# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
如何从一段视频中找出感兴趣的片段?时序行为检测(Temporal Action Localization,TAL)是一种常用方法。
利用视频内容进行建模之后,就可以在整段视频当中自由搜索了。
而华中科技大学与密歇根大学的联合团队最近又为这项技术带来了新的进展——
过去TAL中的建模是片段甚至实例级的,而现在只要视频里的一帧就能实现,效果媲美全监督。

来自华中科技大学的团队提出了一种名为HR-Pro的新框架,用于点标注监督的时序行为检测。
通过多层级的reliability propagation,HR-Pro可以网络学习到更具辨别力的片段级特征和更可靠的实例级边界。
HR-Pro包括两个可靠性感知的阶段,能够有效地从片段级别和实例级别的点标注中传播高置信度的线索,从而使网络能够学习到更具区分性的片段表示和更可靠的提议。
在多个基准数据集上进行的大量实验证明,HR-Pro明显优于现有方法,并取得了最先进的结果,证明了其方法的有效性和点标注的潜力。
下图展示了HR-Pro与LACP在THUMOS14测试视频上进行时序行为检测表现比较。
HR-Pro展现出更了准确的动作实例检测,具体来说:
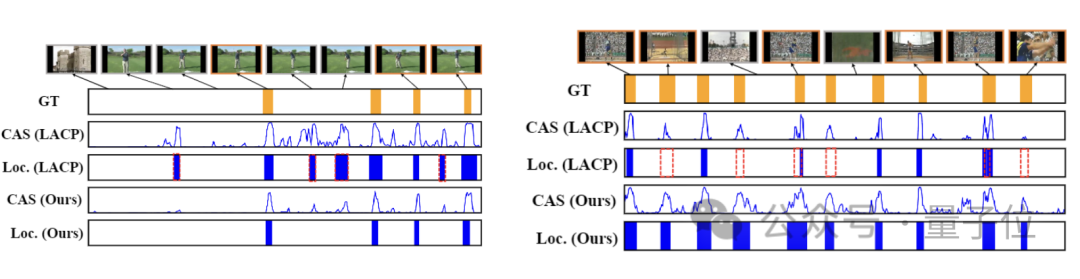
数据集上的测试结果,也印证了这一直观感受。
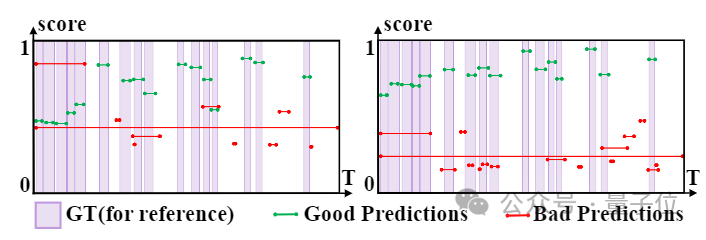
将THUMOS14数据集上的检测结果可视化后可以观察到,在实例级别完整性学习之后,高质量预测和低质量预测之间的差异显著增大。
(左侧是实例级别完整性学习之前的结果,右侧是学习之后的结果。横轴和纵轴分别表示时间和可靠性分数。)
整体来看,在常用4个数据集中,HR-Pro的性能均大幅超越最先进的点监督方法,在THUMOS14数据集上的平均mAP达到60.3%,相较之前的SoTA方法(53.7%)的提升为6.5%,并且能与一些全监督方法达到相当的效果。
在THUMOS14测试集上与下表中的先前最先进方法相比,对于IoU阈值在0.1到0.7之间,HR-Pro的平均mAP为60.3%,比先前最先进方法CRRC-Net高6.5%。
