# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
全网翘首以盼的DeepSeek-R2,再次被曝推迟!
据The Information报道,由于DeepSeek CEO梁文锋始终对R2的表现不满意,因此R2迟迟未能发布。

此外,他们还援引两位国内知情人士的消息称,R2研发进程缓慢可能是由于缺少英伟达H20芯片。
要知道R1的训练总计耗费了3万块H20(国内特供版)、1万块H800和1万块H100。
所以在H20吃紧的情况下,预计耗费更多算力资源的R2难免受到波及。
事实上,这不是R2第一次被曝项目延期了,最早能追溯到今年4月——
仔细一梳理,原来人们对R2的期待,早在V3新版本出来后就开始了。
去年12月底,DeepSeek发布了至今被视为“性价比代表”的DeepSeek-V3模型。到了今年3月24日,官方发布公告称对V3进行了一次升级,新版本代号为V3-0324。
虽然官方轻描淡写只说是“小版本升级”,但很多人实测下来可一点也不小。
于是人们开始推测,在V3-0324已经取得明显进步的情况下,是不是可以用它来训练R2模型。
这里需要补充一下,DeepSeek主打推理的R1模型,正是在DeepSeek-V3-Base的基础上,结合冷启动数据和多阶段训练流程构建的。
所以说,V3更新了,R2还会远吗?
并且结合R1是在初代V3一个月之后发布,当时人们按照这一节奏预测——
R2大概率将在4月上线。(网友os:3月发布V3-0324,4月上R2,完美~)
刚进入4月,DeepSeek就发了一篇关于推理时Scaling Law的论文,引得大家纷纷联想是不是R2马上要来了。
论文题目为《Inference-Time Scaling for Generalist Reward Modeling》,由DeepSeek和清华大学共同提出。
他们核心提出了一种叫做SPCT(Self-Principled Critique Tuning)的方法——
首次提出通过在线强化学习(RL)优化原则和批判生成,实现推理时扩展。
之所以要做这么一项研究,是因为之前大家用奖励模型(Reward Model, RM)在RL中为大语言模型生成奖励信号。但现有的RM在通用领域却表现出受限的情况,尤其是在面对复杂、多样化任务的时候。

不过论文发布后,中间一直没啥动静。
直到4月底,坊间开始疯传一组R2的泄露参数:1.2T万亿参数,5.2PB训练数据,高效利用华为芯片……一整个真假难辨。

时间不知不觉就进入了5月,R2依旧没有丝毫官方消息。
5月中旬,DeepSeek发布了一篇有梁文锋亲自署名的论文。
这一次,团队把DeepSeek-V3在训练和推理过程中,如何解决“硬件瓶颈”的方法公布了出来。

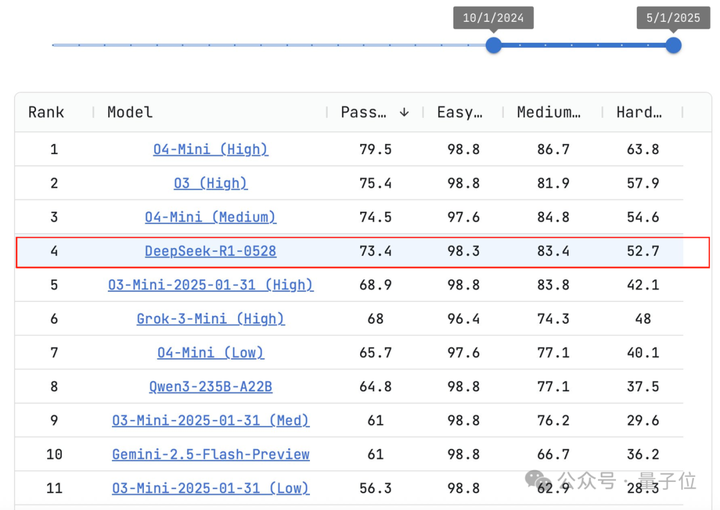
后来又在月末端午节前,官方上线了新版R1——DeepSeek-R1-0528。
看名字你可能以为是个小版本更新,但实际上它在LiveCodeBench上几乎与OpenAI o3-high相当。
由于编程能力强悍,当时一众网友惊呼:讲真这其实就是R2吧!
但直到目前为止,R2依旧未能真正和大家见面。
BTW,就在The Information曝出延迟消息后,Reddit相关帖子下最高赞网友表示:
我相信延迟是值得的。
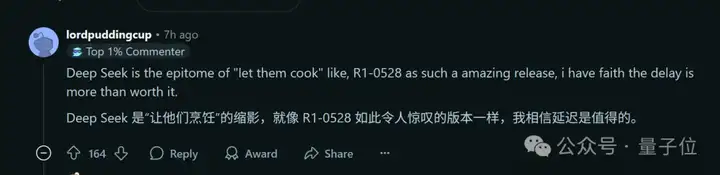
毕竟Llama 4 翻车在前,“没有人愿意成为下一个失误者”。
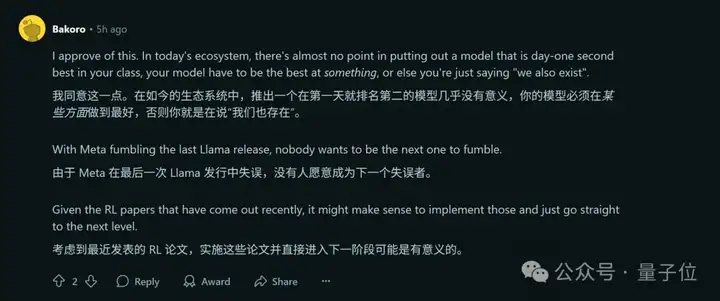
但与此同时,也有人合理推测,R2好歹要等V4出来再说。
理由是,从官方当前发布的论文和一些版本更新来看,V3可能已经到达极限了。
嗯,6月即将结束,谁说7月不值得期待呢(doge)。
参考链接:
[1]https://www.reddit.com/r/LocalLLaMA/comments/1ll6jo5/deepseek_r2_delayed/
[2]https://x.com/theinformation/status/1938337736622019044
文章来自微信公众号 “ 量子位 ”,作者 一水


