# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
DeepSeek又卷起来了!上周刚出的DeepSeek-V3-0324在大模型竞技场排名中,打败了自己的DeepSeek-R1,成为开源AI至尊。
DeepSeek依然很能打,春节余波还在扩散!
据AI产品分析平台aitools.xyz统计,DeepSeek每月新增网站访问量超过了ChatGPT。
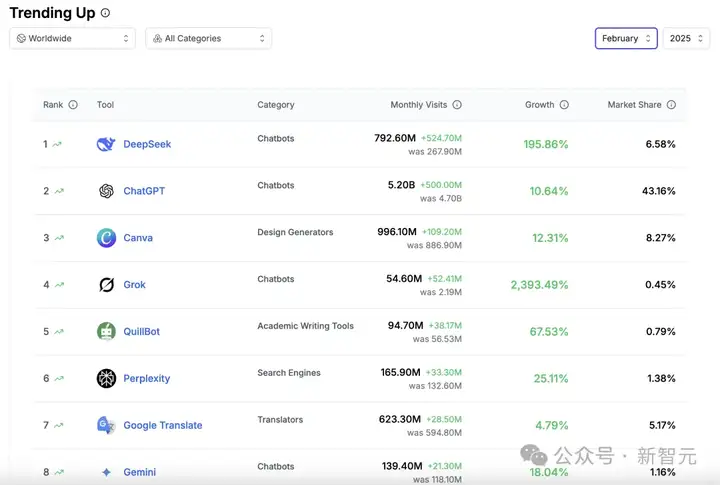
作为异军突起的现象级产品,DeepSeek的增长速度除了创造AI产品的增长奇迹,更是重新定义了全球的AI竞赛格局。
DeepSeek除了「卷」竞争对手,甚至也在自己「卷」自己。
在AI大模型竞技场LMSYS上,发布不到半个月的DeepSeek-V3-0324,已经超过了曾经的「当红炸子鸡」DeepSeek-R1!
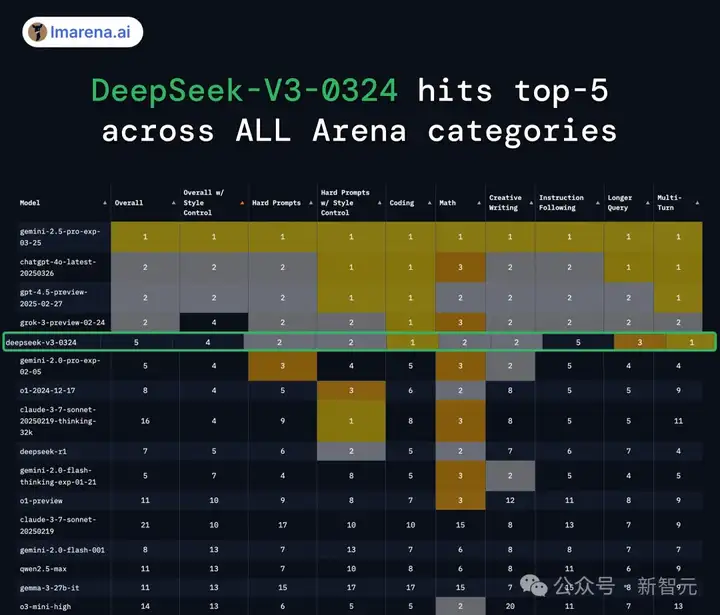
所有类别排名前5,DeepSeek-V3-0324成为排名第一的开源(MIT许可)模型。
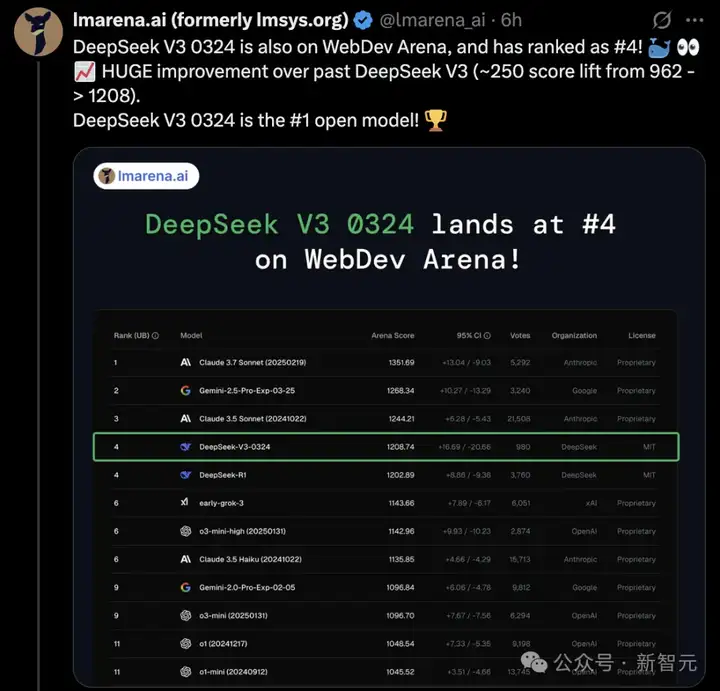