并且HR-Pro能够与具有竞争力的全监督方法达到相当的表现,例如AFSD(对于IoU阈值在0.3到0.7之间,平均mAP为51.1% vs. 52.0%)。
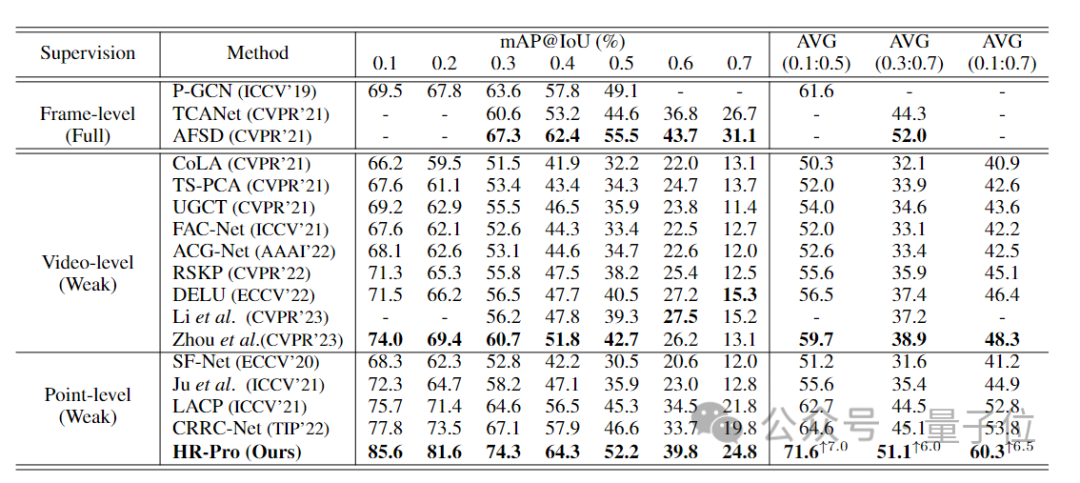
在各种基准数据集上的通用性和优越性方面,HR-Pro也明显优于现有方法,在GTEA、BEOID和ActivityNet 1.3上分别取得了3.8%、7.6%和2.0%的提高。

那么,HR-Pro具体是如何实现的呢?
研究团队提出了多层级可靠传播方法,在片段级引入可靠片段记忆模块并利用交叉注意力的方法向其他片段传播,在实例级提出基于点监督的提议生成来关联片段和实例,用于产生不同可靠度的proposals,进一步在实例级优化proposals的置信度和边界。
HR-Pro的模型结构如下图所示:时序行为检测被划分为两阶段的学习过程,即片段级别的判别性学习和实例级别的完整性学习。
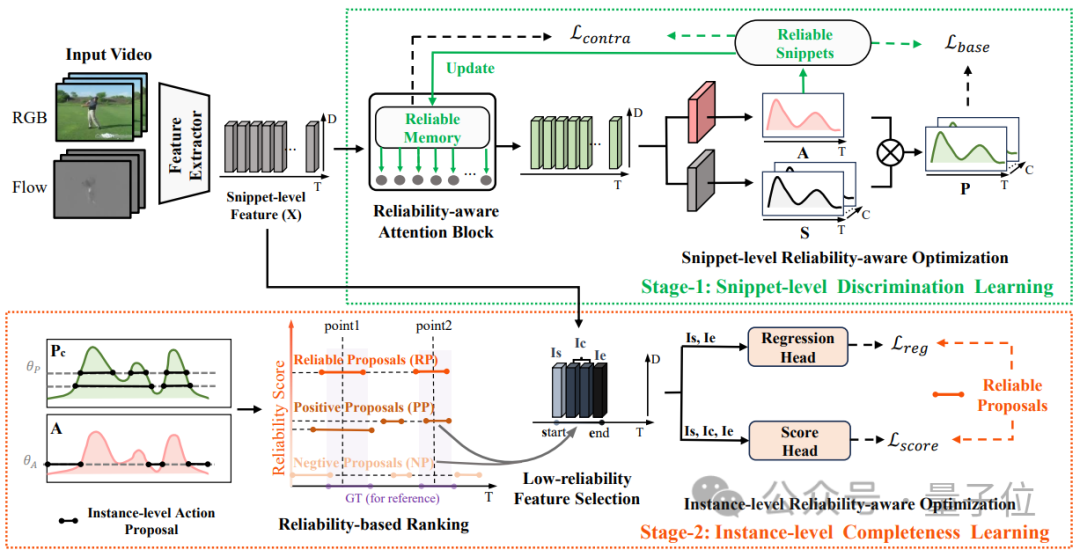
研究团队引入可靠性感知的片段级判别学习,提出为每个类别存储可靠原型,并通过视频内和视频间的方式将这些原型中的高置信度线索传播到其他片段。
片段级可靠原型构建
为了构建片段级别的可靠原型,团队创建了一个在线更新的原型memory,用于存储各类行为的可靠原型mc(其中 c = 1, 2, …, C),以便能够利用整个数据集的特征信息。
研究团队选择了具有点标注的片段特征初始化原型:
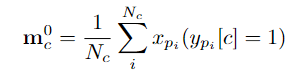
接下来,研究人员使用伪标记的行为片段特征来更新每个类别的原型,具体表述如下:
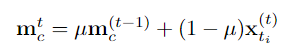
片段级可靠性感知优化
为了将片段级可靠原型的特征信息传递到其他片段,研究团队设计了一个Reliabilty-aware Attention Block(RAB),通过交叉注意力的方式实现了将原型中的可靠信息注入到其他的片段中,从而增强片段特征的鲁棒性,并增加对较不具有判别力片段的关注。
