Step 3.7 Flash、DeepSeek、MiniMax、Gemini、GPT 的 Agent 评测,谁更适合Agent?
Step 3.7 Flash、DeepSeek、MiniMax、Gemini、GPT 的 Agent 评测,谁更适合Agent?最近这段时间,国内外模型更新得很快。
来自主题: AI产品测评
8640 点击 2026-07-03 09:48
 搜索
搜索
最近这段时间,国内外模型更新得很快。

Kimi、智谱和 MiniMax 幕后的 “财务管家”Airwallex 空中云汇,正尝试回答 “AI 时代钱如何在全球丝滑流动” 这一难题。近期,Airwallex 完成 3.2 亿美元 H 轮融资,成为估值 110 亿美元超级独角兽。本轮融资由 Addition 领投,Baillie Gifford、 Amex Ventures 等几家欧美资本跟投
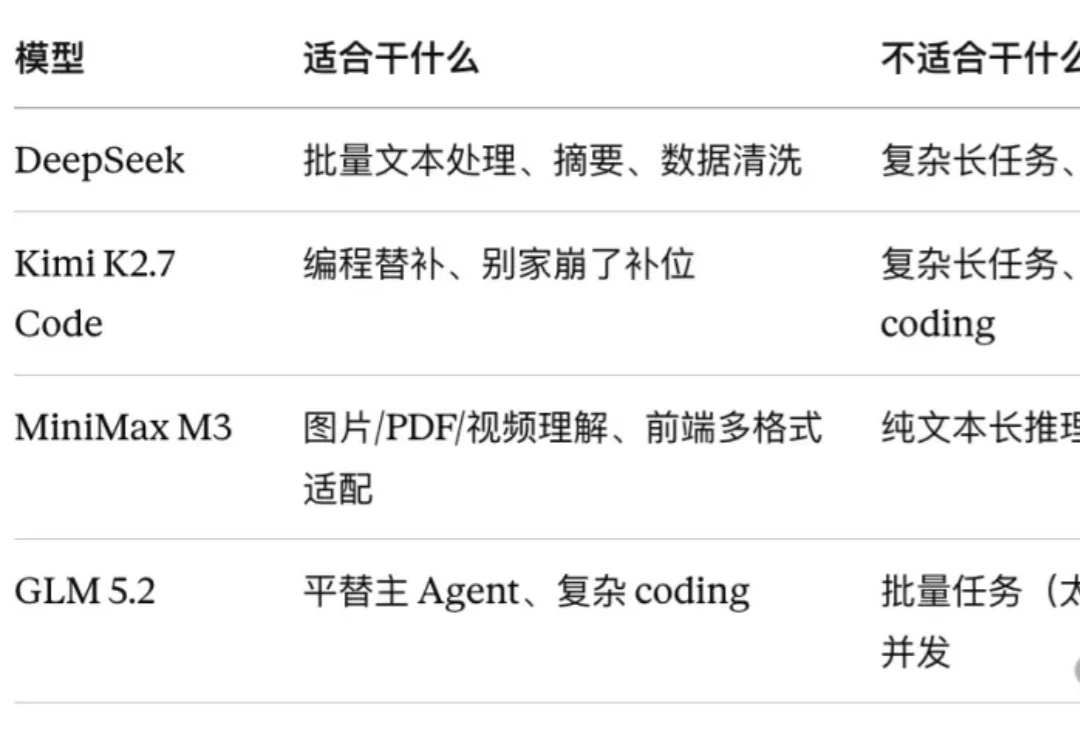
最近,Kimi 2.7 Code 和 GLM 5.2 接连发布,一周双发,国产模型又崛起了。
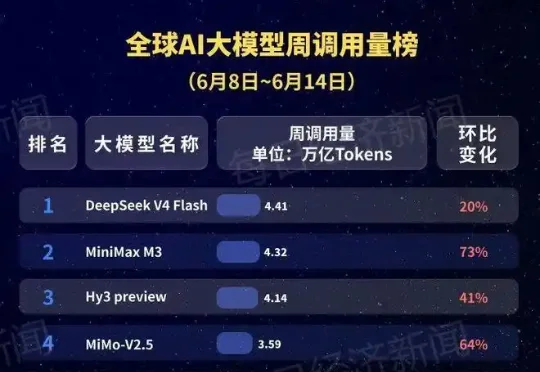
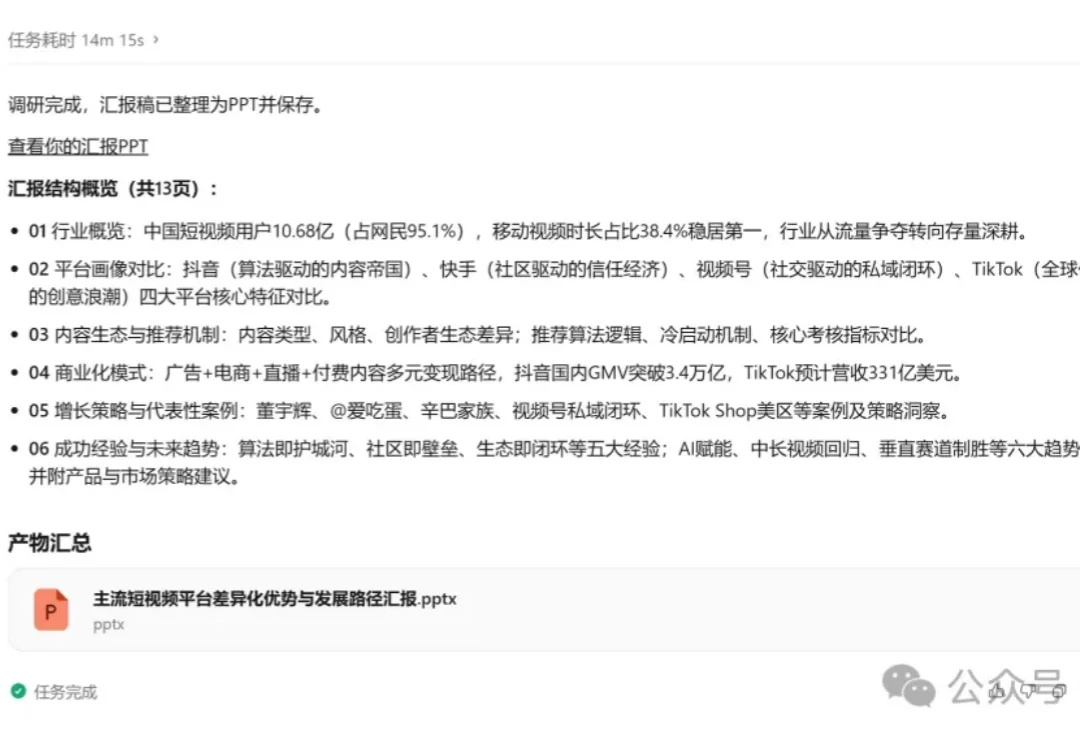
根据OpenRouter最新数据测算,上周(6月8日至14日)全球AI大模型总调用量为44.6万亿Token,较此前一周增长23.5%,连续八周上涨,大模型调用需求仍在持续释放。

这是葬AI起号以来工作量最大的一篇文章。为了严肃评测国产模型的能力,我自研了一个Benchmark,完整测试了智谱、Qwen、Kimi、Minimax、Deepseek这些最新国产模型,还引入了境外势力Claude作对照组。

当智能逼近临界点。

我们在上周五开源了 MiniMax M3 模型权重,同步发布了 MSA(MiniMax Sparse Attention)技术论文。MSA 的架构设计让 M3 在长上下文下的计算成本大幅降低,论文中完整披露了架构与工程实现细节。
Agent 的世界,四月还是山雨欲来。五月尚未结束,已然血雨腥风。

前沿的 Coding 能力、1M 的上下文窗口,还有原生的多模态

MiniMax M3 今日正式发布。MiniMax M3 在编程和智能体等专业任务上达到了前沿的能力。它使用了我们提出的全新注意力架构 MSA (MiniMax Sparse Attention),最高支持 1M 超长上下文。如外界所期待的那样,它也是一个原生多模态模型,支持图片和视频的输入,并能操作电脑桌面。