# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
Transformer架构主导着生成式AI浪潮的当下,但它并非十全十美,也并非没有改写者。
MiniMax-01就以变革者之姿搅动开源社区,押注线性注意力机制并将其扩展到前所未有的4560亿参数规模。
这是一场技术冒险,也可能是架构创新的下一个里程碑。

△ MiniMax-01技术文档
本期「大模型创新架构」主题访谈,量子位邀请到MiniMax-01架构负责人钟怡然,
聊聊线性注意力从实验室走向工业级大模型的全过程,以及他对模型架构的思考和洞藏。
以下为量子位与MiniMax钟怡然的对话实录整理:
量子位:能否先简单介绍一下自己?
MiniMax钟怡然:我是钟怡然,现在是MiniMax的高级研究总监,主要负责网络架构的设计和多模态理解大模型。
在MiniMax主要工作是主导设计MiniMax-01的网络结构。
之前我在上海人工智能实验室担任青年科学家新架构探索组的PI,负责非transformer架构的高效训练建模方法,以及视听语言多模态融合的研究。
量子位:你是什么时候开始研究线性attention的?为什么选择这条技术路线?
MiniMax钟怡然:最早是在2021年7月份开始研究线性attention。
这其实源于我2020年博士毕业时做的一篇论文《invertible attention》,当时可逆神经网络和attention机制都比较火,我们就把两者结合起来研究。

△《invertible attention》论文
后来,我们团队中有成员对数学很感兴趣,而linear attention这样的高效序列建模方法对数学要求较高,需要很多公式推导,
正好契合了团队的兴趣,所以我们选择了这个方向。
量子位:当时linear attention在行业内是什么状态?
MiniMax钟怡然:当时它是非常非主流的,做的人很少,因为那时大部分研究者都在做transformer。transformer在NLP领域基本上已经有大一统的趋势。
我们当时想着,与其继续做transformer泯然众人,不如做something different。
量子位:你如何判断linear attention路线的技术潜力?
MiniMax钟怡然:我们的初衷很直接——解决transformer二次计算复杂度的问题。当时我们也测试了很多方法,包括sparse transformer和linear attention。
结果发现sparse transformer确实能work,显存和速度都比transformer快,而linear attention效果不好,速度也很慢。但我们仍选择了linear attention。
一方面是因为它在数学上很有意思,我们认为它的效果不应该这么差;
另一方面,我们认为sparse attention的上限就是full attention,它很难超越,而linear attention还有超越的可能性。
量子位:能否介绍一下什么是线性attention?
MiniMax钟怡然:线性attention本质上是一个kernel trick。
在transformer中,Q、K、V三个矩阵相乘时,因为维度不同,先乘QK还是先乘KV会导致计算复杂度不同。
