# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
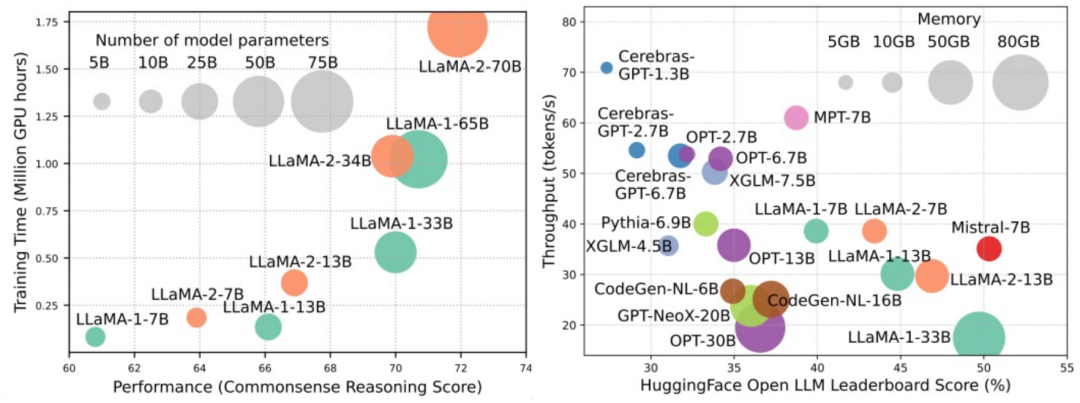
大规模语言模型(LLMs)在很多关键任务中展现出显著的能力,比如自然语言理解、语言生成和复杂推理,并对社会产生深远的影响。然而,这些卓越的能力伴随着对庞大训练资源的需求(如下图左)和较长推理时延(如下图右)。因此,研究者们需要开发出有效的技术手段去解决其效率问题。
同时,我们从图右还可以看出,近来较为火热的高效 LLMs,例如 Mistral-7B,在确保和 LLaMA1-33B 相近的准确度的情况下可以大大减少推理内存和降低推理时延,可见已有部分可行的高效手段被成功应用于 LLMs 的设计和部署中。
在本综述中,来自俄亥俄州立大学、帝国理工学院、密歇根州立大学、密西根大学、亚马逊、谷歌、Boson AI、微软亚研院的研究者提供了对高效 LLMs 研究的系统全面调查。他们将现有优化 LLMs 效率的技术分成了三个类别,包括以模型为中心、以数据为中心和以框架为中心,总结并讨论了当下最前沿的相关技术。

