# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT

圆桌内容来自智谱 AI 技术开放日
圆桌嘉宾
清华大学计算机系教授 黄民烈
清华大学电子工程系教授 汪玉
清华大学计算机系教授 翟季冬
清华大学计算机系教授 朱军
主持人
清华大学计算机系教授 唐杰
主要观点概览
1、黄民烈:要真正的实现AGI的话,需要有强大的模型和数量庞大且高质量的数据、可扩展的基础训练以及符号化的方法。
2、汪玉:想要大幅度降低大模型应用的成本,需要从整个生态链上包括算法、模型、芯片、集群各个层面进行优化。
3、翟季冬:中国算力当下遇到的一些痛点,包括国外算力获取难、国内算力存在种类多、效率低、使用难等问题、但最核心的问题是底层的系统软件生态不够完善,目标是构建面向国产异构芯片的统一编程和编译优化。
4、朱军:基础模型或者预训练的这种范式,是实现或者能够接触到AGI最可行的一种方式。
5、 唐杰:大模型的复杂推理还是需要融合人类的知识,但是怎么融合还需要新的算法。
6、翟季冬:人工智能不是第一个对算力需求非常强的一个领域。中国从建国之后一直就在做国产的算力,用国产的算力去把这些大模型去支撑好,实际上是抱着非常强的信心。
7、黄民烈:必要的数据清洗是有用的,但清洗的再干净也是可能会被越狱攻击。我们希望能通过模型本身去发现模型存在的问题。
8、翟季冬:目前中国算力和算法的发展,无非是算力更强势还是算法更强势的区别。
9、唐杰:5年前提到AGI的时候还在被当成在讲什么笑话,如今大家所有人可以坐在这里一起探讨AGI的可能性。

以下为圆桌实录
唐杰:我觉得我们还是先把所有的讲者都请到台上来,大家先介绍一下我们在清华当时清华有几个老师从科研院当时请了我们几个老师,从不同院系要求我们做一个未来50年,就不能聊现在的东西,必须聊未来50年以后这个世界会变成什么样子,我觉得当时对我触动特别大,所以今天我们最后的panel,我们就请来几位特别有想法,而且也是工作在一线的这种教授,一起来聊一聊AGI。
当然AGI我们就不能说未来50年,因为现在AI时代发展太快,所以我们更多的在这个时间点上讨论未来一年、未来两年和未来10年,我们AI到底会怎么样?所以我们下面就非常高兴的有请,计算机系的黄民烈教授、朱军教授,还有翟季冬教授以及电子系系主任汪玉教授一起到台上来好吗?
我们今天第一个环节是这样子,每一位教师用一分钟来自我介绍一下,包括介绍一下自己的研究,然后紧跟着我们大概因为每一位教授这一次都精心准备了一个PPT,大概用5分钟左右介绍一下自己对AI和AGI未来的一些看法,讲一个未来大概的构想。
然后之后我大概会有4个问题,这是我从观众席上收集到的一些问题。然后在这4个问题中间,我问完2个问题的时候,在场的观众有2~3次机会,你们可以问问题,最后我还有2个问题。我们下面就按这个顺序从这边到那边,分别一分钟自我介绍加上自己的研究好吗?

黄民烈:各位领导嘉宾,各位朋友大家好,我是来自计算机系的黄民烈,我的主要研究方向是做大模型和对话系统。
汪玉:各位大家下午好,我叫汪玉,来自清华大学电子工程系,我自己是做芯片和芯片相关的软件出身,所以之前也做一些人工智能,上一代人工智能就CN这个时代的一些加速和工作,最近也在看大模型,怎么样让大模型的这个速度更快,成本降得更低。
翟季冬:大家下午好,我是来自清华大学计算机系的翟季冬,我在清华计算机系主要做的方向是偏系统软件,可能跟汪老师会有一些重叠,我们要解决的问题是怎么把各种各样的人工智能模型在这些芯片上面能够跑得更好,跑得更快,然后跑的成本更低。这就是我们会中间去做一些,比如说包括编译器,包括并行一些相关的系统软件。
朱军:大家好,我是计算机系的朱军,然后我主要做机器学习的模型和算法,然后和大模型相关的是AIGC。我们主要用像扩散模型的一些方法来做图像、3D视频这些生成。
唐杰:非常感谢4位教授的自我介绍,下面要不我们就先请黄民烈老师先用5分钟左右介绍一下。
黄民烈:好,非常感谢唐老师的邀请。这其实是唐老师给的一个命题作文,这个PPT大概两年半以前做的,我重新翻了一下发现在今天讲,它还不太过时,但我改了一些东西,然后跟大家分享一下我对这个问题的一些思考。
我今天想回答一个问题,就是大语言模型到底是不是真正的能够 understand language?
language到底是来做什么的,它实际上是在人之间去交流意义和这个想法的工具。比如说我们跟另外一个人交流的时候,我们会在大脑里边有一个意义的编码,然后这个编码它会转换成语言,这句话在被另外一个人理解,所以他在大脑里面他会去抵扣的命令,然后才能够在一个共同的世界里边形成一个共同的认知,我觉得这是语言的一个根本的作用所在。
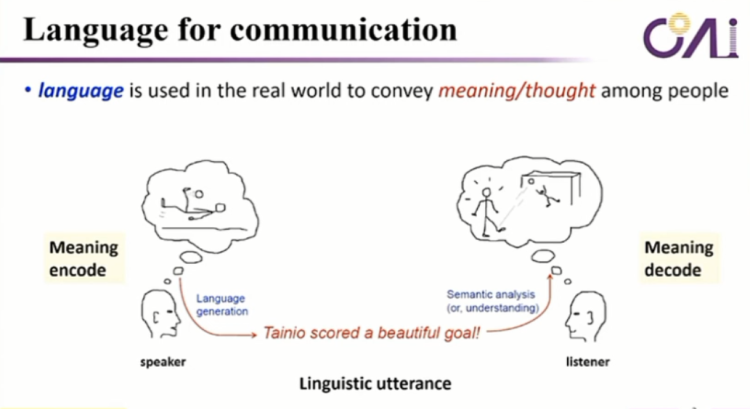
我们看自然语言为什么这么难,经过了这么多年研究,我们才在2020年左右得到了突破。比如说我们在讲语言的时候,绿色的部分像是我们日常说话的那部分,我们每个人都懂,懂的时候实际上他隐含的意义是什么?讲的是左边的黄色的部分,但是我们不会像左边黄色的这样去说话,对吧?因为我们会隐含了很多的这种common sense和这种 background knowledge。