先乘KV可以把计算复杂度变成线性,但问题是QK相乘后会经过softmax,而softmax不满足交换律,无法简单地拆分成先乘KV。
所以linear attention的第一步就是要去掉softmax。
但去掉softmax会影响结果,接下来的任务就是在去掉softmax的情况下,让结果保持一致性,这就是linear attention要做的事情。
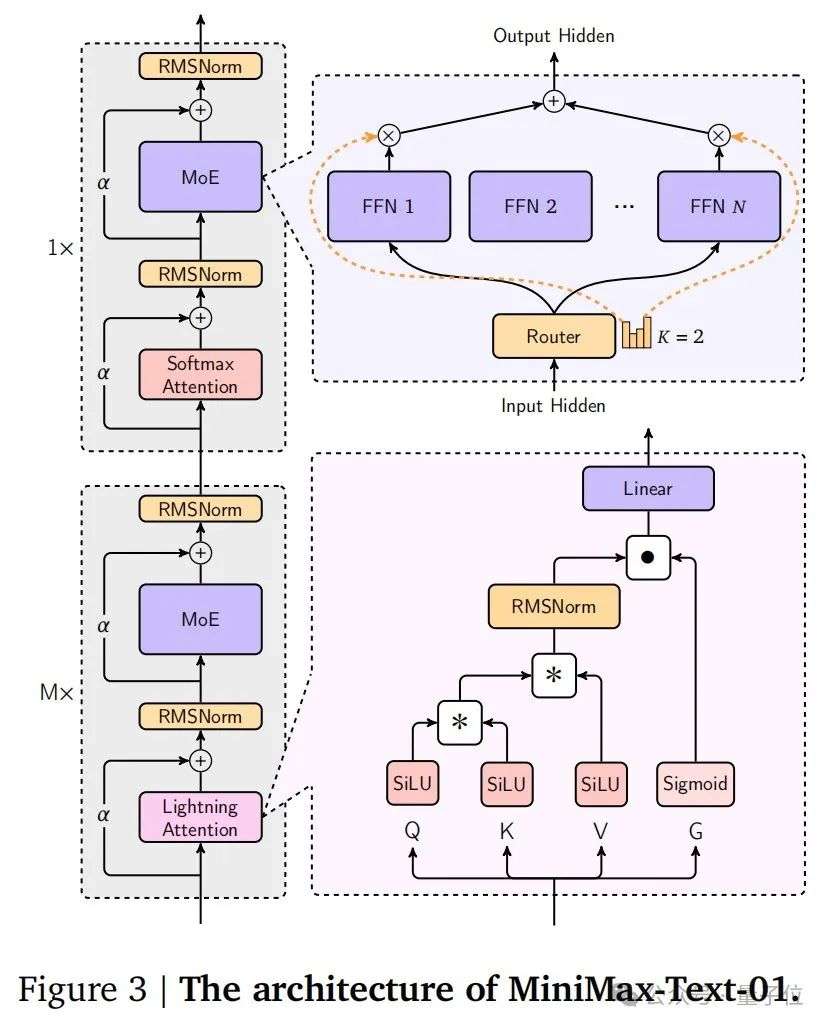
△MiniMax-Text-01架构示意
量子位:线性注意力与稀疏attention、线性RNN架构有什么本质区别?
MiniMax钟怡然:稀疏attention本质上仍是一个softmax attention,只是它计算的点比dense attention矩阵要少,
比如sliding window attention只计算窗口内的attention score,通过少算来达到加速目的。
而linear RNN和linear attention本质上是一个东西,只是有些人把它叫RNN,有些人把它叫attention。
因为所有东西都可以写成RNN形式。比如lightning attention对应rwkv4,而rwkv-7其实是改进版的gated delta net,它们虽然本质相似,但实现细节不同。

△《RWKV-7 “Goose” with Expressive Dynamic State Evolution》论文
量子位:对线性注意力机制的研究有哪些关键节点?
MiniMax钟怡然:最早大概在2018-19年,有研究发现可以通过kernel trick降低transformer softmax attention的理论计算复杂度,但当时效果不好,效率也低。
2019-20年,主流还是sparse attention,谷歌等公司提出了很多sparse attention变种。之后linear attention才开始出现,但面临效果不好、速度不快的局面。
研究人员主要采取两条路线改进:一是通过对softmax函数的逼近,让分布符合softmax;
二是我们选择的路线,不再关心怎么逼近softmax,而是用完全不同的方法建模。
我们在2021年10月发表了第一篇论文《COSFORMER : RETHINKING SOFTMAX IN ATTENTION》,用cos函数取代了softmax操作,让计算可以拆分。
2022年上半年,我们发表了第二篇《The Devil in linear transformer》,分析了linear attention效果变差的原因并给出解决方案,这是lightning attention的前身。

△《The Devil in linear transformer》论文
后来我们还研究了专门为linear attention服务的位置编码,以及长卷积,发表了TNN,
《TOEPLITZ NEURAL NETWORK FOR SEQUENCE MODELING》,这是与S4(mamba的前身)类似的方法。
最后我们推出了lightning attention,通过改进decay方式和网络结构,效果上match了transformer,并通过分块算法(tiling technique)使速度更快。
量子位:怎么看待目前非transformer架构的技术路线?
