型在贪吃蛇中进行大比拼受到广泛关注的时刻,我们发现多人协作游戏或许是一个更合适的测试场景。
「锅里的牛排糊了!灭火器在哪?生菜还没切完!!」—— 如果你玩过《Overcooked》,一定体验过这种手忙脚乱的崩溃感。实时游戏的突发状况、疯狂倒计时的订单,以及频频和你抢活干的队友,让这款强调同步协作的游戏既充满欢乐又令人血压飙升。
《Overcooked》是一款 Team 17 发行的以合作烹饪为主题的派对游戏,玩家需在特别的厨房中与队友实时配合完成切菜、煎牛肉饼、组装汉堡以完成订单,并时刻注意灭火。游戏凭借极具挑战的实时协作机制和令人手忙脚乱的厨房布局,迅速成为考验团队默契的「友情 / 爱情检测器」,也因此得名「分手厨房」。
Overcooked游戏画面
有趣的是,这种高实时性、强交互的虚拟环境也吸引了多智能体系统(Multi-Agent System, MAS)和多智能体强化学习(Multi-agent Reinforcement Learning)研究者的目光。由于游戏要求智能体快速分工协作,解决合作中的协调问题,Overcooked 在 2019 年由 Stuart Russell 和 Pieter Abbeel 领衔的 Center for Human-Compatible AI ,通过简化实现成人智协同的基准 overcooked-ai,开始被被广泛用作探究智能体与人类协作能力的测试平台,尤其是和人类的零样本协作(Zero-shot Coordination)。研究者通过训练 AI 代理预测人类玩家的决策与沟通,探索分布式协作、应急策略优化等课题,其成果甚至为自动驾驶、工业机器人协作提供了灵感。在 overcooked-ai 的「虚拟后厨」,人机协作的边界正被重新定义。

原始的overcooked-ai环境
当实时同步协作对人而言仍有巨大挑战时,上海交大(共同第一作者为博士生张劭和王锡淮,导师为温颖副教授和张伟楠教授)与 AGI-Eval 评测社区开发的 DPT-Agent 框架和基于 Overcooked-AI 重新升级的 Overcooked Challenge 实时同步协作评估环境,加入更复杂的菜谱以及还原游戏的实时协作机制,让大模型加入这场协作游戏,直面同步实时协作挑战:

DPT-Agent 和 Overcooked Challenge 环境现已开源,有兴趣的朋友可以试试接入大模型和 DPT-Agent 一起玩 Overcooked。
看到这里,你一定会问,平时话很多的 ChatGPT 输出一次要好几秒,还有在对话时要思考几十秒的 DeepSeek-R1,虽然推理能力很强也很会思考,但似乎延迟巨大,如何做到和人实时同步协作?
