# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
不用提前熟悉环境,一声令下,就能让宇树机器人坐在椅子上、桌子上、箱子上!

还能直接解锁 “跨过箱子”、“敲门” 等任务~

这是来自UC伯克利、卡内基梅隆大学等团队的最新研究成果LeVERB框架——
基于模拟数据训练实现零样本部署,让人形机器人通过感知新环境,理解语言指令就能直接完成全身动作。

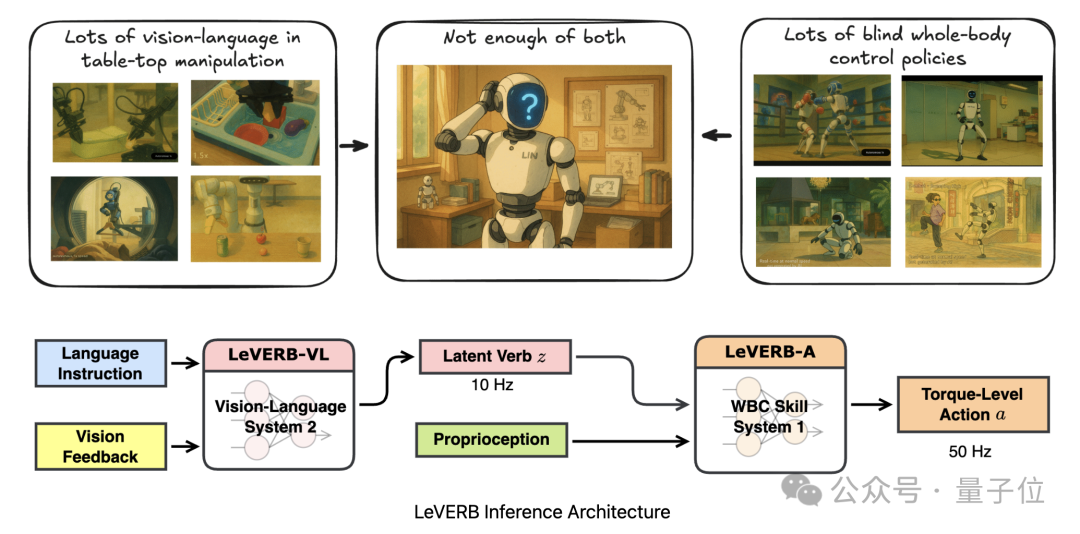
传统人形机器人要么 “能看懂指令却动不了”(缺乏全身控制能力),要么 “只能机械执行动作却读不懂环境”(依赖人工预设动作库)。
LeVERB首次打通了视觉语义理解与物理运动两者之间的断层,让机器人能像人类一样从“想”到“做”,自动感知环境,直接遵循指令完成动作。
上面展示的“坐下”动作就是通过“相机感知环境+'坐在[椅子/盒子/桌子]上'指令”完成的:

团队还推出了配套基准:LeVERB-Bench。
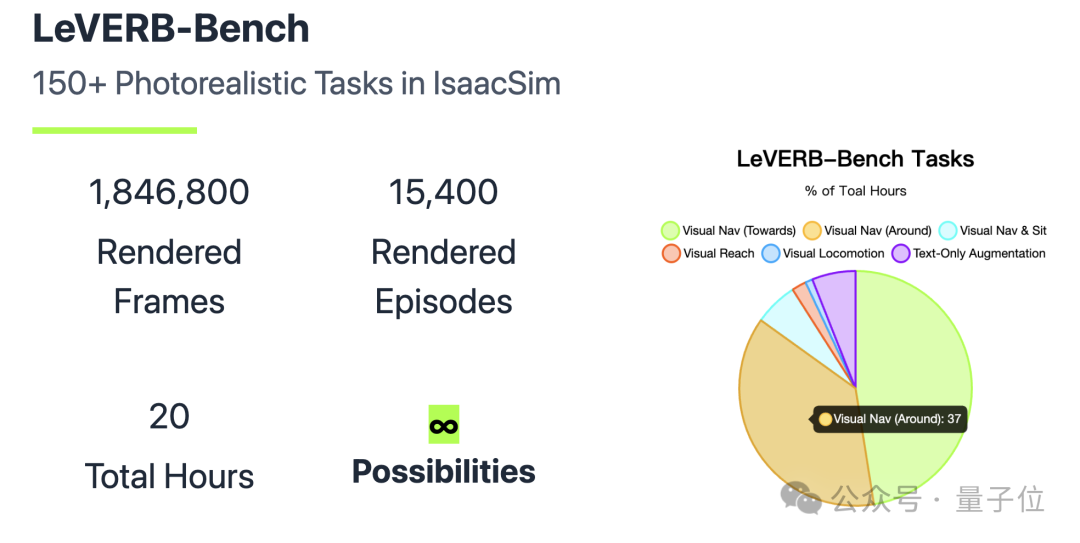
这是首个面向人形机器人WBC(全身控制)的 “仿真到真实” 视觉-语言闭环基准,包含10类超150个任务。
团队将该框架部署在宇树G1机器人上进行基准测试,结果显示:
在简单视觉导航任务中零样本成功率达80%,整体任务成功率58.5%,比朴素分层VLA(视觉-语言-动作)方案的性能强7.8倍。
