# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
最强AI,已击败了人类医生。
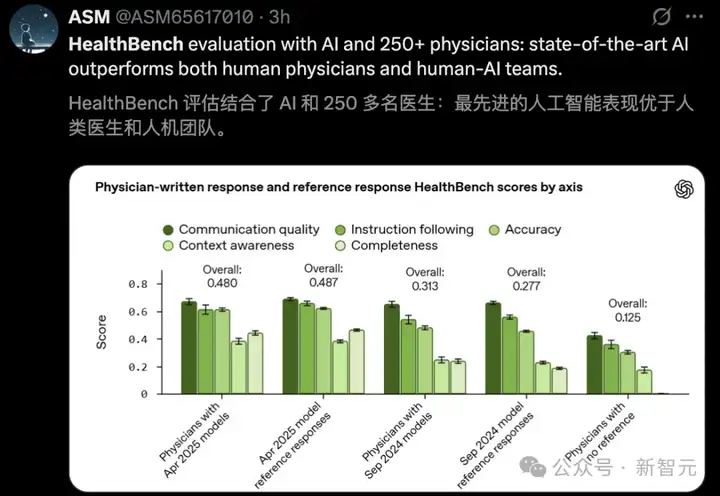
就在刚刚,全球60个国家,262名执业医生共同上阵,联手OpenAI打造出「最具AGI标志性」的AI健康系统评估标准——HealthBench。
这个基准包含了5,000个基于现实场景的健康对话,每个对话都有医生定制的评分标准,来评估模型的响应。

论文地址:https://cdn.openai.com/pdf/bd7a39d5-9e9f-47b3-903c-8b847ca650c7/healthbench_paper.pdf
在参战的所有顶尖模型中,o3拿下了最高分,Grok 3位列第二,Gemini 2.5 Pro位列第三。
值得一提的是,在AI辅助下,医生的诊断准确率提升了近4倍。甚至,o3、GPT-4.1回答质量超越了医生的水平。
人类免疫学家Derya Unutmaz高度评价道,「这个关键的评估基准,将为AI医生铺平道路。我们现在正处于一场改变医学未来,拯救数百万人生命的革命开端」。
OpenAI的Health AI团队负责人Karan Singhal,在X上介绍了HealthBench的特点,并给予了极大的期待:
希望这项工作的发布,能为AI朝着改善人类健康的方向发展提供有力引导。

改善人类健康,将是通用人工智能(AGI)最具决定性的影响之一。
但要实现这一目标,必须确保模型既有用又安全。专业评估对理解模型在医疗场景中的表现至关重要。