答案就是双过程理论(Dual Process Theory)—— 让大模型学会「边煎牛排边写策略」!
大模型在实时同步协作中为何频频翻车?问题出在「大模型想得慢做的慢」与「小模型做的快但做不对」的矛盾:
大模型往往生成一个决策至少需数秒,推理模型则可能达到惊人的几分钟,在分手厨房以秒计算的游戏进程里难以实施决策,而小模型响应的确很快,但往往由于能力不足,出现失误决策。
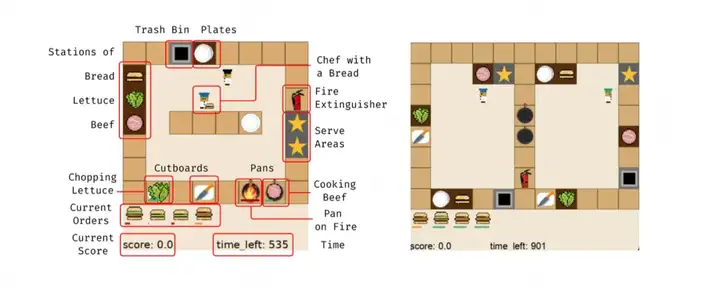
左:Overcooked Challenge 的关卡1,同时支持单人和双人游戏;右:Overcooked Challenge 的关卡2
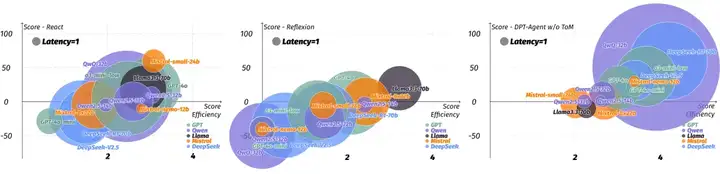
作者使用了一系列的大小模型在 Overcooked Challenge 单人游戏上进行了测试,可以明显的看到绝大多数非推理模型在直接决策(Act as System 1)以及推理模型先思考再决策(Long CoT + Act as System 2)的情况下都无法得分,即使强如 GPT-4o,也无法超越简单的有限状态机(FSM)。
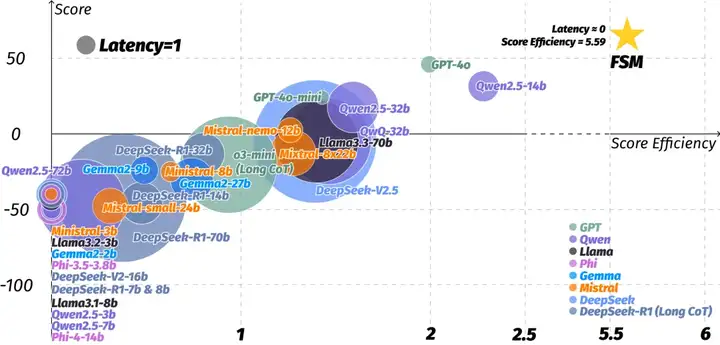
横轴为得分效率:正得分(即不含扣分)/有效宏操作,纵轴为每局游戏平均得分,圆的大小代表模型每一次决策从输入到输出的平均延时(秒)
这使得我们思考一个问题,模型是否能像人一样,一边不间断地做手上的工作,一边思考更复杂的策略,而不是想一步做一步?
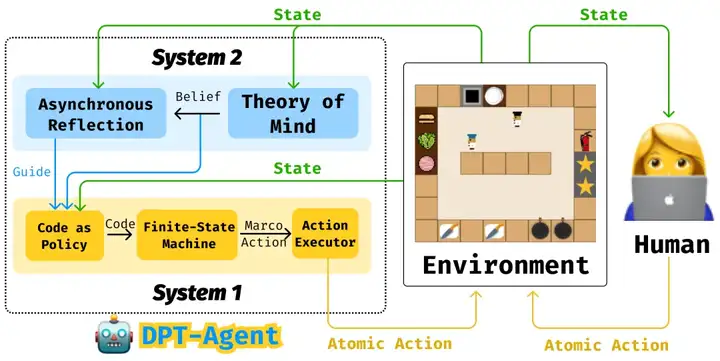
借鉴人类双过程理论(Dual Process Theory),DPT-Agent 通过 System 1 和 System 2 的结合,为 Agent 装上「人脑同款双系统」:
1.「快脑」System 1—— 条件反射级响应
2.「慢脑」System 2—— 战略级读心术
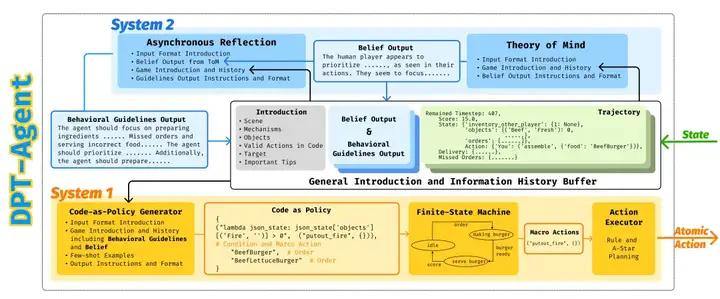
DPT-Agent框架图
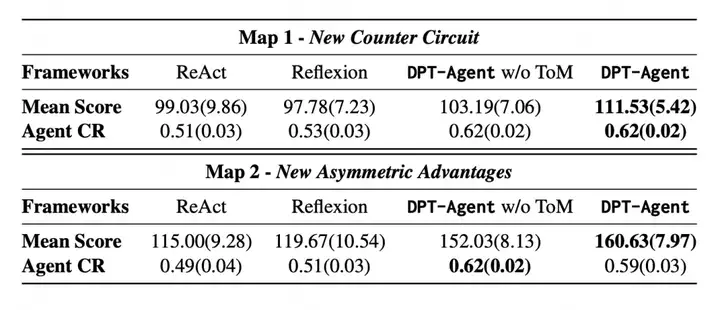
在全新的难度加强 Overcooked Challenge 环境上,20 个主流模型(涵盖 GPT-o3-mini、DeepSeek-R1 系列以及最新发布的 QwQ-32b 等)在 ReAct、Reflexion 和 DPT-Agent 的两个版本(带有 / 不带有心智理论能力)上进行了单智能体、多智能体以及真实人类合作测试,证明了 DPT-Agent 在实时同步协作上的超强能力。
