# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
通过完全启用并发多块执行,支持任意专家数量(MAX_EXPERT_NUMBER==256),并积极利用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE Align & Sort逻辑被精心设计,实现了显著的性能提升:A100提升3倍,H200提升3倍,MI100提升10倍,MI300X/MI300A提升7倍...
MoE(Mixture of Experts)模型模仿了人脑的低功耗运作模式:功能被划分为多个独立的部分,在思考时通过自适应路由部分激活,从而提高计算效率。
牛津大学研究论文中的人脑皮层示意图,来源于互联网
首个可在CUDA真正可行的版本是Switch Transformer[1],随后通过循环利用(Up Cycling)稠密模型Mistral[2]进一步优化了该设计。
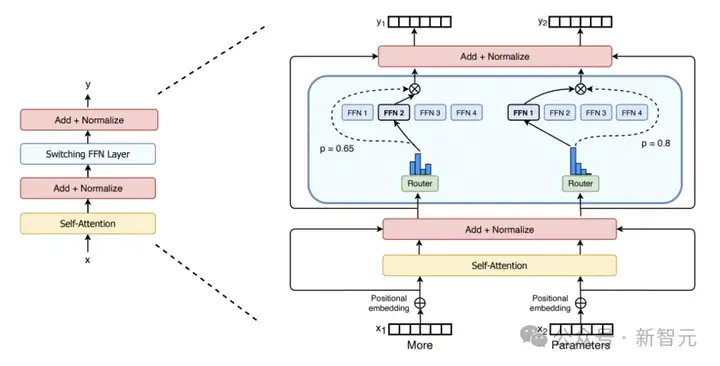
SwitchTransformer-MoE
随后,DeepSeek V2/V3/R1[3][4][5]通过引入共享专家[3]和门控偏差(gating bias)[4][5]进一步改进了MoE,最终实现了无辅助损失(auxiliary loss free)的MoE模型 [4][5]。这一优化本质上归因于一个关键事实:当使用共享专家(DeepSeek团队选择的值为1)时,可以通过在较大的专家池(256个上施加偏差分数的惩罚,从而缓解专家路由的不均衡问题[11]。
MoE层本质上是由多个专家前馈网络(FFN)组成的层,其中包含门控函数(gating functions),用于根据Top-K门控分数(DeepSeek V3/R1中引入偏差)进行激活路由,并在所选的FFN层上通过Group GEMM计算logits。
该功能在很大程度上依赖于基数排序(radix sort)逻辑。借助MoE Align & Sort,机器学习研究人员和实践者可以按照专家ID对tokens进行排序。
在某些应用中,例如TransformerEngine[6][7],该操作最初是通过已废弃的cub::DeviceRadixSort实现的,而增加的permute操作用于记录源(左)到目标(右)的映射,其梯度操作为unpermute。
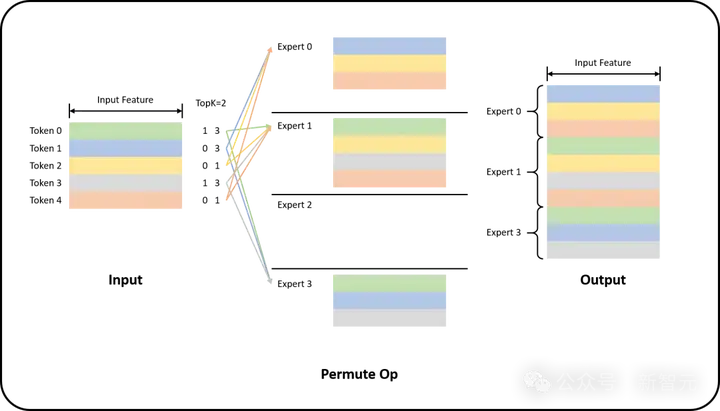
MoE Permute示例
尽管cub::DeviceRadixSort大量使用共享内存,相比于基于__shfl_xor_sync(仅使用线程本地内存)的实现略慢,但它不支持对齐排序(alignment sorting)。
对齐排序对于Group GEMM的效率至关重要,因为它允许专家以块(block 为单位处理tokens。
SGLang 中的MoE Align & Sort算法采用了对齐排序,但在支持多达256个专家的大规模prefill操作时效率并不理想。该问题已在issue#2732中被确认。
目前的实现将MoE Align & Sort拆分为两个kernel启动(kernel launches):
研究人员提出并编写了AMD友好的CUDA设备代码,采用了该设计的MoE Align & Sort算法。因此,在AMD平台上的性能分析和优化将被充分考虑。

文章地址:https://shorturl.at/C23JF
通过在不同的工作负载下使用RocProfiler-Compute进行分析,可以清楚地看到,即使不计入多次设备函数启动的额外开销,第一个kernel仍然消耗了33W个周期,第二个kernel消耗了8W个周期,总计41W周期:
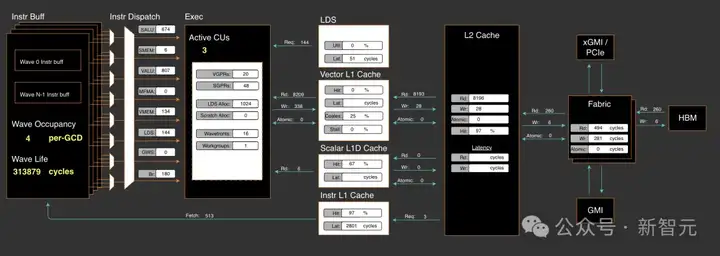
the moe align kernel 1
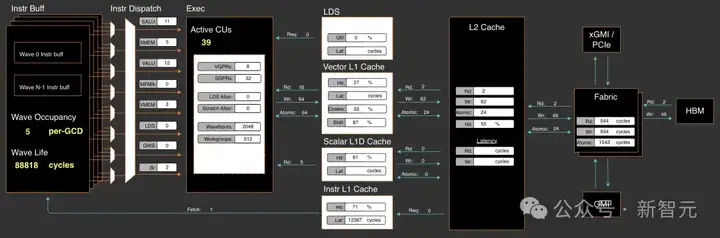
the moe align kernel 2
在ROCm SDK 6.3.0 中,omniperf已更名为rocprof-compute。尽管MI300X/MI300A已得到积极支持,但该工具默认未随ROCm SDK 6.3.0一同发布。不过,在Tools-dockerhub中的展示一样,ROCm计算分析工具的设置仅需简单三步。
现在,在PR#3613(https://shorturl.at/OPbiI)中应用优化方案后,片上计算开销将从之前的41W个周期立即降低至20W个周期。
