# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
港中文和清华团队推出Video-R1模型,首次将强化学习的R1范式应用于视频推理领域。通过升级的T-GRPO算法和混合图像视频数据集,Video-R1在视频空间推理测试中超越了GPT-4o,展现了强大的推理能力,并且全部代码和数据集均已开源。
语言模型的推理刚火完,视频AI也开始「卷」起来了。
这次出手的是港中文+清华组合,直接把强化学习里的R1玩法搬到了视频领域,整出了全球首个视频版R1模型:Video-R1。
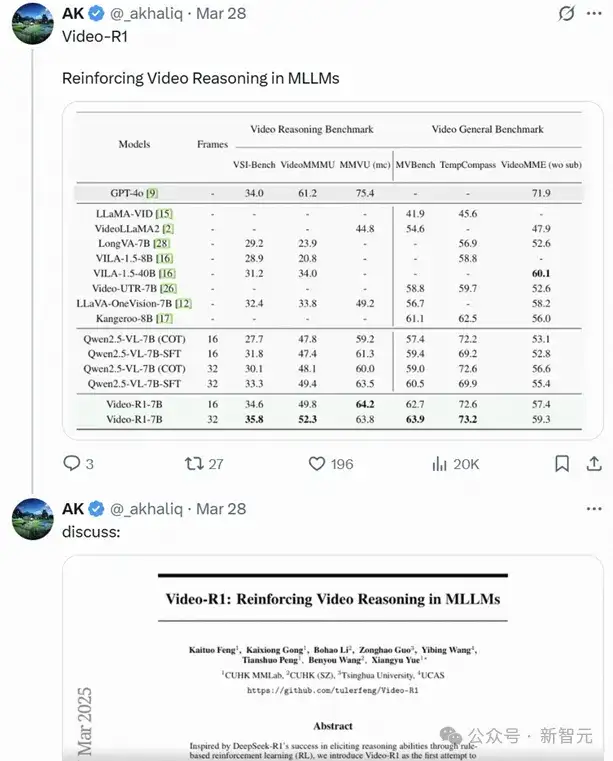
别看它只有7B参数,但它在李飞飞提出的VSI-Bench基准中,竟然超越了GPT-4o!
这波不是简单微调。它背后换上了全新的时间感知算法T-GRPO,再配上图像+视频混合训练、两套高质量数据集,硬是把AI的视频推理能力拉满,让模型不止能「看」,更开始「思考」。
而且,全套模型、代码、数据集——已经开源了!
视频大模型的「推理时刻」,已经开始。

论文链接:https://arxiv.org/abs/2503.21776
项目地址:https://github.com/tulerfeng/Video-R1
知名博主AK也连发2条推特,推荐这篇论文:
视频模型看起来「懂点东西」,其实大多都只是表面功夫。真正让它们「动脑子」的地方,反而是它们最弱的短板。
研究团队指出,如果还按照传统GRPO的套路来训练AI看视频,会踩两个坑:
一个是没时间概念,模型完全不知道视频事件的前后逻辑,常常「看图说话」——看到一帧画面就急着给出答案。这种套路最多就是蒙对几次,没法形成真正的因果推理,泛化性差。例如下图所示。

另一个问题更棘手:训练数据太浅。很多现有视频数据集压根就不适合教模型「思考」,清一色的识别题,几乎没多少需要推理才能解的任务。模型怎么练都只是在死记硬背,根本没机会练大脑。
所以,视频大模型「不聪明」,真不是没潜力,而是没人教对方法。
研究团队整了个狠招:奖励机制绑定时间理解。
研究人员把旧版GRPO算法升级成了更懂时序的T-GRPO,直接把「考虑时序」这事写进了模型的奖励逻辑里。
方法简单粗暴又高效——模型每次会收到两组输入:一组视频帧随机乱序,一组顺序。只有当它在「顺序」输入上答对题的比例更高,才会获得奖励。
这个机制在「教」模型:别光看图,推理得讲前因后果。哪怕只看了一帧猜对了题,也拿不到分。
在这种严格打分机制下,模型终于明白——视频不是PPT翻页,而是一个个逻辑线索串起来的故事。
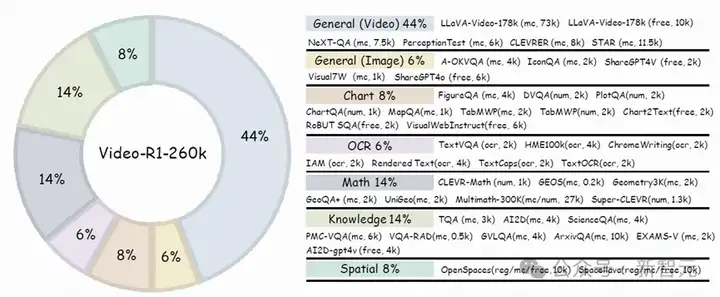
视频推理数据太稀缺,模型「练不成」?
