# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

持续适应性学习,即指适应环境并提升表现的能力,是自然智能与人工智能共有的关键特征。大脑达成这一目标的核心机制在于神经递质调控(例如多巴胺DA、乙酰胆碱ACh、肾上腺素)通过设置大脑全局变量来有效防止灾难性遗忘,这一机制有望增强人工神经网络在持续学习场景中的鲁棒性。本文将概述该领域的进展,进而详述两项6月Nature发表的背靠背相关研究。
不论是多巴胺还是血清素,神经递质都可类比为大脑中的"全局变量",能够让大脑在不同的环境之间切换工作状态,从而应对多种多样的工作需求。以多巴胺为例,1997年的一项研究发现[1]在学习过程中多巴胺能神经元的瞬时反应与强化学习(RL)中的奖励预测误差(RPE)信号非常相似。这一关联催生了多巴胺信号的预测误差假说,认为多巴胺神经元编码了未来结果预期的好坏与实际结果好坏之间的差异。但该假说未涵盖多巴胺的全部功能,这点我们将在后续内容中深入讨论。
另一种神经递质血清素5-羟色胺则对持续学习任务具有关键作用[2]。智能体需要界定既有知识的适用边界,以此平衡之前学习的知识与当前的新任务所需的知识(持续学习),或新到来的数据流(在线学习)。在这种人工智能语境下,此机制可通过损失函数中的正则化约束实现,例如添加保护先前知识权重的惩罚项,而非直接类比强化学习的奖励折扣因子。
与外界奖励相关的神经递质不止是多巴胺,还包括乙酰胆碱,在没有外界奖励的情况下,这两种神经递质之间会呈现频率为2Hz的自发周期性波动[3],如同潮起潮落,一种神经递质的含量增加,另一种就减少,如此往复循环。这一特征有助于解释为何生物体能够在没有外界奖励的情况下进行持续学习。同时,该机制的失效或失控也可以解释为何会出现抑郁症(因为没有即时奖励就无法自我驱动),及妄想症(对想象出来事件的神经元过度激活导致坚信这一虚假的事件)。而相对应的,让智能体能够在没有明确奖励的场景中学习,是AI研究中持续学习算法的一大痛点。
针对人工神经网络中引入神经递质的方法,综述[https://arxiv.org/pdf/2501.06762]进行了系统性的介绍,来自神经科学发现的方法,包括通过超参数和激活函数调整、上下文驱动的期望更新以及权重调节,能用来增强AI智能体的持续学习能力,避免灾难性遗忘。同时,为进一步推进这些方法,可以通过网络拓扑、神经群体异质性、树突特性等探索神经调节组件的影响。具体相关研究,可参考该综述。
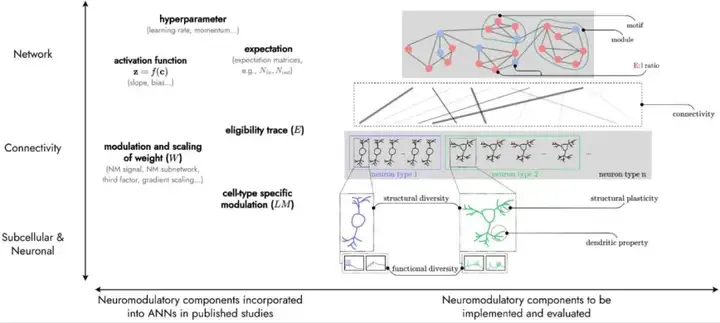
▷图1:将神经调节组件集成到人工神经网络(ANNs)中的框架,根据尺度分为网络层面的自适应重构,神经连接层面的连通性,拓扑结构及及兴奋与抑制,亚细胞及神经元层面的异质性和门控可塑性。
接下来,本文将详述近日Nature同日刊登的两篇将神经科学与人工智能结合的姊妹论文[4,5],一篇关于多巴胺神经元群体的异质性,该研究首次发现大脑能在奖励到来之前构建对未来奖励的预测性地图。它揭示了多巴胺神经元反应中先前未知的结构和异质性。另一篇则讲述了研究者受此启发构建的分布式强化学习框架。这些发现可能重塑我们对决策、冲动行为以及如何构建更类人的人工智能的理解。

