# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
近年来,深度学习技术在自动驾驶、计算机视觉、自然语言处理和强化学习等领域取得了突破性进展。然而,在现实场景中,传统单目标优化范式在应对多任务协同优化、资源约束以及安全性 - 公平性权衡等复杂需求时,逐渐暴露出其方法论的局限性。值得注意的是,在大语言模型(LLM)与生成式 AI 系统的多维度价值对齐(Multi-Dimensional Alignment)领域,如何协调模型性能、安全伦理边界、文化适应性及能耗效率等多元目标,已成为制约人工智能系统社会应用的关键挑战。多目标优化(Multi-Objective Optimization, MOO)作为一种协调多个潜在冲突目标的核心技术框架,正在成为破解复杂系统多重约束难题的关键方法。
近日,由香港科技大学、香港科技大学(广州)、香港城市大学以及 UIUC 等团队联合发布的基于梯度的多目标深度学习综述论文《Gradient-Based Multi-Objective Deep Learning: Algorithms, Theories, Applications, and Beyond》正式上线。这篇综述从多目标算法设计、理论分析到实际应用与未来展望,全方位解析了如何在多任务场景下高效平衡各目标任务,呈现了这一领域的全景。

在深度学习中,我们常常需要同时优化多个目标:
多目标优化算法旨在寻找一系列 「折中解」(也称为 Pareto 最优解),在不同目标间达到平衡,从而满足应用场景中对协同优化的要求。
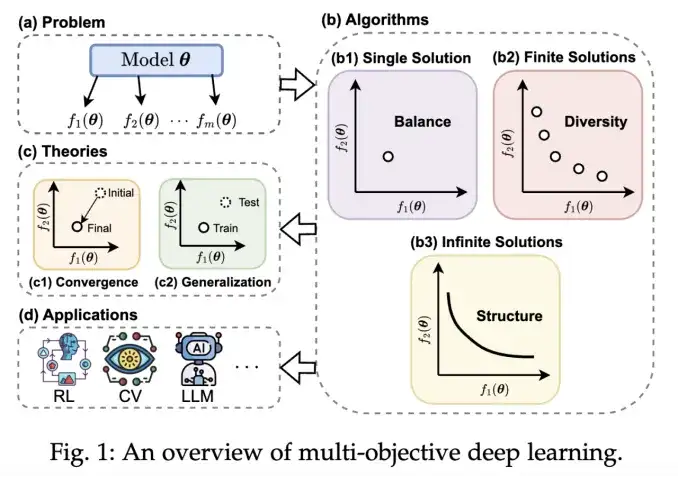
基于梯度的多目标优化方法主要分为三类:寻找单个 Pareto 最优解的算法,寻找有限个 Pareto 最优解的算法以及寻找无限个 Pareto 最优解的算法。
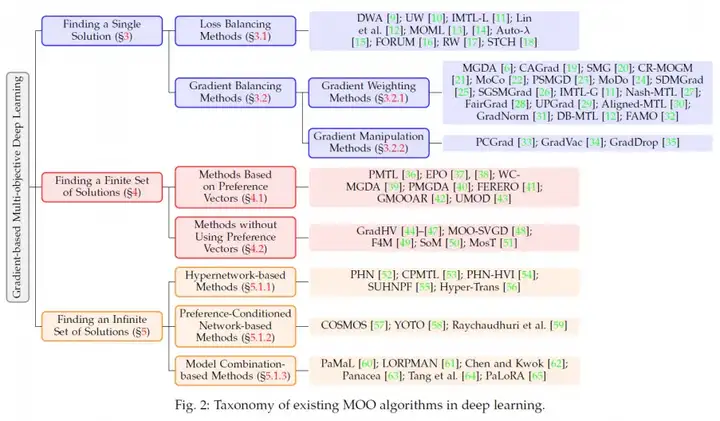
在多任务学习等场景中,通常只需找到一个平衡的解,以解决任务之间的冲突,使每个任务的性能都尽可能达到最优。为此,研究者们提出了多种方法,这些方法可进一步分为损失平衡方法和梯度平衡方法。
一些有代表性的方法如下图所示:
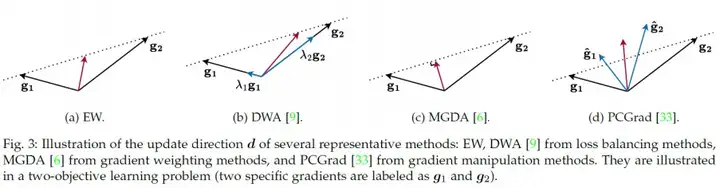
