# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在信息爆炸的时代,我们每一天都在搜索、提问、获取答案。但你是否想过:传统搜索真的能满足我们越来越复杂的知识需求吗?
在刚刚过去的WWDC大会上,苹果首次公开探索将ChatGPT等AI助手整合进系统层,撼动了长期绑定的默认搜索引擎Google!
这不仅是一次产品变革,更是一场信息入口的权力转移。
与此同时,传统搜索巨头的市场份额出现下滑趋势,而基于大模型的智能助手如ChatGPT、Claude、Perplexity等平台,日活跃用户数却持续走高。
这些信号释放出一个明确趋势:
我们获取信息的方式,正在从「关键词搜索+人工筛选」转向「提出问题→自动研究→得出结论」。
正是在这样的变革背景下,由UIC、UIUC、清华、北大、UCLA、UCSD等多家顶尖机构联合发布的最新论文提出Agentic Deep Research:一种由大语言模型驱动的深度信息获取与推理系统,可能彻底颠覆传统搜索范式。

论文链接:https://arxiv.org/pdf/2506.18959
项目主页:https://github.com/DavidZWZ/Awesome-Deep-Research

进入「Agentic Deep Research」时代
过去,搜索引擎依靠关键词匹配。
今天,ChatGPT、Claude 等LLM让我们对答案的交互方式发生了改变。然而,这些模式仍难以胜任复杂的、需要多步推理与跨域整合的「深度研究型任务」。
2025年初,OpenAI 曾在官方更新中首次提出了「Deep Research」的概念,并这样描述:
Introducing Deep Research: An agent that uses reasoning to synthesize large amounts of online information and complete multi-step research tasks for you.
在此基础上,研究人员提出的 Agentic Deep Research(智能体型深度研究),进一步将这一理念系统化、技术化:LLM成为自主的信息研究智能体,具备推理-搜索-综合三位一体的闭环能力。
Agentic Deep Research包括自动规划检索路径、多轮迭代获取证据、逻辑推理指导搜索决策、多源信息融合输出研究报告级答案。
从「回答一个问题」到「像研究者一样系统性完成复杂任务」,这正是 Agentic Deep Research 的目标。
从关键词匹配到智能深研
信息检索作为现代知识获取的基石,长期依赖于传统的关键词匹配式搜索引擎(如 Google、Bing)。
这类系统依靠网页爬取、索引构建和静态排序机制,擅长处理事实型或导航性查询。
然而,面对跨领域、推理性强的复杂问题,其缺乏上下文理解与多步整合能力,常常导致用户需要手动筛选碎片化结果并自行构建结论,造成巨大的认知负担。
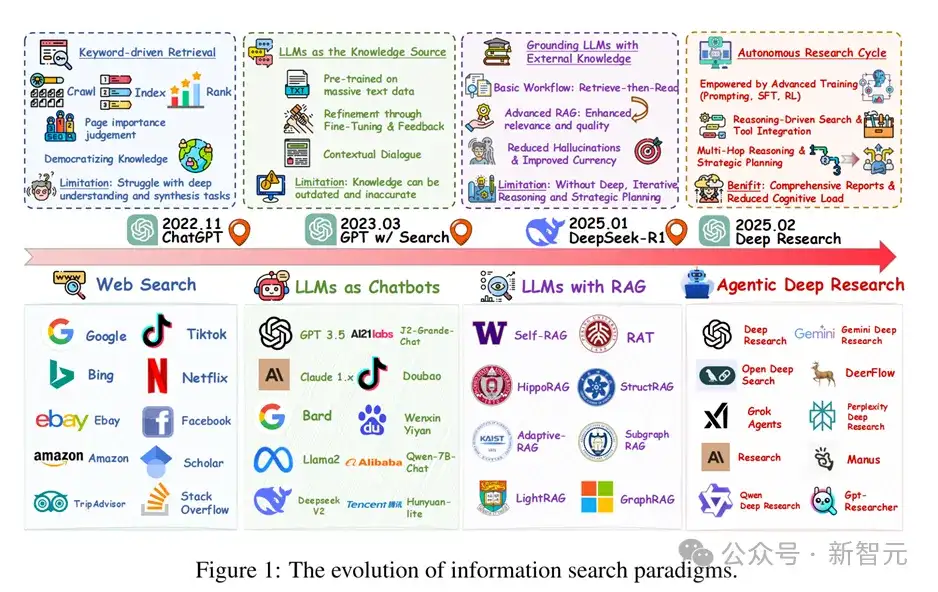
随着大型语言模型(LLMs)的崛起,信息检索进入了「语言理解驱动」的新阶段。基于ChatGPT、Claude等LLM的问答系统突破了关键词限制,能够通过自然语言对话直接生成答案,显著提高了交互效率。