这还是在DeepSeek-R2没有发布的前提下,R2发布的那天,AI圈估计又是一场不眠夜。
但「革命尚未成功」,不要忘了,ChatGPT的总市场份额依然高达43.16%,周活用户已破5亿。

不仅如此,OpenAI也决定通过开源,来应对DeepSeek的巨大冲击。今早,奥特曼已官宣,自GPT-2后首个推理模型,将在未来几个月开源。
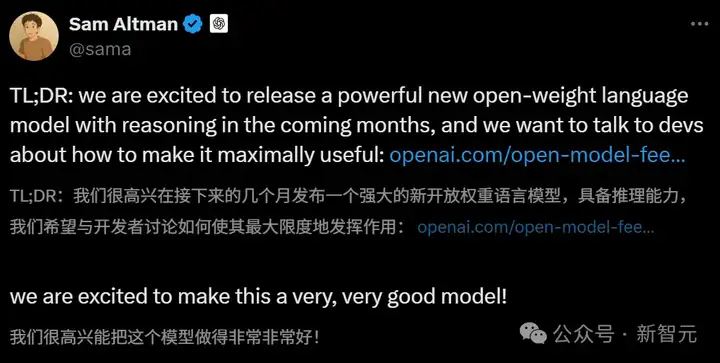
那么,它又会比R1强吗?若是R2提前开源,OpenAI又该如何自处?

DeepSeek-V3-0324这波进化,实属有亿点点厉害。
目前在榜单排行中,它的实力与Gemini 2.0 Pro、GPT-4.5 preview、Gemini 2.0 Flash Thinking并驾齐驱。
也就是说,当前闭源模型最强三款——Gemini 2.5 Pro、GROK 3、GPT-4o之后,开源模型之光便是DeepSeek-V3了!
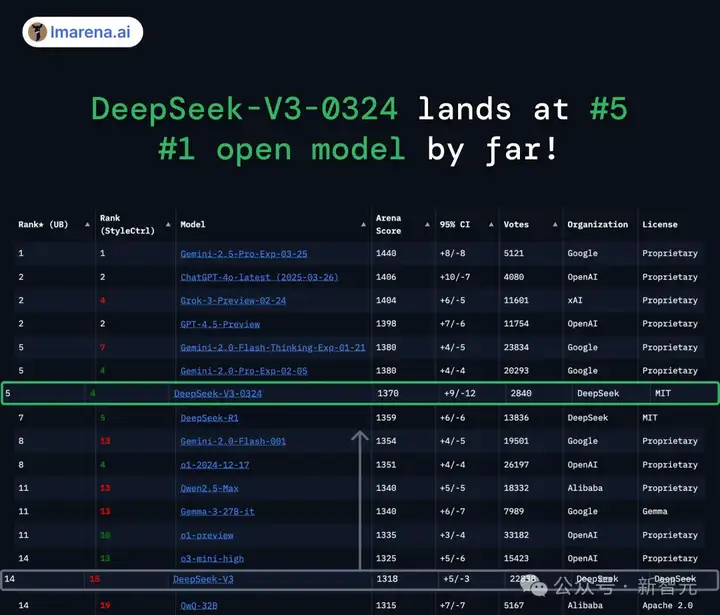
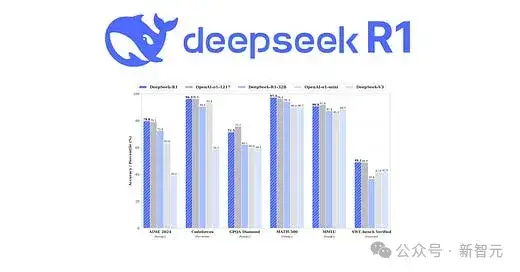