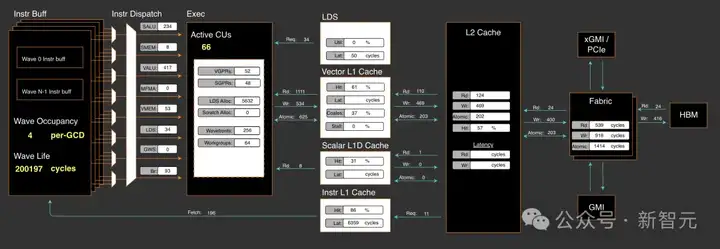
在SGLang中实现高效的多块(multi-blocks)MoE-Align
通过完全地多块(multiple blocks)并发执行,并支持任意专家数量(MAX_EXPERT_NUMBER==256),结合激进使用共享内存(5kB LDS)和寄存器(52 VGPRs,48 SGPRs),MoE Align & Sort逻辑被优化,实现了以下性能提升3x in A100,3x in H200, 10x in MI100, and 7x in MI300X/Mi300A:
借助Rocprof-Compute,可以轻松收集捕获设备代码的一些关键指标,并在远程GUI服务器上进行可视化展示:
服务端开启Rocprof-Compute
总而言之,在AMD MI300X/MI300A上,所提出的高效多块(multi-blocks)MoE Align & Sort算法充分利用了每个wave的向量寄存器(52个),且无寄存器溢出(我已将初始线程块大小调整至最佳值);同时,每个CU使用5kB LDS,且仅有6.8%的存储银行冲突率。
研究人员还分析了MoE Sort & Align的Roofline模型。该模型显示,设备代码的性能在受限于内存带宽的区域有所下降。
在AMD Compute Profile部分,研究人员详细介绍了在ROCm平台上算法设计的影响与性能数据。
本质上,MI300X/MI300A是全球首款基于多芯片(multi-die)设计的高性能AI加速器架构。因此,在该芯片上进行算子优化的方式将与NVIDIA平台略有不同。
基本规则是,XCDs(加速计算芯片)之间的同步代价较高,因此最好充分利用XCDs,并利用L2缓存的局部性亲和性来提高性能。
此外,研究人员应避免昂贵的同步开销,具体方法包括:
使用hipCooperativeLaunch启动协作设备代码可能会增加L2缓存压力(与纹理寻址器停滞率和忙碌率相关),特别是在数据交换(尤其是Die-Die交换增多的情况下。
在此示例中,之前main分支的实现使用了39个活跃CU,这已经接近最佳,因为本质上使用了两个Die。
该实现在多块(multi-blocks)执行中使用了66个活跃CU,跨越两个Die,并且块级归约(block-wise reduction)过程中Die-Die数据交换是不可避免的,将在本季度晚些时候向SGLang提交进一步的V4优化。
具体细节将在性能分析(profiling)部分进一步讨论。
SGLang团队采用Triton First方法实现了相关逻辑,并在2024年12月成功实现DeepSeek V3的Day-0支持。
SGLang的MoE调用了使用Triton实现的Fused MoE 设备代码。
在设备代码启动之前,会应用MoE Align & Sort算法。MoE Align & Sort的Triton设备代码被拆分为四个阶段,其中直接访问DRAM,而不使用共享内存,这与向量化 Triton版本形成对比。
与单块(single block wise)CUDA实现相比,Triton版本的多次设备代码触发以及对LDS、本地缓存和寄存器(例如VGPR)的低效利用,导致了在小规模工作负载上的单次测试执行效率较低。
随后,CUDA实现最终被拆分为两个阶段,其中仅第二阶段的执行在多块(multiple blocks)上进行了加速。
在Mistral[2]和DeepSeek V2[3]之前,开放式稠密模型(open dense models)在推理场景中更为流行。这也是FasterTransformer[8]诞生的时期。
在FasterTransformer[8]项目中(由NVIDIA发起),MoE模型的支持主要依赖于cub::DeviceRadixSort,以及诸如moe_softmax(本质上是cub::BlockReduce实现的softmax)、moe_top_k及其融合版本topk_gating_softmax、用于排列潜在向量logits的permute,最终执行group gemm。
因此,融合优化主要(按计算开销计算)限制在topk gating softmax和biased topk gating softmax,后续这些优化被整合进SGLang。
在该算法发表之前,Megatron在FP16/BF16计算中主要采用FasterTransformer方法,但额外添加了permute的梯度操作unpermute,以支持训练任务。