在单人游戏中,DPT-Agent 在得分效率和得分上均优于 ReAct 和 Reflexion,而高延迟模型更是得到逆袭级别的表现。绝大多数高延迟模型在 DPT-Agent 框架的帮助下取得从有得分能力到能够真正得分的转变,相比 ReAct 和 Reflexion 取得大幅提升。DeepSeek-R1-70B 使用 DPT-Agent 框架后,在延迟基本不变的情况下,得分从使用 ReAct 的 -17.0 以及 Reflexion 的 -20.0 变为 +60.0,逆袭成「厨房战神」。而其他非推理模型也有不同程度的提升。
轴为得分效率:正得分(即不含扣分)/有效宏操作,纵轴为每局游戏平均得分,圆的大小代表模型每一次决策从输入到输出的平均延时(秒)
在真实的协作场景中,AI 常需面对能力参差不齐的伙伴 —— 可能是只会切菜的规则机器人,或是专注煎牛排却绝不上菜的「一根筋」AI。DPT-Agent 如何应对?团队设计了残酷的多智能体实验:
极端测试:与「偏科 AI」组队让 DPT-Agent 搭档三类规则 AI(专精切生菜 / 煎牛排 / 组装汉堡)。
为了公平比较,ReAct 和 Reflexion 使用和 DPT-Agent 相同的 System 2 输出方式与动作执行器来实现为 System 1 + System 2 框架。
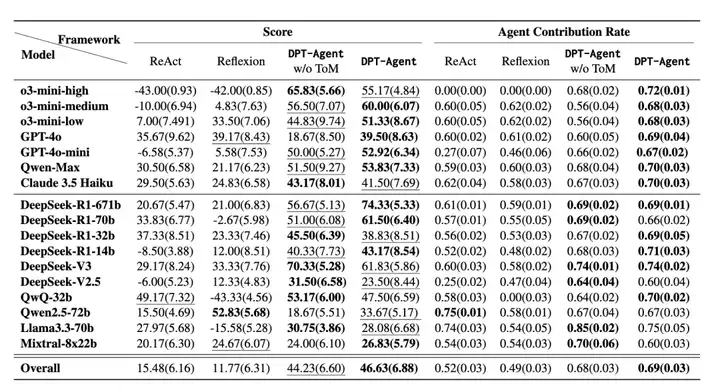
1.推理模型战胜高延迟:DeepSeek-R1 满血版在 DPT-Agent 框架加持下,相比使用 ReAct 的 - 42.5 分有大幅提升,获得 74.3 分的战绩,逆袭成 MVP, o3-mini-high 相比 o3-mini-medium 和 o3-mini-low 即使延迟增大,也一样呈现能力上升趋势。
2.非推理模型表现也亮眼:DeepSeek-V3 在 DPT_Agent 框架加持下表现与满血 DeepSeek-R1 接近,展现不俗实力。
3.ToM 模块的双刃剑:
论文链接:https://arxiv.org/abs/2409.08811
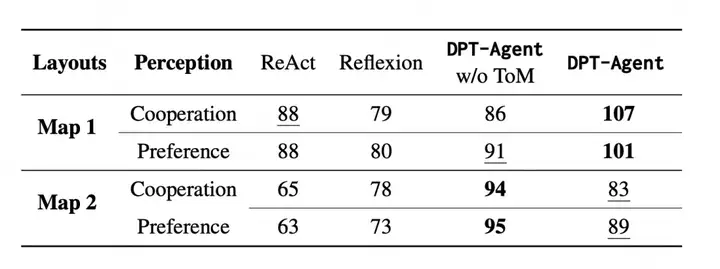
团队在学校内招募了 68 位学生和多智能体实验中所有的 Agent 进行了协作实验,并在先前实验的基础上增加了一个关卡。实验参与者在完全未知 Agent 身份的情况下与所有 Agent 以随机顺序进行实验,对 Agent 进行了协作能力和偏好程度的打分。