同时,研究者建立了一个 GitHub 仓库,用于整理综述中涉及的论文,并将积极维护这个仓库,随着新的研究涌现而不断更新。研究者希望这篇综述能够帮助研究人员和从业者系统地了解高效 LLMs 研究和发展,并激发他们为这一重要而令人兴奋的领域做出贡献。
仓库网址:https://github.com/AIoT-MLSys-Lab/Efficient-LLMs-Survey
以模型为中心的方法关注算法层面和系统层面的高效技术,其中模型本身是焦点。由于 LLMs 具有数十亿甚至数万亿的参数,与规模较小的模型相比,它们具有诸如涌现等独特的特征,因此需要开发新的技术来优化 LLMs 的效率。本文详细讨论了五类以模型为中心的方法,包括模型压缩、高效预训练、高效微调、高效推理和高效模型架构设计。
1. 模型压缩
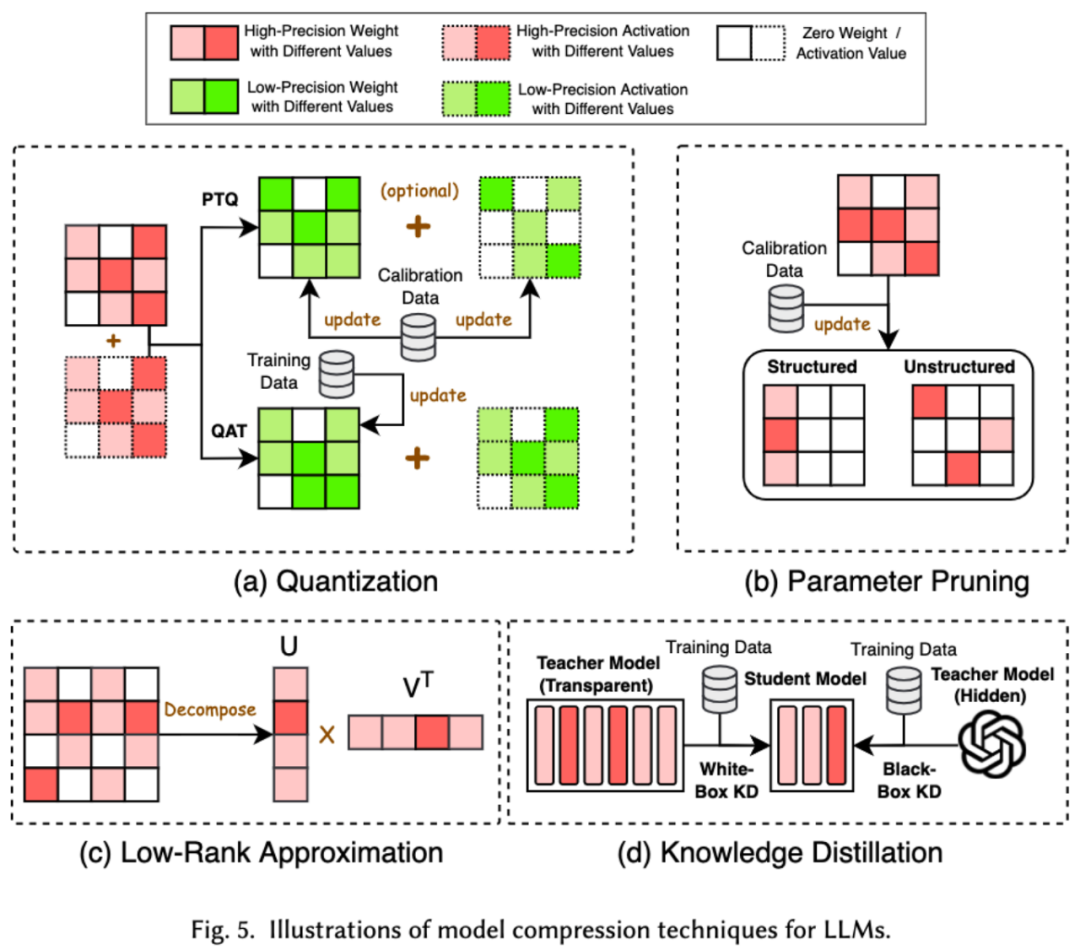