这意味着MoE仍然没有得到高效融合。
SGLang使用了许多vLLM设备代码,但vLLM的Fused MoE最初是由SGLang团队贡献的。因此,它们采用了相同的方法进行部署。
首个AMD友好的Fused MoE版本于2024年11月26日在CK#1634(https://tinyurl.com/3fuj7yws)中提出。随后,MoE Align & Sort被添加到CK#1771(https://tinyurl.com/5h4e8jat)和CK#1840(https://tinyurl.com/3wm8pdc3)中。
核心思路是将MoE 排序与Group GEMM进行融合。此外,CK中的MoE & Sorting在很大程度上采用了SGLang团队的方法,但在CK pipeline及partitioner方面有所不同。
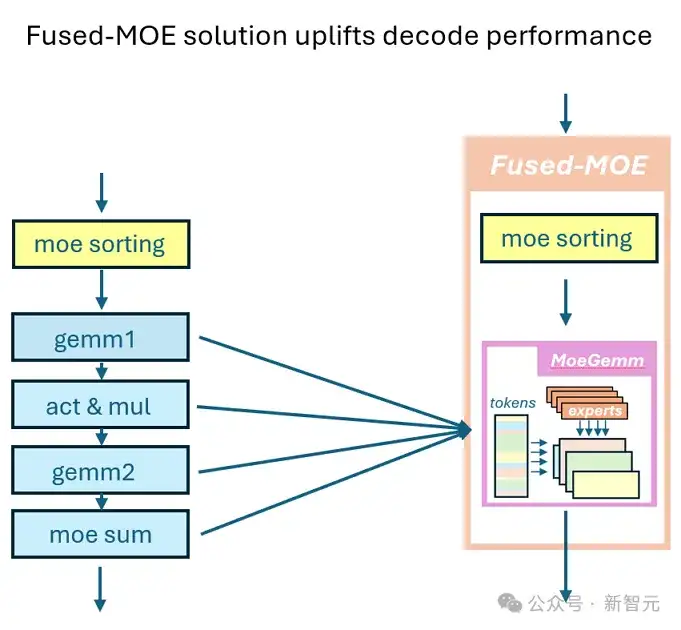
CK融合MoE思路[9]
融合per_group_token_quant(用于在线FP8量化)、MoE排序和Group GEMM可以通过将Radix Sort计算逻辑纳入Group GEMM pipeline轻松解决:即统计出现次数以计算偏移量,随后进行并行放置。
其中最关键的问题之一是如何平衡Radix Sorting和Group GEMM这两种计算负载。
在AMD数据中心芯片中,Group GEMM片段更可能均匀分布在XCD内的所有可用计算单元。然而,当涉及多个XCD时,不同CU之间的数据交换主要通过低速L2 Cache及其互联结构(L2 Cache fabric)进行。
编写CK设备代码需要先编写主机端CK解决方案启动器:
// Here is the entry of fused MoE :
// https://github.com/ROCm/composable_kernel/blob/1342ecf7fbf64f43d8621cf6665c583fdc49b2c6/example/ck_tile/15_fused_moe/instances/fused_moegemm_api_internal.hpp
using f_pipeline = ck_tile::FusedMoeGemmPipeline_FlatmmUk<f_problem>;
using f_partitioner = ck_tile::FusedMoeGemmTilePartitioner_Linear<f_shape>;
using f_kernel = ck_tile::FusedMoeGemmKernel<f_partitioner, f_pipeline, void>;
const dim3 grids = f_kernel::GridSize(a);
constexpr dim3 blocks = f_kernel::BlockSize();
constexpr ck_tile::index_t kBlockPerCu = 1;
static int printed = 0;
auto kargs = f_kernel::MakeKargs(a);
if(s.log_level_ > 0 && printed == 0)
{
std::cout << ", " << f_kernel::GetName() << std::flush;
printed = 1;
}
return ck_tile::launch_kernel(
s, ck_tile::make_kernel<blocks.x, kBlockPerCu>(f_kernel{}, grids, blocks, 0, kargs));
AMD CK分区器和阶段流水线(stages pipeliner)在Fused MoE的最终汇编过程中扮演了重要角色,确实值得深入研究,但已超出本文讨论范围。
但需要记住,MoE Align & Sort是生产者代码的一部分:
// https://github.com/ROCm/composable_kernel/blame/fdaff5603ebae7f8eddd070fcc02941d84f20538/include/ck_tile/ops/fused_moe/kernel/moe_sorting_kernel.hpp#L438
CK_TILE_DEVICE void moe_align_block_size_kernel(...)