研究人员干脆把图像推理数据请进视频训练流程,做了两个关键数据集:一个是图像为主的 Video-R1-COT-165k,专门用来冷启动模型思维;另一个是以高质量视频为核心的 Video-R1-260k,用来精调强化训练。
别以为图片只是打辅助,恰恰相反——它帮AI打好了「逻辑底盘」,学会怎么通用推理;而那些优选过的视频数据,则进一步逼它理解时间逻辑和动态变化。
这套图像+视频混合训练方式,不光解决了数据稀缺,还真让模型形成了从「看图说话」到「视频深思」的进阶跳跃,真正打通了多模态理解的任督二脉。
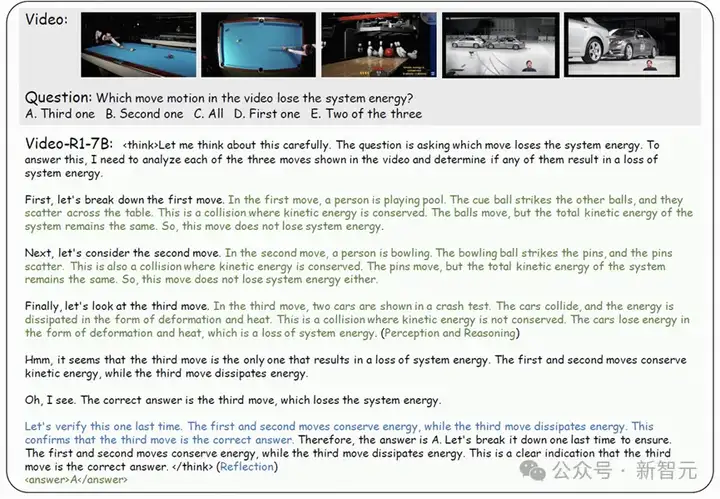
Video-R1在推理过程中,竟然出现了类似人类的「顿悟时刻」——那种突然把所有线索串起来、恍然大悟的瞬间,也被称为「aha moment」。
比如有一道题是:哪个动作会导致系统能量损耗?另一个是:看完一段室内漫游视频,推理出从书柜走到浴缸的路径。
换做以前的模型,十有八九就是「看一眼」就开答,但Video-R1却能一步步分析时序,进行推理,最终给出逻辑闭环的准确回答。
这不是死记硬背,而是推理真正生效的信号。AI第一次表现出:它不只是识图,而是在「思考」视频里发生了什么。

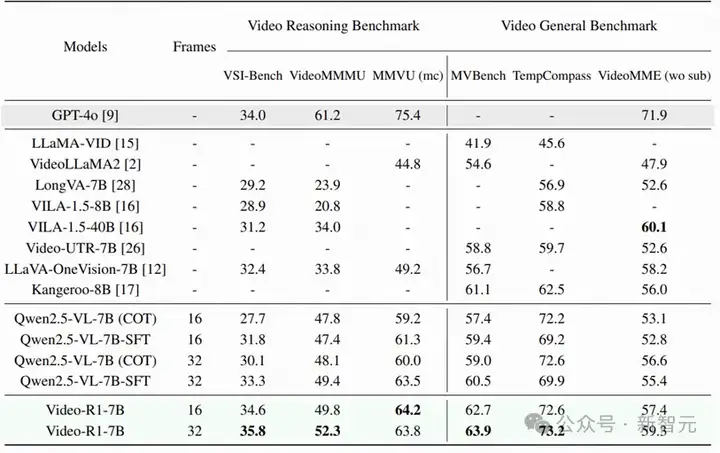
在多个视频推理测试基准上,这个Video-R1-7B模型几乎场场领先,尤其在李飞飞提出的VSI-Bench这一权威评测中,它拿下了35.8%的准确率,超越了闭源顶尖大模型GPT-4o。
不仅如此,RL和传统SFT之间的差距也被拉开了。比如同样是7B体量的Qwen2.5-VL-SFT,在测试中表现不佳。反观Video-R1,则在几乎所有场景中都稳定输出,泛化能力一骑绝尘。
