# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
宾夕法尼亚大学沃顿商学院生成式AI实验室刚刚发布了两份重磅研究报告,通过严格的科学实验揭示了一个令人震惊的事实:我们可能一直在用错误的方式与AI对话。这不是胡说八道,而是基于近4万次实验得出的硬核数据推理的结论。



核心发现预告
你是否也在prompt中习惯性地加上"请"字?沃顿团队用GPT-4o和GPT-4o-mini做了一个让人大跌眼镜的实验。
实验设计:
震撼结果:

关键发现
花时间琢磨的那些"温柔"提示词,可能根本没有想象的那么重要。其实之前也有研究论述这个命题,您可以看下文末。
更令人困惑的是,研究发现prompt的效果在单个问题层面存在巨大差异,但在整体数据集上这些差异会被抵消。
实际场景模拟:
警告
这种不可预测性对于需要稳定表现的AI项目而言,会是一场噩梦。
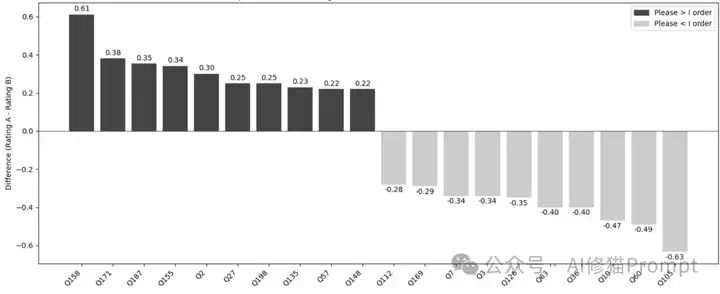
图表解读: 这张图展示了GPT-4o在"请"和"我命令你"两种提示方式下的前10大差异问题。看那些正负60%的差异!这种剧烈波动完全无法预测,说明礼貌用语的效果高度依赖具体问题。
如果你以为Chain of Thought(让AI"一步步思考")是万能神器,那就大错特错了。
测试模型:
核心发现:

典型案例:Gemini Flash 2.0
重要洞察
CoT虽然让AI在难题上表现更好,但同时让它在简单题目上出现了原本不会犯的错误。
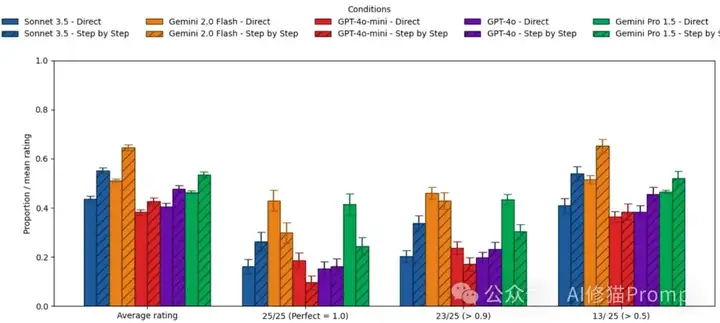
图表解读: 这个对比清楚展示了CoT的"双刃剑"效应。看蓝色条(直接回答)vs橙色条(CoT):在平均表现上CoT确实有提升,但在100%正确率标准下,多数模型的表现反而下降了!
对于专门设计的推理模型(如o3-mini、o4-mini),CoT的效果更是微乎其微。
性能提升对比:

