# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
编者按:现有RAG工具的碎片化和复杂性常常让开发者头疼不已。昨天我的Agent群里朋友们就Rerank问题展开激烈讨论,我想起之前看到的一篇论文,这项研究介绍了一个完美的开源python工具包Rankify,它将检索、重排序和RAG三大功能整合在一个统一框架中,大幅简化了开发流程。无论您是AI研究人员还是工程师,这篇文章都将为您揭示如何通过Rankify构建更高效、更准确的信息检索和生成系统。作者Abdelrahman Abdallah博士是因斯布鲁克大学数据科学组的专家,在自然语言处理和信息检索领域拥有丰富经验。
论文链接:[Rankify: A Unified Framework for Retrieval, Re-ranking, and Retrieval-Augmented Generation] https://arxiv.org/pdf/2502.02464
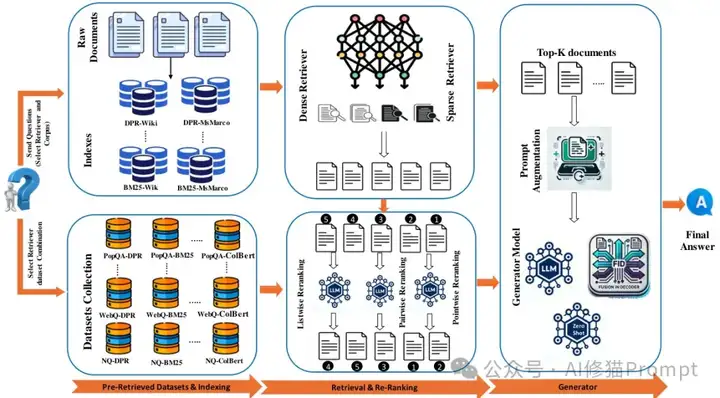
信息检索、重排序和检索增强生成(RAG)是现代AI应用的核心组件,但现有解决方案往往支离破碎,缺乏统一框架。你是否曾经为了实现一个完整的RAG系统而疲于奔命,在不同工具间切换,忍受各种兼容性问题?这种痛苦体验不仅浪费时间,还会影响最终产品质量。现在,一个名为Rankify的开源工具包横空出世,它将检索、重排序和RAG融合在一个统一的框架中,让开发者能够轻松构建高效的信息检索和生成系统,而不必再为工具链的复杂性而头痛。这项研究提供了1.48TB,40个基准数据集以及包括 BM25、DPR、ANCE、BPR、ColBERT、BGE 、 Contriever7种检索技术,24个主流重排序模型,无缝RAG集成。
Abdelrahman Abdallah, CC-BY License

目前市场上的RAG工具存在明显短板,它们要么只专注于检索,要么只关注重排序,很少有工具能够提供端到端的解决方案。这种碎片化导致研究人员和工程师不得不花费大量时间在工具整合上,而非核心算法优化。现有的工具如Pyserini、Rerankers和RankLLM虽然各有所长,但它们通常缺乏灵活性,实现方式过于刚性,并且需要繁琐的预处理步骤,这使得它们在研究驱动的实验环境中显得不够友好。
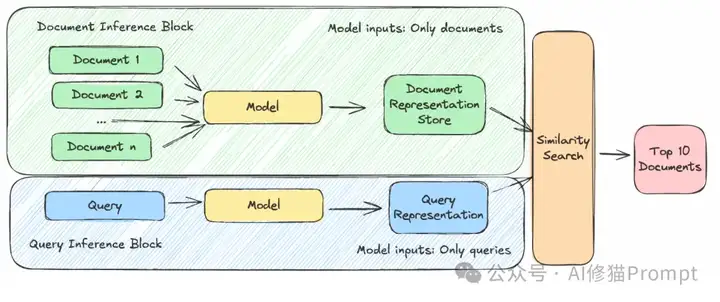
你可能会问:为什么不直接使用一个强大的检索方法,而要采用两阶段管道?答案在于效率与性能的平衡。在第一阶段,系统使用轻量级的检索方法——可以是基于关键词的(如BM25)或基于神经网络嵌入的向量搜索。这一步骤计算成本低:你只需要在推理时对一个(通常很短的)查询进行编码,然后快速进行相似度检查。然而,这一步骤是"冷启动"的,文档的表示是预先计算好的,不会根据新查询进行调整。
这就是重排序发挥关键作用的地方。在重排序阶段,模型同时考虑查询和每个候选文档,能够捕捉到初始检索步骤可能遗漏的微妙联系。缺点是这个过程计算成本高:你必须对每个候选文档运行推理,无法像之前那样预计算表示。对于大规模系统,实时处理每个文档的成本过高。
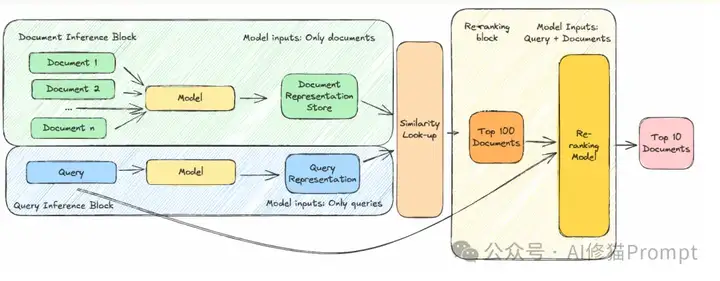
解决方案很直接:结合两种方法。首先使用更快的方法检索较小的文档池(比如10、50或100个看起来最相关的文档),然后对这个短列表应用计算更密集的重排序模型。这种混合策略结合了快速初始检索的效率和查询感知重排序的准确性,创建了一个高效的两阶段管道。
Rankify作为一个全面的Python工具包,旨在解决现有RAG系统的碎片化问题。它提供了一个模块化、可扩展的生态系统,将检索、重排序和RAG统一在一个框架内。与其他工具相比,Rankify支持40个数据集、7种检索器、24种重排序模型和3种RAG方法,总共可以创建超过20,160种不同的配置组合,这一数字远超其他工具包如FlashRAG(2,304种组合)和FastRAG(仅21种组合)。下表展示了Rankify与其他工具的详细对比:

工具包对比
历史上,重排序主要由交叉编码器模型主导——本质上是使用类BERT架构的二元分类器。这些模型将查询和候选文档作为输入,并产生"相关性"分数(通常被解释为概率)。这种方法被称为逐点重排序(Pointwise re-ranking),为每个查询-文档对生成独立的分数。
随着时间推移,重排序方法已经超越了传统模型。一个例子是MonoT5,这是一个训练用来将文档分类为"相关"或"不相关"的模型。模型预测这些标签之一,分配给"相关"的概率作为排名的相关性分数。
更先进的方法现在将大型语言模型(LLMs)应用于重排序任务。例如,BGE-Gemma2微调了一个90亿参数的LLM,通过估计"相关"标签的可能性来计算相关性分数。
除了这些模型外,一些方法采取了不同的重排序方式。例如:
• 后期交互模型(如ColBERT)——不是直接产生相关性分数,而是在后期阶段比较查询和文档的表示,完善排名结果。
• 列表式重排序——不是单独对每个文档评分,而是一次性分析整个文档集并集体重新排序。传统上,基于T5的模型用于此目的,但较新的方法在零样本模式下探索LLMs(RankGPT)或微调较小的模型,使用更先进模型的输出(RankZephyr)。
简而言之,重排序有许多方法,每种方法都有其优缺点——没有一种方法在所有情况下都是最佳的。找出哪种模型最适合你的用例(有时需要微调自己的模型)可能具有挑战性。使这更加困难的是,不同技术通常需要特定的输入格式并以不同方式产生输出,使得在模型之间切换变得困难。
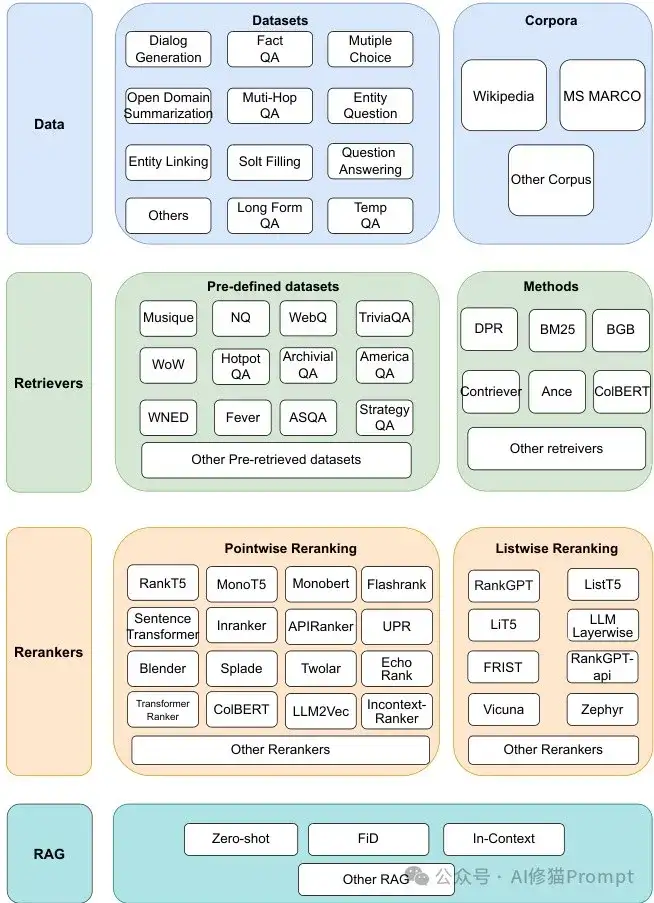
Rankify的一大亮点是它提供了40个经过精心策划的数据集1.48TB,超过1,000万个预检索的文档,涵盖问答、对话、实体链接等多个领域。它还包含了针对多种检索器预计算的Wikipedia和MS MARCO语料库,这极大地减少了预处理开销。想象一下,你不再需要花费数小时甚至数天来准备数据和训练检索模型,所有这些都已经为你准备好了,你只需专注于你的核心任务。
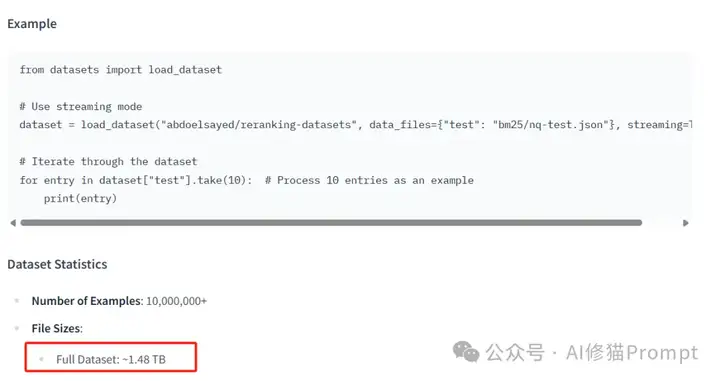
数据集链接:https://huggingface.co/datasets/abdoelsayed/reranking-datasets
检索定义了搜索引擎的工作方式——当你输入查询时,它获取相关文档。然而,并非所有搜索方法都相同。
可以将检索视为一个两步过程:
通过结合这两种方法,混合检索通过利用基于关键词和基于含义的搜索的优势来提高准确性。
Rankify集成了密集检索器(如DPR、ANCE、BPR、ColBERT、BGE、Contriever)和稀疏检索器(如BM25),同时支持24种最先进的重排序模型。这种多样性使得研究人员和工程师可以轻松尝试不同的检索和排序策略,找到最适合特定任务的组合。下面是一个简单的代码示例,展示了如何使用Rankify进行检索和重排序:
from rankify.retrievers import BM25Retriever
from rankify.rerankers import MonoT5Reranker
# 初始化检索器和重排序器
retriever = BM25Retriever(index_name="wiki-small")
reranker = MonoT5Reranker()
# 执行检索
query = "谁发明了电灯泡?"
retrieved_docs = retriever.search(query, k=10)
# 重排序结果
reranked_docs = reranker.rerank(query, retrieved_docs)