▷Sousa, M., Bujalski, P., Cruz, B.F. et al. A multidimensional distributional map of future reward in dopamine neurons. Nature 642, 691–699 (2025). https://doi.org/10.1038/s41586-025-09089-6
我们先模拟一个场景,午餐时刻,你正在纠结,是去排长队享用那家心仪的餐厅,还是去街角的快餐店迅速解决一餐。你的大脑不仅在权衡餐点有多美味,还要考虑获取它得等多长时间。在此决策过程中,传统的视角是“强化学习”(RL)的计算模型。这是一个在奖励和惩罚指导下,通过试错学习和改变策略来获得更多奖励的过程。在生物大脑中,多巴胺在调控过程中扮演着核心角色,当事情的结果(就餐体验)比预期更好或更差时,神经系统会释放化学物质多巴胺来传递信号。
在传统的强化学习模型中,上述过程被简化了。它将未来的回报简化为一个单一的预期值,或者说,一个对未来各种情况预测的平均值。但现实中,响应多巴胺的神经元有很多个。一个更合理的假设是:这些神经元中的每一个都有所不同,从而在概念上能够对所有可能的未来结果进行表征。如果大脑真的只计算未来回报的平均值,而缺少了对未来期望的建模,那么我们在决策时,就会像一个对等待时间或饭菜份量一无所知的食客,仅凭一个笼统的“价值”来评价一顿大餐。
为了验证大脑是否具有上述的分布式奖励处理系统,研究者首先设计了一组精巧的实验。他们需要系统性地拆解奖励的“大小”和“延迟时间”这两个核心变量,观察多巴胺神经元如何对它们的不同组合做出反应。实验中,小鼠通过嗅闻不同的气味线索,来预测一份奖励将在多久之后到来。例如在「气味延迟任务」(Cued Delay Task)实验中,每个气味线索对应不同的水奖励延迟;而在另一实验中,小鼠置于虚拟现实的线性跑道中,在行进接近目标时获得奖励。
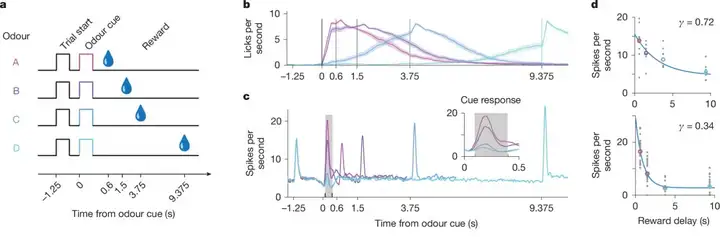
▷图2. 多巴胺能神经元表现出多种折扣因子,从而在不同场景下,编码不同的奖励延迟。a. 实验设计图示。b. 奖励发放前的预期舔舐行为。c. 四种试验类型的平均脉冲时序存在差异。d. 两个单个神经元的放电频率和奖励延迟间的关系。
通过结合基因标记和神经元解码技术,研究者分析了数十个多巴胺神经元的放电情况。他们发现,这些神经元远非千篇一律,而是展现出鲜明的个性差异。在时间维度上,一些神经元更加“不耐烦”,对即时奖励的价值评估更高,而另一些神经元则对延迟(1分钟后)奖励更加敏感(图2),甚至还有些神经元关注更遥远的未来。在价值维度上,一些神经元表现得更“乐观”,对意外的大奖反应更强烈,并期望比平均水平更好的结果。另一些则表现得更“悲观”,对失望的反应更强烈,并倾向于对未来的奖励做出更谨慎的估计。