成本警告
微不足道的提升是否值得付出如此高昂的成本代价?
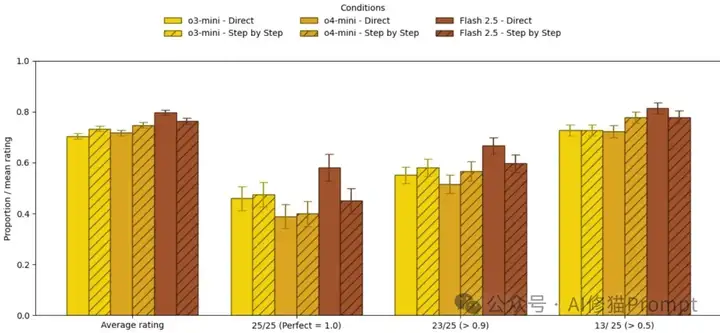
图表解读: 推理模型的表现对比几乎让人怀疑数据是否有误!蓝色和橙色条之间的差异小到几乎看不出来,这就是花费额外20-80%时间和成本换来的"提升"。
绝大多数开发者在测试Agent性能时,都是让模型回答一遍就得出结论。但沃顿研究显示,这种做法可能严重高估了模型的可靠性。
GPT-4o在最严格标准下的表现:
现实场景警告
如果一个AI产品在Demo演示时表现完美,但实际部署后却频繁出错,这种落差足以摧毁用户信心。
研究团队建立了三种评估标准,同一个模型的表现可能完全不同:

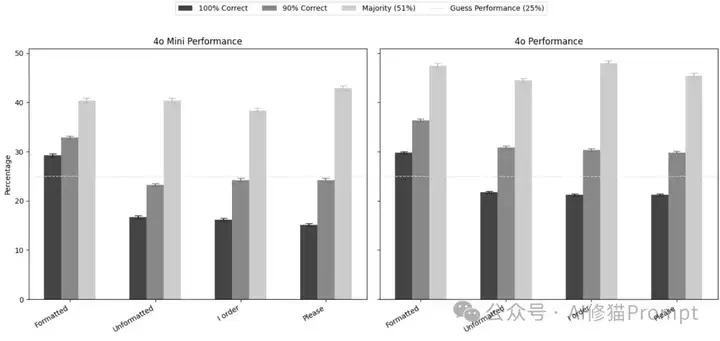
图表解读: 从这个对比图可以清楚看到,同一个模型在不同评估标准下的表现差异巨大。注意看100%正确率条件下,两个模型的表现都非常接近随机猜测的25%基线。
在所有测试的prompt技巧中,只有格式化约束表现出了一致的正面效果。
格式化约束测试:
标准格式要求:
"请按以下格式回答:'正确答案是(填入答案)'"
去除格式要求:
移除所有格式化指令,让AI自由回答
性能下降数据:
核心启示
与其花时间琢磨各种花哨的提示技巧,不如专注于设计清晰明确的输出格式要求。
格式化约束之所以有效,原因如下:
实际应用建议:
// 推荐:明确的JSON格式要求
{
"answer": "具体答案",
"confidence": "0.0-1.0",
"reasoning": "简要推理过程"
}
总结
一个明确的JSON格式要求,比十个"请"字更能保证AI的稳定表现。
许多现代模型即使没有明确的CoT提示,也会自动进行某种形式的逐步推理。
对比实验结果:

重要发现
模型本身已经具备了相当强的推理能力,外部的CoT提示反而可能是多余的。
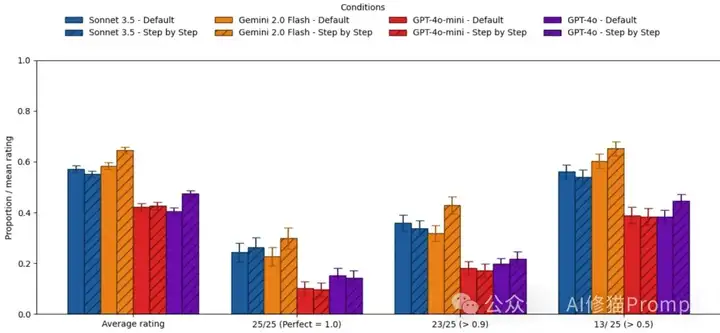
图表解读: 现代模型已经"聪明"到不需要你教它怎么思考了!这张图对比了模型自然状态(蓝色)vs被明确要求CoT(橙色)的表现。看看那些微不足道的差异,你还觉得CoT提示有必要吗?
这个发现为Agent开发带来了全新的思路:
传统方式:
请一步步思考这个问题:
1. 首先分析...
2. 然后考虑...
3. 最后得出结论...
推荐方式:
请分析以下问题并按JSON格式返回结果:
{任务描述 + 格式要求}
核心理念
现代大模型就像一个已经受过良好训练的员工,只需要给他明确的任务目标和输出要求,不需要再手把手教他如何思考了。
响应时间增加统计:

成本计算示例:
假设场景:Agent每天处理1万次查询
CoT额外时间成本:25-150万秒/天
准确率提升:仅2-3%
结论:ROI极低
成本警告
对于需要实时响应的Agent应用来说,这种延迟可能是致命的。
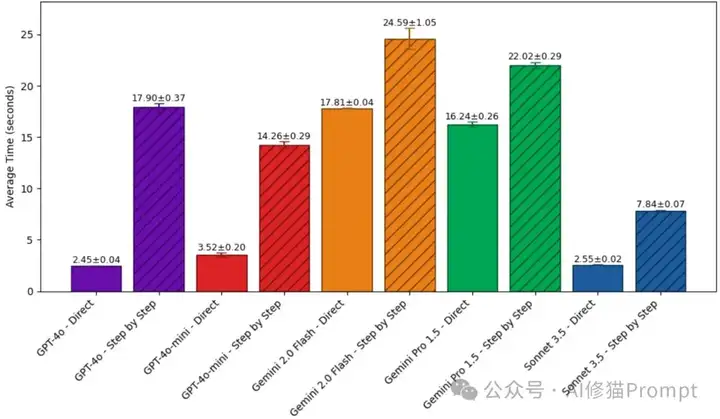
图表解读: 时间成本的残酷真相!看那些黄色条(CoT)相比蓝色条(直接回答)的巨大差异。Gemini Pro 1.5的CoT响应时间几乎是直接回答的6倍!这就是你为那点微不足道的准确率提升付出的代价。
作为Agent开发者,你需要建立精确的ROI计算框架:
评估维度:
决策公式:
ROI = (准确率提升带来的价值) / (时间成本 + 经济成本 + 维护成本)
停止的做法:
❌ 单次测试评估性能
❌ 只关注平均表现
❌ 忽视可靠性边界
推荐的做法: ✅ 每个关键功能至少测试25次
✅ 建立多层次评估标准
✅ 记录性能变异范围
评估标准分配:

新的优先级排序:
🥇 第一优先级:输出格式清晰明确
🥈 第二优先级:根据模型类型决定CoT使用
🥉 第三优先级:prompt用词优化
重要:
一个结构清晰的系统提示比十个精雕细琢的用户提示更重要。
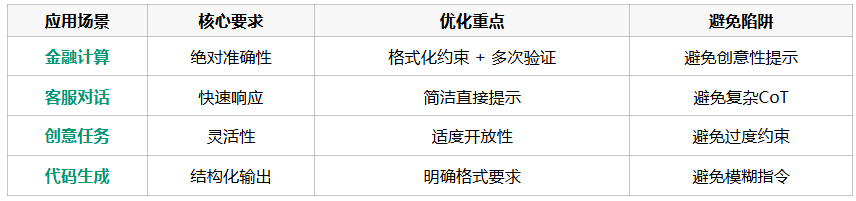
不同场景的策略矩阵:
沃顿商学院的这两份报告用最严格的科学方法告诉我们一个残酷的事实:AI领域的很多"常识"可能都是错的。
从经验驱动到数据驱动:
从单次测试到可靠性评估:
从复杂技巧到简单有效:
科学严谨胜过一切技巧
真正的AI产品优化不是靠直觉和经验,而是靠严格的测试、精确的测量和科学的分析。
关键行动指南:
写在最后: 在这个AI技术快速演进的时代,保持科学严谨的态度比追逐最新的技巧更加重要。
文章来自于“AI修猫Prompt”,作者“AI修猫Prompt”。



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
