# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本文将介绍 MoE 的构建模块、训练方法以及在使用它们进行推理时需要考虑的权衡因素。
专家混合 (MoE) 是 LLM 中常用的一种技术,旨在提高其效率和准确性。这种方法的工作原理是将复杂的任务划分为更小、更易于管理的子任务,每个子任务都由专门的迷你模型或「专家」处理。
早些时候,有人爆料 GPT-4 是采用了由 8 个专家模型组成的集成系统。近日,Mistral AI 发布的 Mixtral 8x7B 同样采用这种架构,实现了非常不错的性能(传送门:一条磁力链接席卷 AI 圈,87GB 种子直接开源 8x7B MoE 模型)。
OpenAI 和 Mistral AI 的两波推力,让 MoE 一时间成为开放人工智能社区最热门的话题 。
本文将介绍 MoE 的构建模块、训练方法以及在使用它们进行推理时需要考虑的权衡因素。
混合专家架构简称 MoE,它的特点如下:
模型的规模是决定模型质量的最重要因素之一。在预算固定的情况下,用较少的步骤训练较大的模型要优于用较多的步骤训练较小的模型。
MoE 可以用较少的计算开销对模型进行预训练,这意味着可以用与稠密模型相同的计算开销,大幅扩大模型或数据集的规模。特别是,在预训练过程中,MoE 模型能更快地达到与稠密模型相同的性能。
那么,究竟什么是 MoE?从 Transformer 模型的角度来说,MoE 包含两个主要元素:
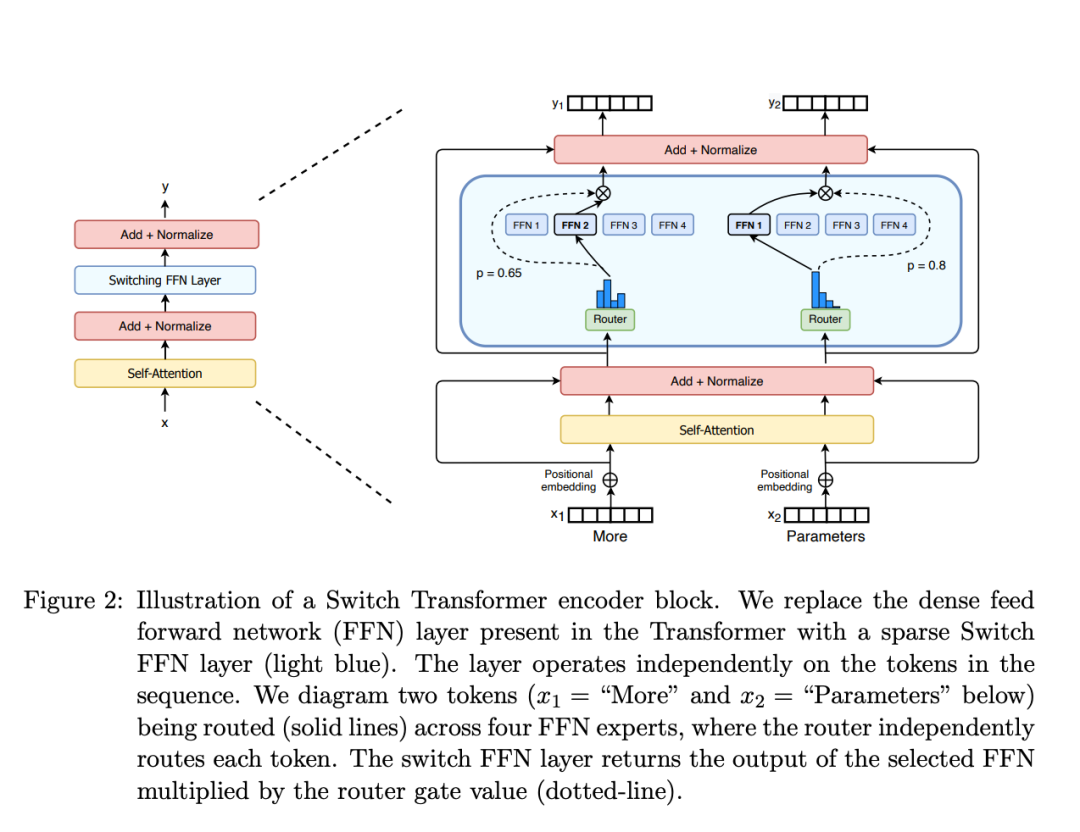
Switch Transformers 中的 MoE 层 (https://arxiv.org/abs/2101.03961)
简而言之,在 MoE 中,一个 MoE 层取代了 transformer 中的每个 FFN 层,MoE 层由一个门控网络和一定数量的专家网络组成。
虽然与稠密模型相比,MoE 具有高效预训练和快速推理等优点,但也面临着一些挑战:
在对 MoE 有了一个大致的介绍后,一起来了解一下 MoE 的发展轨迹。