目前,LeVERB-Bench数据集已在LeRobot格式中开源,项目的完整代码也即将发布。
多数视觉-语言-动作(VLA)模型在控制机器人时,依赖手工设计的底层动作 “词汇”(如末端执行器姿势、根部速度等)。
这使得它们只能处理准静态任务,无法应对人形机器人全身控制(WBC)所需的灵活全身动作。
简单来说,以前的机器人要么高层直接控制细节(就像大脑同时管走路和思考,效率低),要么底层不懂语义(就像四肢只听简单命令,复杂任务做不了)。
而人形机器人是高维非线性动态系统,需要高频控制与低频规划结合,传统方法缺乏对视觉和语言语义的有效整合。
于是,团队提出将高层的视觉-语言指令压缩映射为一个动作向量,也就是一个抽象指令,这种指令能够被底层的动作模块识别并执行。
在LeVERB框架中,这个抽象指令被称为“潜在动作词汇”。
LeVERB框架由分层双系统组成,这两层系统以“潜在动作词汇”作为接口。
该方法的最终目标是使两层的“潜在动作词汇”保持一致,让高层专注 “理解任务”,底层专注 “做好动作”,各取所长。
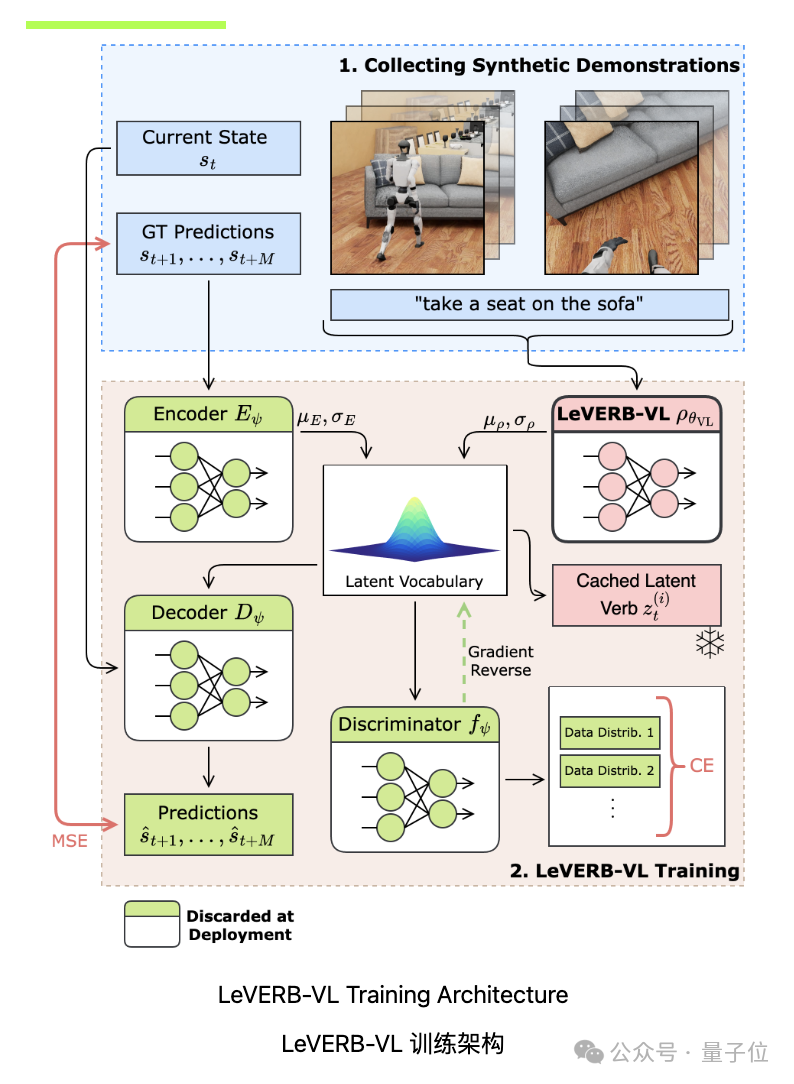
LeVERB-VL负责理解 “看到的东西” 和 “听到的话”。比如看到 “去坐蓝色椅子”,它会先分析 “蓝色椅子在哪”“怎么过去”,但不直接控制动作细节,而是把想法转化成一种 “抽象指令”。