**钟怡然:linear attention其实就是非transformer的方法。非transformer架构现在除了类RNN的路线,其他路线都式微了。
比如CNN像那个长卷积、大核卷积,效果不好逐渐就被淘汰了的感觉,不过在某些方面其实还蛮强,在序列建模,比如说异常检测任务上面还是有一定效果的。
非transformer架构其实就三个,一个是linear attention,一个是长卷积,一个是linear RNN。
但实际上这三个都可以统一成一个,我们把它叫做linear complexity model**。我们写了一篇文章把这三个事情都囊括在一起了。
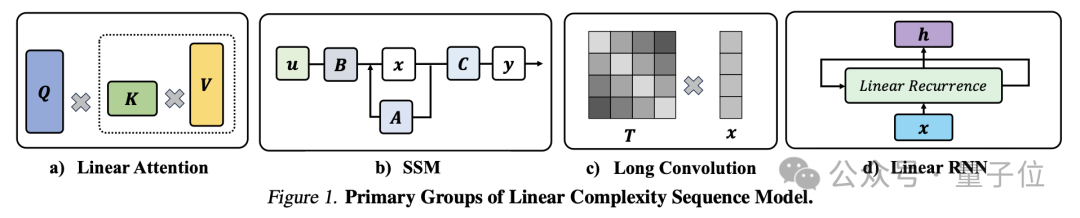
△《Unlocking the Secrets of linear Complexity Sequence Model from A Unified Perspective》论文
量子位:lightning attention与Mamba、RWKV的核心区别是什么?
MiniMax钟怡然:最核心的区别是lightning attention是最简单的linear attention。
Mamba和RWKV都使用data dependent decay,而lightning attention为了速度,使用的是handcraft decay,即人为指定的decay。
虽然可学习的decay效果会更好一些,但会牺牲速度。比如RWKV-7比gating delta net慢10-15%,而gated delta net速度又比lightning attention慢一半左右。
RWKV的建模效果确实比lightning attention好,但速度慢,且仍未解决retrieval问题。
量子位:线性注意力的上限高且可行,现在是行业共识了吗?
MiniMax钟怡然:不是,如果是共识的话,大家都会去scale up linear attention模型了。
而且去现在也不是共识,如果现在是共识,大家也会全部做linear,但可以看到并没有。
但对我们来说,在23年下半年的时候就已经看到了这一点。
当时我问了很多人,跟很多人聊过,他们最常提出的点是他们知道linear attention在小规模上确实work,但觉得一旦scale up上去就会不行。
我当时就想那我就把它scale上去给大家看看。现在minimax-01出来之后,就没人怀疑linear attention在大规模下的能力了。
量子位:你认为linear attention的上限能超越full attention吗?
MiniMax钟怡然:我们现在可以看到hybrid架构比纯transformer要好。但纯linear attention的最大问题是retrieval能力,这是学术界目前难以解决的问题。
现有方法虽然复杂,速度也慢,仍然无法完全解决,这也是为什么必须走向hybrid架构的原因。
量子位:当时决定从实验室出来是因为观察到了什么样的节点?
MiniMax钟怡然:在2023年5-6月份,我们内部已经有lightning attention 2,这是当时世界上第一个速度比Flash attention还快的linear attention实现。
我们认为它已经越过了工业红线,技术成熟度非常高,可以scale up了。
量子位:如何定义这个工业红线?
MiniMax钟怡然:首先效果上比transformer好,其次比transformer快。这样它就具备取代transformer的能力了。
我们当时在15B规模的dense model上验证了这一点。
量子位:当时从实验室出来的节点上,为什么最终和MiniMax走到了一起?
MiniMax钟怡然:当时其实和一些大厂都有聊过。但最后还是和MiniMax把这个事做成了。
首先cosformer是我跟俊杰合作的文章,我们之间有合作的基础,俊杰之前在商汤的时候就是我老板。
23年底的时候俊杰就约我吃饭,他是比较相信技术的这些前沿的可能性。我的理解是他当时也在找技术突破的点。
当时MiniMax已经完成了对Moe的研究,下一步的技术突破点其实很少了。当时lightning attention已经发了,mamba也火了,所以在他眼里是一个可行的方向。
量子位:这和MiniMax做互动陪伴产品有关系吗?
MiniMax钟怡然:没有什么关联,闫俊杰更关心的是模型的上限,怎么能够进一步突破这个天花板。
量子位:linear attention在大众视野里可能更多是一个突破效率的方向,而不是突破天花板。
MiniMax钟怡然:这里面的点是在于,首先每个厂商的算力是恒定的,能把模型加速得越快,能吃的数据就越多,产出的模型就越好。
在算力恒定的情况下,就是模型越快越好。
量子位:现在有观察到数据见顶的情况吗?
MiniMax钟怡然:现在还没有吧。数据还是在一直scale的阶段,但可能不会像23年那么激进。
因为数据永远在增加,每天都会有新的数据出来,对于模型来说,它每天都有新数据去处理。
互联网每天生产的数据就是有那么多,通过清洗,我们仍然能得到新的数据出来。
量子位:相比于人类发展这么多年已经存在的数据来说,数据增速放缓了吗?
