# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在人类的认知过程中,视觉思维(Visual Thinking)扮演着不可替代的核心角色,这一现象贯穿于各个专业领域和日常生活的方方面面。
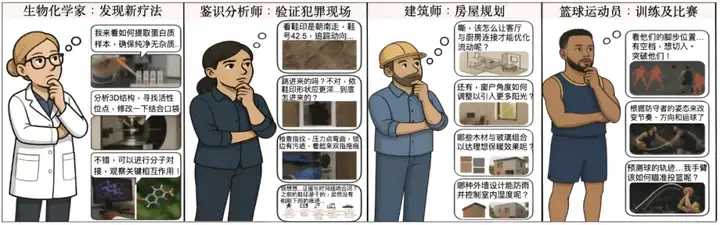
图 1:需要借助「脑补」图像进行思考的真实世界任务。这些任务通常需要视觉预见性和想象力,仅凭基于文本的思考无法完全实现。
生物化学家在探索新的治疗途径时,会在脑海中构建蛋白质的三维立体结构,通过视觉化的分子间相互作用来理解复杂的生化过程;法医分析师在破解疑难案件时,需要在心中重建犯罪现场的空间布局,通过视觉推理来验证证据之间的逻辑连接;建筑师在设计创新建筑时,会在脑海中不断勾勒和修正建筑草图,通过视觉想象来优化空间配置和光照效果;篮球运动员在制定战术策略时,需要在脑海中构想队友的跑位路线、防守阵型的变化以及关键时刻的战术配合,通过视觉化的场景想象来设计最佳的进攻方案;在日常决策中,一般人也会通过「脑补」各种可能的场景图像来辅助判断和选择,用脑海中自发生成的图像作为认知媒介。
这种视觉思维能力的独特之处在于,它能够创造概念间的独特组合和新颖连接,帮助我们发现仅通过纯文本推理无法获得的洞察和创意。而在现代认知科学中,这种「深思熟虑」往往需要多模态的思维过程来支撑。
如今,AI 也迈出了这一步:上海交通大学、上海创智学院、复旦大学和 Generative AI Research Lab(GAIR)的团队提出 Thinking with Generated Images,让大模型能够自发生成视觉中间步骤,像人类一样用「脑内图像」进行跨模态推理。

如何让模型自发性地通过视觉进行「思考」仍属于早期探索阶段。此前的一些工作尝试通过空间搜索任务(如迷宫导航)进行早期探索,但这些任务的局限性在于它们往往可以直接通过文本思考或「对着」图像思考(Thinking with Images)来解决,而不需要真正的「脑补」图像思考(Thinking with Generated Images)。
Thinking with Generated Images 系统性地整理并比较了三个核心概念的本质区别及其适用任务的差异:
研究团队特别强调,「脑补」图像思考在需要空间想象、动态规划和创造性视觉构建的任务上相比于纯文本推理具有根本性优势,这正是人类视觉思维的核心价值所在。

图 2:区分「看」图像、「对着」图像思考、「脑补」图像思考的例子。
研究团队创新性地提出了「原生多模态长思维过程」(the native long-multimodal thought process)这一核心技术框架实现「脑补」图像思考。原生多模态长思维过程由交错的多模态 token 组成:包括文本的词汇或子词(words/subwords)、视觉的图像块(patches)等。
未来有更通用的基座模型后也能推广到音频的帧(frames),以及其他模态领域特定的表示形式(domain-specific representations)。原生多模态长思维过程不仅能够让模型在思维过程中自然地自发生成图像,还能够原生地执行测试时扩展(test-time scaling)以获得更好的模型能力。透过原生多模态长思维过程实现 Thinking with Generated Images 有四大主要优势:
研究团队深入分析人类多模态长思维的认知模式,据此设计并提出了两种原生多模态长思维链模式,应用于视觉生成任务上,最大的体现 Thinking with Generated Images 的优势:

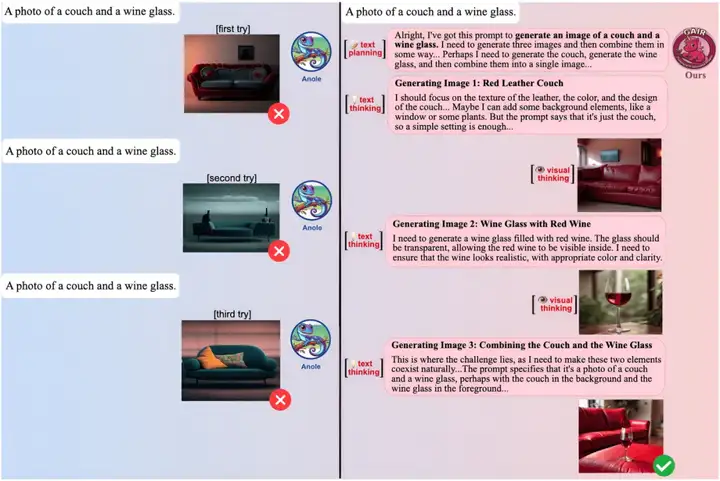
图 3:原生多模态长思维链在GenEval上的例子。


图 4:原生多模态长思维链在DPG-Bench上的例子。
研究团队选择在自回归 next-token-prediction 的多模态统一理解生成模型上开发原生多模态长思维链,这一决策基于几个层次的技术考虑:
在确定了自回归架构的技术路线后,团队选择 Anole 作为基础模型。目前大多数模型都缺乏真正的交错多模态生成能力,而这正是实现「原生多模态长思维过程」的关键技术瓶颈。Anole 相比其他多模态模型具有两个关键优势:
研究团队提出的「原生多模态长思维过程 (the native long-multimodal thought process)」这一核心技术框架实现「脑补」图像思考。与现有方案对比,该提出方案解决了五大局限:
Thinking with Generated Images 带来的能力属于全新维度,可与现有技术叠加协同。该研究着重提升的是「内部想象-反思」的深度推理能力,而检索增强、外部工具调用等技术,仍然在引入外部知识、扩展功能等方面具备优势。
未来,当这些能力并行叠加时,既能利用 Thinking with Generated Images 提出的「脑内草图」,也能借助现有检索增强、外部工具调用等技术,形成 1+1>2 的整体效果。
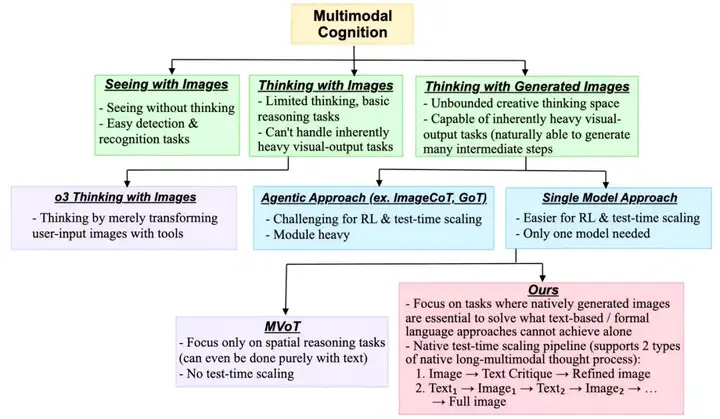
图 5:多模态认知领域相关工作的对比
为了在多模态理解生成模型上实现 Thinking with Generated Images 的自发原生多模态长思维链,研究团队在训练数据、训练策略、以及推理策略上都有深入的探索。
研究团队精心设计了一套合成数据构建流程,专门用于训练模型生成两种类型的多模态长思维链。由于目前没有现成的 LMM 模型支持多模态生成的测试时扩展 (test-time scaling),传统蒸馏技术并不适用,团队创新性地开发了完整的数据构建管线(如图 6 所示)。
数据收集三大黄金法则:
最后通过 QVQ-72B-Preview 进行严格的质量控制,过滤与提示严重偏离的样本。
技术亮点解析:
这一创新性的训练策略使得 LMM 模型能够生成端到端的多模态长思维链,为「Thinking with Generated Images」的实现奠定了坚实基础。这套方法论不仅适用于当前研究,也将为未来多模态推理系统的开发提供重要参考。
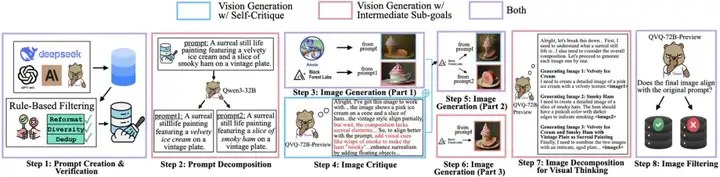
图 6:数据收集流水线示例
在使用统一多模态模型进行视觉生成任务的训练时,大多仅依赖交叉熵训练没有完整的考虑图像 token 之间的关系。
为了解决这个问题,研究团队引入了视觉特征级别的重建损失,将生成图像的隐状态投影回视觉特征空间,并计算与 ground-truth 图像对应特征之间的均方误差 (MSE) 损失。这种设计鼓励模型产生具有更强视觉连贯性和结构完整性的输出。基于优化后损失函数,研究团队设计了系统性的两阶段训练流程:
这种分阶段训练策略确保了模型既具备扎实的基础多模态能力,又能在特定的思维模式上表现出色。
与标准的视觉语言模型或大语言模型不同,统一多模态模型在进行视觉生成任务时面临着独特的推理挑战。为了充分发挥模型的性能潜力,无分类器引导 (Classifier-Free Guidance, CFG) 技术成为提升视觉生成性能的关键。在传统的完整条件 (full conditions)、无条件 (unconditions) 和图像条件 (image conditions) 基础上,研究团队增加了:
这种多条件设计的核心目标是促使中间视觉步骤更加忠实于原始意图,同时避免被生成的长文本思维过度干扰。通过在这些条件之间进行精细化平衡,模型能够:
研究团队在 GenEval 和 DPGBench 两个图像生成基准上对 TwGI-Anole-7b-Obj. 和 TwGI-Anole-7b-Crit. 进行了全面的性能评估。
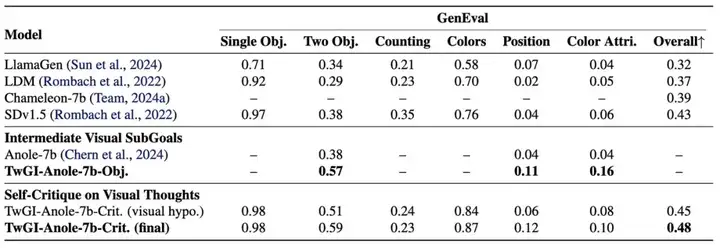
图7: 在GenEval上的表现
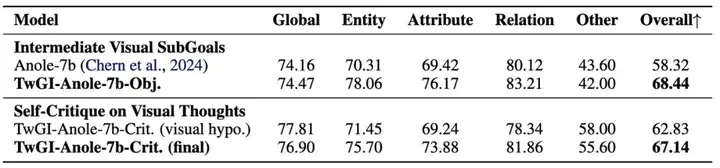
图8: 在DPG-Bench上的表现
实验结果表明,TwGI-Anole-7b-Obj 在 GenEval 和 DPGBench 两个基准上都始终优于基线模型 Anole-7b。在 GenEval 上,TwGI-Anole-7b-Obj 在「双对象」类别中取得了显著提升(0.57 vs. 0.38,相对提升 50%),表明其在处理涉及多个实体的复杂提示时具备了更强的能力。在位置和颜色属性对齐方面也显示出显著改进,体现了在精确空间和视觉构图推理方面的更强能力。
在 DPGBench 上,TwGI-Anole-7b-Obj 在「实体」、「属性」和「关系」类别中都取得了实质性进步,总体分数从 58.32 提升至 68.44(相对提升 17.3%),反映出其在细粒度视觉语义理解方面的增强能力。这些改进验证了我们的假设:将视觉任务分解为中间子目标使得大语言模型能够更系统地推理并生成更高质量的输出。
视觉思维自我批判的实验结果证明了让模型反思和修正自身视觉输出的有效性。TwGI-Anole-7b-Crit. 模型在自我批判步骤后性能显著提升:GenEval 总分从 0.45 提升至 0.48,DPGBench 分数从 62.83 提升至 67.14。这表明模型具备了内省分析生成图像的能力——通过基于视觉反馈的文本推理链,能够识别不匹配、幻觉或遗漏的元素,并随后进行纠正。这种视觉反馈循环的有效性反映了一种模态间协同效应,其中视觉和文本模态相互迭代指导,形成了真正的多模态智能推理机制。
这些结果共同验证:在推理链中主动「画草图」或「打草稿」,不仅让模型生成质量更高、更可控,也带来了深度理解与纠错能力。
Thinking with Generated Images 的能力未来有望推动 AI 在需要空间想象和动态规划的领域实现突破:
《孙子兵法》说:「多算胜,少算不胜,而况于无算乎?」在文本时代,深思靠文字组成的思维链;在多模态时代,深思就需要通过多模态内容的耦合,不仅要会观察、调用工具,还要学会想象、反思、脑补。Thinking with Generated Images 正在把这种能力「写进」模型本身,让 AI 获得人类的视觉想象力。
当机器从「看图说话」升级到「无图脑补」,真正的多模态推理时代,已敲响开场锣鼓,让我们拭目以待。
文章来自于“机器之心”,作者“机器之心”。




【部分开源免费】FLUX是由Black Forest Labs开发的一个文生图和图生图的AI绘图项目,该团队为前SD成员构成。该项目是目前效果最好的文生图开源项目,效果堪比midjourney。
项目地址:https://github.com/black-forest-labs/flux
在线使用:https://fluximg.com/zh
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