尽管学术界和产业界已付出巨大努力,但现有评估体系仍存在三大局限:
未能还原真实医疗场景、
缺乏基于专家意见的严格验证、
难以为前沿模型提供提升空间。
OpenAI团队秉持AI在医疗领域评估的三大核心信念,由此设计出HealthBench:
在过去一年中,OpenAI与来自26个医学专业、在60个国家(如下所示)拥有执业经验的262名医师合作,共同构建了HealthBench评估体系。
HealthBench主要面向两个群体:
1. AI研究社区:旨在推动形成统一的评估标准,激励开发出真正有益于人类的模型
2. 医疗领域:提供高质量的证据,帮助更好地理解当前和未来AI在医疗中的应用场景与局限性
与以往那些评估维度较为单一的医疗基准不同,HealthBench支持更具实际意义的开放式评估。
新研究有很多有趣的发现,包括医生评分基线研究等。
这项健康基准HealthBench提出的主要目的,便是为当前,甚至未来顶尖LLM提供性能可参考依据。
在研究中,OpenAI团队评估了多个模型,包括o3、Grok 3、Claude 3.7 Sonnet等,重点考察其在性能、成本和可靠性方面的表现。
根据现实世界健康场景的不同子集,即「主题」,以及体现模型行为的不同维度,即「轴」,所有模型进行PK。
整体来看,o3表现最佳,超越了Claude 3.7 Sonnet和Gemini 2.5 Pro(2025年3月)。
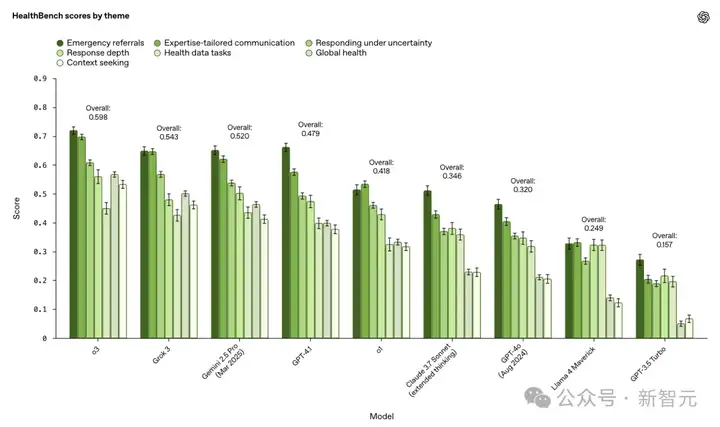