{
const index_t tid = static_cast<index_t>(threadIdx.x);
const index_t start_idx = tid * tokens_per_thread;
...
#if 1
if(tid < num_experts){ // each thread reduce a column segment of tokens_cnts with # blockDim.x elements
...
}
#else
...
#endif
__syncthreads();
// do cumsum to compute offsets based on condition
...
// do parallel placement based on the offsets computed
...
}
因此,在AMD CK方案中,MoE Align & Sort的实现几乎与SGLang主实现保持一致,仅在分区器(partitioner)和流水线(pipeliner)方面有所不同。
需要注意的是,该实现并不总是能在AMD平台上提供最佳性能(请参考AITER中的asm MoE)。
由于AMD CDNA3架构并不支持类似Graphcore的片上(on-chip)洗牌操作(在2023年已经将PopART[12] & PopRT的Remapping操作进行抽象与泛化),而这一特性已在NVIDIA H100/H200/B200中得到了支持,并通过高效的SM<->SM片上通信实现。
因此,在AMD 开源解决方案中,如何以低开销方式在块(block)之间优化数据布局将是一个非常有趣的研究方向。
从哲学上讲,这两类不同工作负载的基于 Tiling 的融合代码可能并不总是比非融合版本更优。相关研究的详细内容将在V4 版本发布时进一步探讨。
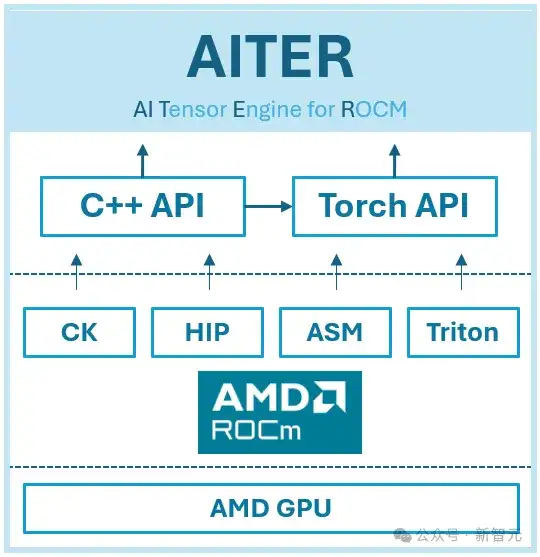
AI Tensor Engine[10]
AITER在今年早些时候被引入,以便整合在不同项目中使用的LLM设备代码。它通过ck moe、asm 版本的 MoE 通过 hipModule和triton fused moe支持MoE融合。
因此,AITER是部分开源的,因为不透明的汇编代码和开发计划是针对MI300X开发者的。
AITER中fused MoE的三倍加速[10]已由Bruce Xu[13]验证,并且这一加速主要来自于在不同形状的Group GEMM中观察到的加速:一个GEMM操作,其中每个专家的FFN权重与一块隐藏状态的token进行相乘。
这一证明可以在PR#199(https://shorturl.at/F8y0F)中找到,asm gemm几乎带来了三倍的性能提升。
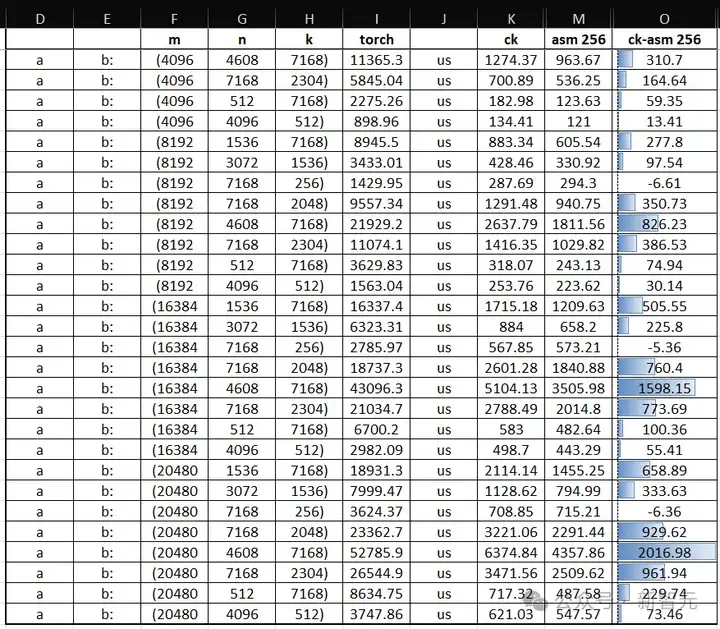
ASM版本扁平矩阵乘
值得注意的是,仍然有一些情况下,选择了来自SGLang社区的triton设备代码。为了在MI300X/MI300A上高效运行triton设备代码,它们采用了基于多芯片架构的特定逻辑,将线程块映射到不同的计算单元(dies)上:
# https://github.com/ROCm/triton/blob/f669d3038f4c03ee7a60835e875937c65b5cec35/python/perf-kernels/gemm.py#L115
...
## pid remapping on xcds
# Number of pids per XCD in the new arrangement
pids_per_xcd = (GRID_MN + NUM_XCDS - 1) // NUM_XCDS