MoE 起源于 1991 年的论文《Adaptive Mixture of Local Experts》(https://www.cs.toronto.edu/~hinton/absps/jjnh91.pdf)。该论文的理念与集合方法类似,都是为由不同网络组成的系统提供监督程序,每个网络处理不同的训练集子集。每个独立的网络或者说专家擅长于输入空间的不同区域。至于如何选择专家这个问题,是由门控网络来决定每个专家网络的权重。在训练过程中,专家网络和门控网络都要接受训练。
2010-2015 年间,两个研究领域的发展共同促成了 MoE 后来的进步:
这些工作促使研究者们在 NLP 的背景下探索混合专家模型。具体来说,Shazeer 及 Geoffrey Hinton 、Jeff Dean,谷歌的 Chuck Norris 通过对引入稀疏网络,将这一想法扩展到了 137B LSTM(https://arxiv.org/abs/1701.06538),从而即使在大规模下也能保持极快的推理速度。这项工作的重点目标是机器翻译,同时也存在一些缺点,如通信成本高和训练不稳定。
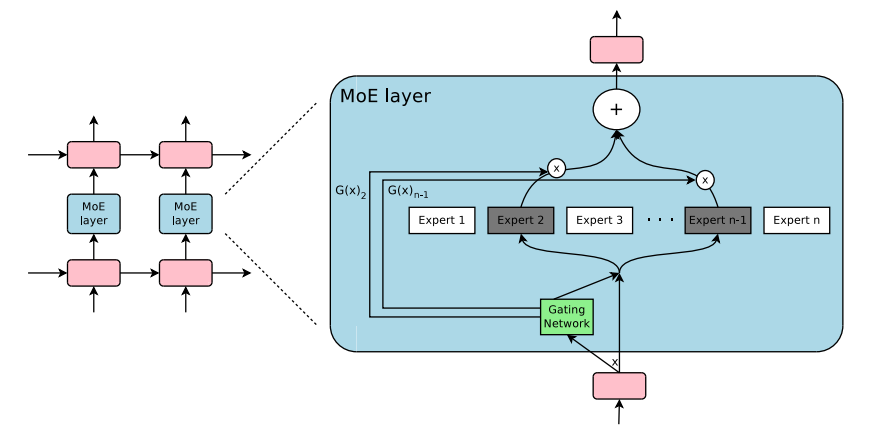
论文 Outrageously Large Neural Network 中的 MoE 层
MoE 可以训练数万亿级参数的模型,例如开源的 1.6T 参数的 Switch Transformer。计算机视觉领域也在探索 MoE,但这里还是先侧重讲解 NLP 领域。
稀疏化一词来源于条件计算理念。在稠密模型中,所有参数都发挥作用,而稀疏化可以只运行整个系统的某些部分。
前文提到 Shazeer 对机器翻译中的 MoE 进行了探索。条件计算(网络中只有某些部分处于活动状态)使得在不增加计算量的情况下能够扩大模型的规模,因此,每层 MoE 都可以包含成千上万的专家网络。
但是这种设计带来了一些挑战。例如,虽然扩大 batch size 通常更有利于提高模型性能,但 MOE 中的 batch size 会随着数据在激活状态的专家网络中的流动而缩小。例如,如果 batch size 为 10 个 token,其中 5 个 token 可能在一个专家网络中结束,而另外 5 个 token 可能在 5 个不同的专家网络中结束,从而导致 batch size 大小不均和利用率不足的情况。
如何解决这个问题?方法之一是让学习后的门控网络(G)决定向哪些专家网络(E)传达输入信息:
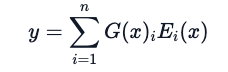