DPT-Agent 展现了超强协作能力,得分在两个地图上碾压其他框架,主观协作能力和人类主观偏好得分最高。

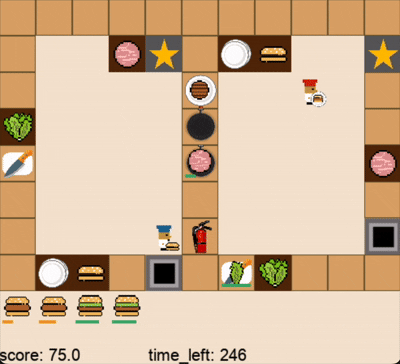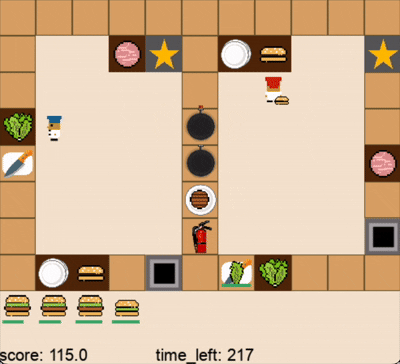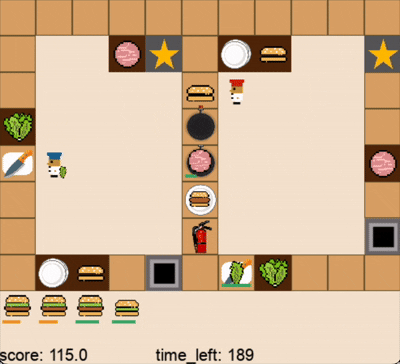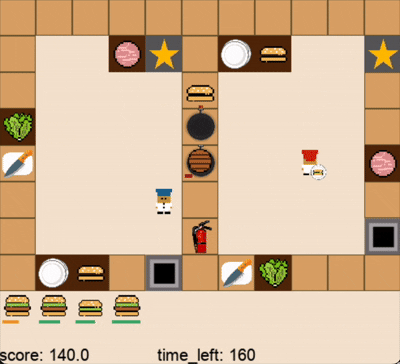
DPT-Agent和人类玩家在关卡1的游戏过程(蓝色帽子为人类玩家,红色帽子为DPT-Agent,视频为2倍速)
人类玩家借助关卡2的中间操作台无缝合作(蓝色帽子为人类玩家,红色帽子为DPT-Agent,视频为2倍速)
同时有趣的是,人类对 agent 的偏好和协作程度,可能与 agent 的得分贡献率有关,人类会展现出更多的对贡献率更高的模型的喜爱。
与人类协作游戏得分与各Agent的得分贡献率
人类主观评价得分
DPT-Agent 使用的 Overcooked Challenge 环境现已开源,支持 Act,ReAct,Reflexion,ReAct in DPT, Reflexion in DPT, DPT-Agent w/o ToM,DPT-Agent 多种框架下的模型评估,同时公开多达 34 个主流模型包含 DeepSeek-R1 在内的评估结果,评估结果现已在 AGI-Eval 平台上线,未来计划推出人机协作评估,请大家一起来和大模型玩分手厨房!
文章来自于“机器之心”,作者“张劭”。



【开源免费】OWL是一个完全开源免费的通用智能体项目。它可以远程开Ubuntu容器、自动挂载数据、做规划、执行任务,堪称「云端超级打工人」而且做到了开源界GAIA性能天花板,达到了57.7%,超越Huggingface 提出的Open Deep Research 55.15%的表现。
项目地址:GitHub:https://github.com/camel-ai/owl
【开源免费】OpenManus 目前支持在你的电脑上完成很多任务,包括网页浏览,文件操作,写代码等。OpenManus 使用了传统的 ReAct 的模式,这样的优势是基于当前的状态进行决策,上下文和记忆方便管理,无需单独处理。需要注意,Manus 有使用 Plan 进行规划。
项目地址:https://github.com/mannaandpoem/OpenManus
【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