# When GRID_MN cannot divide NUM_XCDS, some xcds will have
# pids_per_xcd pids, the other will have pids_per_xcd - 1 pids.
# We calculate the number of xcds that have pids_per_xcd pids as
# tall_xcds
tall_xcds = GRID_MN % NUM_XCDS
tall_xcds = NUM_XCDS if tall_xcds == 0 else tall_xcds
# Compute current XCD and local pid within the XCD
xcd = pid % NUM_XCDS
local_pid = pid // NUM_XCDS
# Calculate new pid based on the new grouping
# Note that we need to consider the following two cases:
# 1. the current pid is on a tall xcd
# 2. the current pid is on a short xcd
if xcd < tall_xcds:
pid = xcd * pids_per_xcd + local_pid
else:
pid = tall_xcds * pids_per_xcd + (xcd - tall_xcds) * (pids_per_xcd - 1) + local_pid
if GROUP_SIZE_M == 1:
pid_m = pid // num_pid_n
pid_n = pid % num_pid_n
else:
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + (pid % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
...
此外,在CK fused MoE中使用了多种AMD芯片内建函数(intrinsics),例如:
等等。这些内建函数可能最终影响fused MoE的汇编实现和性能。
例如,使用__builtin_nontemporal_load可以跳过L2缓存,从而为预测将被重复使用的数据留出更多L2缓存行空间。
Fused MoE尚未在NVIDIA Cutlass 3.8.0中公开支持。因此,当前该仓库中没有提供MoE Align & Sort功能。
在v0.16.0之前,TRT-LLM基本上遵循了FasterTransformer的方法。自v0.17.0版本起,MoE部分开始公开。
编写对AMD设备友好的CUDA实现,并带来超过3x~7x加速
该算法采用了多块执行方案,并由三个不同的部分(D-C-P)组成:
并行非对齐本地累积和
合并非对齐累积和
对齐全局累积和
存储全局累积和
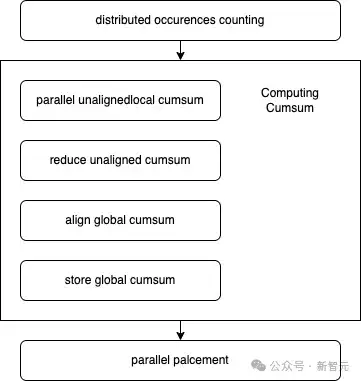
高效MoE Align& Sort算法
并行非对齐本地累积和
该算法首次由在PR#2970(https://shorturl.at/CuBs5)中提出并实现。
