# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

应该如何形容 Prompt 工程呢?对于一个最开始使用 ChatGPT 的新人小白,面对据说参数量千亿万亿的庞然巨兽,Prompt 神秘的似乎像某种献祭:我扔进去几句话,等待聊天窗口后的「智慧生命」给我以神谕。
然而,上手 Prompt 之后,操纵 ChatGPT 似乎更加类似于指挥家指挥管弦乐队,面对我们要解决的问题,合理的编排与组织文字,最后演化成类似指挥家的身体语言,控制大模型这样一个「精密仪器」执行复杂任务。

那么如何快速上手 Prompt 工程将 ChatGPT 不再视为难以操纵的庞然大物而是得心应手的趁手兵刃呢?
就在近日,OpenAI 官方发布了 Prompt 工程指南,讲述了快速上手 ChatGPT Prompt 的种种「屠龙术」,不仅在理论层面对 Prompt 分类总结,还提供了实际的 Prompt 用例,帮助大家来学习如何有效的与 ChatGPT 交互,一起来看看吧!
宏观来看,OpenAI 给出了可以提升 ChatGPT 回复效果的「六大秘籍」,分别是:
让我们先来看第一条策略:清晰细致。
如果说的大白话一点,就是要把你需要解决的问题说清楚讲明白。要想从 ChatGPT 那里获得良好的回复,那么 Prompt 本身必须结合精确性、清晰度与任务描述的细致程度于一身,为了避免歧义而「把话说清楚」是让 ChatGPT 高效工作的重中之重。
举个例子,假设我们想了解「2021年的时候谁是墨西哥的总统」,甚至更进一步还想知道他/她是否目前仍然是总统,如果我们扔给 ChatGPT 一句「谁是总统?」,别说 ChatGPT,就算是政治老师也会一脸懵逼,更好的 Prompt 应该是:「2021年谁是墨西哥的总统,墨西哥几年举行一次选举?」
如果说上面的例子有点极端,那么再看一个更加日常的例子。假设我们要去进行一个会议总结,如果我们期望 ChatGPT 可以给到我们良好的回复,那么我们就不应该直接扔进去一句话:「帮我总结这份会议笔记」,而是要将我们的需求讲明白:「首先使用简单一段总结概括这份会议笔记的主要内容,其次将会议中各个发言者的核心点以Markdown的格式分条列出,最后,如果有的话,列出每个发言者提出的下一步行动计划与方案。」
显然,后者的描述更为清晰,更有可能得到我们想要的答案。OpenAI 在指南中列出了一个 Worse or Better 的示例供大家参考:

同时,OpenAI 给出了一个 Prompt 想要做到表达清晰细致应该需要包含的内容:
以上述的会议总结为例,一个更加完整的 Prompt 可能是:
指令:假设你是一场会议的会议秘书【指定角色】,首先【任务拆分】使用简单一段总结概括这份会议笔记的主要内容,其次将会议中各个发言者的核心点以 Markdown 的格式分 3 条【指定长度】列出,最后,如果有的话,列出每个发言者提出的下一步行动计划与方案【详细信息】。请以将总结插入到下方模板的<>中间。
模板【使用分隔符】:总结:发言人 1 核心观点:发言人 2 核心观点:…… 发言人 1 行动计划:发言人 2 行动计划:……
示例【提供示例】:……
第二点重要的策略是需要为 ChatGPT 提供参考,通过引导 ChatGPT 根据我们给定的材料撰写答案,将会使得模型回答更加聚焦于当前的问题之上,从而生成更加可靠与准确的答案。
譬如,如果我们直接询问模型「知识产权盗窃的法律后果是什么?」,那么模型可能无法专业准确的对问题进行回复,而如果我们给模型提供一篇关于知识产权法的论文或发条,模型就会给出更加专业的回复。
指令:参考提供的法律期刊文章与法条,解释知识产权盗窃的法律后果。参考:【知识产权盗窃的法律规范xxx】
而为了使得模型更好的理解参考文本并且直接引用参考中的原文进行回复,那么就可以对参考引用做出更加细致的解释,譬如:
指令:参考下面这份由三个引号进行分隔的文件,请回答知识产权盗窃的法律后果是什么。请仅仅引用所提供的文件来回答问题,并且引用用于回答问题的相关段落,如果文件中不包含回答问题所需的信息,则需要写出「信息不足」。如果找到了相关答案,则必须注明引文,请使用以下格式引用相关段落({“引用”:……})。参考:【知识产权盗窃的法律规范xxx】
受启发来自软件工程中将复杂系统分解为一组模块的组件的思想,任务拆分也是提示 Prompt 性能的法宝之一,复杂任务可以被拆分为简单任务的累加,通过解决一系列简单任务就可以得到逼近复杂任务满意解的方案。
举一个长文档摘要的例子,对于一个过长的文本,比如直接让 ChatGPT 理解一本 300 页的书籍可能 ChatGPT 无法做到,但是通过任务分解——递归的分别总结书籍中的每一章,在每一章的总结之上对书籍内容进行摘要——就有可能实现对难任务的解决。
具体而言,任务分解的也需要做到:
而这样做,可以:
有一个有意思的点在于,从「Let's think step by step」的实践中我们可以发现,让模型一步一步的思考而不是直接给出答案可以显著的提升任务的准确率。
以思维链技术 COT 的代表应用数学解题为例,有如下的题目:
土地租用成本为 100 美元/平方英尺,太阳能电池板购买成本为 250 美元/平方英尺,固定投入成本为 10 万美元,每年的运营成本为 10 美元/平方英尺,假设购买 x 平方英尺的太阳能电池板,请问一年的总成本为多少?