模型压缩技术主要分为了四类:量化、参数剪枝、低秩估计和知识蒸馏(参见下图),其中量化会把模型的权重或者激活值从高精度压缩到低精度,参数剪枝会搜索并删除模型权重中较为冗余的部分,低秩估计会将模型的权重矩阵转化为若干低秩小矩阵的乘积,知识蒸馏则是直接用大模型来训练小模型,从而使得小模型在做某些任务的时候具有替代大模型的能力。
2. 高效预训练
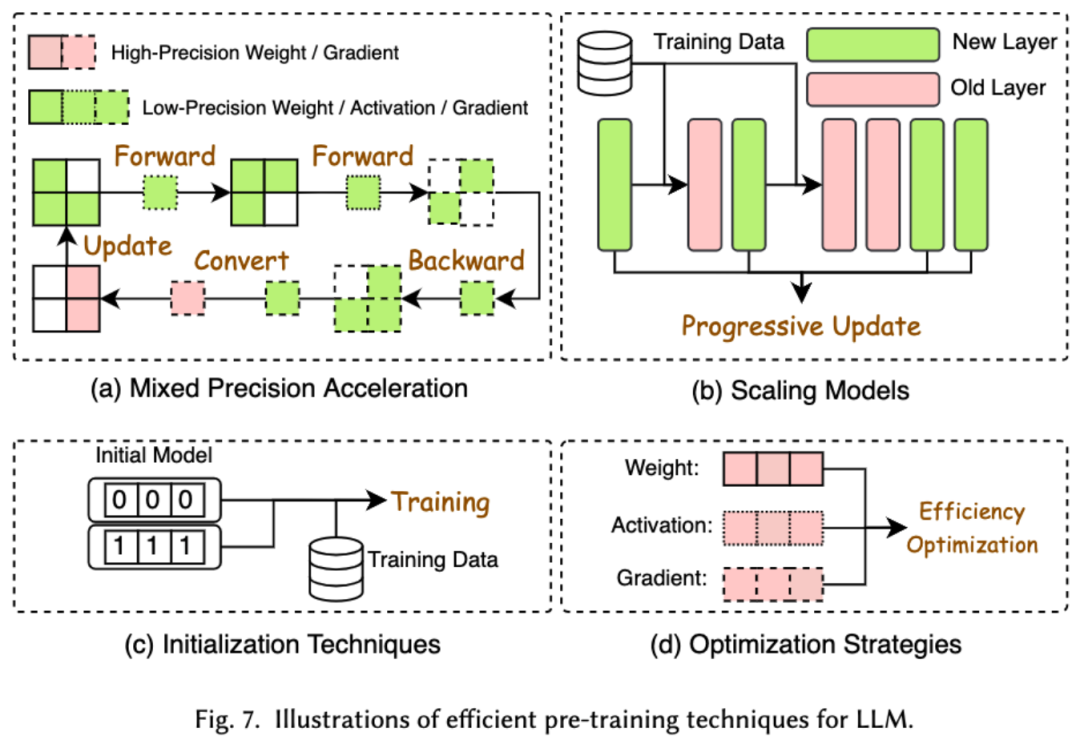
预训练 LLMs 的成本非常昂贵。高效预训练旨在提高效率并降低 LLMs 预训练过程的成本。高效预训练又可以分为混合精度加速、模型缩放、初始化技术、优化策略和系统层级的加速。
混合精度加速通过使用低精度权重计算梯度、权重和激活值,然后在将其转换回高精度并应用于更新原始权重,从而提高预训练的效率。模型缩放通过使用小型模型的参数来扩展到大型模型,加速预训练的收敛并降低训练成本。初始化技术通过设计模型的初始化取值来加快模型的收敛速度。优化策略是重在设计轻量的优化器来降低模型训练过程中的内存消耗,系统层级的加速则是通过分布式等技术来从系统层面加速模型的预训练。
3. 高效微调