在这种情况下,全部的专家网络会对所有输入进行运算 — 用一种加权乘法的方式。但是,如果 G 为 0 时会怎样呢?这种情况下,就不需要经过相应的专家网络运算,节省了计算开销。那么典型的门控函数又是怎么样的呢?在最传统的设置中,只需使用一个带有 softmax 函数的简单网络。该网络将学习向哪个专家传递输入数据。

Shazeer 的研究还探索了其他门控机制,如 Top-K 噪声门控。这种门控方法会引入一些(可调整的)噪声,然后保留前 K 个。也就是说:
1. 添加一些噪音

2. 只选择前 k 个
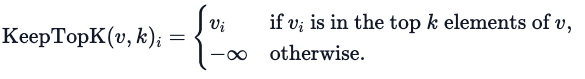
3. 用 softmax 激活。

这种稀疏化操作带来了一些有趣的特性。通过使用足够小的 k(例如一个或两个),研究者发现训练和推理速度比激活许多专家网络的设置更快。那为什么不直接保留 top=1 时的专家网络呢?研究者最初的猜想是,需要路由到一个以上的专家,才能让门控网络学习如何路由到不同的专家,因此至少要选择两个专家。Switch Transformer 的部分将重新讨论了这一决策。
为什么要添加噪声?这是为了负载平衡。
如前所述,如果所有的 token 都只发送给少数几个受欢迎的专家网络,训练效率将变得低下。通常 MoE 训练中,门控网络会收敛到频繁激活同样的几个专家网络。这种情况会随着训练的进行趋于显著,因为受青睐的专家网络会更快地得到训练,从而更容易被选中。为了缓解这种情况,可以添加一个辅助损失,以鼓励给予所有专家同等的重要性。该损失可确保所有专家获得大致相同数量的训练样本。后文将探讨专家能力的概念,即专家可以处理 token 的数量阈值。在 transformer 中,辅助损失通过 aux_loss 参数显示。
Transformer 是一个增加参数数量可以提高性能的非常明显的例子,因此,谷歌顺理成章地在 GShard 上沿用这种思维,将其中 Transformers 的参数量扩展到 6000 亿以上。
GShard 在编码器和解码器中都使用了 top-2 门控技术,用 MoE 层取代了 FFN 层。下图显示了编码器的部分情况。
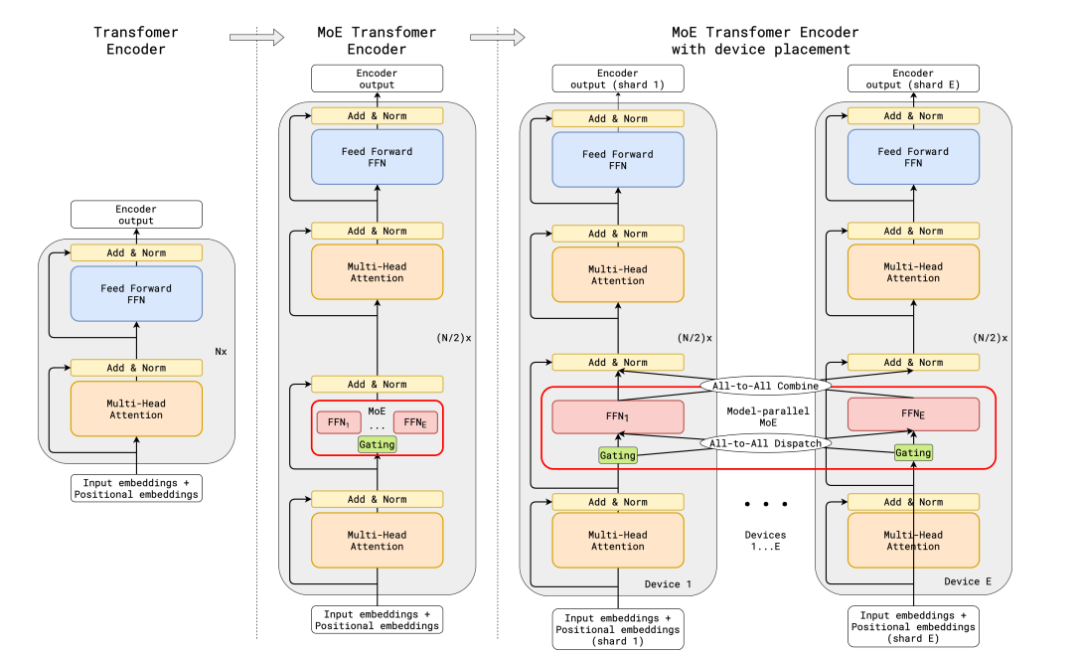
GShard 中的 MoE Transformer 编码器