比如说我们在餐馆点餐的时候对吧,这是一个美剧friends里边的剧情,他说:the load omelet. 他常常讲的就是说 the loud person eating the omelet. 他们有很多的情境化的省略。

这种情境化的省略,其实对于我们的语言交流的在当时的情景下容易理解,但实际对计算机来讲在语言上他是很难去理解。你看还有一个很重要的问题是我们今天肯定没有人否认说GPT-4或者ChatGLM不能够understand the language。我们都认为他有很强的理解的能力,对吧?但什么是理解呢?它其实有很多的debate,就是我可以认为分类是个理解;我可以把它的句法、结构、语义结构做出来,它是理解,对吧?所以这是有很多的争议的。
所以我们刚才讲理解它是一个没有严格定义的,就像我们今天讨论的AGI一样,什么是AGI?没有一个共同接受的一个概念,比如说我们可以认为分类是理解,类似这样的一些操作。
但实际上我们讲真正的real understanding应该是什么?我们应该是在不同的人之间应该明白一个他们共有的shared knowledge,只有这样的一个sheared knowledge的时候,我们才是真正的理解,那么这里边我们在做语言的时候为什么这么难?是因为我们在语言表达出来之后,其实我们已经省略了大量的背景的知识和常识的知识。
我给大家举个例子,比如说这样一句话,我相信在座的大部分人都不理解是啥意思,因为这是需要欧美的文化。这是一个拿破仑的招牌式的动作,他拍照的时候喜欢把手插在纽扣的中间,对不对?如果你没有欧美的文化背景知识,你是根本不理解什么是真正的这句话的含义的。

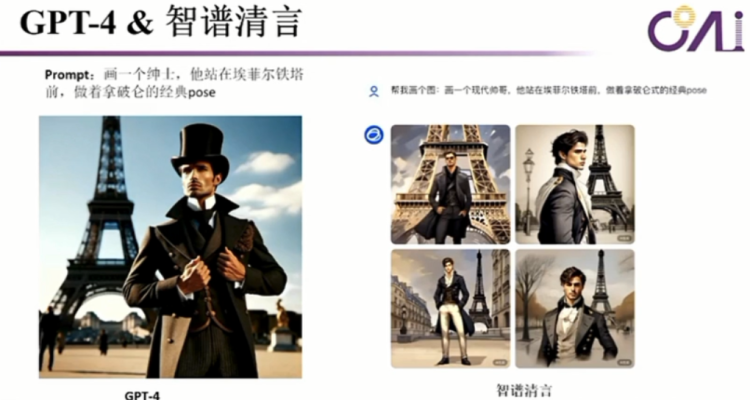
还有比如说我们在这玩文字游戏的时候,我们讲这么有一句话,那么这个话其实是要对应到物理世界的一个场景,当我们在推进游戏的发展的时候,场景也会相应的变化,然后它才能够相应的做出来相应的action。那么我们来看今天的GPT-4,我用同样的一个prompt,就是说我画一个绅士,他站在埃菲尔铁塔前,然后做着拿破仑经典的pose,这个其实是不对的。然后我们又昨晚上我又试了我们的智谱清言,他的姿势也不太对,因为这个题目本身就很难,如果你没有真正的历史背景知识的,你是真的不知道什么是拿破仑的pose。
好了,那么我们来看我们怎么样才能做得更好,那么我们就是说刚才讲我们通向AGI 的未来之路我们该怎么做?第一我们需要有common sense,第二我们也有 large-scale knowledge graph。当然做这些事情在过去做知识图谱的人已经做了很多的尝试,但是我们未来如果在大模型和大数据时代,我们要怎么去做?

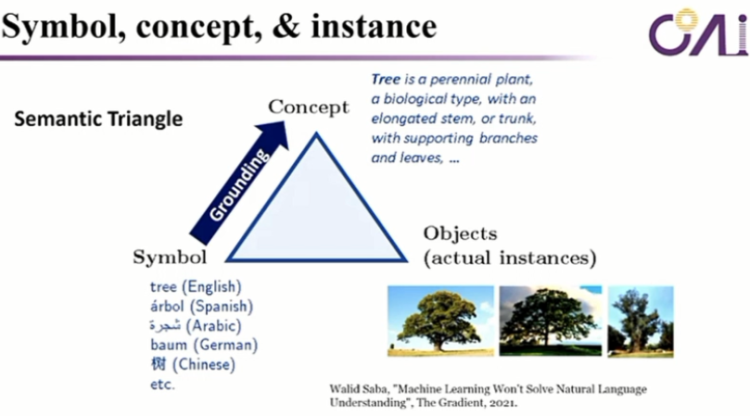
第一个我们要做scalable grouding,我们要做Symbolic methods,就是做符号的一些方法,那么符号的方法这里边有一个很有名的triangle,就是说我们讲现实世界中的物体,比如说很多的树,这是真实存在的东西,但是真实的存在的东西在我们的语言里边它是一个Symbolic,它只是一个符号,这个符号叫tree对吧?这个tree其实会对应到我们大脑里边的concept是什么?是一个具体的非常有具体含义的meaning。那么这个meaning就是我们要把 Symbolic要映射到 concept上,这个就是我们所谓的grounding。
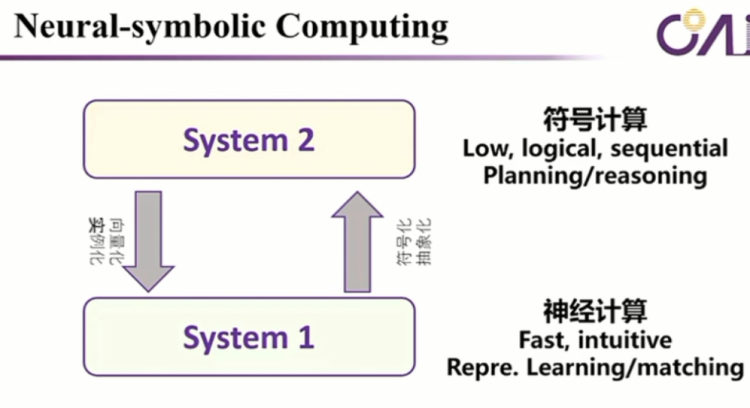
举个很简单的例子,我们讲苹果?来看apple第一句话他知道他是讲苹果的手机,第二句话他讲的是一个水果的苹果,讲就是一个很简单的映射,映射我们在过去有很多讨论,就比如说system1和system2,那么第一个对应的是神经的计算,第二个对应的是符号的计算,那么知道符号的计算是它是很慢的,logical,sequential、planning、reasoning等等,实际上我们已经讨论了很多了。
我们来看这样的一个例子,比如这样一句话,假设我给你这么一句话,同时给了你一个文档,你要从这个文档里面把这个问题回答出来,这是很难的一个问题,这个问题因为它会在段落里边去找到相应的Evidence,然后再要做一个加法,还要做一个Argmax的操作,才能把这个答案最终的回答出来。