MiniMax钟怡然:其实不一定,你看中国上下五千年积攒出来的也就那几本书。
但随着互联网的发展,数据量的增长是非常陡峭的一个曲线,可能互联网之前产生的整体数据,比不上之后一年产生的数据。
量子位:在scale up过程中,lightning attention面临了哪些挑战?
MiniMax钟怡然:为了验证它的可扩展性,我们首先做了scaling law实验,从小模型逐步扩展到7B、9B,最后scale到400多B的模型。
而且我们从理论上证明了linear的容量比transformer大。
我们把容量定义为RNN的current states大小。对transformer来说,容量大小是O(d),d是size;
对linear attention来说,容量大小是d²/h,由于d远大于h,所以容量更大。
最终实现上我们也验证了hybrid模型比纯transformer效果更好。
量子位:4M长度的序列窗口是如何实现的?
MiniMax钟怡然:对lightning来说,训练长度可以是任意的。只要算力打满,训练8K、32K或128K的速度是一样的,TGS(token per GPU per second)是相同的。
而transformer因为是n²的计算复杂度,sequence越长,计算复杂度增长太快,latency呈二次曲线上升。
在1M长度时,softmax attention的latency是lightning attention的2,700倍。
量子位:后续做到无限上下文窗口还有哪些技术挑战需要应对?
MiniMax钟怡然:我们现在的hybrid架构中还有1/8的softmax attention,在1M长度下这是瓶颈,这1/8带来的latency远高于剩下7/8的linear attention。
如果要进行长文本优化,肯定要考虑优化softmax attention部分,可以借鉴稀疏注意力方式,让它更快、更轻。
另外,我们也考虑让softmax和linear attention的混合比例更极端,不再是1/8,可能是1/16或1/32。
最激进的方案是整个模型只放一层softmax,但为了保险我们没有采用,主要考虑是对retrieval能力的影响。
量子位:为什么retrieval能力对模型如此重要?
MiniMax钟怡然:**retrieval是in-context learning的基础,是必要条件**。
你必须记住上下文中的信息才能做in-context learning,而in-context learning是现在所有大模型高阶能力的基础,
比如CoT(Chain of Thought),特别是long CoT,它们都依赖retrieval能力。
量子位:你有关注到行业内,对FFN和attention最新的架构改进吗?
MiniMax钟怡然:FFN的改进就是Moe,我也关注了字节的Ultra Mem,但我觉得它是一个有损的东西,是有损的压缩,
未来它scale up上去可能会有问题,不过我们没有scale up,我只能说它可能会有问题。

△《Unlocking the Secrets of linear Complexity Sequence Model from A Unified Perspective》论文
因为FFN基本上就是这些。Moe这块我们的改进无外乎从之前的大专家改成现在的小专家模式,让它变得更加稀疏,然后再往下做一些加速,还需要进一步研究。
再对它进行优化的话,因为FFN就是矩阵乘法了,优化就只能像Nvidia他们在CUDA层面上做一些矩阵乘法的最底层优化。
量子位:有关注到行业内对attention架构方面的改进吗?
MiniMax钟怡然:attention上的改进基本上就是linear。
我们也在考虑未来会不会做一个更强的Linear,在目前基础上,把Linear attention做进一步加速
改进方向有很多种方案,一个是改decay,还有就是改里面的一些小trick,具体可以期待我们的新paper。
量子位:咱们目前的上下文长度和推理成本的这个比率算是比较先进吗?