这种设置对大规模计算非常有利:当扩展到多个设备时,MoE 层将在设备间共享,而所有其他层都将被复制。具体细节在下文的 「高效训练 MoE」中进一步讨论。
为了保持均衡负载和规模效率,GShard 的作者除了采用与上一节讨论的类似的辅助损耗外,还引入了一些改进:
GShard 的贡献在于为 MoEs 确定了并行计算模式。需要注意的是:推理时,只有部分专家网络会被触发。与此同时,还有一些需要共享数据的步骤,比如自注意力机制,适用于所有 token。这就是为什么对于一个由 8 个专家组成的 47B 模型时,GShard 可以用一个 12B 的稠密模型进行计算。如果使用 top-2,则需要 14B 个参数。但考虑到注意力操作是共享的,实际使用的参数数量为 12B。
尽管 MoE 前景广阔,但它们在训练和微调不稳定性方面仍有弊端。Switch Transformer (https://arxiv.org/abs/2101.03961)的出现意义非凡,作者甚至在 Hugging Face 发布了一个拥有 2048 个专家的 1.6 万亿个参数的模型(https://huggingface.co/google/switch-c-2048)。与 T5-XXL 相比,Switch Transformer 的预训练速度提高了 4 倍。
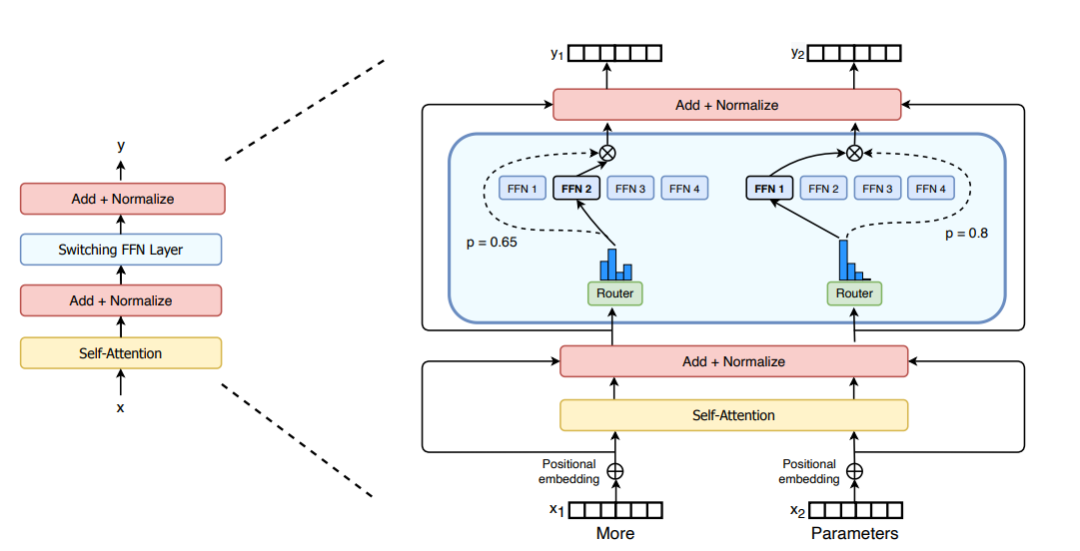
Switch Transformer 论文中的 Switch Transformer 层
正如在 GShard 中作者用 MoE 层取代了 FFN 层一样,Switch Transformer 论文提出了一个 Switch Transformer 层,该层接收两个输入(两个不同的 token),有四个专家网络。
与至少使用两个专家网络的最初想法相反,Switch Transformers 采用了简化的单一专家策略。这种方法的效果如下:
Switch Transformer 还探索了专家容量的概念。
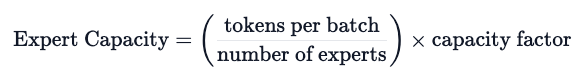
上面推荐的容量计算方法是将 batch size 中的 token 数量平均分配给专家。如果使用大于 1 的容量系数,就能在 token 不完全平衡时提供缓冲。增加容量会导致设备间的通信费用增加,因此需要注意 trade-off。尤其是在容量系数较低(1-1.25)的情况下,Switch Transformer 的表现尤为出色。