对此,现在,有个学生给出的解题步骤为(1)土地成本100x,(2)电池板购买成本250x,(3)运营成本10x,(4)固定投入100000,则总成本为 100x + 250x + 100x + 100000 = 450x + 100000。
显然这名学生将运营成本的 10x 错写为了 100x,但是如果直接将学生答案输入模型,询问「学生的解决方案是否正确?」时,模型却会错误认为该解法正确:
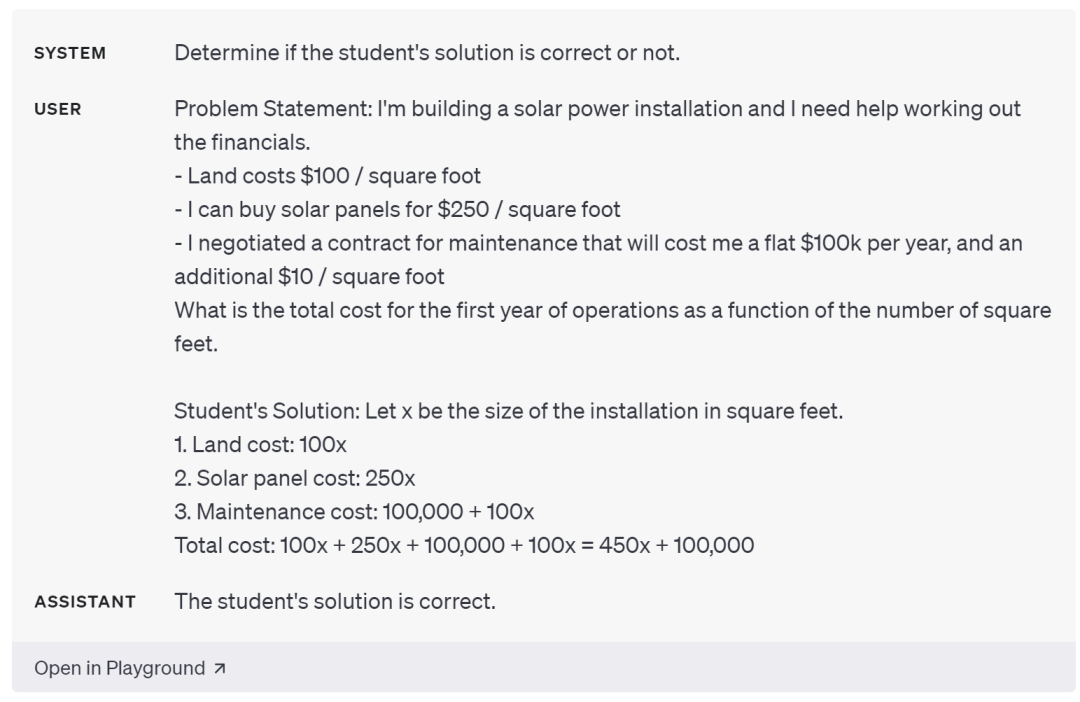
但是如果「让模型进行思考」,告诉模型首先由模型自己确定一个解决方案,再将自己的解法与学生的解法进行比较,评估学生的解法是否正确。在自己完成问题之前,不要确定学生的解法是否正确。
而如果这样输入,模型不仅可以提供正确解法还可以很快发现学生的错误之处:

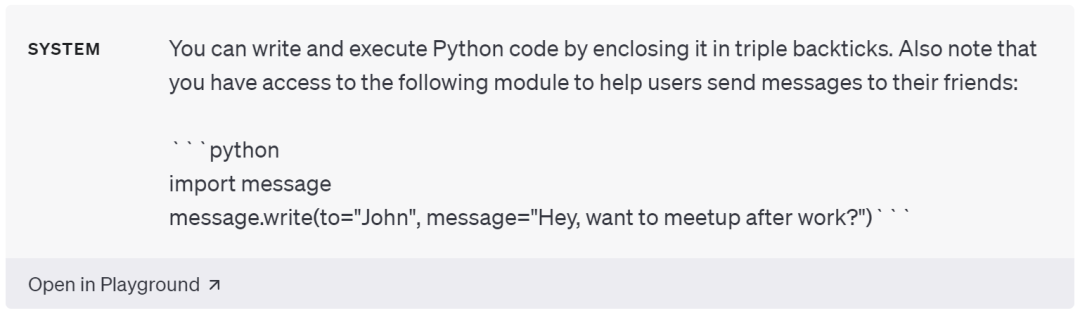
从 AI Agent 的思路出发,语言模型必然不是万能的,但是就如同人类一样,我们可以通过向模型提供其他工具的方式来弥补模型的弱点,其中最经典的应用莫过于大模型与代码执行引擎的结合。
所谓让专业的人去做专业的事,直接从自己学习与训练的语料中感知到今天的天气如何可能对大模型而言是无法做到的,但是现在有太多方便调用的天气 API 可以很快的帮助模型查询到今天的天气,从而使得模型提升自己的能力。