它通过VLA先验模块、运动学编码器、残差潜在空间、运动学解码器和判别器等组件,将视觉和语言输入映射到平滑规则的潜在词汇空间,为运动控制生成潜在动作计划。
训练时,通过轨迹重建、分布对齐和对抗分类三部分优化模型,同时采用数据混合策略增强数据多样性,并对超参数进行精细设置,以实现对视觉 - 语言信息的高效处理和准确决策 。
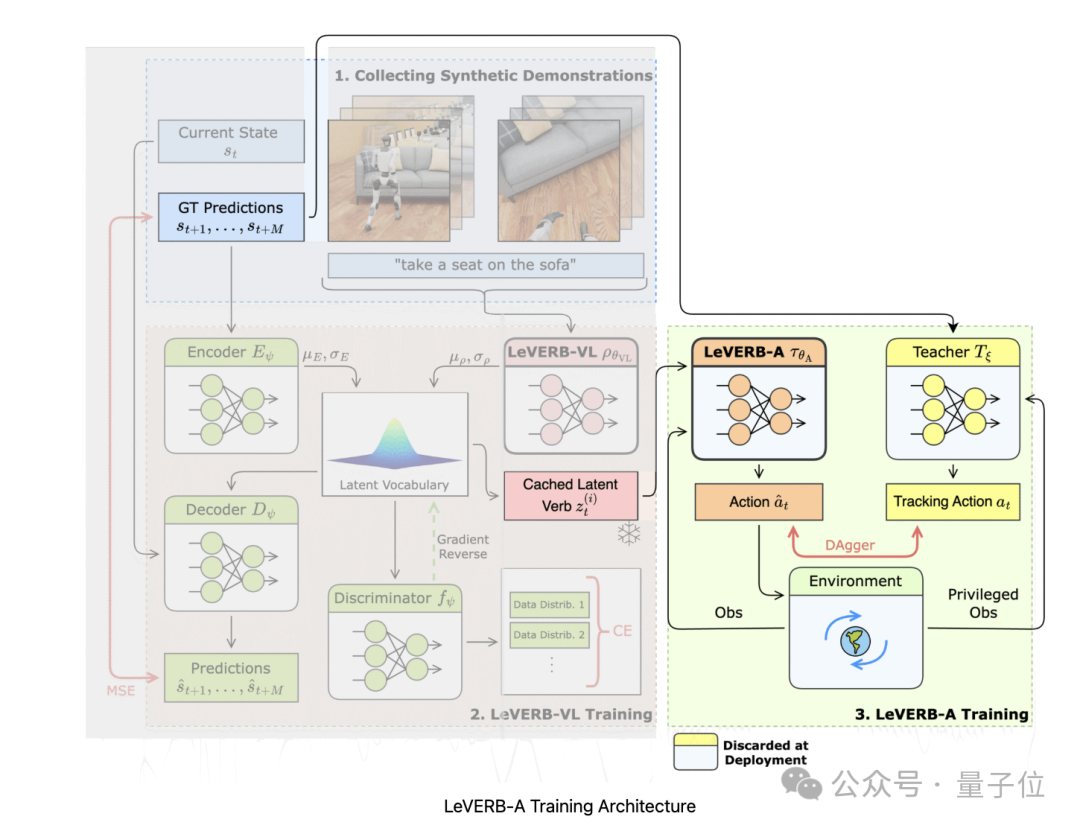
这部分作用是将LeVERB-VL生成的潜在指令转化为机器人可执行的动力学级动作。
训练时,先通过近端策略优化算法训练与视觉-语言无关的教师策略,再使用DAgger算法和Huber损失函数将教师策略的动作蒸馏到以潜在命令为条件的学生策略(即LeVERB-A)中。
运行时,LeVERB-A接收本体感受信息和潜在向量,采用Transformer架构输出经重新参数化的扭矩级关节位置动作指令,并在机器人板载CPU上用C++实现实时推理,完成人形机器人的全身控制 。
无法衡量就无法展开下一步工作,团队还专门提出了一个人形机器人视觉-语言全身控制(WBC)任务的配套基准LeVERB-Bench。
在人形机器人WBC领域,用于训练VLA模型的演示数据稀缺。现有基准存在诸多问题,如仅关注locomotion、在状态空间中无视觉、渲染不真实导致仿真与现实差距大等,无法满足研究需求。
