# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
语言模型究竟是如何感知时间的?如何利用语言模型对时间的感知来更好地控制输出甚至了解我们的大脑?最近,来自华盛顿大学和艾伦人工智能研究所的一项研究提供了一些见解。他们的实验结果表明,时间变化在一定程度上被编码在微调模型的权重空间中,并且权重插值可以帮助自定义语言模型以适应新的时间段。
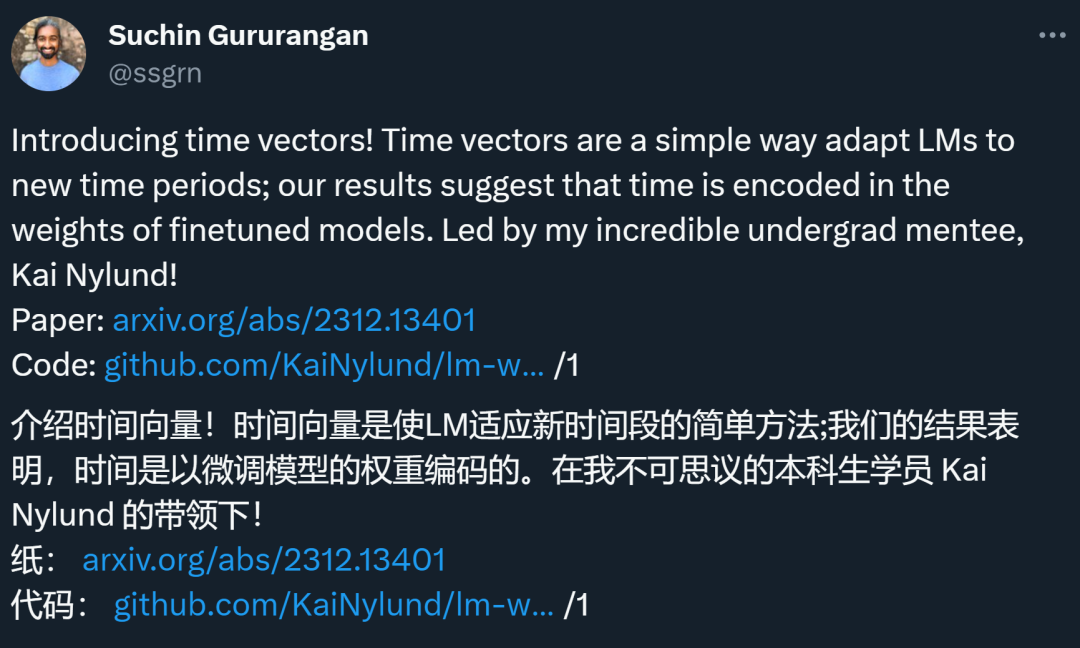
具体来说,这篇论文提出了时间向量(time vectors)的概念,这是一种让语言模型适应新时间段的简单方法。论文发布后立即引起了一些研究者的注意。新加坡海事智能公司 Greywing 联合创始人、CTO Hrishi Olickel 称赞这篇论文是他今年读过最好的论文之一。

他将本文的核心步骤概括为:
权重差值此时可以作为一种向量,用于探索模型在这段时间内学到了什么。那么具体来说能用这个向量做些什么呢?
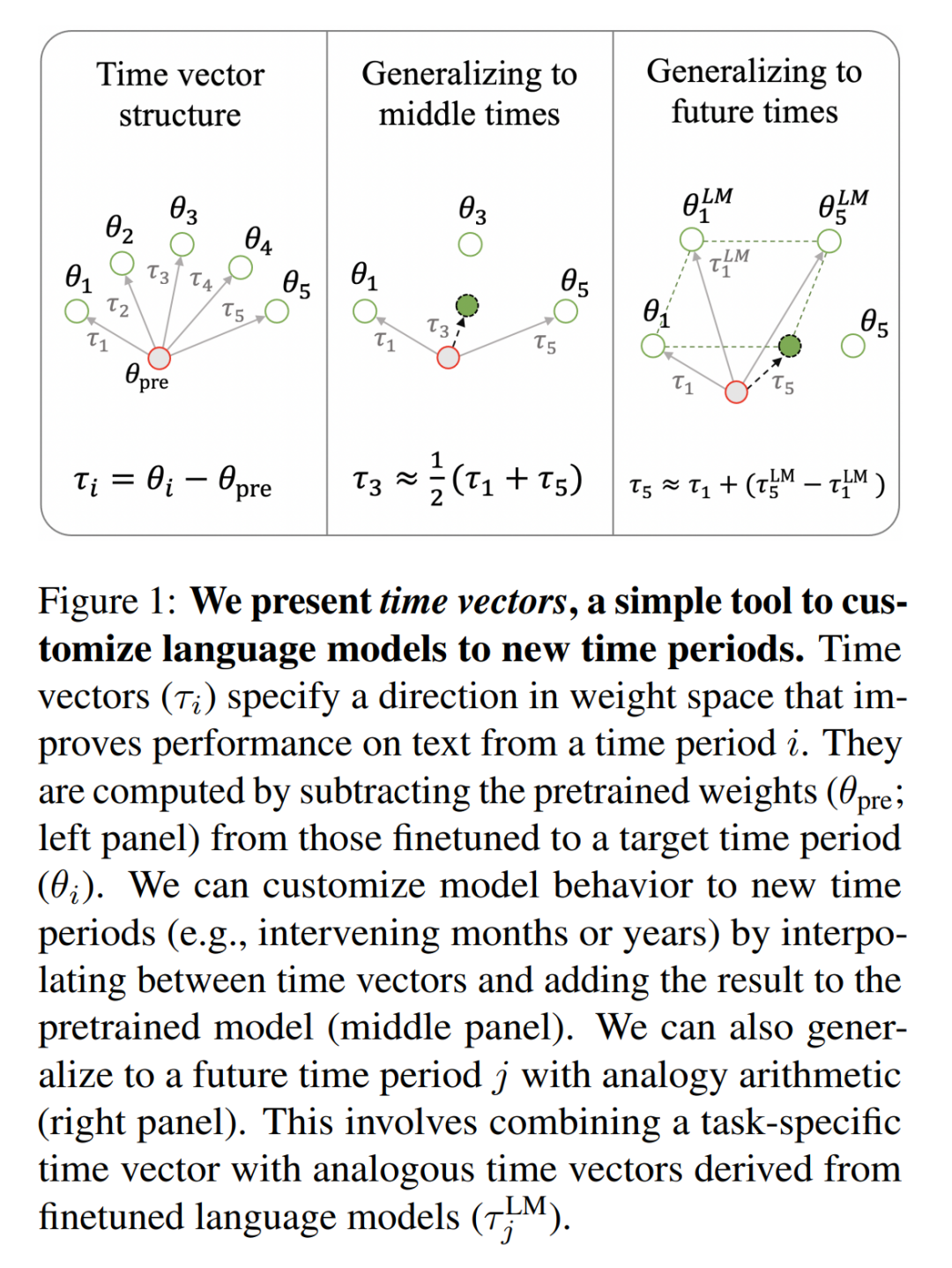
首先,可以检查微调是否有效 —— 从结果来说微调确实有效。模型困惑度和 F1 值强烈表明,当输入的数据符合微调后的时间时,任务性能有相应的提高!