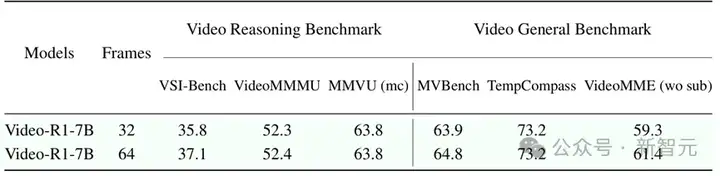
还有一个非常关键的发现:帧数越多,推理越准。当模型输入的视频帧数从16增加到32,再到64,测试表现都跟着上台阶。这说明,对时间线的理解力,正是视频推理模型的决胜点——谁能处理更长的视频,谁就更有未来。
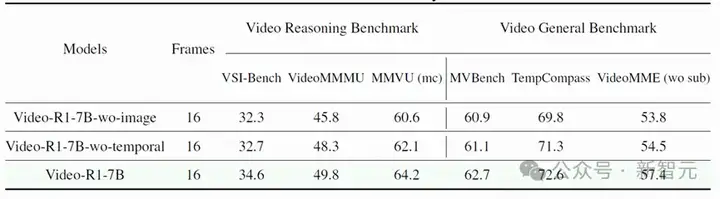
团队还做了一组消融实验,直接「抽掉」图像数据训练、再试试砍掉时间建模模块,结果都一样——模型性能明显下滑。这直接验证了一件事:Video-R1的每一块设计都打在了点子上。
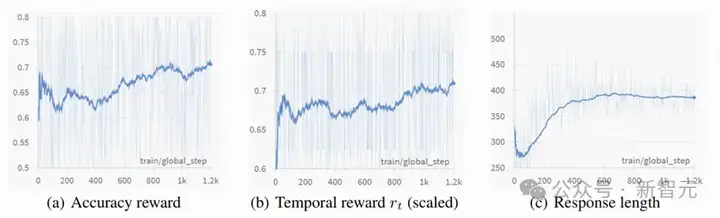
不仅如此,从训练动态中也能看出门道。随着强化学习的推进,模型获得的准确率奖励和时间奖励在持续上升,说明它不仅越来越会答题,还越来越懂得「时间逻辑」这回事。
有意思的是,模型在训练早期输出的回答变短了——这是在主动抛弃之前SFT里学到的次优推理模式;但随着训练推进,输出逐渐恢复并稳定,形成了一套更高效、更具逻辑的表达路径。
Video-R1用实力证明:强化学习不只是NLP的专利,视频大模型也能玩出推理力。
它不靠「堆料」,靠的是机制设计和训练策略,并且全套开源。
R1的推理范式,正在把下一场AI革命,从文本世界带进了每一帧画面里。
视频推理的时代,真的来了。
参考资料:
https://arxiv.org/abs/2503.21776
文章来自于“新智元”,作者“LRST 好困”。



【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