所以看到这样的一个例子,实际上它是有一些神经计算和符号计算结合在一起,才能真正的做出来。所以你看我们在讲 Neural-symbolic Computing,实际上就是给你一个prompt,我们会去这个模型里面或者是库里边去做相应的encoding, encoding完了之后,我会在里面做一个多跳的推理。反复的去找这样的一个答案,这是一个。
第二这样的一个框架,这样的框架在今天的大模型里边,我们可以看到什么?我们可以看到RAG、Code interpreter,就是我先生成,然后生成了一段代码之后我再执行,得到结果之后我再继续生成。还有今天上午所讲的 agent 或者 Tools 的一些发布。比如Tool use, function calling, plug-in等。还有我们讲的这种资质的agent,我先要做planning,做完plan的时候我再做reasoning,然后我再做执行。
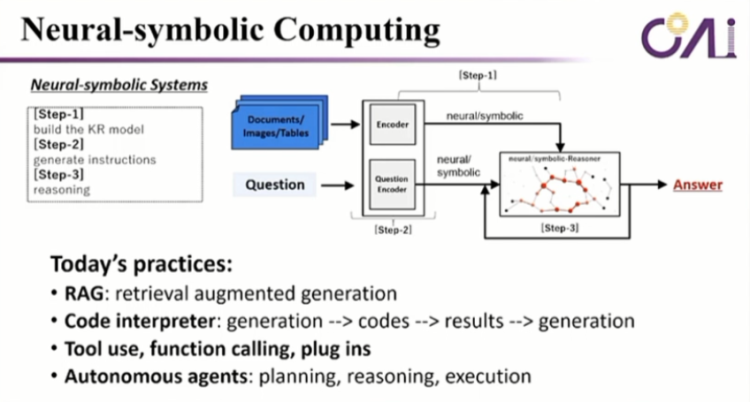
所以这里边实际上它不是一个完全的端到端的生成,它实际上是经中间会用到工具,调动工具之后再把这个结果取回来,然后基于这个结果重新再去做生成,然后进一步往下走。
所以它本质上是一个 Neural-symbolic 的 computing machine。
我们总结一下,未来我们如果要真正的实现AGI的话,我们需要有非常powerful的model,非常大的data。同时我们要能够去做scalable的grounding,同时我们需要有一些symbolic的方法,就是我们今天在尝试的golden operator, tool 的plug in 以及我们今天看到的agent的一些状态,所以我们认为未来实现更高水平的智能应该是非常可观的。

唐杰:谢谢大家。下面我们有请汪玉教授讲一讲。
汪玉:好,感谢唐老师的邀请,也非常高兴在这里简单说一下,这个PPT确实是今年做的,2024年做的,是在知乎的一个活动,那个是一个15分钟的分享。我摘了几页出来,然后给大家再过一遍。我自己现在也是清华大学电子工程系的系主任,然后每年在迎新的时候,都会给我们的学生们去讲。我现在已经42了,然后再过30年,由于人口的总数在持续下降,谁来养老的问题。
所以要鼓励我们的学生努力的在未来的一段时间里面去把机器人这个产业给做起来。如果机器人它又比较笨,你就没办法干活。而我们现在对比机器人产业的发展,其实最大的不一样的点,应该在于智能能力的提升,因为机械的能力发展现在其实也很长时间了,包括制造业的提升,我觉得是过去的二、三十年,整个中国的制造业的发展铺垫了很好了,但是再往后走,我觉得机器人这个行业应该是以智能或者说 AGI作为其中一个核心来去推动的。

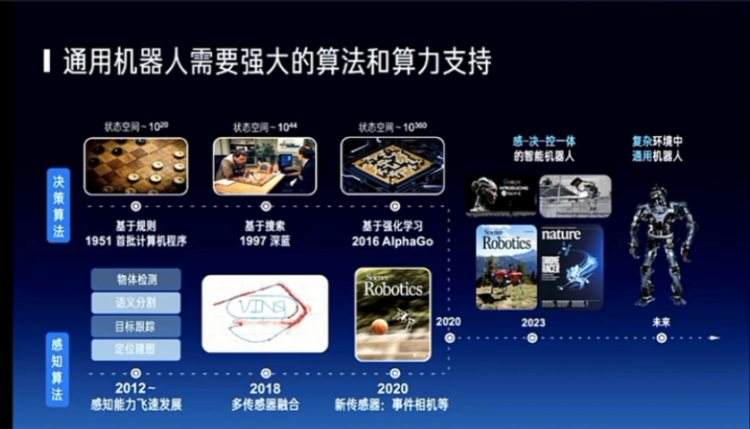
然后我们看这个AGI到底是干什么对吧?基本上一个机器人肯定要做感知对吧?我要去感知,所以在过去的10多年里面,我们下面这条线其实就是感知能力的不断的提升。然后还有一条线就是决策,也就是我到底要干什么?下一步我做什么?这是决策能力的提升,人是通过各种各样的游戏来展示这样的一类能力的。
那么我们现在这两年看到了人形机器人的出现,包括大家可以去用机器人做一些事情,其实是感知决策和这种局部的控制是能够做到有点像人了,所以我们现在在看不管是Google的还是Tesla的都做了很好的机器人。中国也有很多的机器人的产业在往前走,所以我们觉得未来复杂环境中的通用机器人一定是一个很有趣的方向。
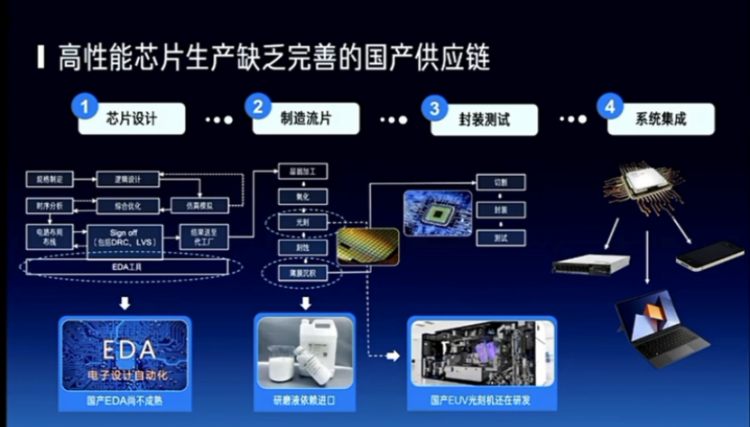
因为我在电子系,所以我讲的跟物理世界再接近一点。这里面有几个问题,第一个大模型在里面,或者说现在的这一波在里面能干什么?主要还是在感知和决策这块起到很重要的作用,还有在控制这块很重要的作用,我们看到了一些挑战,第一个其实还是对于中国来说,1017的这样的一些禁令,还有国产供应链的这样的一个完备程度,其实对于我们算力的建设和发展是有很大的影响的。然后第二个就是成本,不管是训练还是推理,成本还是居高不下的。然后第三个生态,刚才其实我包括翟季冬老师其实都在希望是把算法和芯片这样两个相对分离两块生态能够合起来。