在所有评测类别中,DeepSeek-V3-0324在编码、Multi-Turn上,位列第一。
其他数学、创意协作、长查询等基准中,V3也取得了亮眼的表现。
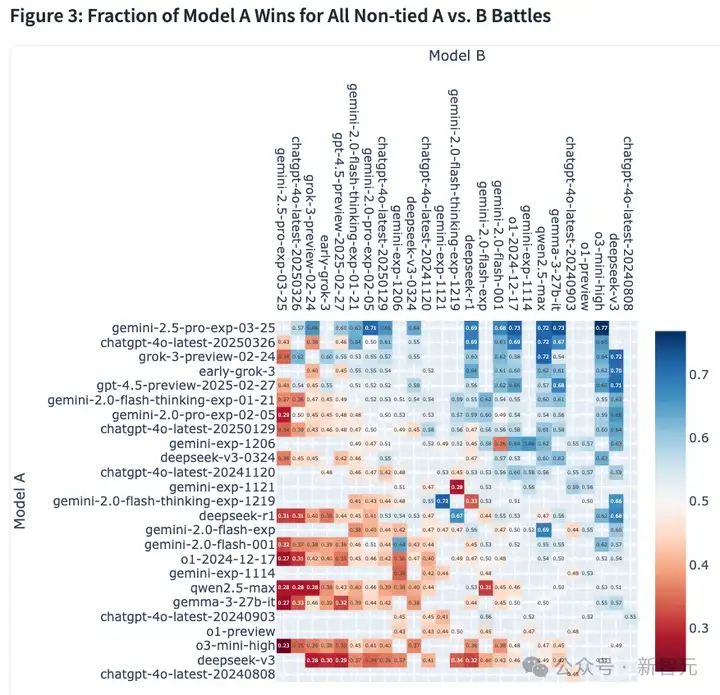
如下是所有模型的胜率热图。
所有开发者,着实感受到了DeepSeek-V3-0324强大的编程能力。有开发者,直接用一条指令便构建出一个游戏。
他表示,「编程革命已至,零基础也能驾驭」。

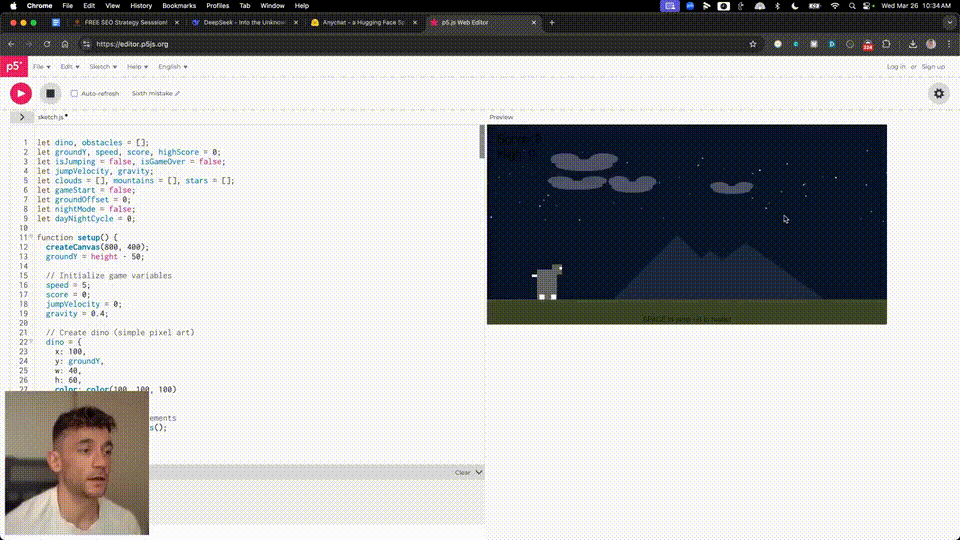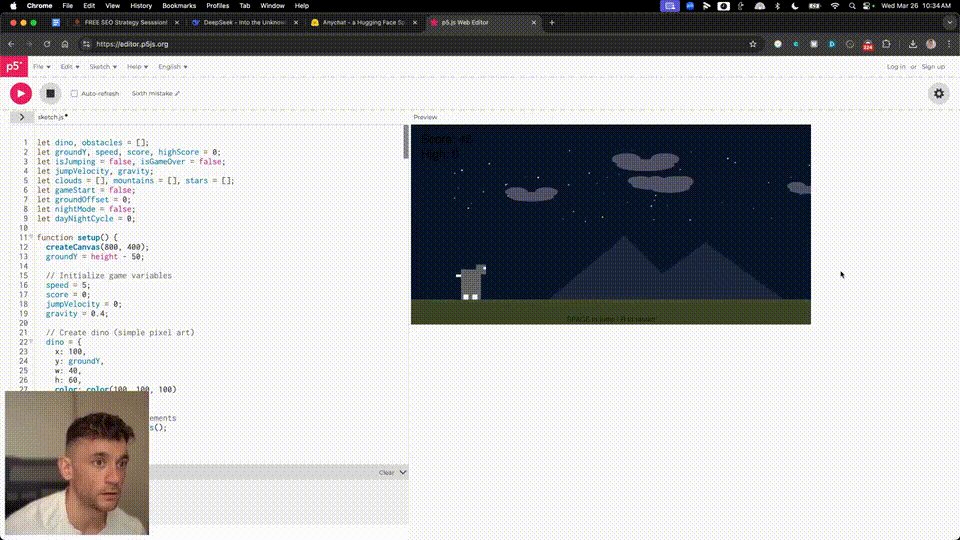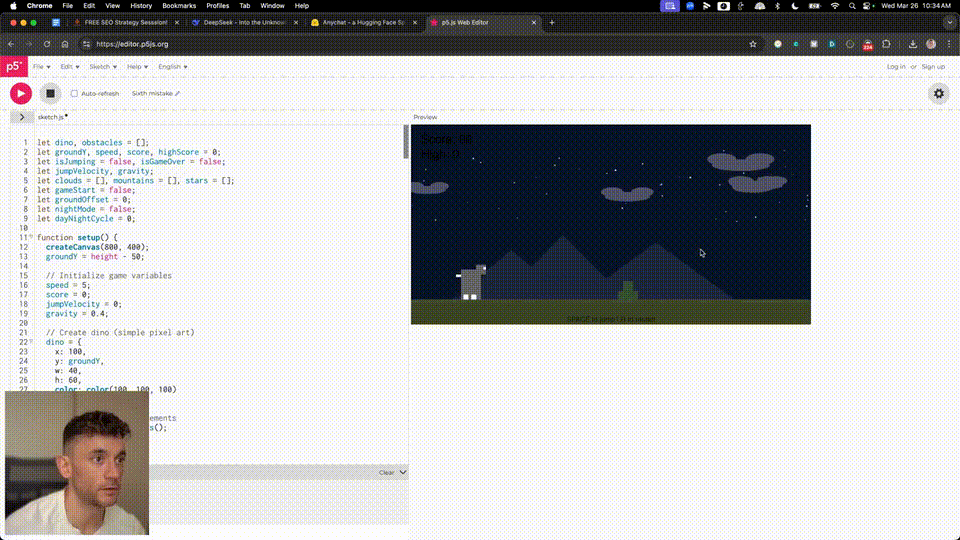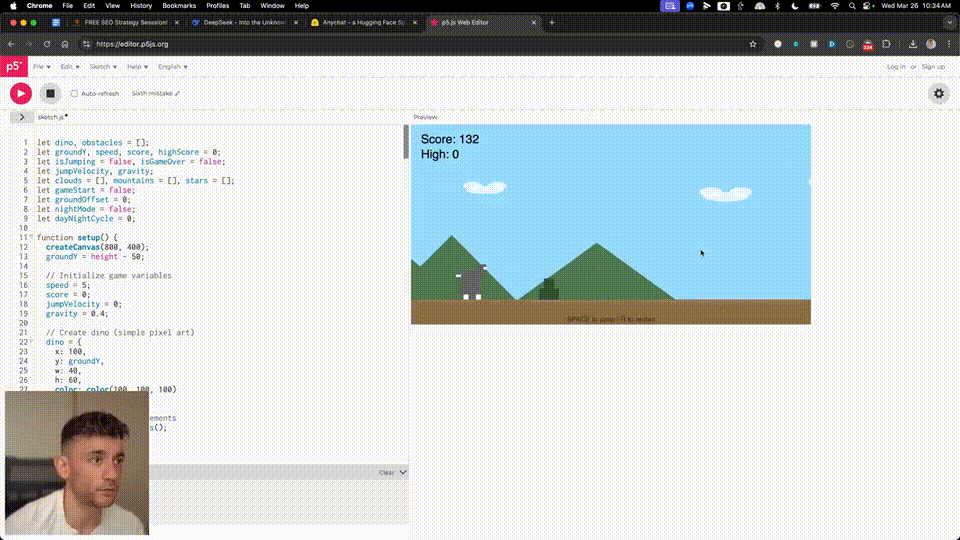
V3肝了800行代码,一次性构建出网站,也没有出任何错。

一直以来,有种说法:「美国创新,中国迭代」。
直至今年1月,来自中国初创公司DeepSeek打破了这个「定律」。
他们发布的首款推理模型DeepSeek-R1,性能堪比几个月前刚推出的OpenAI o1。