LeVERB-Bench在仿真中重放重定向的动作捕捉(MoCap)运动,收集逼真的轨迹数据。这种方式无需在数据收集时进行可靠的动态控制,运动学姿势能提供任务级语义,还支持使用互联网视频等来源的重定向人形数据。
采用IsaacSim中的光线追踪渲染技术,能更准确地模拟场景光照和阴影,减轻以往合成数据中因光照不真实导致的仿真与现实差距问题。
通过程序生成管道,对每个轨迹进行缩放和随机化处理,随机化场景背景、物体属性、任务设置、相机视图,并对部分演示进行镜像,以确保数据的多样性和语义丰富性。
手动或使用VLM为数据标注以自我为中心的文本命令。同时,利用VLM为仅包含运动的对标注文本指令,增加仅语言数据,扩大数据覆盖范围。

LeVERB-Bench包含多种任务类别,如导航(Navigation)、走向目标(Towards)、绕物体移动(Around)、移动(Locomotion)、坐下(Sitting)、伸手够物(Reaching)等。
从视觉-语言任务和仅语言任务两个维度进行分类,共涵盖154个视觉-语言任务轨迹和460个仅语言任务轨迹,每个轨迹经过多次随机化后生成大量演示数据。
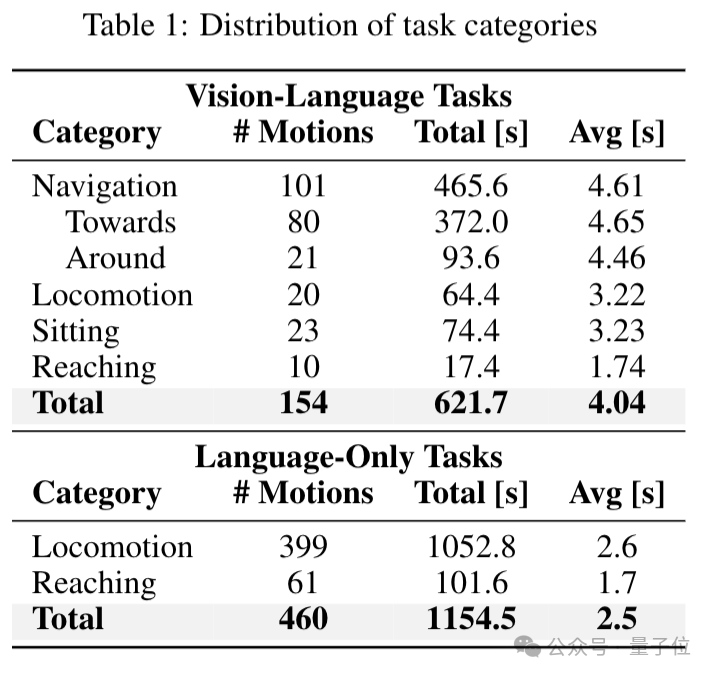
通过154条轨迹,每条随机化100次,生成了17.1小时的逼真运动轨迹数据。此外,还增加了2.7小时的仅语言数据,覆盖500条不同轨迹,进一步丰富了数据集。

