# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,全球规模最大的单细胞基础大模型来了,而且是纯国产!
近日,中山大学杨跃东教授团队联合重庆大学、华为、新格元生物科技,研发单细胞基础大模型CellFM,成果发表在Nature Communications上。

该模型整合了超1亿人类单细胞数据,构建了8亿参数的深度学习框架,在生物表征学习和跨数据集泛化能力上取得重大突破,成为全球规模最大的单细胞基础大模型。
模型训练对算力和存储资源要求极高,得益于国家超算广州中心“天河星逸”超算系统以及华为国产芯片的有力支持,团队快速实现了CellFM的高效训练与优化。
CellFM的成功构建为通用型单细胞基础模型开发提供了新范式,有望加速单细胞组学在多场景中的应用拓展,推动生命科学与智能计算的深度融合。
研究团队还表示,为推动科研合作,将公开CellFM的代码和预训练模型,为研究者提供统一框架。

杨跃东,中山大学计算机学院教授、国家超算广州中心总工程师, 国家级青年人才,主持基金委重大专项课题、国家重点研发课题等重大项目。作为第一/通讯作者发表100多篇论文,谷歌学术总引用超1万次,近三年连续入选斯坦福大学发布的年度全球前2%最有影响力科学家,目前主要研究融合超算和智算的多尺度生物信息计算方法,并基于“天河二号”开发一站式生物医药超算平台。
单细胞测序技术能够以前所未有的精度解析每个细胞的基因表达特征,揭示细胞间的异质性。
然而,当前单细胞数据分析仍面临数据噪声大、批次效应强、数据稀疏等挑战,亟需建立统一的细胞状态表征模型。
为解决这一问题,近年来研究者开始尝试基于海量数据训练单细胞基础模型,但现有的人类细胞基础模型仍受限于训练数据规模和参数量的不足。
为突破这一困境,杨跃东教授联合团队整合公开的人类单细胞转录组开源数据,经过筛选、清洗、均一化等预处理流程,构建了目前已知最大规模的高质量训练数据集(>1亿细胞)。
基于这一庞大数据集,研究团队创新性地开发了8亿参数的单细胞大模型CellFM,其规模为当前单一物种大模型的8倍。
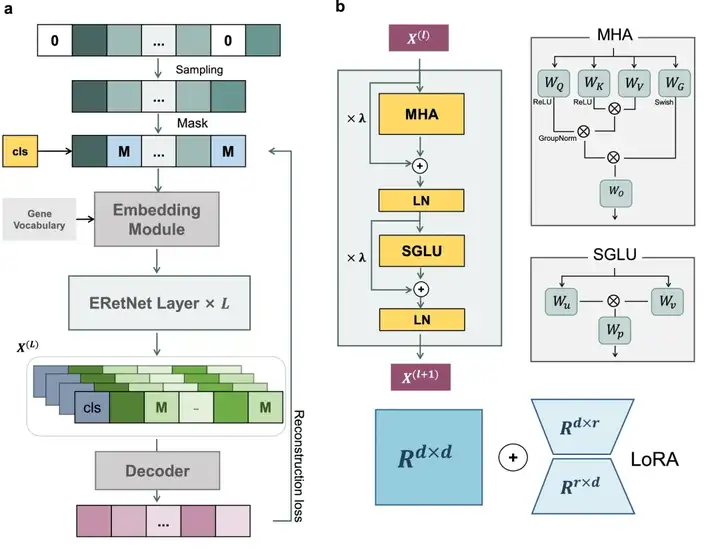
图:CellFM框架概述
CellFM汇集了来自各公共数据库的约2万份样本,涵盖多种组织、疾病状态及测序平台。这些数据经过新格元SynEcoSys®数据库的标准化处理,并基于华为MindSpore AI框架开发,训练时使用了四台华为Altas800服务器,每台服务器配备8个Ascend910 NPU。
实验表明,CellFM在包括细胞注释、扰动预测和基因功能预测在内的各种单细胞下游应用中,性能均显著优于现有模型。
大量实验结果表明,预训练完成后的CellFM在各项单细胞下游零样本任务中表现均优于现有模型,如scGPT和scFoundation等。
基因功能预测是生命科学研究的基础,其精准性和效率直接影响疾病机制解析、药物靶点发现及合成生物学设计等关键领域的发展。