从整体上看,这些看似独立的神经元共同协作,实时编码着一幅关于未来的概率地图。这个地图不仅包含奖励的可能性,还包括奖励大小、抵达时间及其发生概率的多维坐标系。实际上,脑并非在计算一个模糊的平均预期,而是在精确地描绘整个奖励的概率分布,这正是现代人工智能系统的一个核心原则。
此外,这种群体编码能够预测动物的前瞻性行为。研究者还发现,神经元的调谐会适应环境。如果奖励通常是延迟的,神经元就会进行调整,它们会改变它们对更长时间后奖励的价值评估,并变得对未来的奖励更加敏感。具体来说,神经元共享一个“共同的价值函数”,并各自采用不同折现因子,对该函数在时间上的导数进行指数折现响应。例如有的神经元持续上升,有的先降后升,甚至有的下降趋势(图3c)。这种灵活性就是我们所说的对外界环境变化的高效编码。
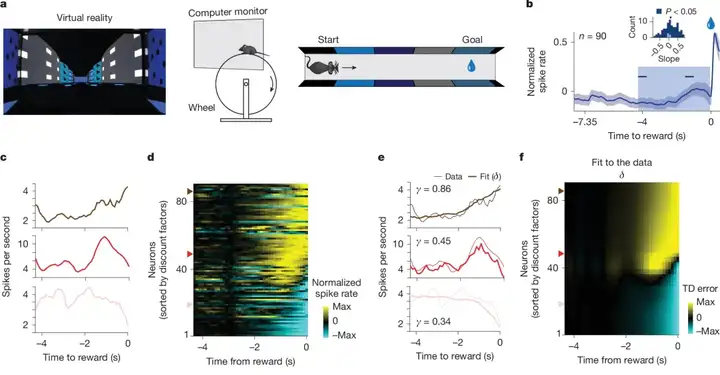
▷图3:不同多巴胺神经元的折扣因子多样性解释了不同的攀升表现。a. 实验装置。b单个多巴胺能神经元(n = 90)的平均活动在奖励发放前轨道的最后几秒内呈上升趋势。c. 在接近奖励的最后阶段表现出不同上升活动的单个神经元示例,包括单调上升(深红色)、非单调(红色)和单调下降(浅红色)上升。d. 整个神经元群体中的单个神经元在递增活动方面表现出多样性。e:图 c 中所示单个神经元的示例模型拟合。f. 模型捕捉到了整个群体中递增活动的多样性。
具体来看,虽然所有神经元都能够改变对未来的反应,但它们相对的作用仍能保持稳定,乐观的神经元保持乐观,悲观的神经元则保持谨慎。这种多样性的持续存在,可能是使大脑能够同时表征多种可能未来,并计算期望的关键机制。这就像拥有一支具有不同风险特征的顾问团队。有些人敦促行动,而另一些人则建议耐心等待。
这种观点分布可能是在不可预测世界中做出良好决策的关键,与机器学习中集成学习(ensembles)相似。在集成学习中,多个具有不同视角或偏差的模型协同工作,作为多样化的预测器,以提高它在不确定性下的性能。
从经验中学习到的神经编码不仅帮助动物根据过去的情境行事,更能使它们为不同的未来做计划。这种神经编码不仅用于从过去的奖励中学习,还用于对未来进行推断,并根据接下来可能发生的事情,主动地调整行为。
在计算模拟中,研究人员表明,获取这种多巴胺编码的概率地图使人工智能体在特定环境下能够做出更明智的决策,特别是在奖励随时间变化或依赖于内部需求(如饥饿)的环境中。大脑不必模拟每一种可能的结果,而是可以参考这张概率地图,根据情境重新权衡,这可能解释了当动物需求变化时,它们为何能快速转换策略的原因。饥饿的实验鼠会倾向于快速获得少量奖励,而满足的实验鼠可能愿意等待更好回报。实验鼠脑中存储的概率地图可以支持这两种策略,根据需求变化调整相应权重。
这一发现,也为理解人为何会做出冲动决策开辟了新视角。如果个体在多巴胺系统如何表征未来方面存在差异,能否解释为什么有些人更倾向于即刻满足,而另一些人则会选择延迟满足?进一步而言,由此衍生的疑问是,这种差异是否导致某些人更易形成冲动行为模式?如果确实如此,这种内在的“概率地图”能否通过治疗或环境改变来重塑,例如鼓励个体以不同的方式看待他们的世界,并更信任长期奖励?