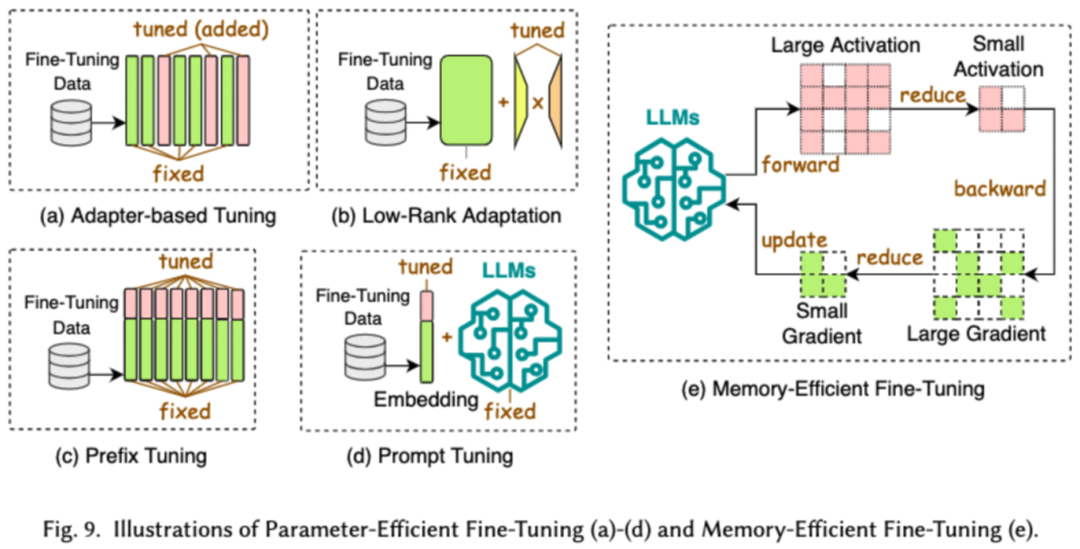
高效微调旨在提高 LLMs 微调过程的效率。常见的高效微调技术分为了两类,一类是基于参数高效的微调,一类是基于内存高效的微调。
基于参数高效微调(PEFT)的目标是通过冻结整个 LLM 主干,仅更新一小组额外的参数,将 LLM 调整到下游任务。在论文中,我们又将 PEFT 详细分成了基于适配器的微调、低秩适配、前缀微调和提示词微调。
基于内存的高效微调则是重在降低整个 LLM 微调过程中的内存消耗,比如减少优化器状态和激活值等消耗的内存。
4. 高效推理
高效推理旨在提高 LLMs 推理过程的效率。研究者将常见的高效推理技术分成了两大类,一类是算法层级的推理加速,一类是系统层级的推理加速。
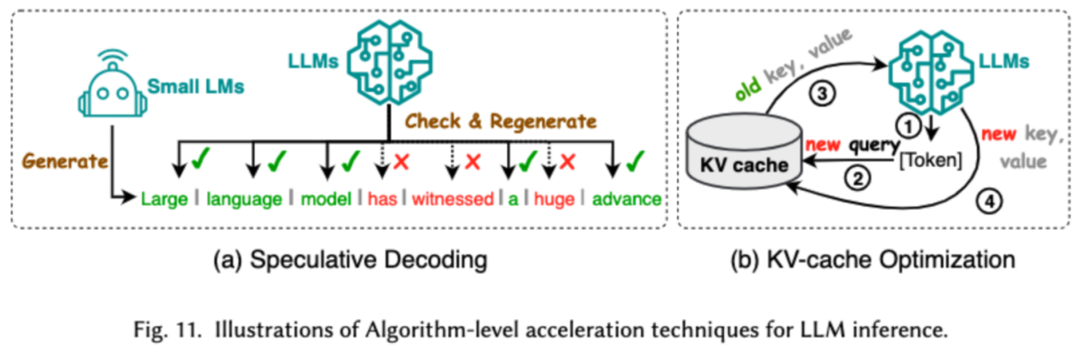
算法层级的推理加速又可以分成两类:投机解码和 KV - 缓存优化。投机解码通过使用较小的草稿模型并行计算令牌,为较大目标模型创建猜测性前缀,从而以加速采样过程。KV - 缓存优化指的是优化在 LLMs 推理过程中 Key-Value(KV)对的重复计算。