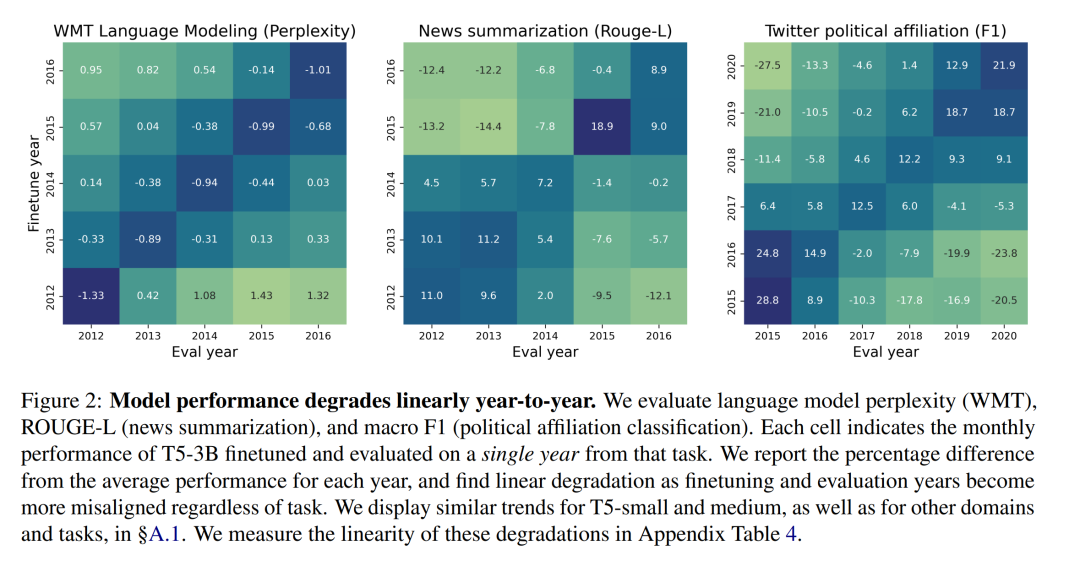
同样有趣的是,随着训练数据时间的推移,模型的性能呈线性下降。这一点在月份粒度和年份粒度上的结果都是如此。同时在特定月份训练的模型在同年其他某几个月份的表现也会相对较好(如下图中的对角线条纹现象)。
Hrishi Olickel 猜想这是由于语义上存在的相似性(相同的月份名称),不是因为模型产生了深层次的理解。并且如果能研究一下不同模型对应层之间的差值有多大,也许就能知道这种影响有多深。同样有趣的是向量的组织方式。
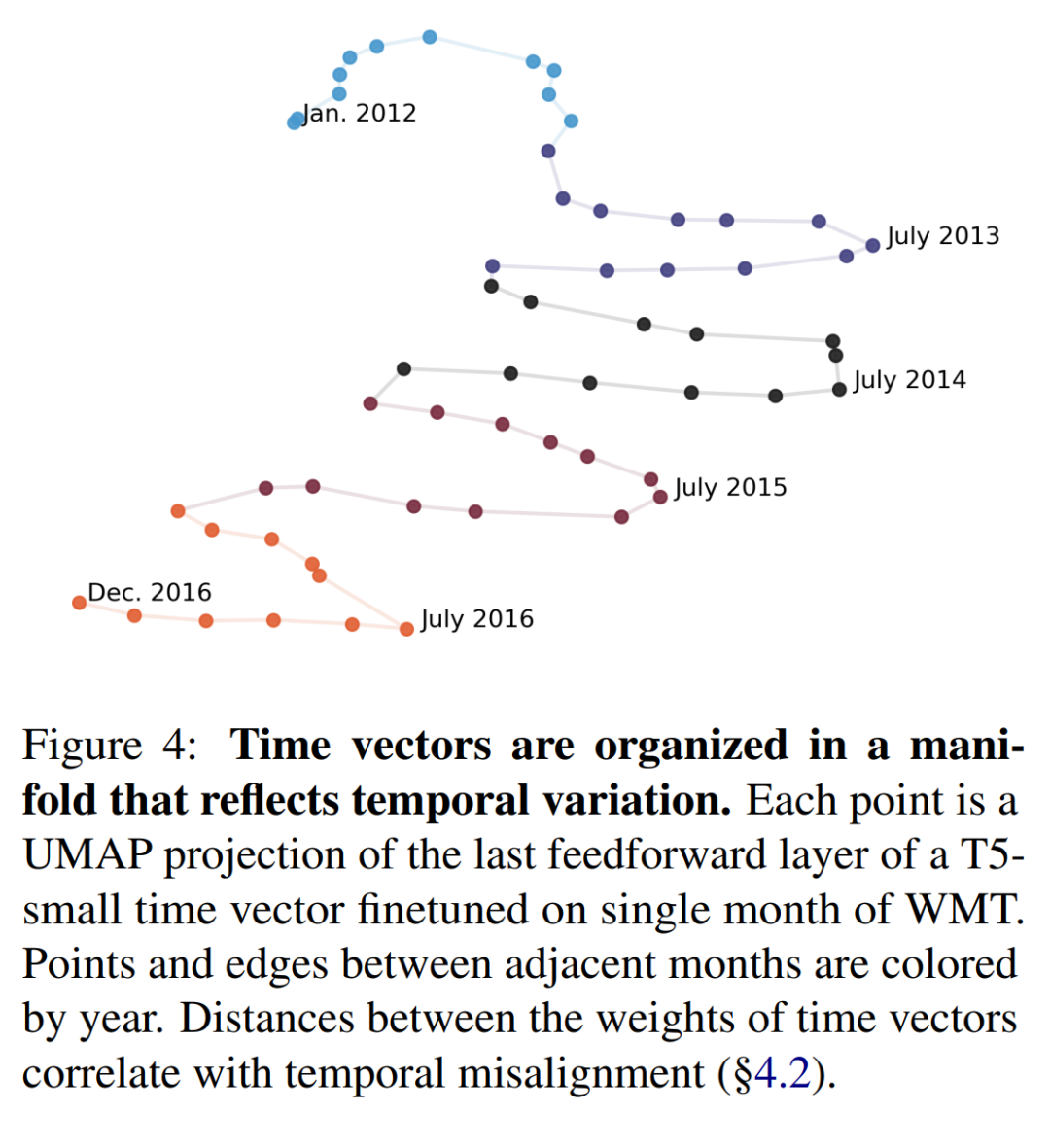
Hrishi Olickel 认为能够提出一个存在内部时间的模型,是相当惊人的。人类到现在都不知道时间是如何在大脑中工作的,但如果我们是语言驱动的学习者(如 LLM),而「意识」是一个内心里循环启动的「进程」,那么人和 LLM 可能会有相似之处。
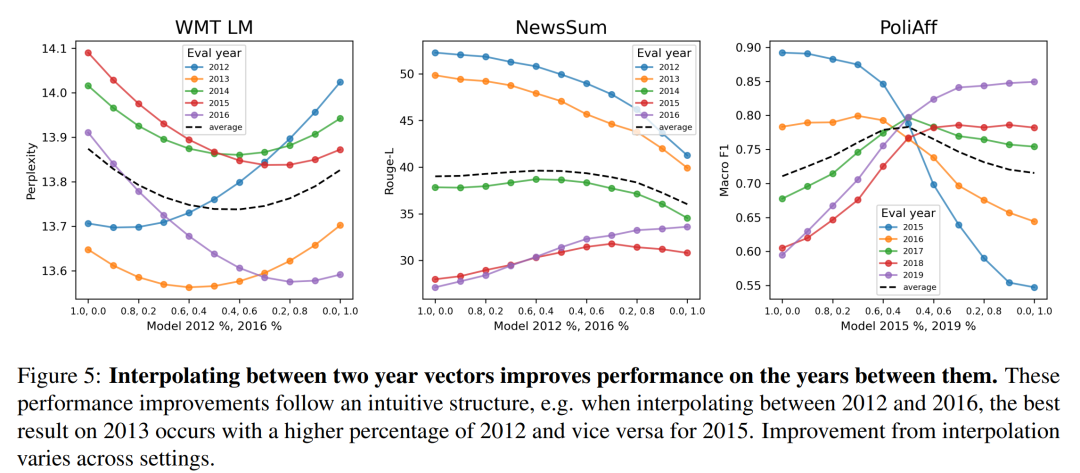
更有趣的地方在于,有了这些向量之后,就可以在它们之间进行插值,从而在没有进行微调的年份也获得较好的性能!向量之间的插值是简单的算术运算 —— 系数加法。


与之前的基于任务进行训练得到的模型权重向量一样,这种插值方法可能是在找出真正的迁移学习之前,可行的训练方法之一。如果能从微调中进行插值,就能对模型输出进行精细且低成本的控制,省去微调的成本和时间。
基于此,Hrishi Olickel 提出了几个猜想:

Hrishi Olickel 认为这个章节非常有趣。从这段文字中不能确定他们的意思是否是交换权重时只交换插值,如果是并且能奏效,那就太棒了。
Hrishi Olickel 表示,对人工智能(至少是基于语言模型的人工智能)的新理解来自于我们能够实时编辑和利用这些模型权重的能力 —— 他强烈怀疑(或希望)其中一些能力将帮助我们理解人类的大脑。
以下是论文的具体内容。
时间变化是语言的一个基本特征。正如本文第 3 章中所提到的,时间变化在语言模型开发中表现为时间错位(temporal misalignment),即训练数据和测试数据的时间偏差会导致模型在时间段不同的情况下性能大幅下降。这就需要采用适应技术,根据需要定制特定时间段的模型。然而,由于时间尺度众多,而且可能无法获得目标时间段的数据,因此设计此类技术十分困难。
最近的研究表明,神经网络的行为可以通过微调模型参数之间的闭式插值进行编辑。本文证明了权重空间的插值也可用于低成本地编辑语言模型,创造模型在不同时期的行为。
在第 4 章中,本文引入了时间向量,作为任务向量的扩展(参见论文「Editing Models with Task Arithmetic」)。即在单个时间段的文本上对预训练的语言模型进行微调后,减去原预训练模型的权重,得到一个新向量。这个向量代表了权重空间的移动方向,可以提高模型在处理目标时间段文本时的性能。
在第 2 章中,本文利用按时间组织的数据集分析时间向量的结构,用于语言建模、分类和总结。研究结果一致表明,时间向量直观地分布在一个流形上;在时间上更接近的年份或月份产生的时间向量在权重空间上也更接近。同样,在 4.2 节中,本文还表明,年度和月度中的时间退化问题与时间向量之间的角度密切相关。