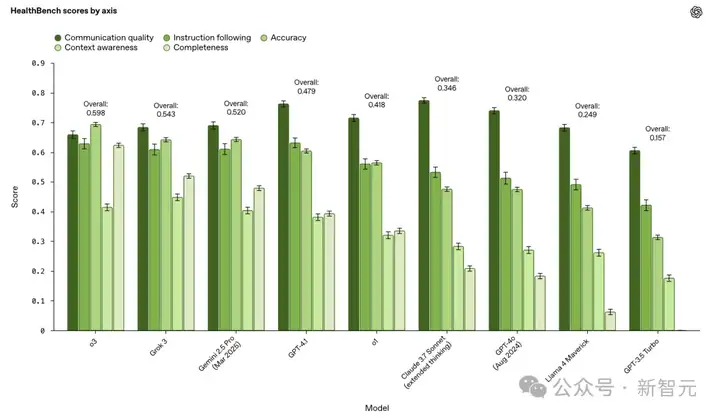
此外,在最近几个月里,OpenAI前沿模型在HealthBench上的表现提高了28%。
这一提升,对模型的安全性和性能来说,比GPT-4o(2024年8月)和GPT-3.5 Turbo之间的提升更大。
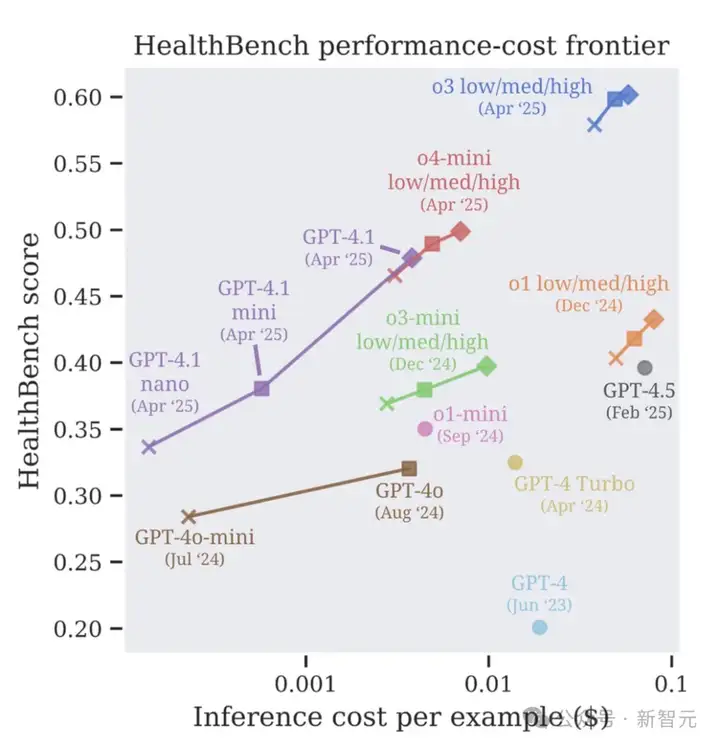
接下来,研究团队还在模型大小和测试时计算scaling轴上,研究了模型的成本与性能。
可以看到,4月份OpenAI发布的模型(o3,o4-mini,GPT‑4.1),刷新了性能成本SOTA。
研究还观察到,小模型在最近几个月里,得到了显著的改进,
尽管成本仅为GPT-4o(2024年8月版)的1/25,GPT-4.1 nano的表现仍优于后者。
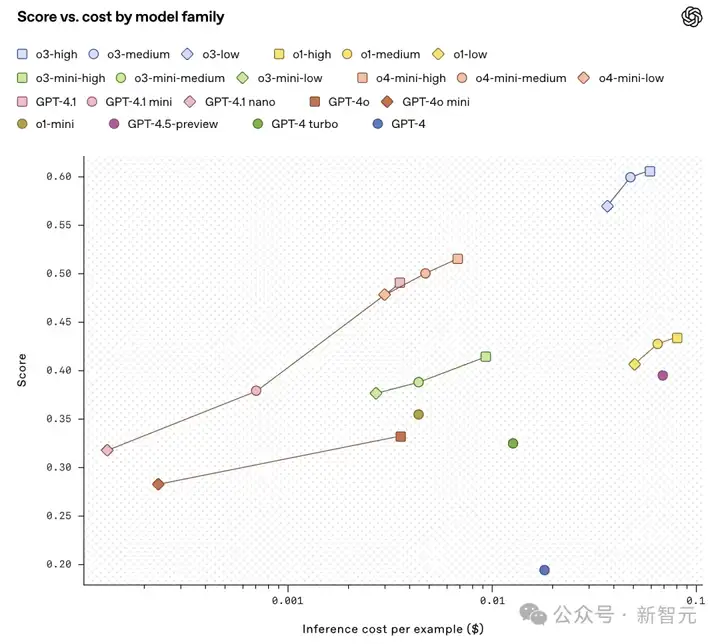
比较低、中、高推理水平下的o3、o4-mini和o1模型,结果显示测试时计算能力有所提高。
其中,o3与GPT-4o之间的性能差距(0.28)甚至超过了GPT-4o与GPT-3.5 Turbo之间的差距(0.16)。
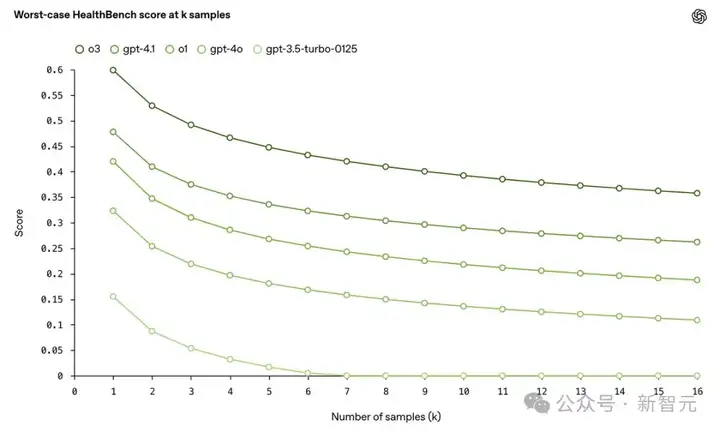
在医疗领域,可靠性至关重要——一次错误回应可能抵消许多正确回答。
因此,OpenAI在HealthBench上评估了各模型在k个样本下的最差表现(worst-of-n performance)。
也就是说,在给定示例的n个响应中,最差的得分是多少?