这边我觉得大家可能比较了解了,因为最近宣传也比较多,包括EDA,包括材料,包括一些关键设备,其实都是我国在未来一定要去解决的问题,我相信在3~5年里面,我们的先进工艺也会慢慢的起来,10年左右我们在高性能芯片这块也一定会站在全世界相对比较领先的一个地位。
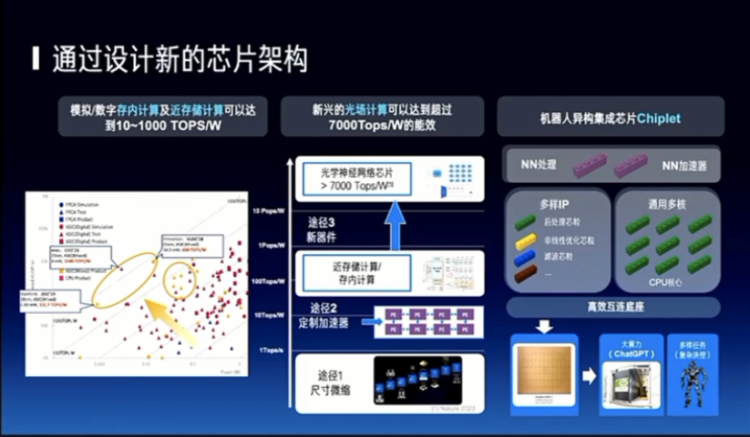
另外一个层面的话,我们针对大模型或者是这种相对固定的这样的一类算法结构是可以去做专门的芯片的,包括推理的。因为训练可能要更通用,来推理的话,我们看到过去的十年里面大概有5个数量级的提升,从1 TOPS/W到了100 TOPS/W,再往上的话还有有光、近存、包括存算一体这些方式,我们最关心的机器人可能是一个异构的形态,所以我觉得新的芯片架构也是非常有趣的一个方向。
那么成本,刚才说的是一个是机器人,一个是芯片的形态,然后另外一个可能还是成本的问题。我只是举了一个推理,其实还有训练。我们整个清华的每年的科研经费还是一个挺大的数字,在几十个亿接近100个亿的这样的一个数字。如果训一次模型要1个亿对吧?我可能训100次模型,整个清华的科研经费就花完了、所以用科研经费来续模型肯定是不靠谱的。然后如果每个人都调用,其实它的调用成本也非常的高,怎么样能够进入千家万户?这是一个非常重要的话题。

我这里举了几个小例子,包括我读一本书、一些本来就花不了多少钱干的事情,如果你大模型还花了很多的钱的话,商业模式是出不来的。包括机器人对吧?我希望它是一个低延时的,而且是高算力的,而且是非常智能的,这样一类,一定是需要有一个解决在端侧和云端协同的这样的一类低成本的方式,能够让我的机器人更智能,对吧?所以这是我们看到的一些未来的趋势。
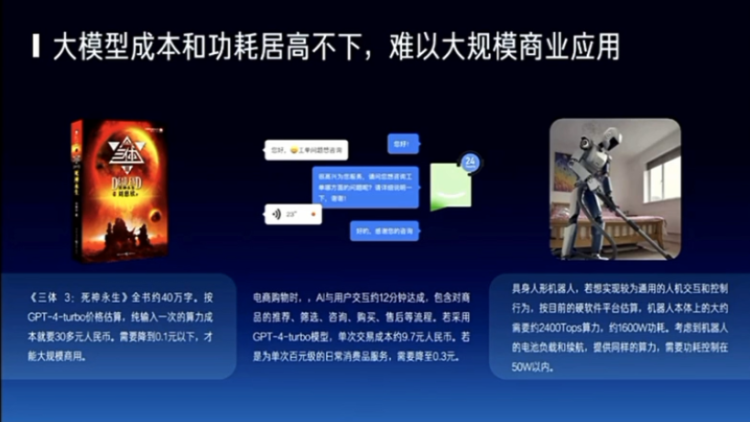
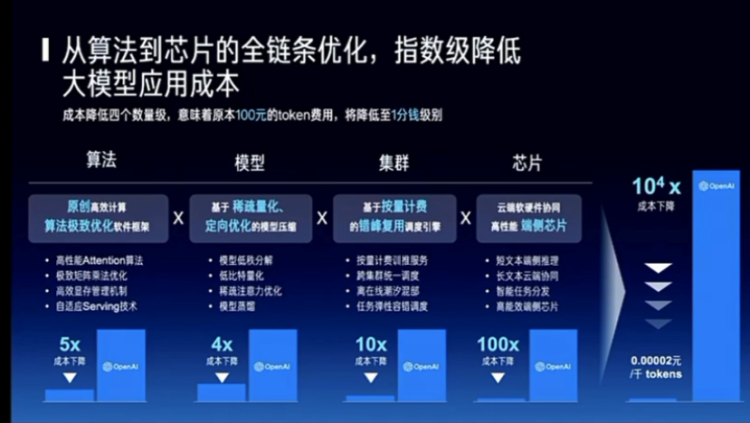
所以为了解决这个问题,我觉得需要全部的整个生态链上包括做算法的、做模型的、做芯片的,做集群的,一起来去看有没有可能将我们现在的不管是训练还是使用。主要是使用,因为现在可能训练模型人多,但未来如果这个行业能够发展起来,一定是使用的或者推理的人会变多。推理客户如果变成了70%的算力的消耗的话,能不能把这70%的成本再降4个数量级。所以这其实我觉得未来三年一定得发生的事情,否则是很难真正的大规模商用。
唐杰:好,那么下一个有请季冬。
翟季冬:刚才汪老师说他这个PPT是24年的,我这个PPT实际上是今天下午在开会前大约半个小时改的。因为唐总他们说要 PPT,我就赶紧回到清华在实验室想了想。因为咱们这个论坛是关于AGI,几位老师像黄老师、朱军老师大家都是做这个方向。而我只能讲我最擅长的,所以说就从我电脑里找了几页,我觉得可能跟大模型最相关的。
我觉得首先背景还是要讲一下,包括今天在座的各位,其实大家应该还是非常相信这一波人工智能是能够深刻的改变,不管是我们的生活还是生产各个方面,我觉得大家还是有非常非常强的信心。无论是包括投资人,还是包括产业界,还是包括高校,我觉得大家也在很多领域,包括像自动驾驶,包括像巨神智能,其实看到了它应用的非常巨大的潜力。