传统的生物学研究需要大量实验,而CellFM大模型通过虚拟预测,能够快速锁定功能靶点,依靠“计算先行、实验验证”,构建AI for Science高效研究新范式。
CellFM可以对不同生物学功能的基因进行准确分类,在三种二分类问题中准确率(Accuracy,缩写ACC)都位列第一,如剂量敏感性任务较UCE和scGPT分别提升5.68%和5.86%,且UMAP可视化显示出更清晰的基因簇分布。
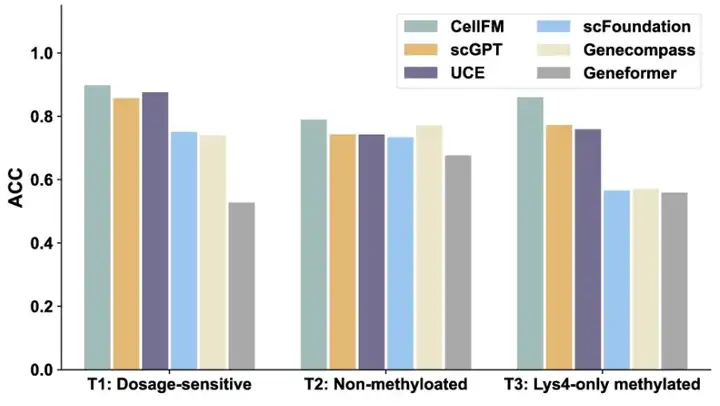
图:各模型在3种基因功能二分类任务中的ACC对比。CellFM在3种任务中都获得了最高的ACC
扰动响应/靶点基因预测通过解析基因调控网络对扰动的动态响应,为精准药物研发、个性化治疗及合成生物学设计提供分子靶标和机制依据。
CellFM能够模拟细胞对基因敲除、过表达或药物处理的响应,快速筛选潜在的药物作用或基因调控结果。
用CellFM的基因嵌入向量替换经典扰动模型GEARS的嵌入向量,在Adamson和Norman数据集上,差异基因变化的Pearson相关系数在所有对比模型中最优。
CellFM还能够根据扰动反向预测靶点基因,例如基于疾病样本中的异常细胞,逆推出可能导致该表型的关键基因或药物靶点。CellFM反向扰动预测的Top10命中率比scGPT高18.1%;且Top3命中率达到了scGPT的2倍,显著提升寻找靶点基因的效率。
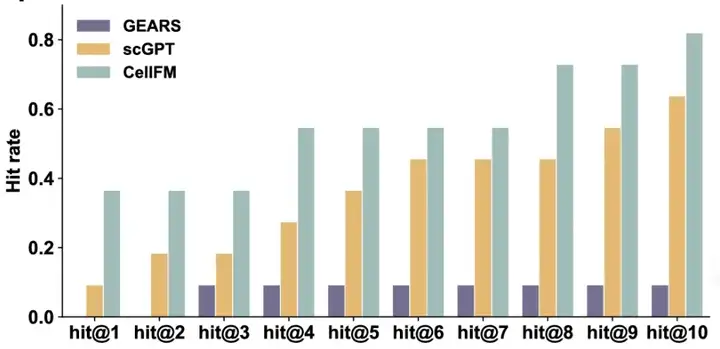
图:各模型扰动靶点基因预测命中率。CellFM的Top1-Top10命中率均领先其他模型
细胞类型注释是单细胞测序分析的关键环节,其准确性直接影响细胞图谱构建、疾病异质性解析以及发育轨迹推断等下游研究的可靠性。
CellFM能够对新样本进行高精度、低门槛的细胞注释,极大减少人工标注成本。加速未知细胞群的识别与功能探索,为药物筛选中发现关键响应细胞群奠定基础。
CellFM对同批次和跨批次数据都可以精确注释,ACC均位列所有对比模型榜首。如免疫数据集中,CellFM能准确预测大多数类型,而scGPT仅能预测主要类型。
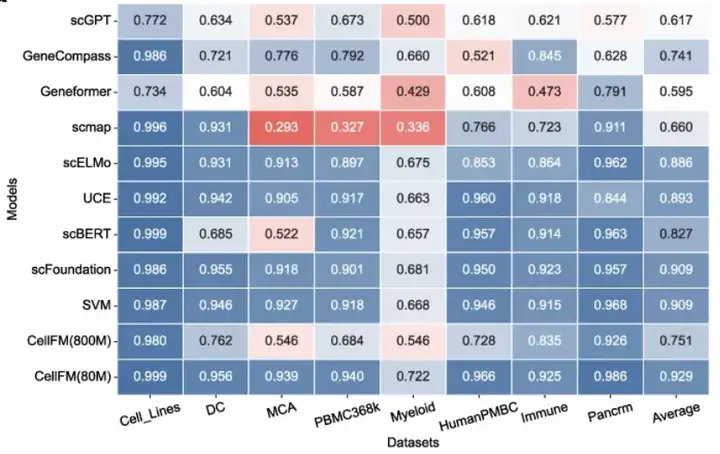
图:各模型对同批次数据集的细胞类型注释准确率热图
在跨批次数据中,CellFM也能够显著抵抗批次效应,保障结果一致性,提升候选靶点验证效率和可靠性。
CellFM是国产芯片训练大模型的一个成功案例,也是我国生物智能计算领域的重要研究进展,为精准医疗和药物研发提供了智能化新引擎。
未来,单细胞大模型将进一步揭示肿瘤微环境、免疫细胞状态等动态变化,为癌症、自身免疫病等复杂疾病的精准分型提供新标准。
单细胞大模型还有望快速筛选疾病特异性细胞亚群中的关键基因或通路,缩短靶点发现周期。并模拟人类生理系统反应,预测不同治疗手段在患者体内治疗效果,减少临床失败风险,降低药物开发成本。
文章来自微信公众号 “ 智药局 “




【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