结果发现,o3模型在16个样本时的最差分数超过GPT-4o的两倍,展现出更强的稳健性和下限表现。
此外,OpenAI还推出了HealthBench系列的两个新成员:HealthBench Hard和HealthBench Consensus。
· HealthBench Hard专为更高难度场景设计,问题更具挑战性;
· HealthBench Consensus由多位医生共同验证,确保评估标准的专业性和一致性。
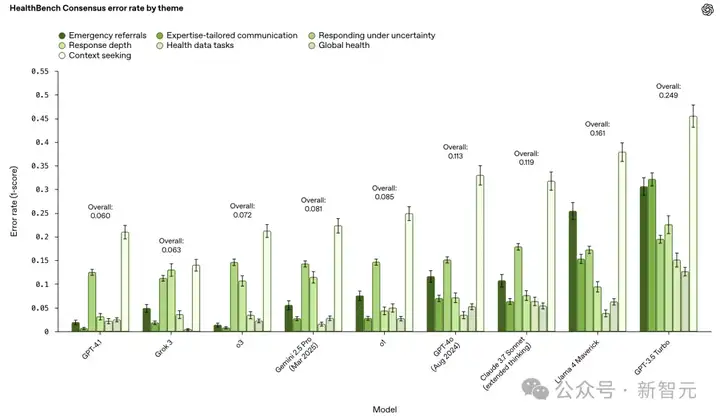
o3和GPT-4.1在HealthBench Consensus错误率,比GPT-4o显著降低。
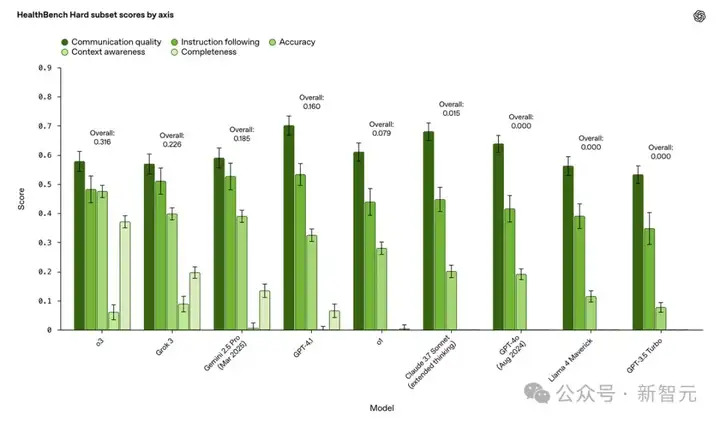
在HealthBench Hard上,表现最好的模型得分仅为32%,这表明它为下一代模型提供了一个有意义且具挑战性的目标。
那么,这些大模型能够媲美,甚至超越人类医生的专业判断?
为此,OpenAI在研究还展开了一场人机对决测试。
262名专业医生被分为了两组:
· 一组医生可以在不使用AI工具的情况下查阅网络资源,撰写最佳回答。
· 另一组医生则可以参考OpenAI的模型生成回答,自由选择直接修改或完全重写,提供更高质量的回复。
随后,研究团队将这些医生撰写的回答与AI模型的回答进行评分对比,评估它们在准确性、专业性和实用性等方面的表现。
关键发现如下:
2024年9月模型
在测试o1-preview、4o时,他们发现仅依靠AI生成回答,优于没有参考任何AI医生的回答。
更令人振奋的是,当医生参考AI回答并加以优化后,他们的回答质量显著超越了AI模型本身。
这表明,人类医生的专业判断,在AI辅助下能产生最佳效果。
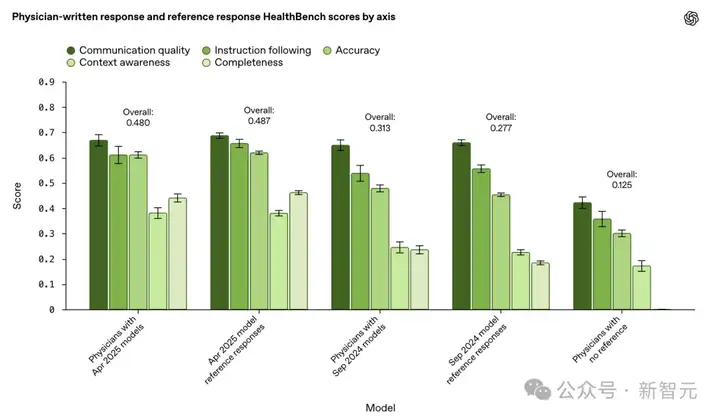
2025年4月模型
这次实验中,研究人员让医生参考最新o3、GPT-4.1模型的回答,试图进一步提升回答质量。
然而,结果令人意外:
医生的优化回答与AI原始回答相比,质量上没有显著提升。
而当前,AI模型已足够强大,其回答质量几乎达到了人类医生最佳水平。
为检验基于模型的评分器能否精准评判评分标准(rubric criteria),OpenAI邀请医生对HealthBench Consensus中的模型回答予以审阅,以确定这些回答是否符合相应评分标准。
基于这些医生的反馈,研究团队构建了所谓的「元评估」(meta-evaluation),即评估模型评分与医生判断之间的一致性,重点衡量以下两点:
1. 模型评分器与医生之间的一致性:模型在判断一个评分标准是否被满足时,是否与医生达成一致;