系统层级的推理加速则是在指定硬件上优化内存访问次数,增大算法并行量等来加速 LLM 的推理。
5. 高效模型架构设计
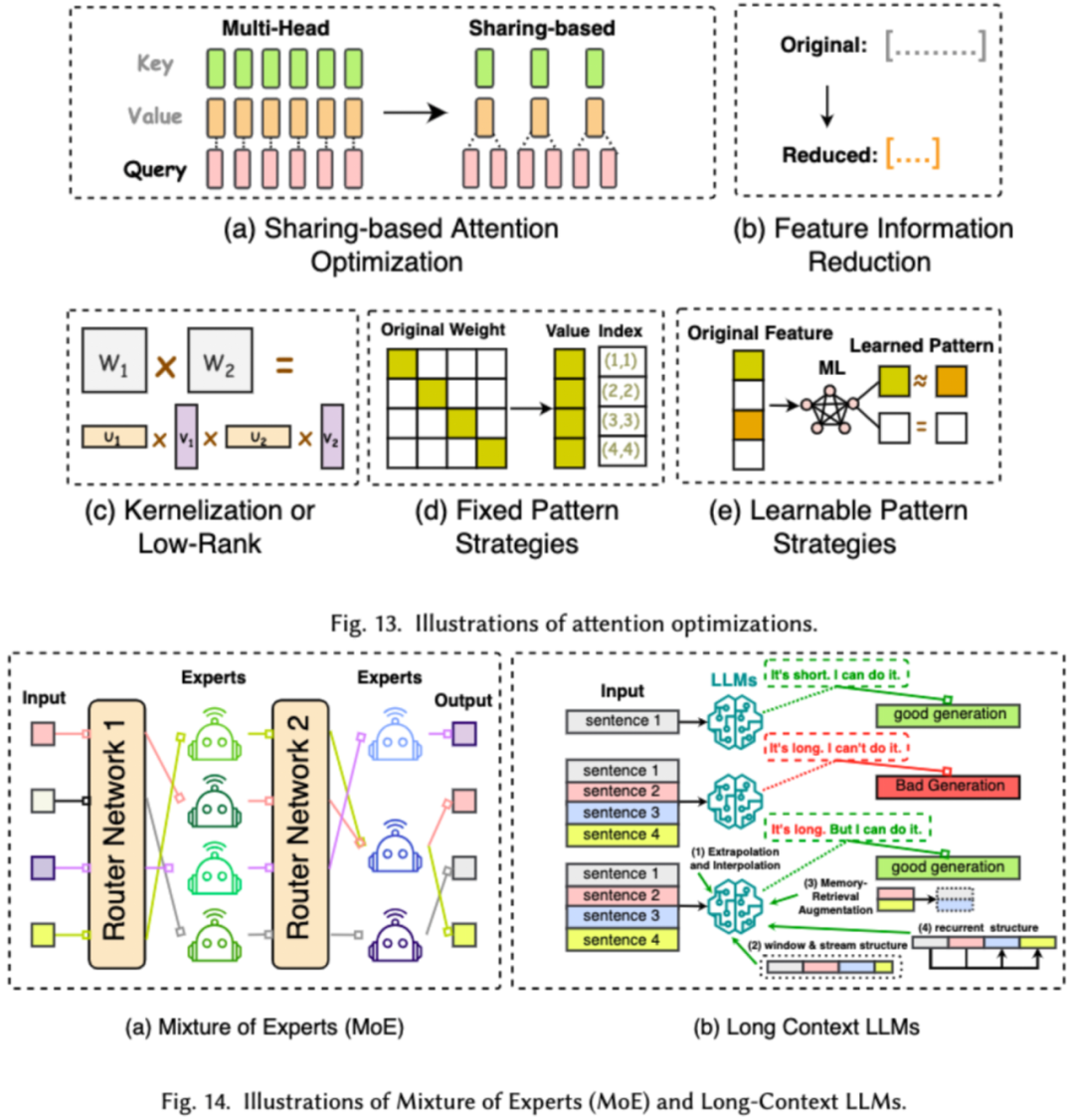
对 LLMs 进行高效架构设计是指通过策略性优化模型结构和计算过程,以提高性能和可扩展性,同时最小化资源消耗。我们将高效的模型架构设计依据模型的种类分成了四大类:高效注意力模块、混合专家模型、长文本大模型以及可替代 transformer 的架构。
高效注意力模块旨在优化注意力模块中的复杂计算及内存占用,混合专家模型(MoE)则是通过将 LLMs 的某些模块的推理决策使用多个小的专家模型来替代从而达到整体的稀疏化,长文本大模型是专门设计来高效处理超长文本的 LLMs, 可替代 transformer 的架构则是通过重新设计模型架构,来降低模型的复杂度并达到后 transformer 架构相当的推理能力。