本文利用这种时间向量结构来引导模型,使其更好地覆盖新的时间段的数据。通过在两个时间向量之间进行插值,可以产生新的向量,这些向量应用到预训练模型时,可以提高模型在间隔月份或年份中的性能(第 4.3 节)。该结构还可用于跨时间段泛化特定任务模型,并使用专门用于未标记数据的类似时间向量(第 4.4 节)。
本文的研究结果表明,微调模型的权重空间在一定程度上对时间变化进行了编码,权重插值可以帮助定制语言模型以适应新的时间段。本文作者开源了论文的代码、数据和超过 500 个根据特定时间段微调的模型。
以年为单位的模型线性性能退化
之前关于时间错位的研究表明,模型会随着时间逐年退化。
为了证实这些结果,本文在每个数据集的每个年度分段上对 T5-small、T5-large 和 T5-3b 进行了微调。然后,在测试数据的每个其他时间分段上对这些经过调整的模型进行评估。
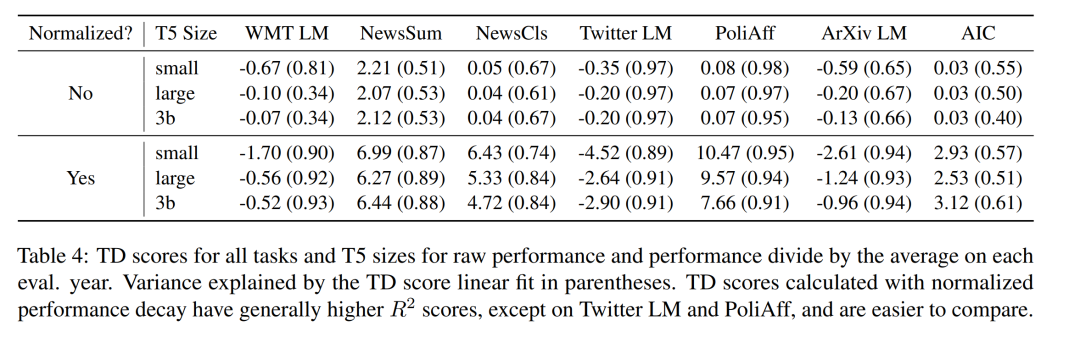
图 2 中以年为单位展示了时间错位热图,以及与年平均值相比的困惑度变化百分比(避免固有的年度性能差异)。与之前的研究结果一致,本文观察到每个任务中都存在着线性退化的特点,无论模型的大小(更多详情请参见表 4)。与 早先研究结果一样,有些任务(如政治派别分类)的退化比其他任务更明显。原文附录中的 §A.2 中会对这些差异进行量化。
以月为单位的模型非线性性能退化
接下来,本文介绍了按月为单位的时间错位问题。这个问题尚未得到探讨。论文作者在 2012-2016 年间的 WMT 数据集上,按月份分段,并训练了 T5-small,从而得到了 58 个经过月份分类的模型。然后,在这些按月拆分的多个模型上,总共进行了 3,364 次验证实验。