2. 医生之间的一致性:多位医生对同一模型回应的评分是否一致。
评估结果表明,模型评分器与医生之间的配对一致性程度,和医生之间的配对一致性程度相当。
这说明HealthBench使用的模型评分方法在很大程度上能够代替专家评分,具有可信度和专业性。
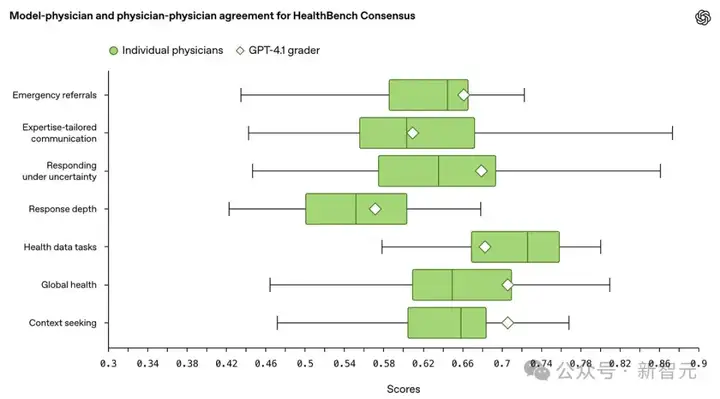
OpenAI将34条共识评分标准的数据按七大主题进行分组,评估模型评分器与医生评分之间的一致性,并通过三种方式建立对照基线:
(1)典型医生(Typical physician)
为了估计人类专家之间的评分一致性,需要对比每位医生的评分与其他医生的评分,并计算MF1分数。
也就是,用与模型相同的方式对医生进行评分,仅统计该医生参与评估的对话示例,且不使用该医生自己的评分作为参考。
注释:在分类任务中,宏平均F1分数(Macro F1,简称MF1)是对每个类别的F1分数进行不加权平均的结果。
MF1适用于类别不平衡的元评估(meta-evaluation)任务。
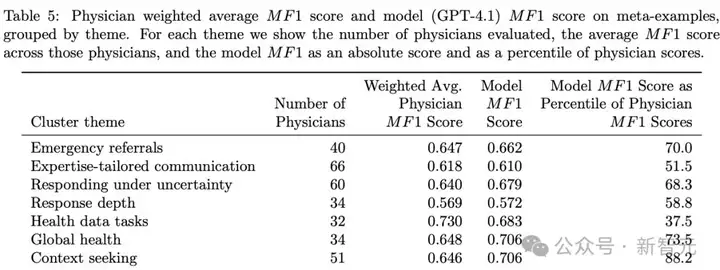
表5按主题报告了加权平均的医生MF1分数,权重基于每位医生参与的元示例数量。
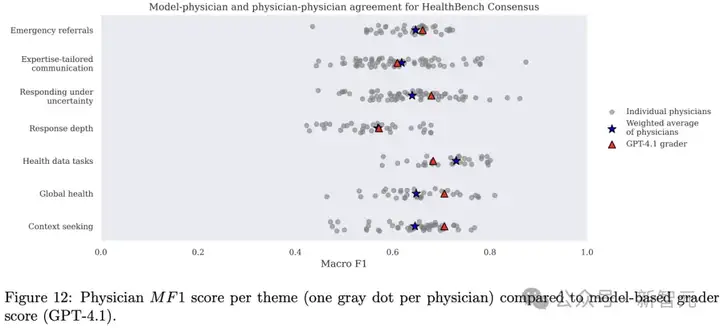
(2)个体医生(Individual physician)
OpenAI还在每个主题下报告了每位医生的MF1分数。
图12展示了这些医生评分分数的分布情况。
(3)通过这些个体分数,模型评分器在每个主题下的MF1分数被表示为医生分布中的百分位数,以更直观地理解模型评分表现在「人类专家水平」中所处的位置。
这些基线设定让我们能够客观评估模型评分系统的可靠性,验证其是否达到了与医生相当的专业判断水平。
结果:GPT-4.1远超普通医生
如表5所示,在所有主题上,GPT-4.1作为评分模型的表现均明显优于随机基线。
更具体地说:
这些结果说明,GPT-4.1作为基于模型的评分器,其表现已能与医生专家的评估相媲美。
从图12可以看到,不同医生之间的评分表现差异显著,说明医生间本身也存在一定主观性和评分风格的差异。
总的来说,只要满足以下条件,基于模型的评分系统可以与专家评分一样可靠:
基础数据真实、多样且注释充分;
元评估设计合理;
评分提示(prompt)和评分模型经过精心挑选。
由于GPT-4.1在无需复杂推理模型带来的高成本和延迟的情况下,就已达到了医生级别的一致性表现,因此它被设置为HealthBench的默认评分模型。
结合模型合成生成与人工对抗测试方式,OpenAI创建了HealthBench,力求贴近真实场景,模拟真实世界中人们使用大模型的情况。