以数据为中心方法侧重于数据的质量和结构在提高 LLMs 效率方面的作用。研究者在本文中详细讨论了两类以数据为中心的方法,包括数据选择和提示词工程。
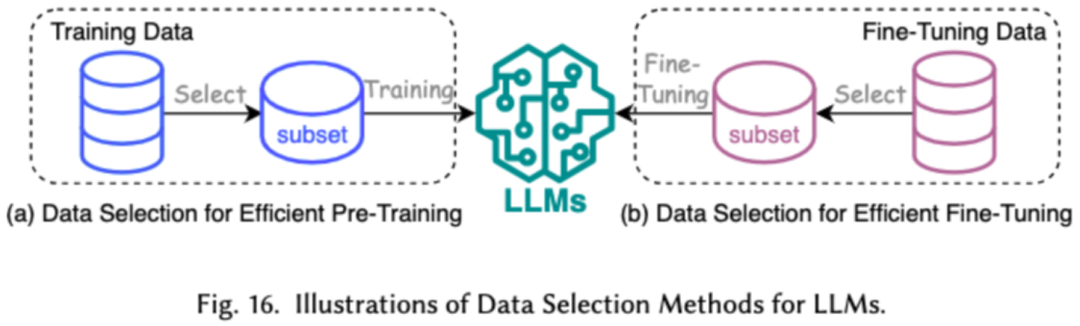
1. 数据选择
LLMs 的数据选择旨在对预训练 / 微调数据进行清洗和选择,例如去除冗余和无效数据,达到加快训练过程的目的。
2. 提示词工程
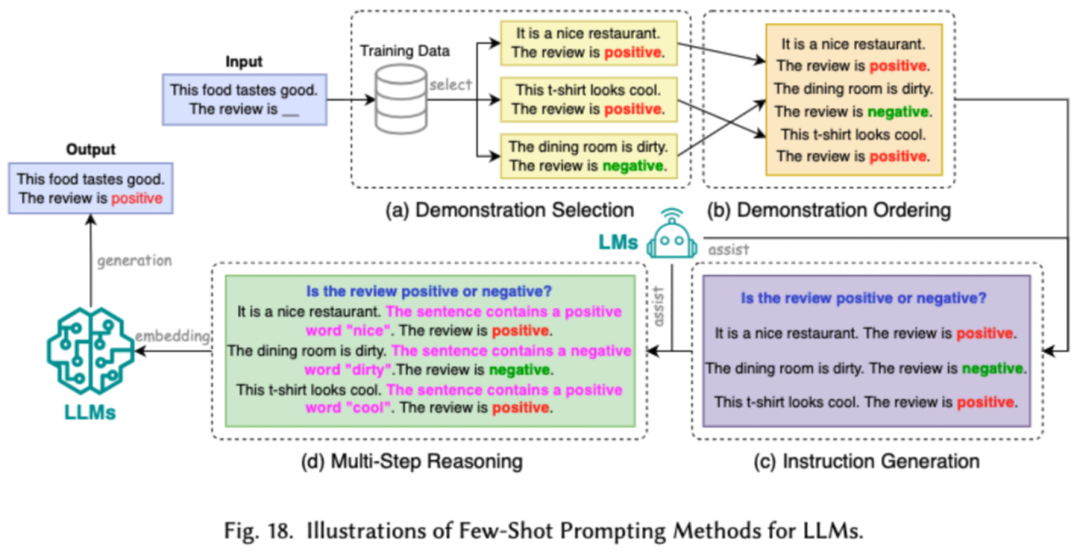
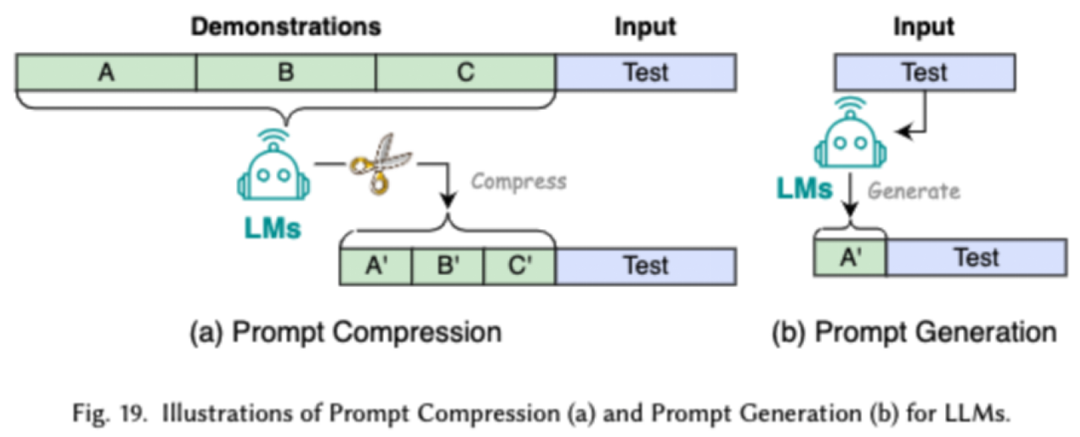
提示词工程通过设计有效的输入(提示词)来引导 LLMs 生成期望的输出,它的高效之处在于可以通过设计提示词,来达到和经过将繁琐的微调相当的模型表现。研究者将常见的的提示词工程技术分成了三大类:少样本的提示词工程、提示词压缩和提示词生成。
少样本的提示词工程通过向 LLM 提供有限的示例集以引导其对需要执行的任务进行理解。提示词压缩是通过压缩冗长的提示输入或学习和使用提示表示,加速 LLMs 对输入的处理。提示词生成旨在自动创建有效的提示,引导模型生成具体且相关的响应,而不是使用手动标注的数据。