Rankify不仅仅是一个检索和重排序工具,它还提供了与RAG的无缝集成,允许将检索到的文档传递给语言模型进行评估。Rankify的RAG集成支持多种生成模型,包括:
此外,Rankify还提供了全面的评估工具,包括各种检索和问答评估指标,如Top-K准确率、精确匹配(EM)、召回率、精确度和NDCG(归一化折扣累积增益),帮助研究人员客观地比较不同方法的性能。
Rankify在多个基准测试中展现出卓越的性能。例如,在Natural Questions(NQ)数据集上,Rankify实现的DPR检索器达到了79.5%/86.8%的Top-20/Top-100准确率,与原始DPR论文报告的78.4%/85.4%相比有明显提升。类似地,在TriviaQA和WebQuestions数据集上,Rankify实现的检索器也展现出与原始论文相当或更好的性能。
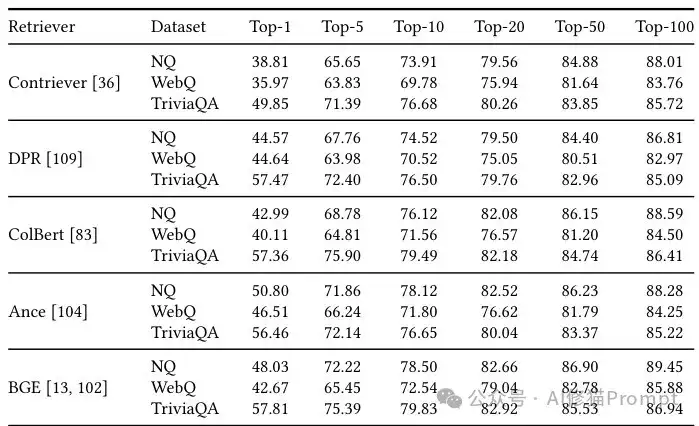
检索性能对比
使用Rankify构建RAG系统非常简单,只需几行代码即可完成。首先,通过pip安装Rankify:
pip install rankify
然后,你可以使用以下代码构建一个完整的RAG系统:
from rankify.retrievers import BM25Retriever
from rankify.rerankers import MonoT5Reranker
from rankify.rag import LLMGenerator
# 初始化组件
retriever = BM25Retriever(index_name="wiki-small")
reranker = MonoT5Reranker()
generator = LLMGenerator(model_name="llama-7b")
# 执行RAG流程
query = "解释量子计算的基本原理"
retrieved_docs = retriever.search(query, k=10)
reranked_docs = reranker.rerank(query, retrieved_docs)
answer = generator.generate(query, reranked_docs[:3])
print(answer)
你正在开发一个问答系统,需要从大型知识库中检索信息并生成准确的回答。使用传统方法,你需要分别构建检索系统和生成系统,然后想办法将它们整合起来。而使用Rankify,这一切变得异常简单。你只需几行代码就可以实现从检索到生成的完整流程,而且可以轻松切换不同的检索器和重排序模型,找到最适合你特定任务的组合。
Rankify支持的40个数据集涵盖了各种任务类型,包括开放域问答、多跳推理、事实验证和时间检索等。这些数据集的检索性能各不相同,例如,在TriviaQA等开放域问答数据集上,BM25检索器可以达到较高的Top-k准确率,而在2WikiMultiHopQA和HotpotQA等多跳数据集上,检索率相对较低,这反映了在多个文档中检索支持证据的挑战。下表展示了BM25在多个数据集上的检索性能:
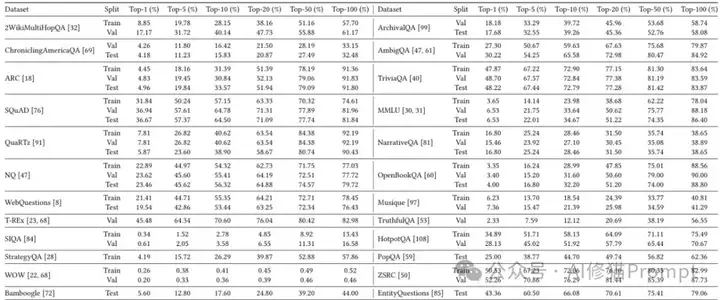
数据集检索性能
立即开始使用Rankify!
RAG系统的构建不必如此折磨。有了Rankify,你可以告别工具碎片化和复杂性带来的痛苦,专注于你的核心任务。无论你是研究人员还是工程师,Rankify都能为你提供一个统一、灵活、高效的框架,帮助你构建最先进的检索和生成系统。现在就尝试pip install rankify,体验检索、重排序、RAG三合一的完美解决方案吧!
Abdelrahman Abdallah
发布日期:2025年2月27日
职位:博士候选人
所属机构:因斯布鲁克大学数据科学组