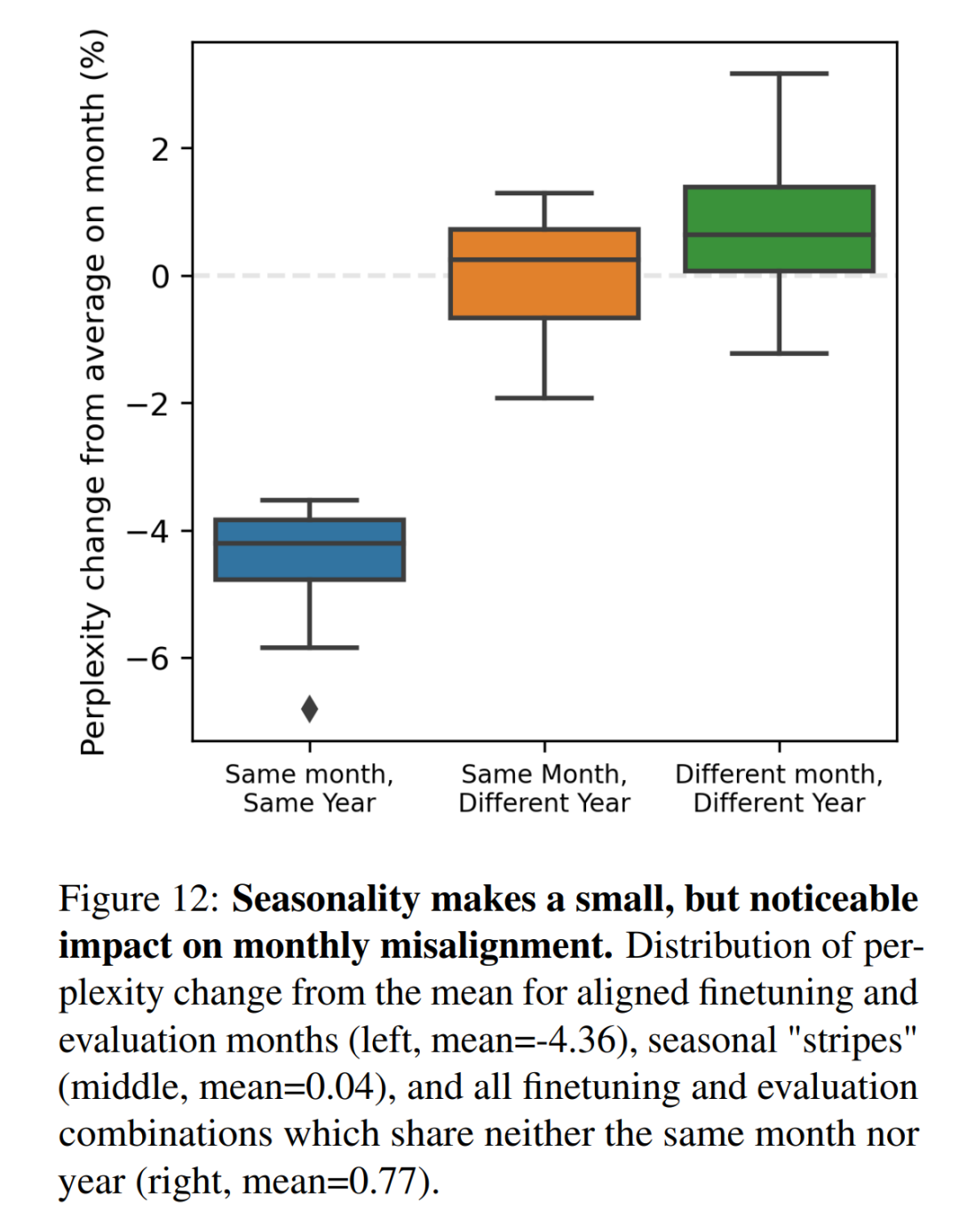
如图 3 所示,在 WMT 数据集的特定月份上对模型进行微调和评估,可以发现时间错位的非线性模式,与每年的月份周期相对应。每隔 12 个月出现的平行于对角线的条纹可以捕捉到这种模式,这表明特定月份的模型在其他年份的相同月份往往表现更好。本文在附录图 12 中量化了这些困惑度差异。还在 §A.4 中总结了线上训练设置中的模型退化模式。
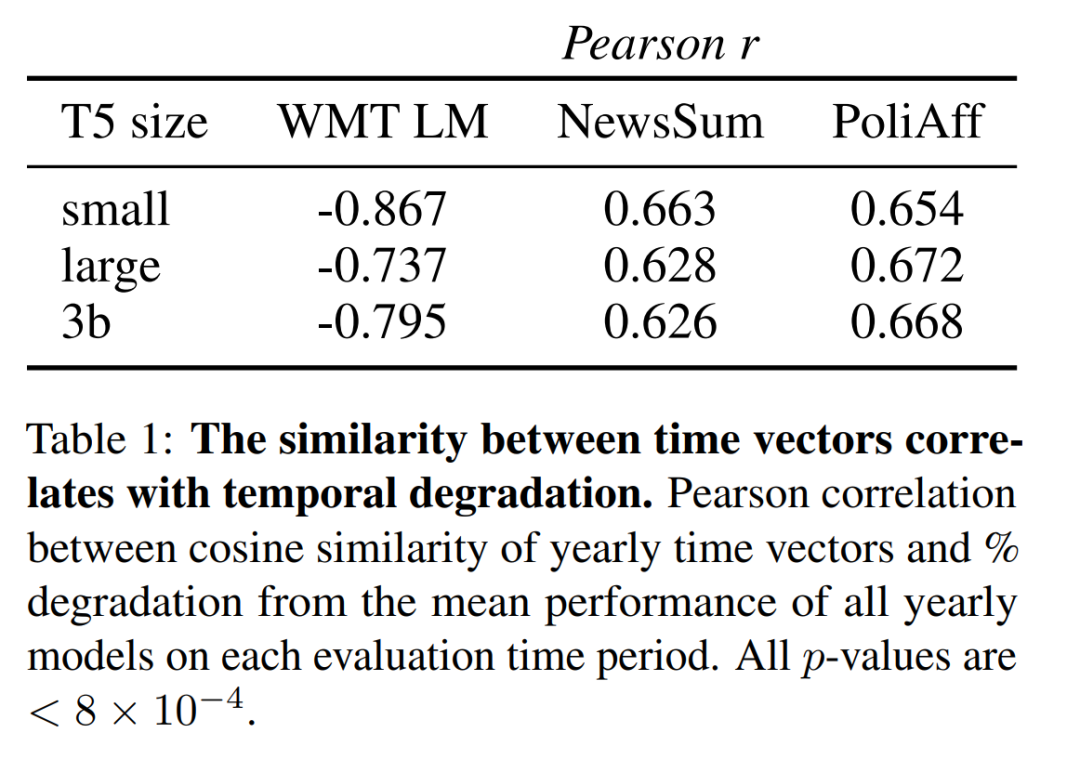
时间向量相似度与时间退化的相关性
本文在图 4 中用 UMAP 对时间向量进行了可视化,这表明在权重空间中更接近的时间向量在时间上也更接近。为了验证这一假设,本文测量了在不同时间段训练的每对时间向量的模型权重之间的余弦相似度(见附录第 A.1 节)。
本文的结果显示,这一相似度指标和性能(图 11)随着时间的推移,存在相似的衰减。
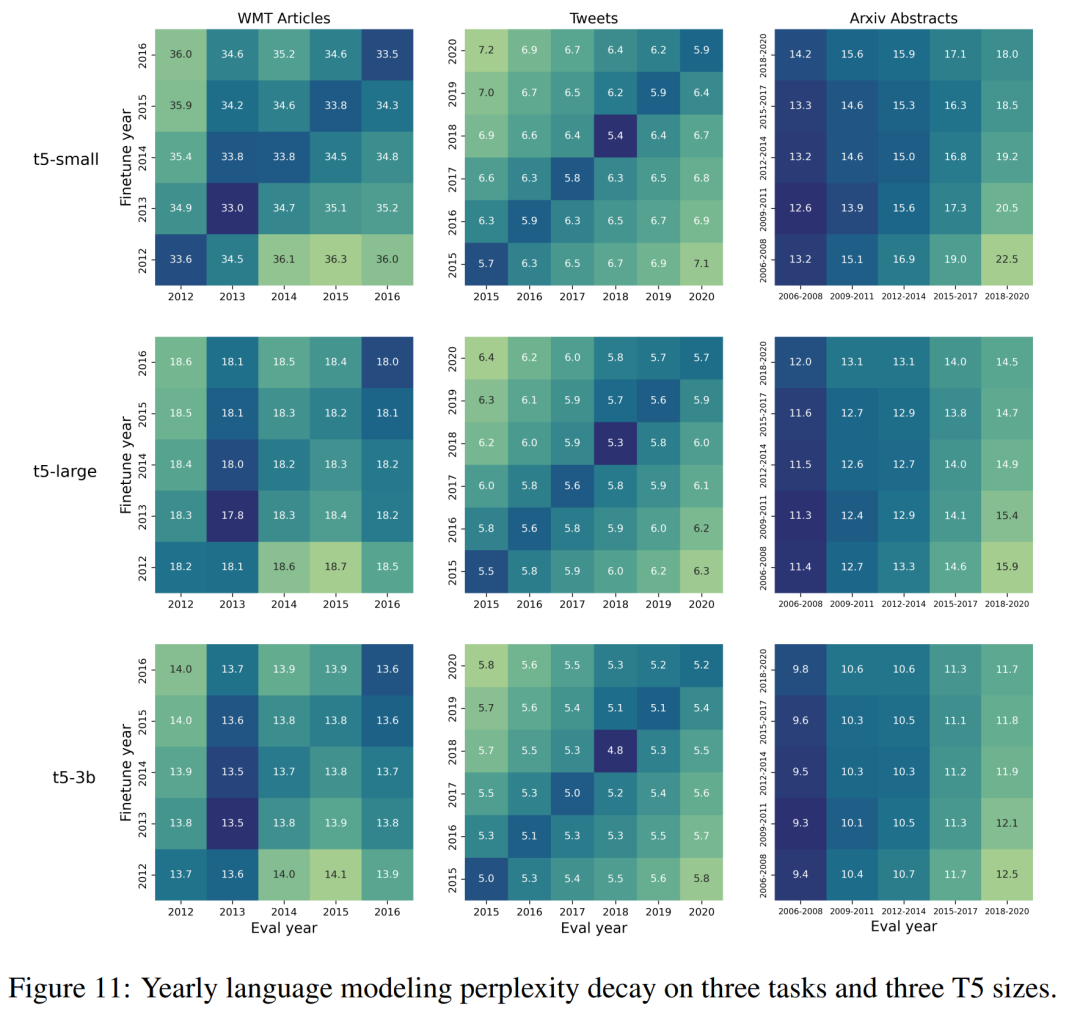
表 1 显示,余弦相似度与不同年份相对性能变化之间的相关性在 WMT 语言建模中最高。同时,这种相关性在不同规模的 T5 中也基本相似,在 WMT LM 中,T5-small 的得分高于 T5-large 和 T5-3b,且绝对值均不低于 0.6。