MiniMax钟怡然:**一旦牵涉到把sequence length拉长的话,我们是有很明显的算力成本优势**,越长,成本优势会越明显,无论是推理还是训练。
比如说在1M上,linear attention所消耗的算力是full attention的1/2700。
相比之下,因为我们仍然有1/8的full attention,那基本上就是它就是transformer架构的1/8,因为linear attention基本上不算开销了,基本没有开销。
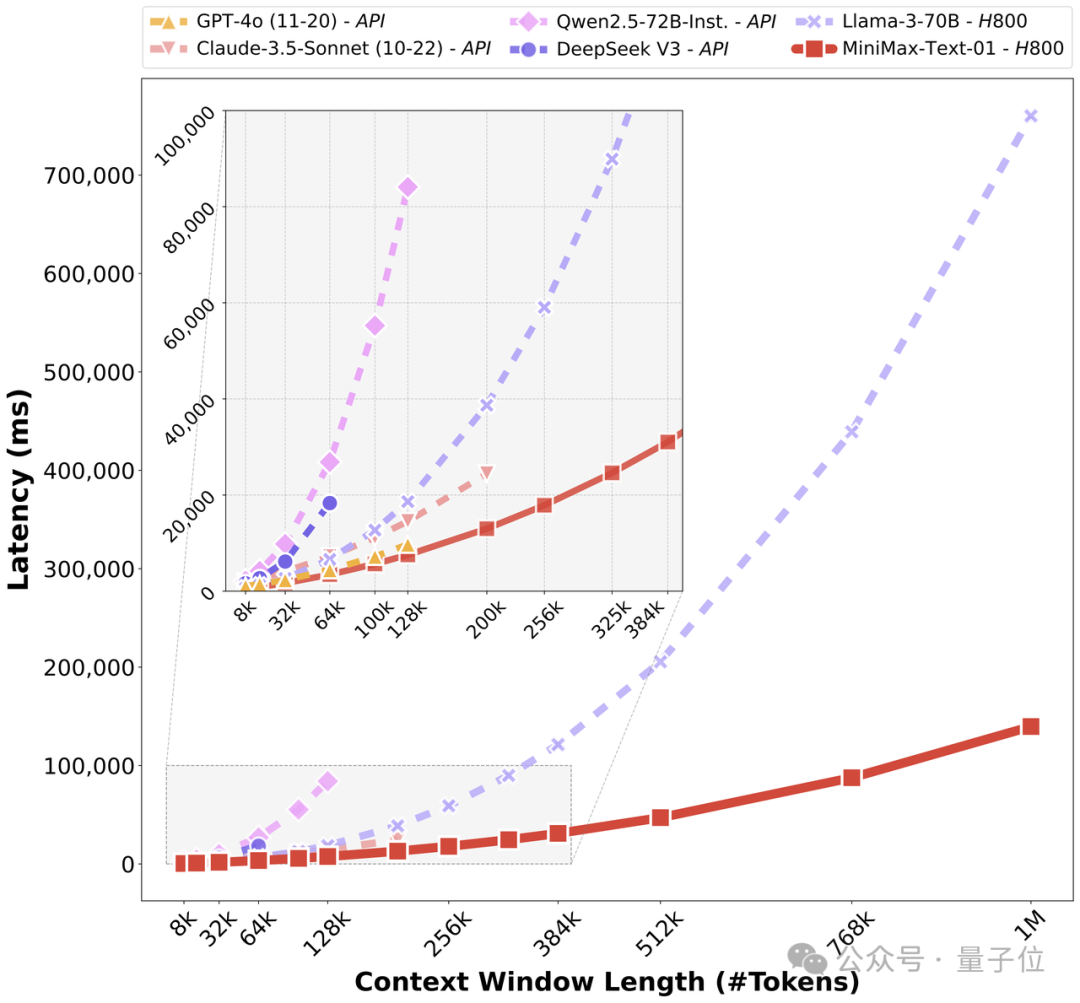
△linear attention处理长输入效率和全球顶尖模型对比
量子位:计算开销这么低的话能实现计算瓶颈吗?
MiniMax钟怡然:现在确实是访存瓶颈,decoding的时候是访存瓶颈,而不是计算瓶颈。
因为lightning很快,实在太快了,没有办法让访存也像计算占用一样少的资源。主要是因为实际应用中的序列长度都不够长。
未来如何让它成为计算瓶颈,那就是看怎么样去优化访存了。这些会是工程那边需要负责的事情。
量子位:如果线性注意力成为下一代主流架构了,什么样的硬件适配改进会更适合它呢?
MiniMax钟怡然:这里面非常tricky的一件事情就是,我们需要考虑的是序列长度。
如果你的序列长度关注于8K、32K,那么attention总共也就占比百分之十几,剩下的百分之八十几都是后面的FFN部分。
即使你把attention全部优化到极致,到了0,你也只优化了百分之十几的时延。
但如果把序列长度拉长的话,attention的占比就会越来越大,这是相比于full attention来说,但对linear attention来说,它的占比是不变的。
因为FFN也是线性的,linear attention也是线性的,它的占比大概是10%左右,这个是几乎不变的,即使在1M情况下它也是百分之十几的占比。
但如果是full attention的话,attention计算可能就占了百分之99,后面的FFN只占了百分之1了。所以linear attention只会在长文上有优势。
如果线性架构成为主流的话,后面可能就是追求低能耗的硬件,只能把能耗降低。
包括脉冲神经网络芯片(Spiking Neural Network, SNN)可能会更适合,其实也有人在做。
△脉冲神经网络芯片示意
量子位:对模型开源效果有哪些期待呢?