Switch Transformer 的作者还重新审视并简化了章节中提到的负载平衡损耗。对于每个交换层,辅助损耗会在训练过程中添加到模型总损耗中。这种损耗会鼓励模型倾向于统一路由,并可使用超参数加权。
Switch Transformer 的作者还尝试了选择性精度,例如使用 bfloat16 的参数精度来训练专家,而在其他计算中使用全精度。较低的精度可以降低处理器之间的通信成本、计算成本和用于存储张量的内存。在最初的实验中,专家和门控网络都使用 bfloat16 进行了训练,但训练结果并不稳定。这主要是由于路由网络参与计算造成:由于路由网络具有指数函数,因此更高的精度非常重要。为了减少不稳定性,路由也使用了全精度。
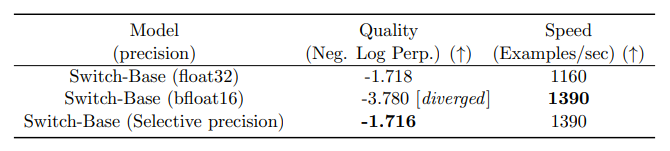
使用选择性精度不会降低质量,并能更快地训练模型。
微调部分中,Switch Transformer 使用了编码器 - 解码器设置,并将 T5 与 MoE 对应。GLaM (https://arxiv.org/abs/2112.06905)探讨了如何用三分之一的计算开销训练出与 GPT-3 质量相匹配的模型,从而扩大模型的规模。GLaM 作者的研究重点是纯解码器模型以及小样本及零样本的评估结果,并不是微调。他们使用了 Top-2 路由和更大的容量系数。此外,他们还将容量因子作为一个指标进行了调研,在训练和验证过程中,可以根据想要使用的计算量进行改变。
上文讨论的平衡损失可能会导致不稳定问题。但是可以使用许多方法以牺牲质量为代价来稳定稀疏模型。例如,引入 dropout 可以提高稳定性,但有损于模型的性能质量。另一方面,添加更多的乘法分量可以提高模型的性能质量,但会降低稳定性。
ST-MoE(https://arxiv.org/abs/2202.08906)中引入的路由器 z 损失,通过惩罚进入门控网络的较大的对数值,在不降低质量的情况下显著提高了训练的稳定性。由于这种损失会鼓励数值变小,因此舍入误差会减少,这对门控中的指数函数会产生很大影响。