在评估时,会在20个随机环境中进行,每个任务类别的场景纹理和物体属性完全随机化且在训练数据中未出现过,同时对第三人称相机角度进行局部随机化,确保评估任务在视觉上未在训练集中出现,以此检验模型的泛化能力。
团队将LeVERB框架部署在Unitree G1机器人上,测试其在真实场景中的零样本闭环控制能力,让机器人执行如 “走向椅子坐下” 等任务。验证了LeVERB从仿真到真实的迁移能力,证明该框架在实际应用中的可行性。

通过在LeVERB-Bench基准上评估,LeVERB框架表现出色,简单视觉导航任务零样本成功率达80%,整体任务成功率为58.5% ,比朴素分层VLA方案高出7.8倍。这表明LeVERB能有效处理复杂视觉-语言任务,在不同场景下具备良好的泛化能力。
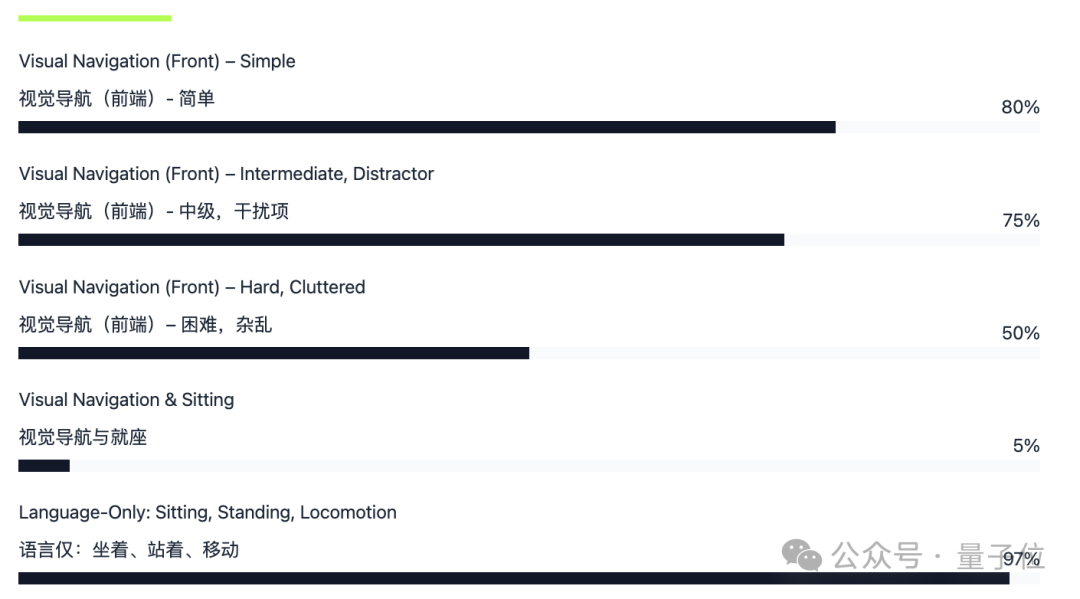
还对LeVERB框架的关键组件进行消融实验,探究各组件对性能的影响,例如去掉判别器(ND)、运动学编码器(NE)等组件进行测试。
去掉判别器(ND)会导致性能显著下降,表明其在对齐潜在空间、增强模型泛化能力方面的重要性;去掉运动学编码器(NE)也会使性能降低,证明运动学编码器对补充运动细节信息的必要性。
LeVERB团队有半数成员是来自UC伯克利、卡内基梅隆大学(CMU)等的华人学者。
该项目的主要负责人薛浩儒硕士毕业于卡内基梅隆大学(CMU),现于UC伯克利攻读博士学位。