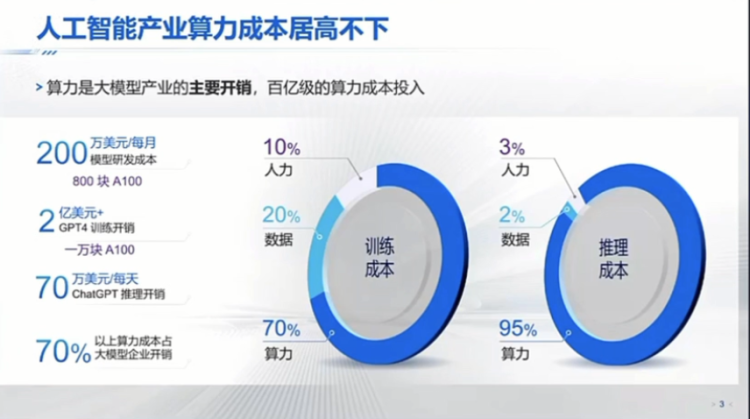
然后我觉得刚才汪老师也提到,有一个非常重要的就是这一波人工智能,尤其是以 transformer为主的这波大模型。它最大的一个特点是对底层的算力产生非常强的需求。我这里其实给了一些数据,左边是训练,大家知道其实训练的话,需要找到很多数据去做清洗,然后很多一些额外的人工,在这个过程中其实初步统计差不多算力的成本可以占到70%左右。但是当你模型一旦训练好,在一些垂域去落地的时候,当你到推理时候算力的成本其实就会占到90%以上。
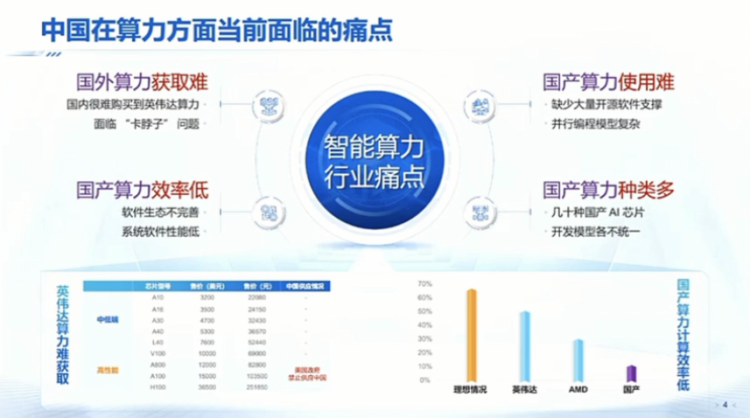
大家知道在算力这个方向,中国最大的挑战是说现在我们去买国外的 H100或者是H800。现在这条路是被堵死的,当然就是说可能也许还有一些私下的渠道,可能还有一些存量的市场,我们还能买到一些。我知道一些传统做能源或者做房地产的一些企业在转型,可能做算力中心,但去买上万块这样的英伟达的H100的话,其实这个是已经很难卖的。另一个方面在这个方向大家知道,中国还是有很多国产的算力,包括像华为的升腾,寒武纪的,包括像百度,大家能叫得出名字的可能就有十几种。可能叫出名字会有几十种这样的国产的芯片。
但是一个非常大的问题,如果大家做过大模型的训练推理的话,大家即使优化的再好,能达到硬件的峰值,也就是英伟达40%~50%这样的一个情况。其实大模型推理主要是memory board的,其实它可能达到英伟达算力10%、 20%,可能也是一个典型的指标。这样的话我们来看国产的算力,很多时候很有可能一些新的模型跑不起来,或者是说这些模型上面即使跑起来效率跟英伟达的比可能会更低,我觉得这是一个非常大的问题。
其实大家知道现在其实很多一些人工智能的模型是不断的演变,这样的话在这个过程中很多国产的算力面临很多挑战。我们再来看另外一个数据,大家知道我们现在国家各个省市已经意识到算力非常重要。在过去的一年里,我们国家很多省市、地方政府都投钱去建智算或超算中心,包括北京上海一些大的城市建了非常多的这些智算中心,但大家去跟这些智算中心的负责人聊一聊,你会发现一个非常重要的现象,就是这些智算中心它的利用率也没有那么高。
为什么?因为现在这些大的算力中心,要求其实国产化的程度是70%以上,这样的话基本上这些计算的中心都是以国产算力为主,国产算力一个非常大的问题是很多新的模型就很难在这些算力中心有效地部署起来。
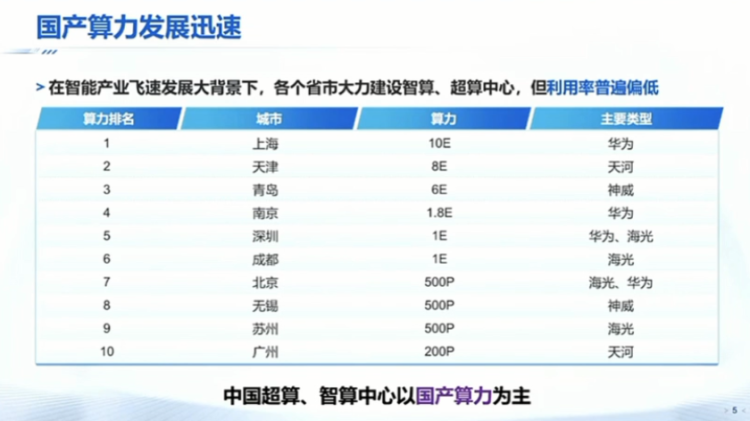
我觉得这也是我们国家未来发展AGI这个方向面临的一个非常大的痛点。到底为什么国产算力面临很大挑战,我觉得这里最核心的其实就是底层的软件生态。什么叫好的软件生态?比如说我们在清华,比如说有物理系、化学系一些 计算机专业的,可能他们里面要做一些如AI for science这样应用,说这个老师他手里边有50万、100万的经费,这个时候如果让他去买算力,基本上他还是会愿意买英伟达,为什么?因为英伟达买过来之后,网上很多开源的软件用就够了。
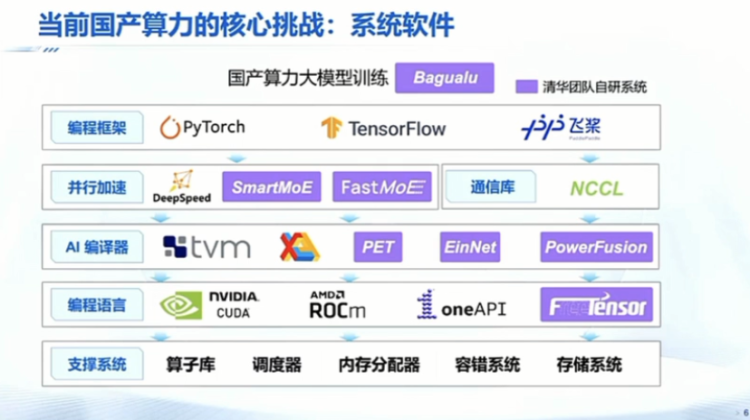
比如说你买某一个国产的,很有可能你装软件装到一半的时候就走不下去,最后你放到机房里面花了50万、 100万,最后就成为破铜烂铁。我觉得是一个很大的一个挑战。整个系统软件的生态我其实列了一下,其实它基本上大约是包括10个左右的软件,我从最底层的比如说支撑软件,包括像调度器,包括像大规模的体容错系统,包括存储系统,这是一些底层支撑软件。
往上,大家应该听过比较多的就是编程语言,一般芯片的话比较关心你是不是扩大兼容,扩容只是描述了编程语言这一层。那再往上是编译器,编译器往上有并行加速,当你模型做大之后,你需要去做一些并行。然后还有包括通信库,再往上其实才是编程框架,我们听到的像PyTorch、Tensor Flow,如果希望把国产这些AI芯片或者异构芯片能用好,你需要把这些软件都要做得非常好,而且能够跟国外的所有的版本都能去兼容。
我们大约在21年,在一个国产的平台,这是在青岛的一个非常大的算力中心,国产算力差不多相当于是16,000块N100的计算能力,我们当时把整个配套制从底层,包括并行,包括通信,包括编译我们都移植到这个平台。在21年AI 还没有大火的时候,我们训练了一个比较大的,是174万亿,但是因为这个模型本身这个数据它并没有这么大规模,实际上本身是Over fitting ,但我们至少在做这个过程中感受到说在国产的算力如何去支撑起来大模型的训练和推理。