根据 ST-MoE 作者的观察,编码专家网络专注于组别 token 或浅层概念。例如,标点符号专家、专有名词专家等。另一方面,解码专家网络的专业化程度较低。其作者还在多语言环境中进行了训练。不同于想象之中,每个专家网络都精通一种语言:由于 token 被路由分发和负载平衡的原因,没有任何一种语言的专家网络是专业的。
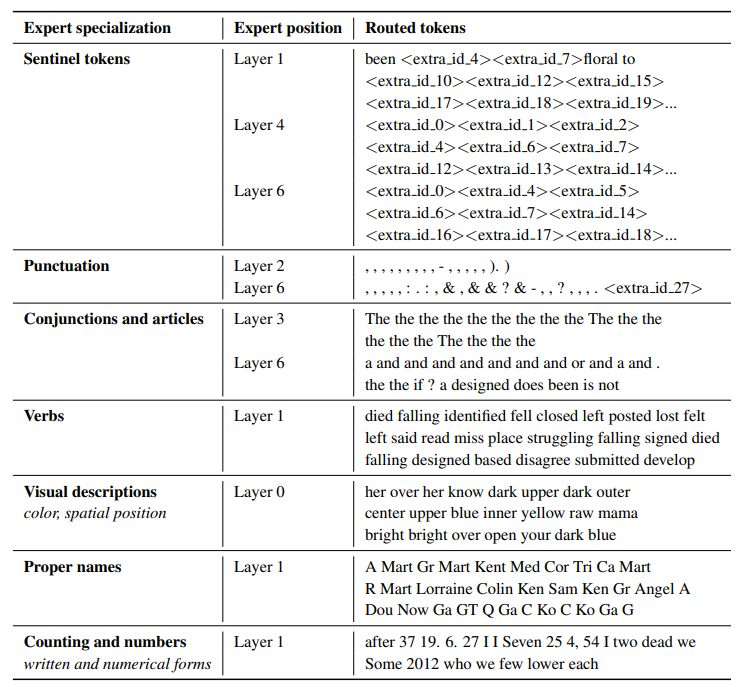
ST-MoE 论文中的表格,显示不同的 token 组分别被发送给了哪个专家。
专家数量越多,采样效率越高,速度越快,但收益也会递减(尤其是在 256 或 512 的量级之后),推理需要更多的显存。Switch Transformers 中研究的大规模特性在小规模中也是一致的,即使每层有 2、4 或 8 个专家也是如此。
Mixtral 支持 4.36.0 版本的 transformers 。使用 pip install "transformers==4.36.0 --upgrade 进行更新。
稠密模型和稀疏模型的过拟合动态截然不同。稀疏模型更容易出现过拟合,因此可以在专家本身内部探索更高的正则化(例如,可以为稠密层设定一个 dropout,为稀疏层设定另一个更高的 dropout)。
还有一个需要决策的问题是:是否使用辅助损失(auxiliary loss )进行微调。ST-MoE 的作者曾尝试关闭辅助损耗,结果发现即使有高达 11% 的 token 被丢弃,质量也没有受到明显影响。token dropping 可能是正则化的一种形式,有助于防止过拟合。
Switch Transformer 的作者观察到,在固定的预训练困惑度下,稀疏模型在下游任务中的表现不如稠密模型,尤其是在推理任务繁重的任务中,如 SuperGLUE。另一方面,在 TriviaQA 等知识密集型语料集中,稀疏模型的表现却好得出乎意料。作者还观察到,专家较少有助于微调。对泛化问题的另一个观察结果是,模型在较小的任务中表现较差,但在较大的任务中表现良好。
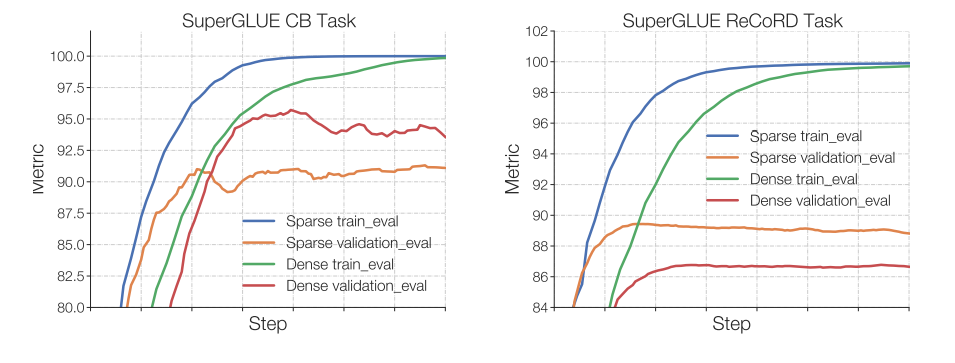
在小型任务(左图)中,可以看到明显的过拟合,稀疏模型在验证集中的表现要差得多。而在大型任务中(右图),MoE 的表现很好。图片来自 ST-MoE 论文。
尝试冻结所有非专家权重导致了性能的大幅下降,不过这在意料之中,因为 MoE 层占据了大部分网络。尝试相反的方法:只冻结 MoE 层的参数后,结果发现效果几乎与更新所有参数一样好。这个发现有助于加快微调速度并减少内存占用。