他曾在MPC Lab、LeCAR 实验室实验室进行机器人研究,现在NVIDIA GEAR实验室实习。

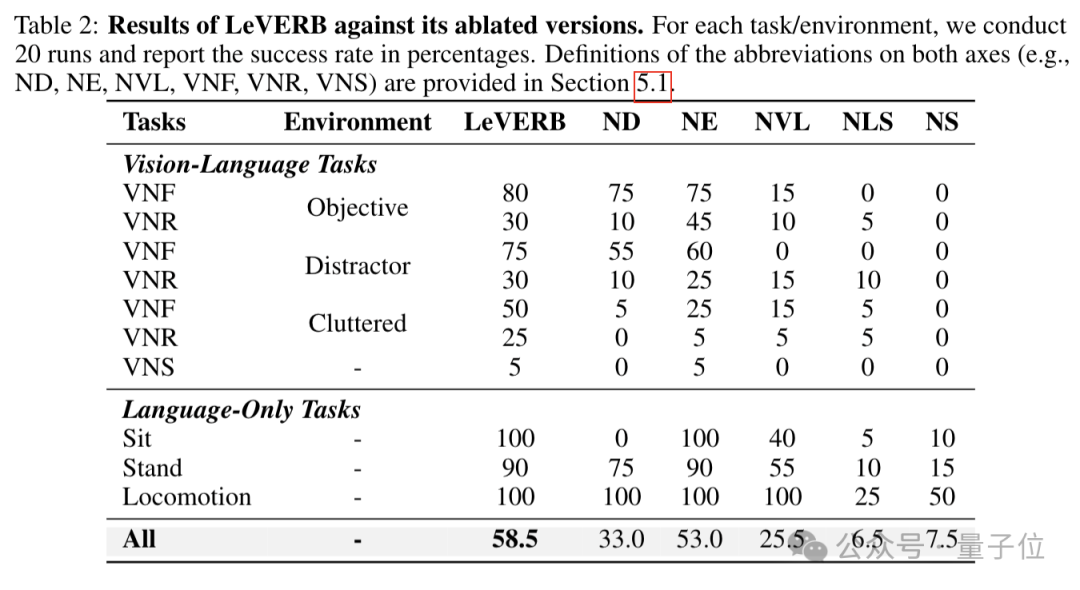
2021年至2024年,他领导了AI Racing Tech项目——一个价值数百万美元的自动驾驶赛车研究项目。
该项目在F1级自动驾驶赛车上部署了真实世界的机器人学习,最高时速达到160英里。
AI Racing Tech在2022年的美国印第安纳波利斯自动驾驶挑战赛中夺得亚军,在2023年夺得季军。
另一位负责人廖启源本科毕业于广东工业大学机电工程专业,目前是UC伯克利机械工程专业的博士研究生。
他的研究方向专注于开发新型机器和驱动方式、结合学习和基于模型的方法、协同设计硬件、学习和控制。
目前,他在波士顿动力公司实习。

感兴趣的朋友可以到原文中查看更多细节。
项目地址:https://ember-lab-berkeley.github.io/LeVERB-Website/
论文地址:https://arxiv.org/abs/2506.13751
参考链接:
https://x.com/HaoruXue/status/1937216452983160863
文章来自于微信公众号“量子位”。



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