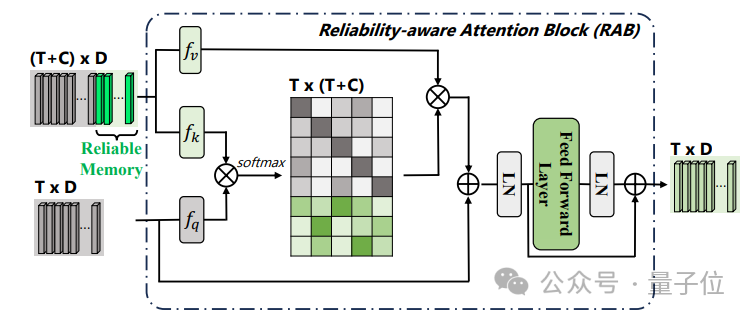
为了学习到更加具有判别里的片段特征,团队还构建了可靠性感知的片段对比损失:
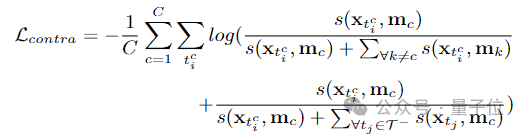
为了充分探索实例级别行为的时序结构并优化提议的得分排名,团队引入了实例级别的动作完整性学习。
这种方法旨在通过可靠的实例原型的指导,通过实例级别的特征学习来精化提议的置信度得分和边界。
实例级可靠原型构建
为了在训练过程中利用点标注的实例级别先验信息,团队提出了一种基于点标注的提议生成方法用于生成不同Reliability的proposals。
根据其可靠性分数和相对点标注的时序位置,这些提议可以分为两种类型:
为确保正样本和负样本数量平衡,研究团队将那些具有类别无关的注意力分数低于预定义值的片段分组为负样本提议(Negative Proposals, NP)。
实例级可靠性感知优化
为了预测每个提议的完整性分数,研究团队将敏感边界的提议特征输入至得分预测头φs:

然后用正/负样本提议与可靠提议的IoU作为指导,监督提议的完整性分数预测:
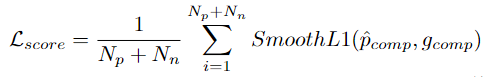
为了获得更准确边界的行为proposal,研究者将每个PP中的proposal的起始区域特征和结束区域特征输入到回归预测头φr中,以预测proposal开始和结束时间的偏移量。
进一步计算得到精细化的proposals,并希望精细化后的proposals与可靠proposal重合。
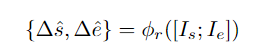
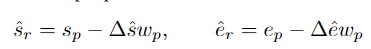
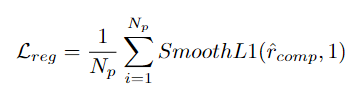
总之,HR-Pro只需很少的标注就能很好的效果大幅度降低了获取标签的成本,同时又拥有较强的泛化能力,为实际部署应用提供了有利条件。
据此,作者预计,HR-Pro将在行为分析、人机交互、驾驶分析等领域拥有广阔的应用前景。
论文地址:https://arxiv.org/abs/2308.12608