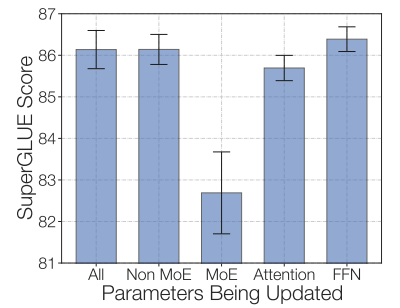
通过只冻结 MoE 层,可以在保证质量的同时加快训练速度。本图来自 ST-MoE 论文。
在微调稀疏化 MoE 时需要考虑的最后一个问题是,不同的 MoE 有不同的微调超参数 — 例如,稀疏模型往往更受益于较小的批大小和较高的学习率。
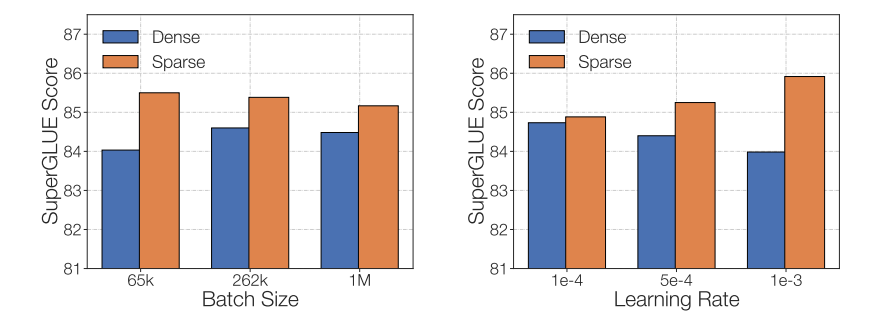
稀疏模型的微调质量随着学习率的增大和 batch size 的降低而提高。本图来自 ST-MoE 论文。
研究者们一直在努力对 MoE 进行微调,这个过程是充满曲折的。最近的一篇论文《MoEs Meets Instruction Tuning》行了这样的实验:
论文中,当作者微调 MoE 和 T5 后,T5 等效模拟输出的效果更好。当作者对 Flan T5 和 MoE 进行微调后,MoE 的表现明显更好。不仅如此,Flan-MoE 相对于 MoE 的改进幅度大于 Flan T5 相对于 T5 的改进幅度,这表明 MoE 可能比密集模型更受益于指令调优。任务变多会让 MoE 受益更多。与之前建议关闭辅助损失函数的结论不同,损失函数实际上可以防止过拟合。
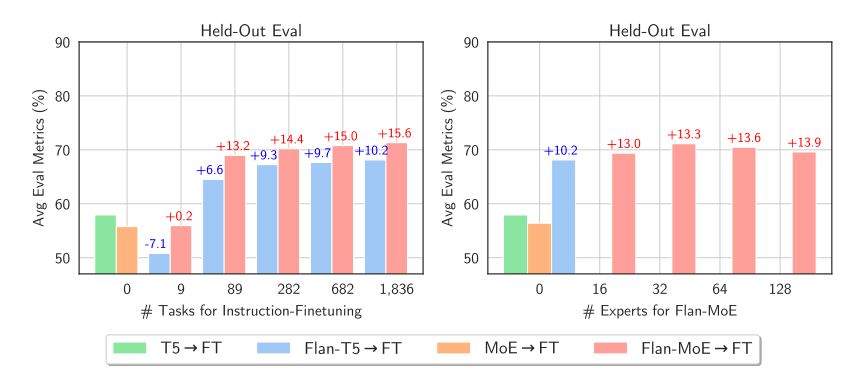
与稠密模型相比,稀疏模型更受益于 instruct-tuning。图片来自《MoEs Meets Instruction Tuning》论文
专家模型适用于使用多台机器的高吞吐量场景。在预训练运算预算固定的情况下,稀疏模型将更为理想。对于显存较少的低吞吐量场景,稠密模型会更好。
注意:不能直接比较稀疏模型和稠密模型的参数量,因为二者所代表的意义明显不同。
最初的 MoE 工作将 MoE 层作为一个分支设置,导致模型计算速度缓慢,因为 GPU 并非为此而设计,而且由于设备需要向其他设备发送信息,网络带宽成为瓶颈。本节将讨论现有的一些工作,以使这些模型的预训练和推理更加实用。
并行计算
并行计算的种类:
在专家并行模式下,专家被置于不同的工作站上,每个工作站采集不同批次的训练样本。对于非 MoE 层,专家并行的行为与数据并行相同。对于 MoE 层,序列中的 token 会被发送到所需的专家所在的工作站。