其中典型的应用有:
要想真正测试到「好的 Prompt」,那么必然要在一个全面系统的环境下对 Prompt 进行评估与检验。很多场景下在一个孤立的实例中一个 Prompt 的效果良好并不能代表这个 Prompt 可以推而广之,因此对 Prompt 的系统测试也是提升 Prompt 能力的关键环节之一。
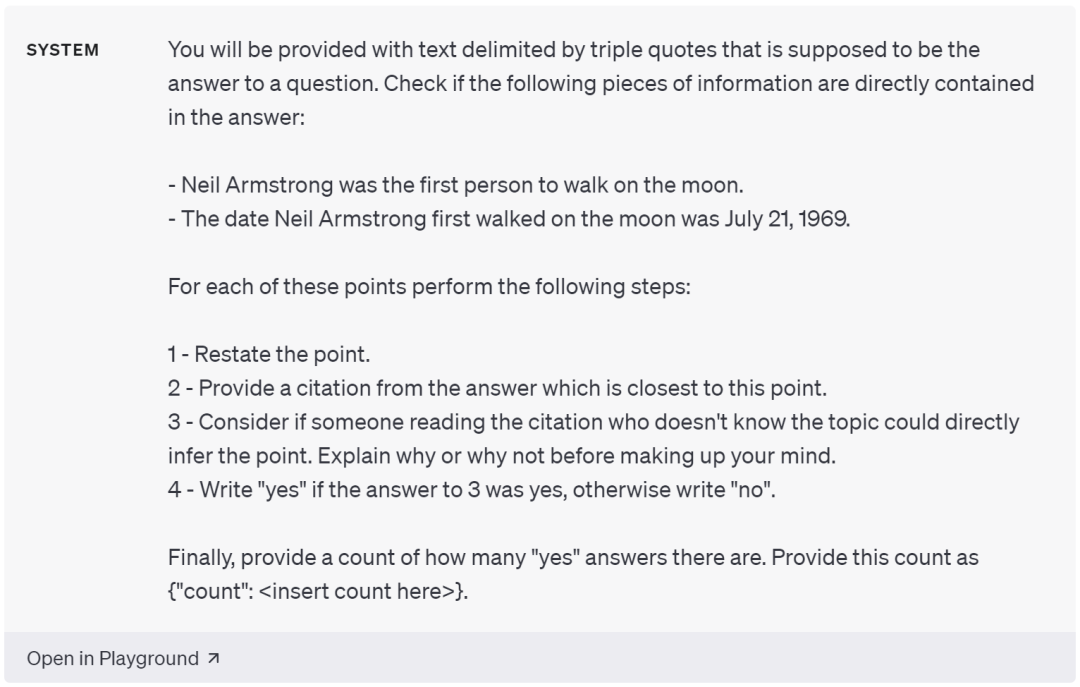
其中,一种方法是假设我们已经知道了正确答案应当包含的某个已知事实,那么就可以使用模型来查询输出中包含多少必要的事实。比如我们假设存在一个事实「阿姆斯特朗是第一个登上月球的人」,则可以向模型输入:
以下有三组以引号进行分隔的文本,该文本的正确答案是:尼尔·阿姆斯特朗是第一个登上月球的人,请检查答案是否直接包含上述信息,对于每组文本,请首先理解文本,提供最接近正确的答案的引文,考虑在不清楚相关主题的人是否可以直接从该文本推断出正确答案。
此外,还可以借助「矛盾推断」,「细节补充」等等方式对输出答案进行评估,以确定更好的 Prompt 格式。