多巴胺能神经元多样性对应的智能算法
在神经科学和人工智能之间的相互借鉴日益深入之际,该研究的发现揭示了一个关键联系。计算机科学领域会借鉴大脑使用的策略来提升智能体的学习能力。比如在人工神经网络中集成对所有可能未来的编码,包括其时间、大小和可能性,而非仅针对单一场景。这种方法可能成为开发具备更接近人类推理能力机器的关键。
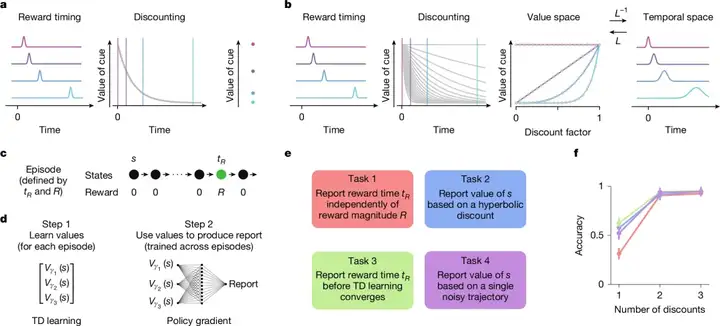
▷图4,对比单一尺度的强化学习与多时间尺度的强化学习,a)未来奖励通过单一指数的折现函数衡量,b)使用多个折现因子,将未来的奖励当成一串向量进行衡量
一个不仅能够考虑平均值,还能考虑分布和概率的系统,为学习系统提供了极大的灵活性。它允许智能体根据自身当前的目标和优先事项来进行适应,以最大化即时或延迟的奖励,从而更好地适应变化的目标和不断变化的环境(图4f所示,在图4e对应的四类任务上,多个折现因子衡量奖励后,强化学习模型的准确性相比单一折现因子显著提高)。
那么具体的算法是什么样的?答案如图5所示,从左上(a)引入不同大小的奖励对应不同折现因子幅度分布的时序差分学习(TD learning),到右上(b)经典强化学习框架下的时序差分学习,以及左下(c)同时引入时间-幅度因子分布的时序差分学习(TMRL),再到右下(d)引入多个时间对应不同折现因子时间分布的时序差分学习,即第二篇Nature论文中提到的受上述研究启发提出的新算法框架。
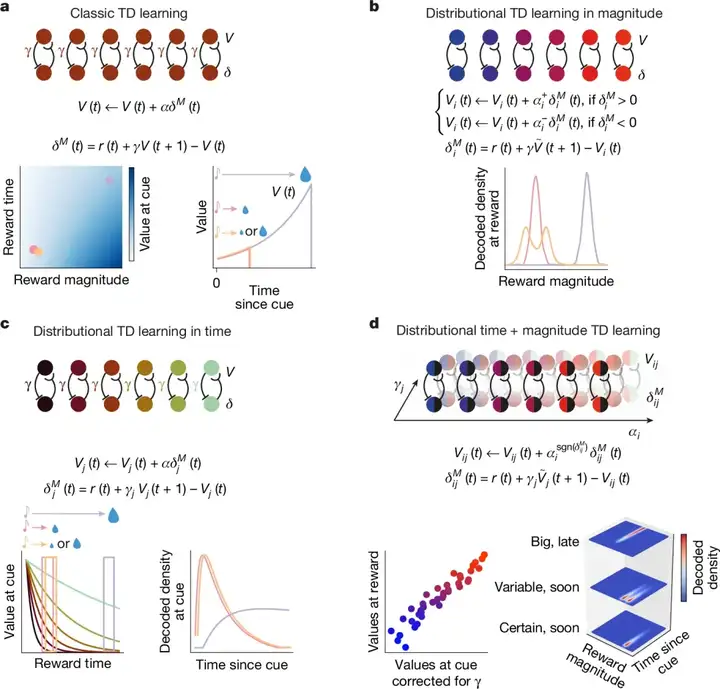
▷图5,TMDL算法框架和其它时序差分学习的差异,图a的传统方法,将奖励时间(延迟)和幅度(大小)压缩为单一标量值,图b引入多个估值函数,粉色线索(小额确定奖励)与橙色线索(小额可变奖励)可区分进行响应;图c,每种奖励对应不同的时间折扣因子,紫色线索(大额延迟奖励)的响应区别于其他小奖励,图d同时加入了上述两种异质性,从而得以构建一个对未来奖励预期对二维地图
TMRL不仅是一个理论上更优的框架,它还能惊人地准确描述真实大脑的运作方式。研究者发现,该模型能够完美预测实验中小鼠中脑多巴胺神经元(DAN)的活动模式。

▷Masset, P., Tano, P., Kim, H.R. et al. Multi-timescale reinforcement learning in the brain. Nature 642, 682–690 (2025). https://doi.org/10.1038/s41586-025-08929-9