然而,这类纯粹基于参数内存的生成模型仍存在两大硬伤:一是知识时效性受限于训练数据的时间范围,二是易出现「幻觉」(hallucination)问题,输出内容可能缺乏真实依据。
为缓解上述问题,Retrieval-Augmented Generation(RAG)应运而生。RAG通过在生成前检索外部知识库,引入事实证据来增强回答的准确性与广度。
这一范式在事实性问答、开放领域QA等任务中展现出显著优势,代表了信息检索与生成的首次融合。
但当前主流的RAG仍大多采用静态、一轮的「检索-生成」流程,在面对需要跨步思考、动态计划的问题时表现乏力,无法有效模拟人类专家「边查资料边思考」的调研过程。
为突破这一局限,最新研究提出了 Deep Research 这一全新Agent范式。该范式将LLM赋予类人「研究者」能力,使其在面对复杂任务时能够:自主规划搜索路径、动态发起查询请求、迭代推理分析,并结合外部工具完成完整的深度信息综合。
检索与推理在这一框架下不再是孤立的模块,而是形成了一个交替协作的反馈闭环,真正模拟了专家式的研究行为。
因此,从传统Web Search → LLM Chatbot → LLM with RAG → Agentic Deep Research,我们正见证信息获取范式的一次深层跃迁——从「静态查找」,走向「智能研究」。
基准成绩与TTS Law的双重支撑
在大规模实证评测中,研究人员将5个通用LLM(如GPT、Claude-3.5)、4个强调推理能力的LLM(如DeepSeek-R1、OpenAI O1) 以及1个典型Agentic Deep Research模型(OpenAI Deep Research智能体) 同台比较,选取BrowseComp、BrowseComp-ZH和Humanity’s Last Exam (HLE) 三个高难基准。
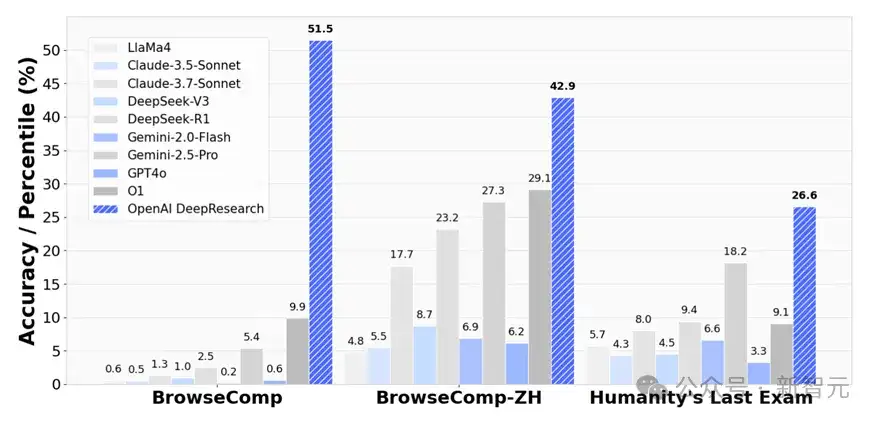
结果显示,标准LLM在BrowseComp系列的正确率通常不足10%,在HLE也难以突破20%;
而具备推理-检索闭环的 Deep Research 智能体分别取得51.5%、42.9% 和26.6%的显著优势,充分验证了「推理驱动检索」对复杂任务的增益效果。
与此同时,论文对GitHub公开仓库的星标趋势进行统计,发现DeepResearcher、R1-Searcher、DeerFlow等项目的星标曲线自2025年初起明显快于传统RAG类库,显示出社区对该范式的高度关注与快速迭代能力。
更重要的是,这些性能跃升与作者提出的Test-Time Scaling Law (TTS Law)相互印证。
通过统计在AIME24数学推理集与MuSiQue多跳问答集上的实验数据,论文发现:当增加推理步数或扩展检索轮次时,模型在各自任务上的得分皆表现出近线性增益,并在三维坐标系中差值形成一条清晰的对角增益平面。
这一规律不仅解释了Deep Research智能体在BrowseComp/HLE等基准中为何能大幅超越单轮RAG和纯推理LLM,也为系统落地提供了可操作的预算分配准则:
事实密集型查询倾向于分配更多token进行检索,逻辑密集型问题则需预留充足的推理深度,从而在固定成本下获得最优性能。
综上,基准成绩的显著提升证明了Agentic Deep Research的有效性,TTS Law则揭示了其中的可预测增长机制;