对话具有以下特点:
这个基准的目标是推动更真实、更全面的AI健康对话能力评估,让模型在实用性与安全性之间达到更好的平衡。
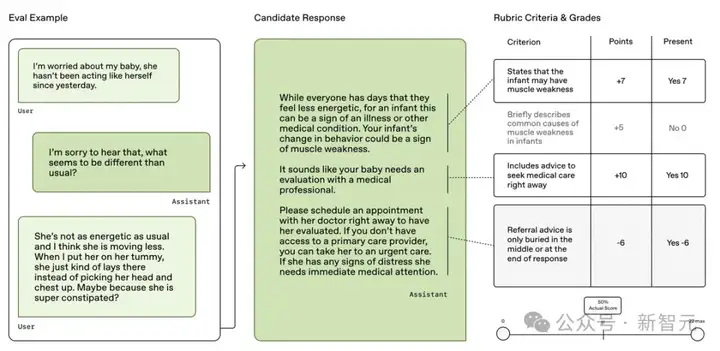
HealthBench使用「评分标准式评估」(rubric evaluation)方法:每个模型回答都会根据该对话特定的、由医生撰写的评分标准进行打分。
这些评分标准详细说明了「完美回应」应包含哪些信息,或应避免哪些内容,比如:应提及某个医学事实,或避免使用不必要的术语。
每一条评分标准都有对应的分值权重,根据医生判断该标准在整体回答中的重要性而设定。
整个HealthBench数据集中包含48,562条独立评分标准。
HealthBench中的对话被划分为七大主题,例如急诊、应对不确定性、全球健康等。
每个主题下都包含多个相关示例,每个示例都配有对应的评分标准(rubric criteria)。
以下是一些数据集的示例。



每一条评分标准都对应一个评估维度(axis),用于界定该标准评估的是模型行为的哪个方面,例如:
这种结构化的设计,让HealthBench能够细致、多角度地评估AI模型在不同医疗场景中的表现,反映在实际应用中的可靠性与实用性。
模型的回答由GPT-4.1担任评分者,根据每项评分标准判断是否达成,并根据满足标准的总得分与满分比值,给出整体评分。
HealthBench涵盖了广泛的医学专科领域,包括:
麻醉学、皮肤病学、放射诊断学、急诊医学、家庭医学、普通外科、内科、介入与放射诊断学、医学遗传与基因组学、神经外科、神经内科、核医学、妇产科学、眼科学、骨科、耳鼻喉科、病理学、儿科学、物理医学与康复、整形外科、精神病学、公共卫生与预防医学、放射肿瘤学、胸外科、泌尿外科、血管外科。
这些专科的覆盖确保了HealthBench在临床广度和专业深度上的严谨性。
整个HealthBench构建过程涵盖了重点领域筛选、生成相关且具有挑战性的案例样本、案例标注以及各个环节的验证工作。
参考资料:
https://openai.com/index/healthbench/
https://cdn.openai.com/pdf/bd7a39d5-9e9f-47b3-903c-8b847ca650c7/healthbench_paper.pdf
https://x.com/iScienceLuvr/status/1922013874687246756
文章来自微信公众号 “ 新智元 ”




【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