研究者利用了动物的瞳孔大小会根据奖励历史来更新奖励预期的趋势,发现奖励历史驱动了对预期奖励期待的更新。同时,多巴胺能神经元的反应包含了系统在奖励大小即将发生变化之前预测未来变化所需的信息。例如,仅从奖励给于前450毫秒这一阶段多巴胺能神经元群体的激活情况这一被高效动态编码的信息,就可以估计未来奖励的多维分布图。
除了TMDL的框架能够描述实验数据外,相比于传统的时序差分学习,优势在于其能够零样本适应奖励给予时间与幅度的变化。
在一个纯计算模拟实验中,研究人员让小鼠处于3种可能的环境下,一种是在黎明提供小额即时奖励,第二种是全天提供可变幅度奖励;第三种则是在黄昏提供大额延迟奖励,以观察小鼠会选择。该情况下,当小鼠从黎明到黄昏的时间段内活动时,其时间折现因子(即对延迟奖励的折扣率)会逐渐降低,导致黄昏阶段的大额延迟奖励感知价值上升(因其等待时间缩短,主观上变得更容易获取),这反映了环境的动态性;同时,小鼠的决策偏好受内在生理状态调节,例如在饱腹状态下,相比饥饿状态时,会显著降低对大额但伴随风险的奖励的选择倾向。
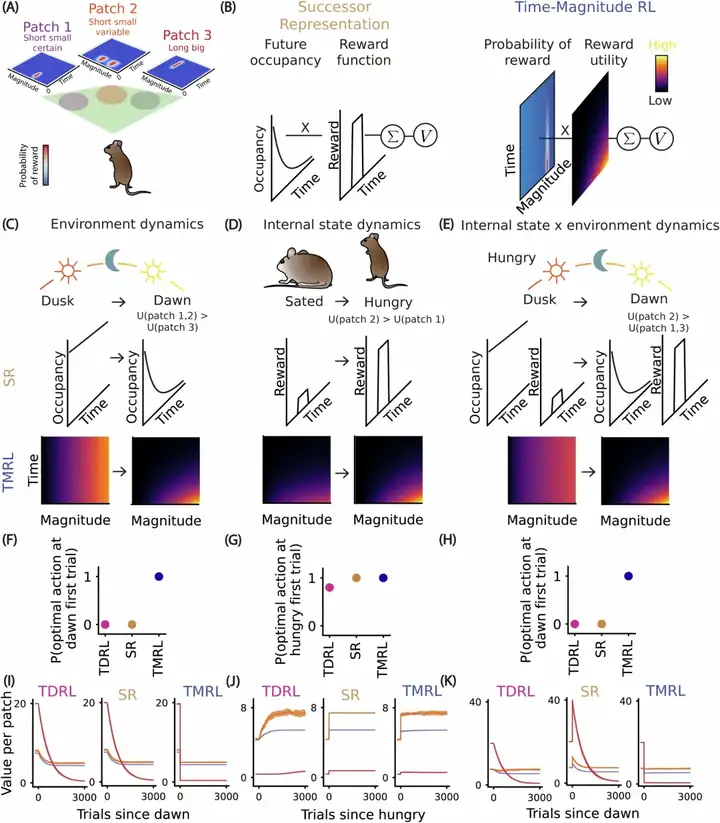
▷图6,对比TMRL和传统时序差分算法及后继表示法(Successor Representation)在尝试次数上的对比
结果显示,当内部状态切换为“饥饿”时,TMRL算法能够像真实动物一样,在第一次尝试中就立刻选定提供即时奖励的最优区域。而传统的时序差分学习(TDRL)则完全失灵,必须通过大量的经验试错,才能从头开始重新学习正确的策略。另一种较为先进的后继表征(SR)算法表现居中,虽无需完全重学,但仍需更新内部模型,无法做到TMRL那样的无缝切换。
这便意味着,TMRL算法并非在被动地“学习”一个固定的策略,而是在主动地“查询”一幅早已构建好的、包含万千可能的未来地图。当条件变化时,它只需调整地图上的权重,就能瞬间找到新的最优路径。
行文至此,笔者想到了如今人们谈起大模型时,会说大模型化身马屁精,表现出讨好人类的谄媚行为。笔者猜测这背后的原因,可能就在于当下的强化学习,人类偏好对齐都是只关注实时奖励。而大模型如同前文提到的小鼠,需实时适应动态奖励规则,其决策受时间折现因子影响,而忽视了用户对话是动态环境,模型通过强化学习优化即时反馈,但未系统追踪长期交互价值,从而导致大模型对齐的是人类的短期偏好而非长期价值。由于大模型缺少类似TMRL的二维的奖励地图,当人们发现大模型表现出谄媚行为,并试图矫正时,往往需要重新从头训练,而不能零样本地打个补丁做快速调整,让大模型不再那么谄媚。