这种关系也延伸到按月划分的尺度下。在两两月度之间, WMT 时间向量的余弦相似度中可以看到周期性条纹(见附图 9)。与平均值(图 3)和余弦相似性矩阵(图 9)相比,月度性能下降呈负相关(Pearson r = -0.667; p < 10-16)。附录 A.5 中分析了整个在线训练过程中单年时间向量的余弦相似性。
这些结果表明,时间向量的组织方式可以预测其在相应时间段的表现。接下来将探讨如何利用这种结构,通过时间向量之间的插值来提高新时间段的性能。
对中间时间进行插值
存档问题或采样率低会导致数据集在最新和最旧示例之间出现间隙。在没有数据的情况下,由于时间上的错位,预计模型在这些 "间隙" 时间上的表现会更差。在本节中,可以发现通过对最新和最旧时间的模型进行微调,可以更好地让模型适应这些时间段。
方法
对于两个时间矢量 τ_j , τ_k, 计算它们的插值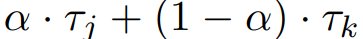 。本节在最早年份时间向量 τ_0 和最晚年份时间向量 τ_n 之间进行内插,并对每个 α∈[0.1, 0.2, ..., 1.0] 的时间 t_0, ..., t_n 进行验证。
。本节在最早年份时间向量 τ_0 和最晚年份时间向量 τ_n 之间进行内插,并对每个 α∈[0.1, 0.2, ..., 1.0] 的时间 t_0, ..., t_n 进行验证。
结果
如图 5 所示,在 WMT LM 和 PoliAff 任务中,在起始年和结束年微调模型之间进行内插可以提高中间年份的性能。一般来说,中间年份(WMT LM 为 2014 年,PoliAff 为 2017 年)的改进幅度最大,而在更接近起始和结束时间的年份,改进幅度则会减小。