MiniMax钟怡然:首先是宣传上的效果。
我个人觉得开源除了展示一些肌肉以外,最重要的还是看大家后续怎么能够用起来,我觉得小模型开源可能是未来我们比较考虑做的。
还有怎么让大家能够finetune的一些基建做起来,可能也是需要考虑的。开源是我们以后长期的事情,之后旗舰模型应该会持续开源。
量子位:未来非hybrid的某个纯血架构有跑出来的可能吗?
MiniMax钟怡然:目前没有方法能比hybrid做得更好,特别是在速度方面。
加入一小部分softmax attention,在序列长度不是特别长的情况下,速度优势非常明显,特别是flash attention出现后。
纯血架构的研究仍在进行,但难度很大,已经没有低垂的果实了。我们有一些技术方案,但实现都不简单,最终取决于我们需要做到多长的序列长度。
另一个问题是,超长文本是否有强烈的刚需?虽然像Claude等模型已达到200K上下文,但用户似乎对当前已有长度也很满意。
未来agent应用可能会带来对超长序列的需求,但目前还没有成熟的benchmark。
但我觉得这个问题就像Nvidia会为未来的游戏开发超前性能的显卡一样,虽然现在还用不上,但这是面向未来的技术。
比如deep research需要模型读取几十个网站的内容,处理时间在几十分钟级别,这可能是长文本的一个应用方向。
量子位:你觉得CoT之后的下一个大事情可能会是什么呢?
MiniMax钟怡然:这个我们想过,首先现在的reasoning model是比较火的,今年的主流还会是reasoning这一块。
之后的话,我们很难想到纯语言模型未来还有什么特别大的变革。
我也跟别的老师聊过,他们的感觉是大家会去重新减少模型开销,就让reasoning的速度越来越快,让它的价格变得越来越低,在维持效果的情况下把成本往下压。
因为天花板很快就接近了,现在绝大多数的情况都是在对大模型能力进行查漏补缺。但如果说还有更大的技术突破,短期内可能比较少见,我们还没看到。
量子位:MiniMax在探索了线性注意力之后,下一个可能探索的方向是什么呢?
MiniMax钟怡然:下一个可能是去探索多模态的架构,具体指的是我们要不要做这种原生的生成理解统一大模型的架构。
量子位:以AGI为终点,计算复杂度O(n²)还是O(n)的模型会是更好的答案?
MiniMax钟怡然:那当然是O(n)了。从拟人化来说,人肯定是O(n)复杂度的。就比如说打个比方,如果人的复杂度是O(n²),那么我跟你说话的速度会变得越来越慢。
因为对transformer来说,它的inference的complexity是O(n²)的计算复杂度,也就是我吐第一个token和吐第100个token的时延是不一样的。
我们人类无法想象这样的事情,因为人从降生下来之后总没有重启过,是一直在吐东西的,所以人的计算复杂度就是恒定的。
量子位:人一定是智能的最优解吗?
MiniMax钟怡然:我们目前只能这么想,还有一些人做仿生智能的路线,我们没有太关注那些方向。
量子位:以AGI为终局的话,模型哪些方向的改进是最重要的事情?
MiniMax钟怡然:除了语言建模以外,还有一个就是学习方式的问题。
你怎样去学习,以及从环境当中学习,与环境的交互当中学习很重要,毕竟现在的多模态理解还是非常的缺数据。
而且机器即使是few-shot的学习目前也都是带标注的,但人的学习是不带标注的。那么怎么把所有的东西统一在一个自建构的框架下面,也是一个问题。
代码:https://github.com/MiniMax-AI/MiniMax-01
模型:https://huggingface.co/MiniMaxAI/MiniMax-Text-01, https://huggingface.co/MiniMaxAI/MiniMax-VL-01
技术报告:https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf
文章来自于微信公众号“量子位”,作者 :量子位




【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