如今观测技术的进步,使得研究者能够持续观察多个神经元动态。由此得到实验数据表明,多巴胺能神经元可以对奖励的感官特征、动作或环境特征等均表现出敏感性,并可构建环境结构的内部模型框架。因此,输出单一的、无模型的时序差分强化学习框架需要升级为TMRL,以更准确地描述大脑中的时序特征。智能体需要记录事件间关系,从而形成类似的时序图用于追踪事件间时序关系,该能力不仅对其生物体的生存很重要,还可能有助于因果推理。
20多年前,多巴胺神经元的发现,引发了学者思考人脑中是否具有类似强化学习中时序差分算法的运行机制。之后的诸多研究指出,多巴胺并非是唯一在大脑中调控不同“工作模式”神经递质,神经元可以释放多种神经递质,也可被多种神经递质影响,多个神经递质间也存在相互关联。在人工神经网络的算法改进中,也有诸多试图引入神经递质的尝试。这无疑显现了人工智能与神经科学双向奔赴中的一个方向。
经典的时序差分算法将关于奖励时间、大小和质量的信息压缩成一个单一的标量值。该值以一种通用货币表示预期的平均时间折扣未来奖励的总和,感官特征以及关于奖励大小和时间的明确知识都会丢失。但是,前述实验证实这不符合真实情况。而人工智能算法的改进,例如从传统的时序差分学习升级为TMRL后,就能对多巴胺能神经元的活动进行准确建模,从而再现多巴胺能神经元在给于奖励前450ms时对未来奖励的预测,这是人工智能算法指导神经科学研究的体现。
在关于TMDL的Nature论文[5]的结尾,作者写到:尽管我们已经解码了从多巴胺能神经元群体中未来奖励的联合图谱,但我们仍然不清楚这些信息是如何以及在大脑的哪些神经回路中被读取的。我们认为多巴胺能神经元的反应源自对其上游输入的估值表征,这些表征可能更直接地参与指导行为。未来需要确定这种信息如何影响生物在复杂和动态的自然环境中面临的问题。而对该问题的回答,笔者猜想或许可以通过计算神经科学与人工智能模拟在虚拟环境中(如minecraft)优先尝试此问题。
[1] Schultz, W., Dayan, P., & Montague, P. R. (1997). A Neural Substrate of Prediction and Reward. Science, 275(5306), 1593–1599. https://doi.org/10.1126/science.275.5306.1593
[2] Guseva, D., Wirth, A., & Ponimaskin, E. (2014). Cellular mechanisms of the 5-HT7receptor-mediated signaling. Frontiers in Behavioral Neuroscience, 8.
文章来自于“追问nextquestion”,作者“郭瑞东”。


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