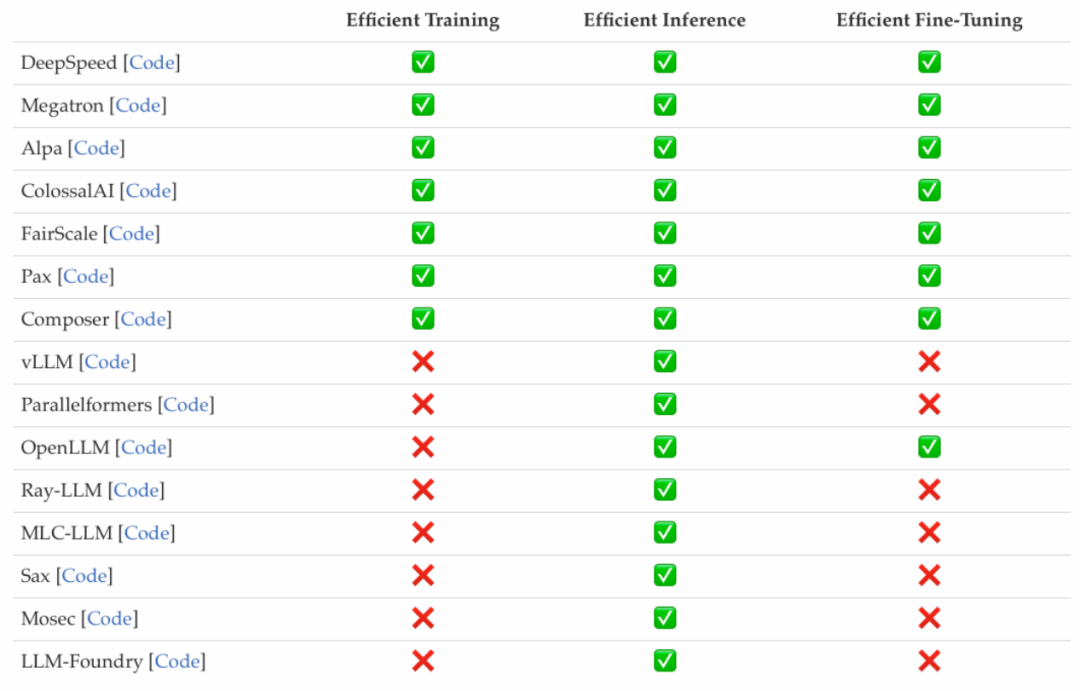
研究者调查了近来较为流行的高效 LLMs 框架,并列举了它们所能优化的高效任务,包括预训练、微调和推理(如下图所示)。
在这份调查中,研究者为大家提供了一份关于高效 LLMs 的系统性回顾,这是一个致力于使 LLMs 更加民主化的重要研究领域。他们一开始就解释了为什么需要高效 LLMs。在一个有序的框架下,本文分别从以模型的中心、以数据的中心和以框架为中心的角度分别调查了 LLMs 的算法层面和系统层面的高效技术。
研究者相信,在 LLMs 和以 LLMs 为导向的系统中,效率将发挥越来越重要的作用。他们希望这份调查能够帮助研究人员和实践者迅速进入这一领域,并成为激发新的高效 LLMs 研究的催化剂。
文章来自于微信公众号“机器之心”


【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