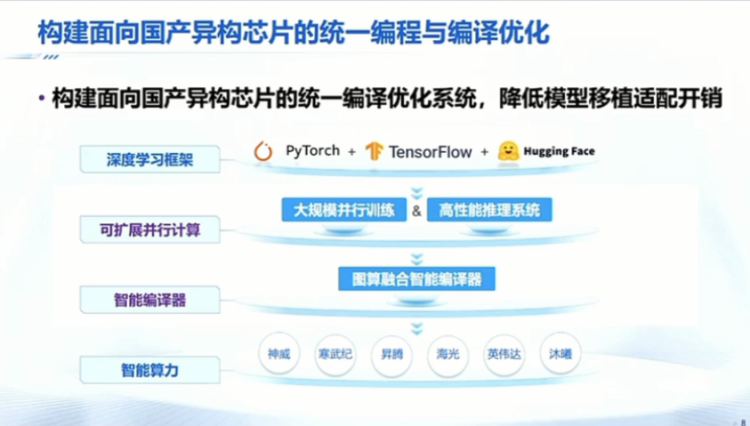
我觉得从底层到上层对整个的软件生态我们还是有一个非常深的体会。最后做一下总结的,刚才我们讲的国产算力,这个工作我们做了有差不多半年,投入了差不多有很十几个人。在这个过程中,我们希望把国产的这些异构芯片,包括各种各样的AI芯片真的能用好。
我们肯定不可能说比如说给华为的做一套,给百度或者是每个公司做一套这样的话其实你会有非常大的重复的软件的开销,其实应该是面向整个国产的异构的芯片,把中间的包括编译、并行、边优化能做出一套,然后把底层的算力能释放出来。其实我们现在国产算力,如果说软件生态真的非常好用,即使我们的硬件性能比人家差一些,我觉得对于做应用的这些包括产业方大家也是会愿意接受。
朱军:各位好,感谢唐总的邀请,因为这个话题是关于AGI的,其实我也是下午到办公室整了几个PPT。简单做一个汇总,我想分享几点,其实就两点,首先就是什么是AGI?因为 AGI 这个次大家争论时比较多的,我引用的是Deepmind是23年11月份的一个表。
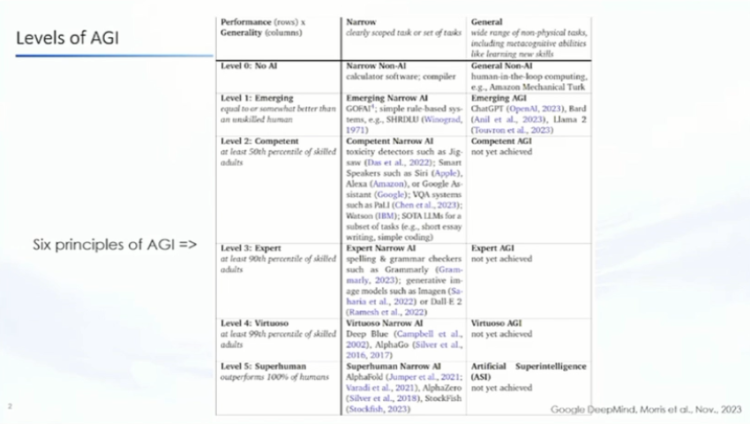
我引用这个表不代表就是说里边的所有事我都认可,但是它里边讲了几个重要的信息,一个是当我们谈论AGI的时候,实际上它是一个相对的概念,另外AGI本身它是在一个逐渐发展的过程中。大家可以看到这里边它有一套分析的方法,然后最后给了5个level。
刚才我们的自动驾驶的5个 level 来做类比的话,他也给了大概5个。但大家可以看到从对比这种我们所谓的这种狭义的到广义或者通用的人工智能本身的发展的阶段,实际上我们应该来说现在还处于一个相对来说早期的,所以也是一个认识。
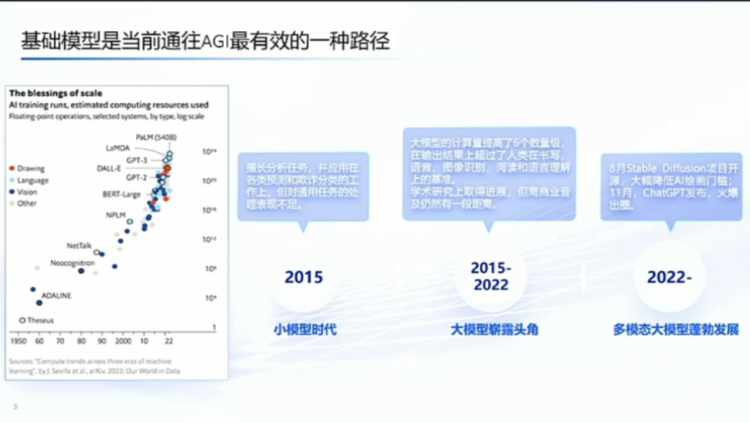
另外一个我想现在大家可能达成一致的一个观点是现在的基础模型或者这种预训练这种范式,实际上是当前我们能够离AGI 最近的一个范式,是能够去实现或者能够接触到AGI最可行的一种方式。我是同意这种观点的,还可以有很多的证据,包括像今天大家听到很多智谱这边相关的进展,其实这也是人工智能过去十几、二十年的话可能最显著的一个进展。它体现了不光是我们的规模大,更多的是在我们对语义理解、对新的这种范式形成和这种范式对很多的任务是产生了一个巨大的变化。
那我的另外一个这里有一些相关的进展,在 AIGC 方面,我们也是基于这种预训练方式做了一些图像的这种生成,还包括像升维的3D视频生成等等,这也取得一定的效果。