在寻找有限个 Pareto 解集时,需要同时考虑两个关键因素:解的快速收敛性(确保解迅速逼近 Pareto 最优前沿)和解集的多样性(保证解在 Pareto 前沿上的均匀分布)。目前主要有两类方法:
一些有代表性的方法如下图所示:
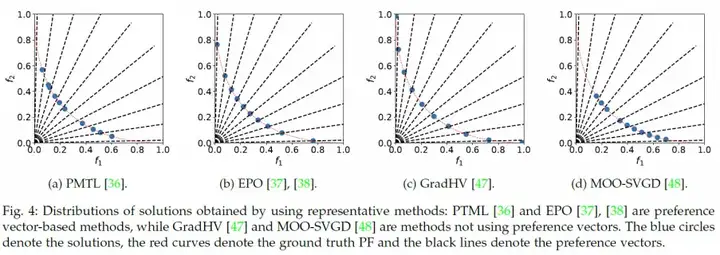
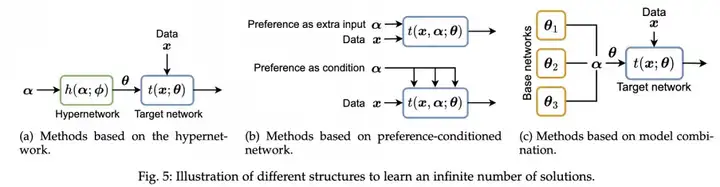
为满足用户在任一偏好下都能获得合适解的需求,研究者设计了直接学习整个 Pareto 集的方法,主要包括:
在训练过程中,这些方法通常采用随机采样用户偏好,利用端到端的梯度下降优化映射网络参数,同时结合标量化目标或超体积最大化等策略,确保映射网络能够覆盖整个解集并实现稳定收敛。
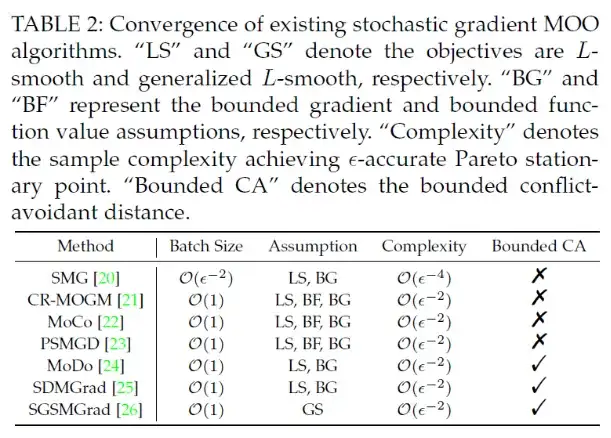
我们从收敛性和泛化性两个角度总结了现有的 MOO 的理论分析:
基于梯度的多目标优化方法已在多个前沿应用中展现出巨大潜力,主要包括:
尽管多目标优化方法已取得诸多进展,但仍面临一些亟待解决的问题:比如:理论泛化分析不足, 计算开销与高效性问题, 高维目标与偏好采样挑战, 分布式训练与协同优化以及大语言模型的多目标优化。
我们开源了多目标深度学习领域的两大的算法库:LibMTL 和 LibMOON。
项目地址:https://github.com/median-research-group/LibMTL
项目地址:https://github.com/xzhang2523/libmoon
本综述旨在为多目标深度学习领域提供一份全面的资源整合。我们系统地梳理了从算法设计、理论分析到实际应用的各个方面,并深入探讨了未来发展面临的挑战。无论您的研究重点是多任务学习、强化学习,还是大语言模型的训练与对齐,相信都能在本文中找到有价值的见解与启发。我们也认识到,当前的工作可能未能完整涵盖该领域的所有研究成果,如果你有任何建议或补充,欢迎访问我们的 GitHub 仓库,并提交 Issue 或 Pull Request,让我们携手推动这一领域的发展,共同进步!
文章来自于“机器之心”,作者“陈巍昱、张霄远、林百炅”。



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