I am a PhD candidate in the Data Science Group, supervised by Prof. Adam Jatowt. My research focuses on natural language processing and information retrieval, with an emphasis on Dense Retrieval, and open-domain question answering systems. I have published articles in top-tier IR/NLP conferences and leading journals.
[1] Abdallah, A., Mozafari, J., Piryani, B., & Jatowt, A. (2025). ASRank: Zero-Shot Re-Ranking with Answer Scent for Document Retrieval. arXiv preprint arXiv:2501.15245.
[2] Abdallah, Abdelrahman, Jamshid Mozafari, Bhawna Piryani, Mohammed M. Abdelgwad, and Adam Jatowt. "DynRank: Improving Passage Retrieval with Dynamic Zero-Shot Prompting Based on Question Classification." arXiv preprint arXiv:2412.00600 (2024).
[3] Robertson, Stephen, and Hugo Zaragoza. "The probabilistic relevance framework: BM25 and beyond." Foundations and Trends® in Information Retrieval 3, no. 4 (2009): 333-389.
[4] Karpukhin, Vladimir, Barlas Oguz, Sewon Min, Patrick SH Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. "Dense Passage Retrieval for Open-Domain Question Answering." In EMNLP (1), pp. 6769-6781. 2020.
[5] Lin, Jimmy, Xueguang Ma, Sheng-Chieh Lin, Jheng-Hong Yang, Ronak Pradeep, and Rodrigo Nogueira. "Pyserini: A Python toolkit for reproducible information retrieval research with sparse and dense representations." In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 2356-2362. 2021.
[6] Clavié, Benjamin. "rerankers: A Lightweight Python Library to Unify Ranking Methods." arXiv preprint arXiv:2408.17344 (2024).
[7] RankLLM is a Python toolkit for reproducible information retrieval research using rerankers, with a focus on listwise reranking.
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