研究人员将每个块中的累积和执行进行了负载均衡,分配给kElementsPerThr(16)个线程,每个线程需要处理kElementsPerThr+kElementsPerThr+threadIdx.x次加法操作。
因此,与当前仓库中的单线程版本相比,波前(wavefront)更快地到达,可以观察到此版本实现的性能提升了30%。
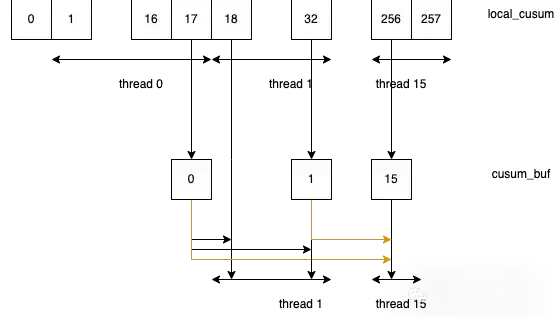
一旦获得了每个块中的本地非对齐累积和(Unaligned Cumsum),就可以在预分配的HBM缓冲区中进行块级别的累积和归约。
研究人员选择了FRAG_SIZE_M(16)xFRAG_SIZE_N(16)xFRAGS_PER_BLOCK(4)的SRAM块进行块级归约,其中FRAGS_PER_BLOCK是可调的:
块级归约
在AMD平台上,计算是基于「1 warp加载/1warp计算」的方式进行的,而在NVIDIA平台上则是「2warps加载和1warp计算」。
该设计充分利用了AMD CDNA3架构中64个SIMD通道的优势。并且,在这种多芯片架构中,块的数量始终是XCD数量的倍数。
FRAGS_PER_BLOCK被设置为4,以便在多轮中复用SMEM。
研究人员改进了向量化代码,并处理了如果输入数据大小与kElementsPerAccess常量不对齐时的循环尾部情况。
基准测试显示,合并率有所提高,但仍然限制在30%左右。研究人员将在V4版本中继续优化此问题。
编写PyTorch扩展可以自动将CUDA设备代码转换为HIP设备代码,配合ROCm SDK进行使用。
但是,有些情况下HIP设备代码与CUDA设备代码表现不同:
在没有CUDA图捕获的情况下,研究人员针对DeepSeek V3模型的大规模工作负载进行了广泛测试。因此,专家数量设置为256。当前的算法不支持在CUDA图捕获下运行,将在V4版本中解决此问题。
由于GPU虚拟化和测试节点上分配的CPU数量,性能可能会与裸机测试时有所不同。
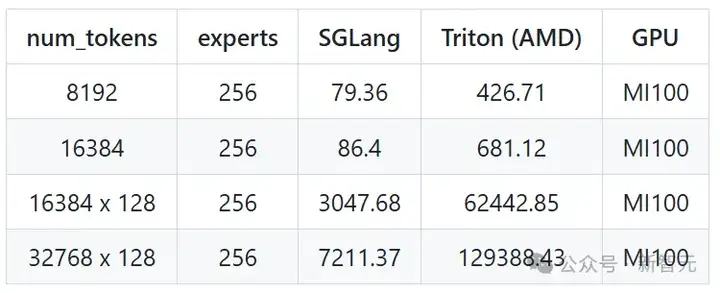
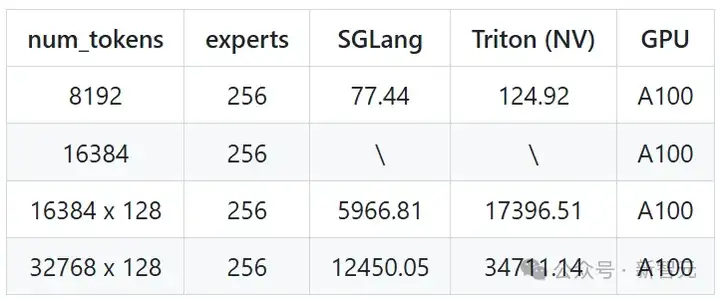
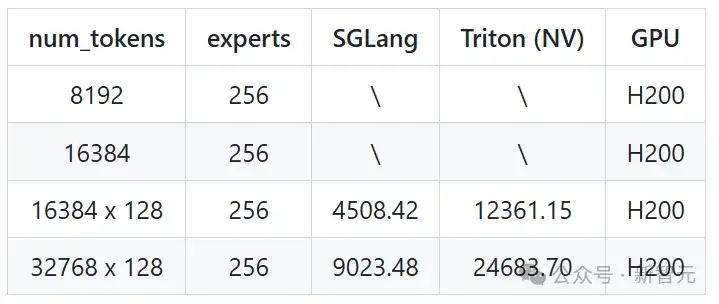
因此,研究人员使用Triton实现作为基准,展示MoE Align & Sort算法在加速倍数和效率上的表现。
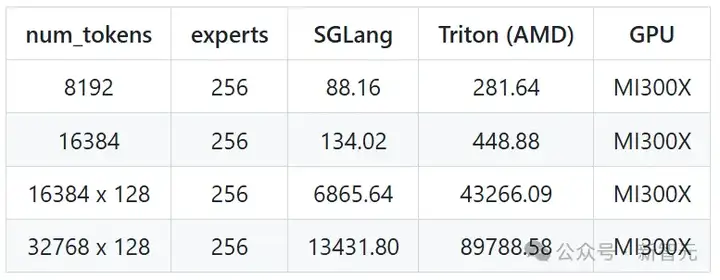
每个测试首先进行了验证,之后才开始基准测试。在基准测试中,可以观察到,在AMD平台上,Triton的运行时间显著长于在NVIDIA平台上的运行时间,因此建议进一步优化Triton的MLIR,以获得比NVIDIA Triton更高效的降级过程。
对于AMD Triton,可以观察到MI300X的速度比MI100快1.5倍,因此MI300X的性能提升幅度不像MI100那么显著。此外,尽管普遍认为MI300X比MI100更快,但在测试中,MI100上的算法性能要优于MI300X。
这部分归因于内存瓶颈操作,在多芯片之间的通信降低了执行速度。
在两个平台上,都观察到了应用该算法后显著的性能改进,其中现有的CUDA实现几乎与Triton消耗相同的时间。
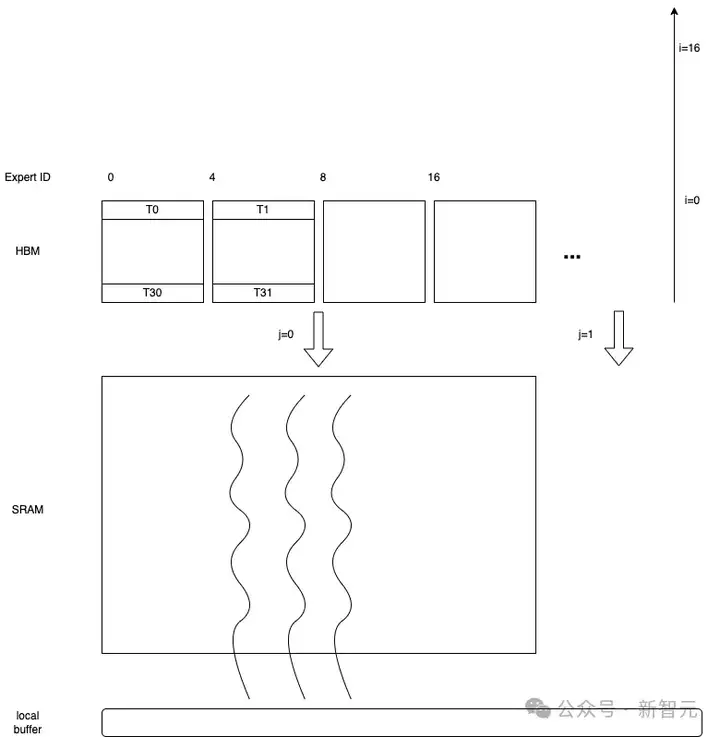
为了最大化使用AMD异构系统,建议进行以下检查。
git clone
https://github.com/yiakwy-xpu-ml-framework-team/AMD-sglang-benchmark-fork.git