不同设置下的改进模式也不尽相同,与 WMT LM 相比,PoliAff 在 α = 1.0 和 0.0 附近的性能变化更为平缓,而 NewsSum 在不同 α 之间的改进与验证年份之间的性能差异相比微乎其微。表 2 量化了这些变化,显示插值法缩小了时间对齐模型和错位模型之间的差距。PoliAff 的改进尤为显著,仅平均值就提高了近 8 个 macro-F1 百分点。
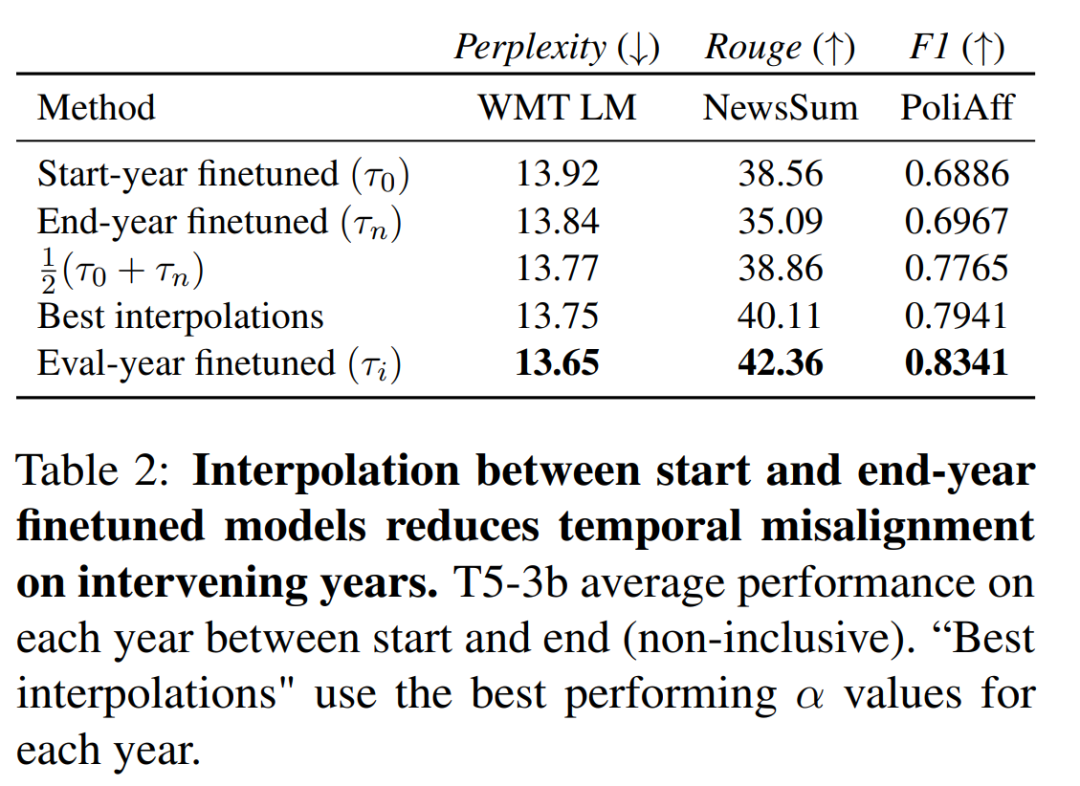
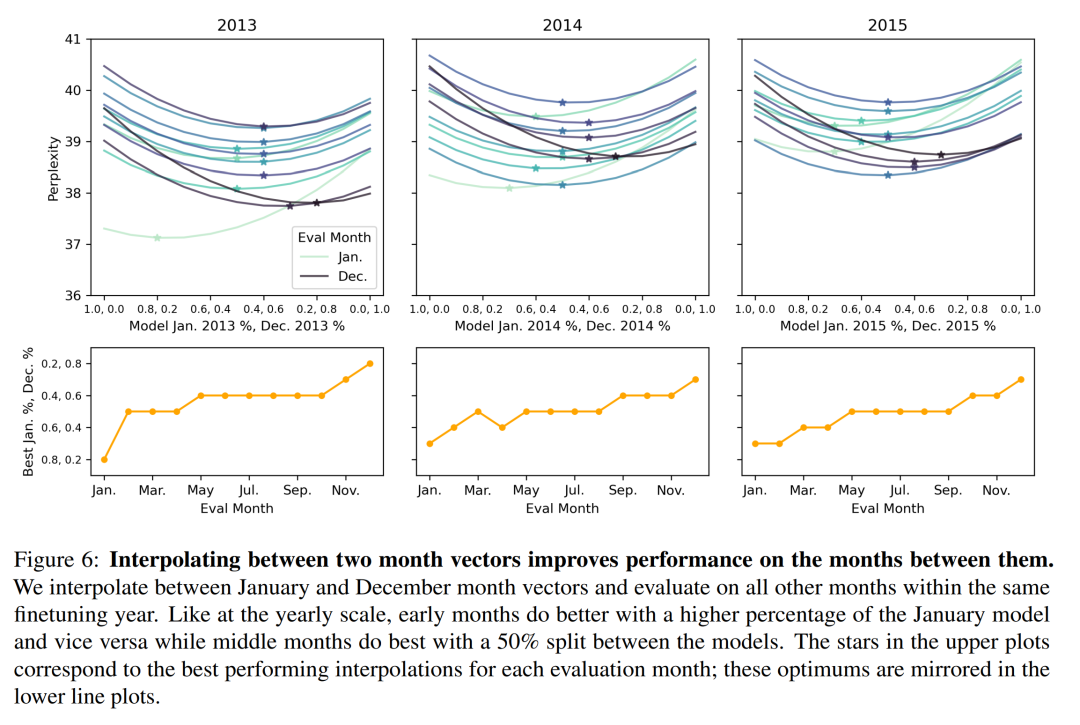
图 6 显示,这些结果扩展到按月划分的 WMT LM 后;可以在一年内 1 月和 12 月确定的时间向量之间进行插值,以提高这几个月的模型表现。每个月的最佳插值遵循一个直观的模式,1 月份模型的百分比越高,会导致前几个月的性能更好,反之亦然。
生成未来的时间模型
标注数据集创建于过去,因此,依赖监督进行微调的语言模型很快就会过时。更新这些模型的成本可能很高,需要进行额外的微调,还需要从更多最新的文本中创建标注数据集。本节将介绍一种新技术,使用任务类比算法,将在源时间段 j 上微调过的任务模型,更新至目标时间段 k,并且只包含 j 中未标记数据。
方法
给定语言模型,其权重![]() 、
、![]() 是根据 j、k 时间段的未标注文本微调的,而任务特定模型的权重 θ_j 是根据 j 时间段的标注数据微调的,对向量进行如下运算:
是根据 j、k 时间段的未标注文本微调的,而任务特定模型的权重 θ_j 是根据 j 时间段的标注数据微调的,对向量进行如下运算:
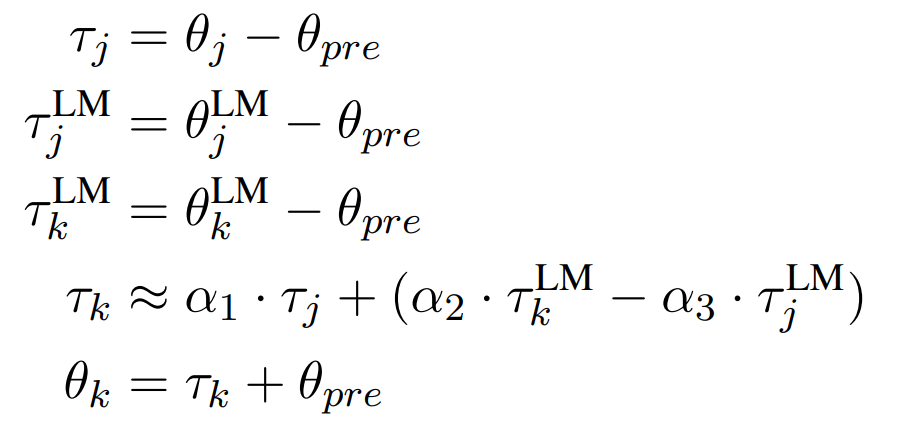
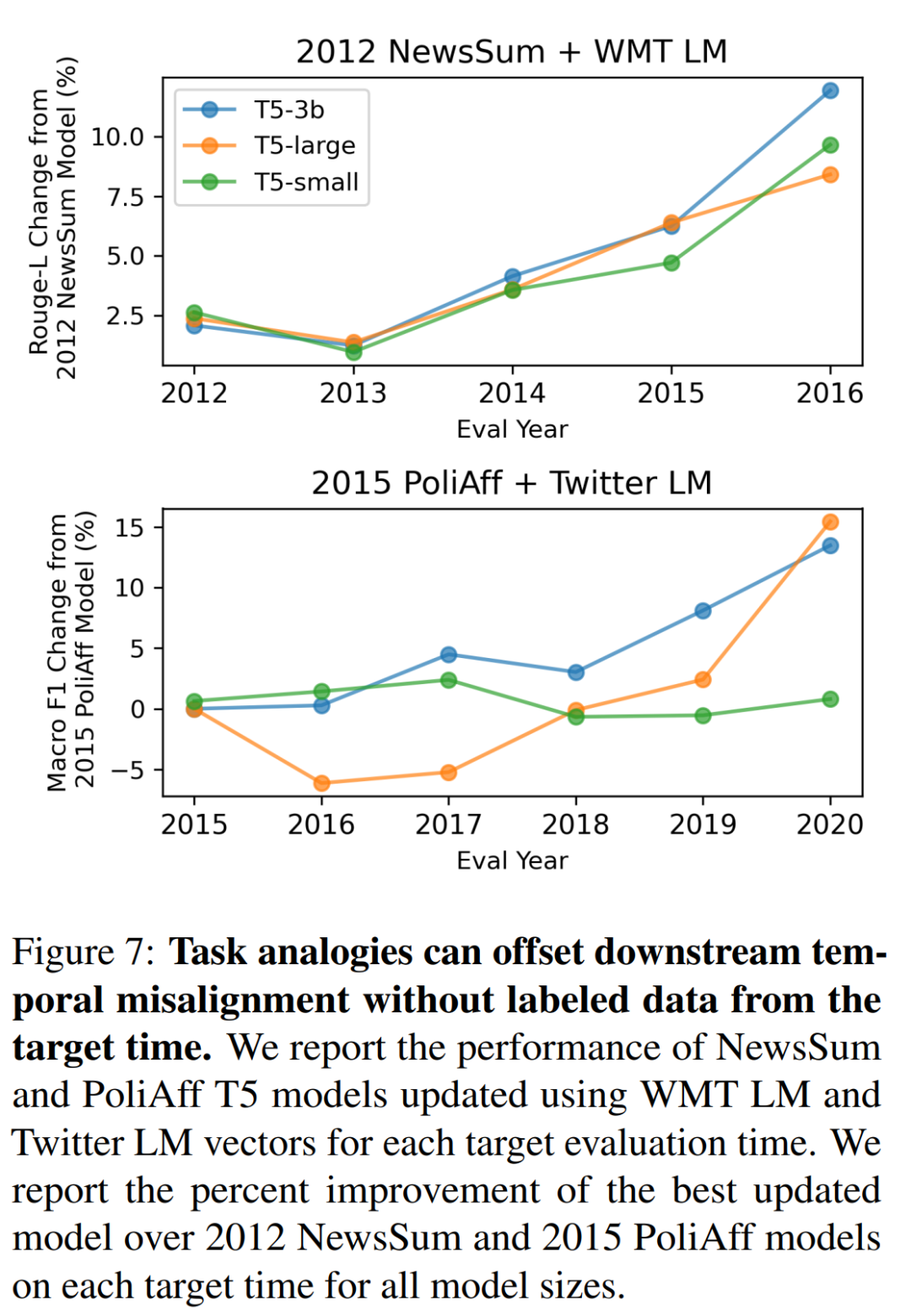
本文在每个目标时间 t_k 上验证估计的 θ_k,遍历 α_1 ∈ [0.6, 0.8, . . 2.2]、α_2、α_3 ∈ [0.1, . . 0.6] 的所有组合,并报告与原始模型 θ_j 相比的最佳结果。本节使用 WMT LM 和 Twitter LM 时间向量,分别将 2012 年的 NewsSum 模型更新为 2013-2016 年,将 2015 年的 PoliAff 模型更新为 2016-2020 年。
结果
任务类比算法提高了 PoliAff 和 NewsSum 任务在未来年份的性能。图 7 显示,随着目标年份和起始年份的错位越来越大,与起始年份的微调相比,改进幅度也越来越大。模型大小也会影响性能,T5-large 和 T5-3b 的改进幅度更大。在 PoliAff 中,T5- small 与基线相比没有改善,而 T5-large 任务类比在 2016 和 2017 年的表现比基线差,在 2019 和 2020 年才有所改善。奇怪的是,作者发现只是缩放 α_1 也能提高模型完成未来几年任务的性能。附录 A.6 中报告了 α 消减和其他两个分类任务的结果。在这些任务中,研究者观察到的结果大多相似,但也有因任务而异的不一致之处。
更多细节请参见原论文。
文章来自于 微信公众号“机器之心”


【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