R1横空出世,不仅创新性十足,而且成本低得惊人,前一代模型V3的最后一轮训练只花了600万美元。
AI大神Karpathy认为,和美国一些竞争对手动辄花几千万甚至上亿美元相比,这简直就是「小巫见大巫」。
随着R1飙升至热门下载榜首,大型科技投资者陷入恐慌,英伟达、微软等科技股市值蒸发超过1万亿美元。
奥特曼也表达了自己的焦虑,并考虑开源,像DeepSeek一样,让模型公开可用和可修改,从而降低使用成本。
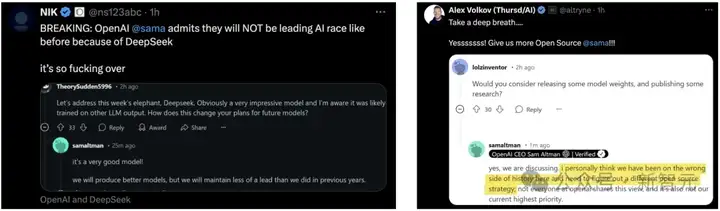
奥特曼深刻忏悔:自己在开源AI上站错了队
乔治华盛顿大学助理教授Jeffrey Ding表示,「很多人都低估了中国开发这些前沿突破性技术的能力。」
一夜之间,国内外不同赛道的大企业,争相把R1模型接入自家产品。
DeepSeek的成功就像一针「强心剂」,能以无法想象的方式推动经济发展。
与此同时,投资者纷纷涌入中国科技股。
DeepSeek的成功表明,中国AI初创企业并非只有依靠巨额资金才能在全球竞争中崭露头角。
转折点出现在2024年秋季,从那时起,差距开始逐渐缩小。
尤其是在开源领域,中国企业开始聚焦小型模型的优化,显著提升了训练效率。
开源模型有助于构建更庞大的用户生态。
阿里在推动开源技术发展方面发挥了重要作用,开源社区Hugging Face性能排名前十的LLM,均基于阿里云的通义千问模型进行训练。
中国AI行业能实现快速追赶,庞大的市场规模是一个重要因素。
腾讯旗下拥有超10亿用户的微信平台,将DeepSeek的模型接入后,用户量呈爆发式增长,迅速成为中国AI领域的明星企业。
此外,人才也是中国AI行业崛起的关键要素。
中国高校每年培养出大量优秀工程师,为AI初创企业提供了充足的人才资源。这些年轻人专业能力出众,其数量和质量是美国高校难以比拟的。
如今,DeepSeek不再仅仅是一家公司,而是开源AI、低成本AI的代名词。
它不仅打破了硅谷在AI领域技术领先地位,更以低成本、高效率的创新模式,重新定义了全球科技竞争的新范式。
参考资料:
https://x.com/ai_for_success/status/1906744310512648586
文章来自于“新智元”,作者“编辑部 XYs”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