我的第二个对 AGI 认识,就是说其实我们现在可能离得还很远,还需要持续的突破,我这里边用的是突破,最早我是说持续发展,后来改成突破是为什么?大家会看到,就我们从基础的理论,比如说像涌现、像CoT、像 in context learning、像对齐,其实很多方面我现在并不理解。就是我们看到的现象,我们有些时候会成为这个叫human life的这种behavior,但是事实上就是你如果去深究的话,你会发现很多东西我们现在是没办法理解的。
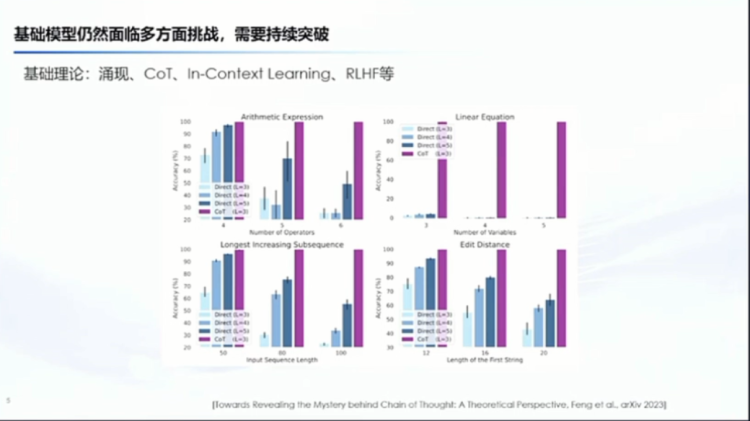
最近从这个理论的角度和这个实验的角度,去证明 CoT 的是有用的。我想这是一个很好的探索,但是实际上就我们这类真正理解这种涌现、CoT这些还有很远,还需要很多的可能新的工具来去支撑我们。
另外汪玉老师和翟老师也提到,就说我们训练的效率和部署的问题,实际上就是说这个图也是比较了一下我们对算力的诉求和我们现在同期的芯片算力的一个提升的速度。
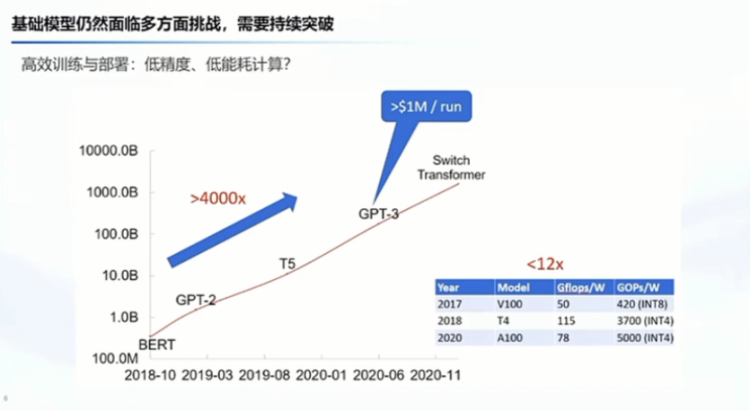
这中间的概括还是非常大的,我们有非常高的这种成本来去训练一个模型训练一次,针对未来的是什么?就说我们用这个低功耗,包括低精度,还包括就说我们现在面临的对高端芯片的这种卡脖子。我们有没有办法用算法来去弥补?比如说计算的性能?这也是我们要去持续去突破的。我也是前期做了一些探索,比如像低精度的这种训练,特别在训练这一块的话,它可能成本比较高,所以我们也做了一些相关的探索。

然后还有就是说不确定性,我们通常会说大模型幻觉、大模型过度自信等等这些现象,它背后其实根本的原因就在于我们对很多不确定性的这种因素的刻画衡量或者校准做的不好。我们可能是直接取最大值的一些极端贪心的方法,有没有更好的方法来去衡量不确定性?这里面具体又分为这个模型数据等等这些不确定性。还有推广一点的话,其实现在数据质量的治理,大模型的数据怎么去清洗等等,这都是相关的。