毫无疑问,Prompt 的质量显著影响着大模型的性能,而好的 Prompt 有甚至不仅仅是一种技术更是一种「艺术」。作为「人」与「AI」互动的窗口,Prompt 很有可能是未来 AI 时代我们必须掌握的「第二语言」,而这份 OpenAI 官方的指南就非常类似一本小学英语入门教科书,感兴趣的大家可以去查阅原文浏览更加详细的例子。
链接: https://platform.openai.com/docs/guides/prompt-engineering/six-strategies-for-getting-better-results
除了指南以外,OpenAI 还提供了更加即插即用的各个场景下的优秀 Prompt 范例。
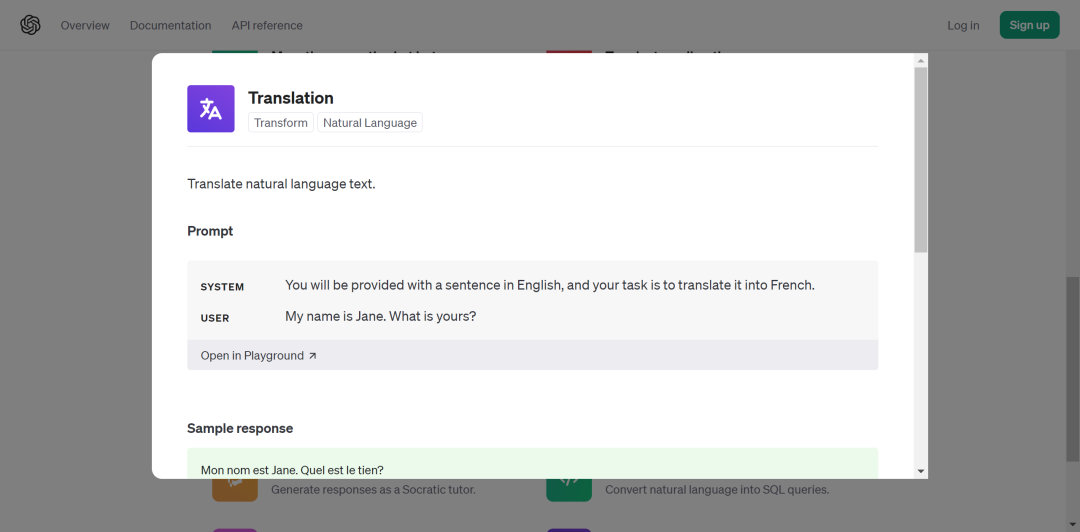
譬如我期望使用大模型完成翻译任务,那么在 Prompt examples 中搜索翻译,就可以找到优秀的「满分作文」供我们抄袭(x)借鉴(√)。
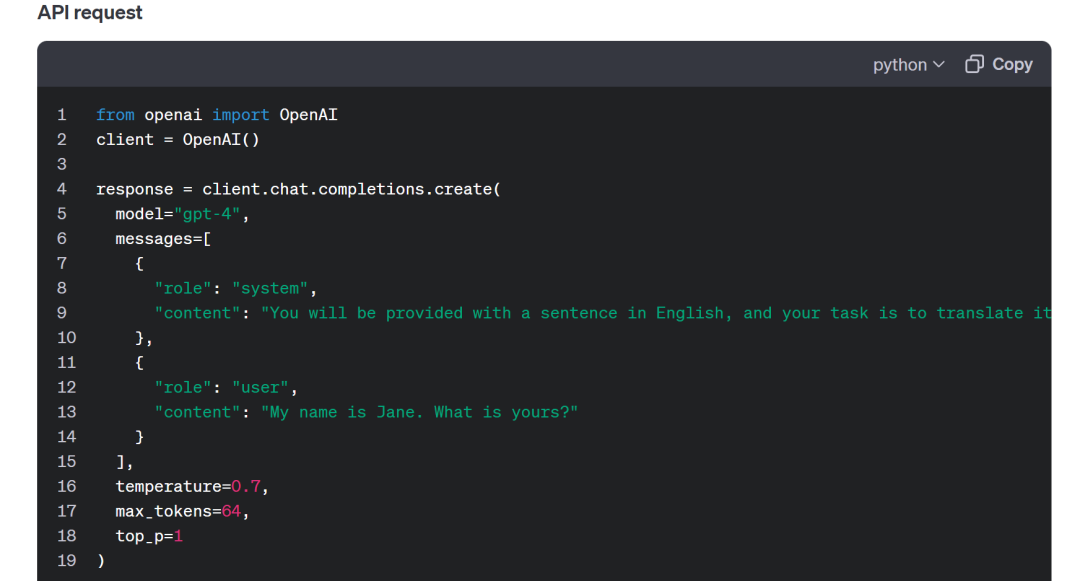
除了 Prompt 以外,还有 API 调用的代码以供参考,提供了推荐的 temperature 等参数:
参考资料:
https://platform.openai.com/examples
文章来自于微信公众号 “新智元”,作者 “小戏”


【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