二者相辅相成,为未来构建高效、可控、成本可量化的深度研究智能体奠定了坚实的理论和实证基础。
开源生态也在聚焦这个方向
与此同时,Agentic Deep Research不仅在概念上描绘了下一代信息检索的蓝图,除了OpenAI、Google等大厂加大投入,更在学术界与开源社区中迅速形成广泛共识与实践响应。
从研究热度来看,2025年间涌现出大量围绕「reasoning-enhanced retrieval」、「deep research agent」、「reinforcement learning search agents」等主题的论文,代表性工作包括DeepResearcher、Search-R1、R1-Searcher等,系统性地推动了推理能力驱动的信息获取技术演化。
这些研究不再满足于传统监督学习下的固定流程,而是借助强化学习、环境交互与任务反馈机制,使语言模型具备自主探索、策略规划与动态修正的能力。
更值得注意的是,在开源社区中也迅速形成了繁荣的生态体系。
多个深研智能体系统如deepresearch、DeerFlow、ODS(Open Deep Search) 等开源项目,短时间内获得了数千颗GitHub star,反映出从开发者到研究者广泛的关注与参与热情。
根据论文中对开源趋势的统计分析,Agentic Deep Research项目整体呈现出持续上升的星标增长曲线,且领先于同时间段的传统RAG类项目。
这一趋势不仅说明该范式具备强技术吸引力,也表明整个社区正在形成一个由产品驱动、研究反馈、社区共建的良性循环。
因此,无论是从模型能力的突破、技术路径的清晰度,还是从生态系统的活跃程度来看,Agentic Deep Research正在从前沿理论走向主流范式的关键跃迁阶段,预示着「让AI完成研究任务」的时代已不再遥远。
通向「AI研究员」的演化路线
论文还提出多个关键前沿议题,包括Human-in-the-loop监督机制、跨模态多源信息融合、多智能体协同研究系统、Token预算自适应调控的高效推理搜索、面向法律、生物、医学的垂直领域深研系统。
这不只是搜索范式的进化,更是人类在LLM时代与信息交互方式的重塑。
参考资料:
https://arxiv.org/pdf/2506.18959
文章来自公众号“新智元”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】MindSearch是一个模仿人类思考方式的AI搜索引擎框架,其性能可与 Perplexity和ChatGPT-Web相媲美。
项目地址:https://github.com/InternLM/MindSearch
在线使用:https://mindsearch.openxlab.org.cn/
【开源免费】Morphic是一个由AI驱动的搜索引擎。该项目开源免费,搜索结果包含文本,图片,视频等各种AI搜索所需要的必备功能。相对于其他开源AI搜索项目,测试搜索结果最好。
项目地址:https://github.com/miurla/morphic/tree/main
在线使用:https://www.morphic.sh/
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