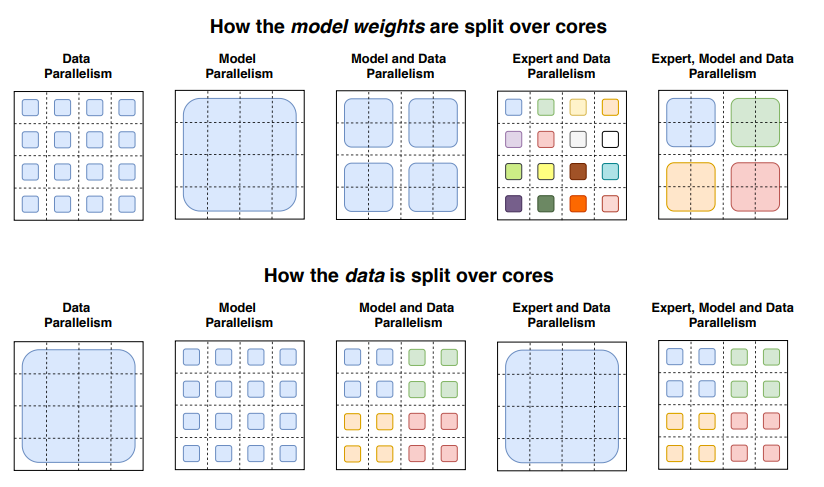
Switch Transformers 论文中的插图,显示了数据和模型是如何通过不同的并行技术在内核上分割的。
提高容量因子 (CF) 可以提高模型质量,但会增加通信成本和内存开销。如果全连接通信(all-to-all communications)速度较慢,使用较小的容量因子会更好。这里提供一个可以参考的配置:使用容量系数为 1.25 的 top-2 路由机制,每个内核留有一名专家。在验证过程中,可以改变容量系数以减少计算量。
mistralai/Mixtral-8x7B-Instruct-v0.1 可以被部署到推理终端上。
MoE 的一大缺点是参数较多。本地用例可能希望使用更小的模型。以下是几种有助于本地部署的技术:
FasterMoE(2022 年 3 月提出)分析了高效分布式系统中 MoE 的性能,并分析了不同并行策略的理论极限,还分析了倾斜专家受欢迎程度的技术、减少延迟的细粒度通信调度,以及根据最低延迟挑选专家的拓扑感知门控,从而使速度提高了 17 倍。
Megablocks(https://arxiv.org/abs/2211.15841)推出了一款全新的 GPU 内核,能处理 MoE 中存在的动态问题,探索了高效的稀疏化预训练。论文中建议不要丢弃任何一个 token,并实现了高效地 token 映射技术,从而显著提高了速度。诀窍在于,传统的 MoE 使用分批矩阵乘法,假定所有专家都具有相同的形状和相同数量的 token。相比之下,Megablocks 将 MoE 层表示为块稀疏运算,可以适应不平衡分配。
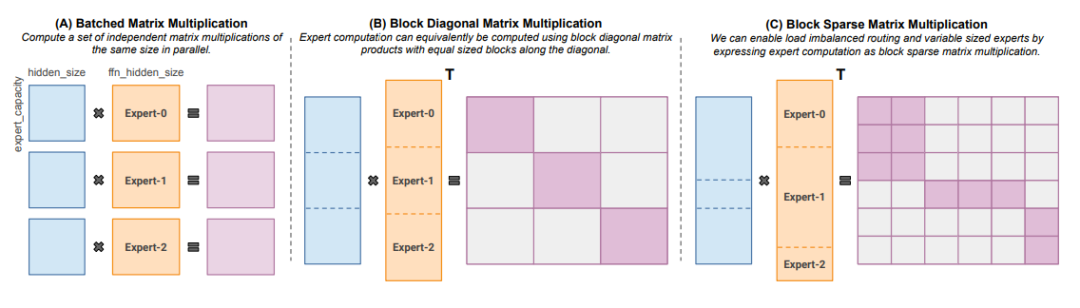
针对不同大小的专家和 token 数量的块稀疏矩阵乘法。图片摘自 MegaBlocks 论文。
当前的 MoE 开源项目:
已发布的 MoE:
以下是一些值得探索的有趣的领域:
原文链接:https://huggingface.co/blog/moe?continueFlag=a09556ebd7121bce97f7bbb8eb2598c8
文章来自于微信公众号 “机器之心”




【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