-b optimize_moe_align_v3 && cd sgl-kernel && python setup_rocm.py install
可以验证不同输入令牌和专家数量组合的可行性 :
cd ../benchmark/kernels/fused_moe_trition && python benchmark_deepseekv3_moe_align_blocks.py --verify
在ROCm 6.3.3版本中,设置rocprof-compute只需三步即可完成,详细的设置步骤可以在这里找到:Tools-dockerhub中的rocprof-compute设置。
在分析中,工作负载为16384个tokens x(从256个专家中选择8个),除非另有说明。
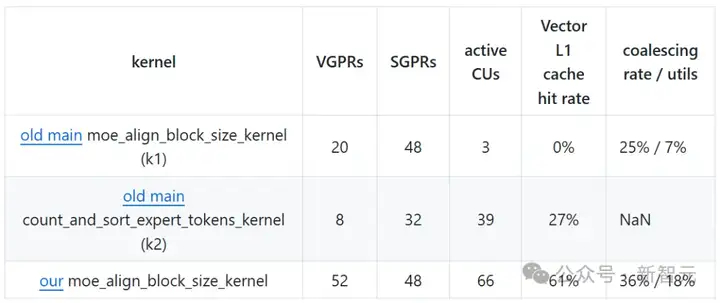
研究人员在算法中最大化了VGPRs的使用,但减少了SGPRs的总使用量。数据也表明,VGPRs/SGPRs的溢出为零,这表明寄存器的使用是健康的,并且此设备代码没有性能损失。
向量L1缓存(vL1D)是每个CU的本地单元,命中率记录了从L2缓存请求到CU时的缓存行命中率。30%的L2缓存请求通过vL1D的纹理寻址器合并,达到了61%的命中率,如果需要,稍后可以进一步提升。
当数据从CU请求到vL1D的寻址处理单元(纹理寻址器)时,复杂的决策逻辑决定是否接受数据请求或回滚数据请求。以下是四种状态:
有关这种微架构行为的详细信息,可以在AMD CDNA3的ISA文档以及rocProfiler-compute文档中找到。
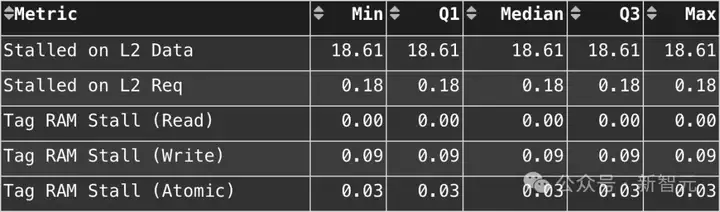
vL1D 寻址器停顿
研究人员在该算法设计中观察到了18.61%的数据等待停顿率来自于向量L1缓存。
数据的读写负载平衡大大减少,从8kB的读取操作和27B的写入操作,转变为109B的读取操作,468B的写入操作和202B的原子操作的组合。
在CDNA3架构中,L2缓存是所有计算单元(CU)共享的,且是线程块之间共享数据的主要通道,这些线程块分布在不同的CUs上。
通过多通道和地址交错设计,向L2缓存的请求可以大大并行处理。
此外,使用AMD特有的内置函数如__builtin_nontemporal_load,可以绕过L2缓存来处理那些不需要再次访问的数据。
更多L2缓存研究细节将在V4版本中揭示。
新的算法通过最大化使用LDS和向量寄存器,显著加速了CUDA和ROCm平台上的MoE Align & Sort,提升幅度高达3x~7x。
还可以观察到,相较于单个芯片,内存密集型操作在多晶粒异构集成架构下可能表现更差,这表明在多芯片如MI300X/MI300A和B200/B300设备上编程时,可能需要新的微调方向。
然而,该算法的细节仍有进一步优化空间,以提高缓存命中率和主内存合并率。
特别感谢来自NUS团队的覃含章教授,王昀鸿博士在MI100/MI250性能验证中的合作,Zev Rekhter在MI300X性能验证中的合作,范舒宜在H200验证中的合作,以及BBuf在SGLang解决方案的讨论和审阅。
请注意,这是SGLang社区的独立工作。
本文作者王翼之前在Graphcore担任机器学习专家,后加入美国知名半导体公司担任AI架构师(SMTS主任工程师)。
参与贡献诸多机器学习社区开源软件,主要研究兴趣在LLM训练、推理的软件栈优化,并应用计算机体系结构知识协同设计软硬件解决方案。
参考资料:
[1]W. Fedus, B. Zoph, and N. Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. CoRR, abs/2101.03961, 2021. URL https://arxiv.org/abs/2101.03961.
[2]A. Q. Jiang, A. Sablayrolles, A. Mensch, C. Bamford, D. S. Chaplot, D. d. l. Casas, F. Bressand, G. Lengyel, G. Lample, L. Saulnier, et al. Mistral 7b. arXiv preprint arXiv:2310.06825, 2023.
[3]DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model. CoRR, abs/2405.04434, 2024c. URL https://doi.org/10.48550/arXiv.2405.04434.
[4]DeepSeek V3 : https://arxiv.org/abs/2412.19437; Retrieved on 2025-03-18
[5]DeepSeek R1 : https://arxiv.org/pdf/2501.12948; Retrieved on 2025-03-18
[6]TransformerEngine : https://github.com/NVIDIA/TransformerEngine; Retrieved on 2025-03-18
[7]NV Group GEMM : https://github.com/yiakwy-xpu-ml-framework-team/NV_grouped_gemm; Retrieved on 2025-03-18
[8]FasterTransformer : https://github.com/NVIDIA/FasterTransformer; Retrieved on 2025-03-18
[9]CK Fused MoE V1 : ROCm/composable_kernel#1634
[10]AMD 3X MOE : https://rocm.blogs.amd.com/artificial-intelligence/DeepSeekR1-Part2/README.html
[11]Lean Wang and Huazuo Gao and Chenggang Zhao and Xu Sun and Damai Dai Auxiliary-Loss-Free Load Balancing Strategy for Mixture-of-Experts, 2024. URL https://arxiv.org/abs/2408.15664.
[12]PopART on chip TensorRemap : https://github.com/graphcore/popart/tree/sdk-release-3.4
[13] DeepSeek V3 Optimization based on AITER backend : sgl-project/sglang#4344
原文地址:
Github(https://shorturl.at/bEEn9),Hugging Face(https://shorturl.at/PMH3F)
文章来自于“新智元”,作者“LRST”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