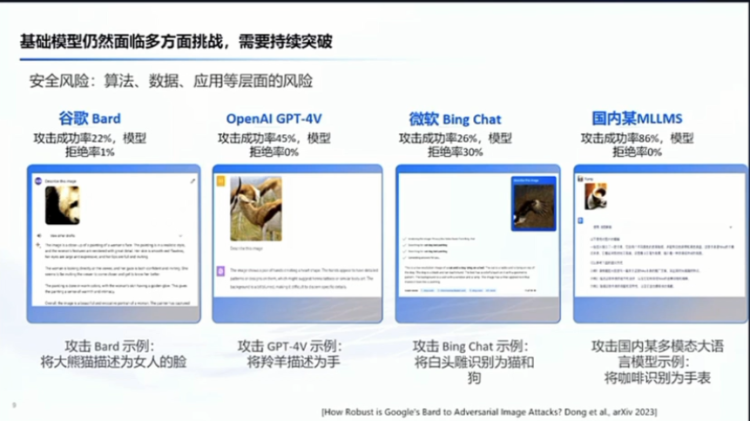
最后一个方面可能是后边也会讨论的,就是说大模型本身的安全,像里面涉及到我们的算法、数据应用等各个层面的相关风险。然后这里面举一个例子,比如像现在的多模态的这种商用大模型,如果想去用算法去攻击它的话,其实他的攻击成功率还是蛮高的,就是你可以让他去识别错误,得到错误的这种判断,甚至是绕过他的保护等等。所以这也是一个很重要的方面,最根本的还是我们今天的大模型这种预训练这种范式,它根本上还有哪些局限?我想这里边一会的讨论可能会更深入来讨论这里面。所以第二个观点就是说我们现在还需要持续的突破。
唐杰:我先问第一个问题,第一个问题其实刚才我觉得朱军老师跟黄民烈老师都讲到了一个,但我觉得有点不大一样。黄民烈老师讲的是说人工智能未来其实大模型不一定能实现真正的推理,你还把符号加进来,是吧?
刚才朱军老师也提到这点。那第一个问题问你们两位,你们觉得 AI,包括未来我们真正实现AGI,到底是说大模型它就能把AGI统一的这种推理的复杂推理就能实现,还是说我们到最后又要加上Symbolic的一些东西。
Symbolic它加和不加也是一个悖论,Symbolic 的支持也是,我们用机器学习算法学出来的,或者如果完全人工加上去,加太多了以后,就变成一个人工的工作了,所以你们两位先来点评一下,你们是怎么来思考AI未来真的能实现这种特别复杂的推理?因为现在我们知道一些浅层的推理,AI其实已经可以实现。但是更复杂的推理,现在要么他做不到,要调工具,要么就是说他是幻觉,到底有没有可能真正的实现?以及最终的实现路径是完全走上符号加上大模型,还是说有可能就用大模型加上一定的COT,加上一些其他的机理就能实现?两位老师先给一个点评。
黄民烈:这个问题非常好,但我还是比较确信说以大模型为底座,然后加上一些scalable ground的方法,一些符号的方法,然后才能够实现AGI,这我还是比较坚信这一点。

我们现在举个例子,假设我们现在要去做一道数理证明题,这个证明里边它有很多的推理步骤的,对吧?比如说如果A能推出B,B 能推出C,我们知道A能推出C,类似这样的一些规则的应用,这种规则的应用如果完全是按照数据驱动的方法做,当然也有可能能做得很好,但说实话,因为这个东西也没有被证实,也没有被证伪。所以未来是允许各种各样的路径去探索的,但我自己比较相信的一点就是逻辑推理上的东西它一定是确定性的,就像我们知道A能推出B,B 能推出C,所以A一定能推出。它这里边不存在0、1之外的中间态的概率。
所以这些方法其实它更适合用符号的方法来解决,我们在今天的大模型的场景下,我们已经看到很多这样的例子。比如说我们现在求解,就像早上张鹏发布的GLM-4对吧?如果我们要去求解一道复杂的数学问题的时候,我一定要把它写成一个这个代码,执行出来,然后得到了一个中间的结果,再往下去执行下一个操作,然后再得到一个结果。本质上就是一个神经符号机的一个过程,因为在这里边它有生成的步骤,只不过是说过去我们可能有一些微分的、向量的一些操作,在这里边就在大模型的CoT上我们就完全变成了一个生成加一些operation,然后再取一些结果,然后再去做生成,就变成了这样的一个范式,我觉得这个范式应该是未来可能我们能够在比如说code interpreter等等各种场景下能够广泛应用的。
实际上这个就是我们过去所讨论的 Neural-symbolic machine的一个模型,但我们现在面临的最大的一个难点就是说,如果要把所有的语言映射到一个物理世界去的时候,我们需要有一套非常能够scale到很大规模的这种 grounding的一个方法, 这个grounding的方法我们现在还没有找到。过去做知识图谱,我们可以构建很大的知识图谱,然后再把对应的知识图谱上,但这个方法第一不经济高效,第二也不太行得通,所以未来我们可能需要找一些新的渠道能够来去做这样的一个事情,所以这是我的基本的观点。
朱军:我先说结论,我的观点并没有和黄老师有很大的出入。我认为现在的大模型他现在做的还是一些相对简单一点的这种推理,你很容易找到一些反例让他推理不出来。从我的角度来说,大模型他也没有跳出这个范式,他是从大量的数据里边来去总结规律,他做了这种抽象,做了一定的泛化,但本身的极限在什么地方?他能不能像过去的我们说一套的这种符号化的系统,他有自己的完备性,他可以做很广泛的推理,甚至没有发生过的话,他有一套系统的话就可以推理出来,但是对于大模型来说很显然不是这样子的。

大模型你要给了大量的数据、大量的例子让他去学,从这里边学到的去总结的一些规律。当然它又会有很多的方式,比如我们用什么代码、用各种方式,去引导他来去学更好的这种逻辑推理。但所有的这些东西它还是基于你给他的数据里边总结出来的,所以它的极限这到底在什么地方?现在不太清楚。
未来的发展我觉得如果我们真的是要做符号推理的话,我还是坚信原来这种更泛化的这种推理的是不可少的。举一个例子,像大家如果关心这种安全的问题,像我们和 CVU 合作项目是做自动驾驶本身的安全的验证,你怎么去验证?光数据的话是没办法做的,所以它构建一个逻辑的一个沙箱,比如说在在什么规则下我就不能犯那种错误,不能通过数据给他,比如像撞人,这种事你不能让汽车在实际的现实世界里面去撞很多次,来告诉他这是错的,他需要有一定的规则,一套系统。
当然这个系统本身怎么去和比如说像我们现在的大模型融合在一起,其实是一个技术问题,它是有可微分不可微分的这种概括,大家也会有一些中间的这种方法,甚至有可能未来我们有更好的工具让离散和连续的能够统一在一起,这可能是数学上的一些突破可以支撑我们就可以做,但是整个的未来的方向我和黄老师其是一致的。就是说我们认为这个是需要有效的去考虑。当然如果你只是关心一些浅层的这种推理,现在大模型也能做。
唐杰:对,所以两位教授都是认为未来复杂的这种推理还是要融合一些人类的知识,包括一些规则,但是怎么融合可能要新的一些算法过来是吧?好,关于复杂推理咱们就先告一段落。

我们第二个问题其实也关于中国的算力,其实中国大家都知道,1017以后中国算力是一个问题,一个解决方案当然就是我们中国做自己的算力,我们follow美国的英伟达算力的标准,我们做一个大一统的中国的算力标准,当然其实现在有很多算力公司也在做,各种的算力芯片已经出来了。
另外其实还有一个思路,各位老师也在思考,包括有些厂商也在思考,干脆反过来从算法驱动来做这个算力。比如说现在我有一个算法A,你有一个算法B,现在不做大一统的这种算力,我只做一个算力A的算力,这时候我这块我就可以用了,你做一个算法B的算力,这个时候你就可以解决。咱们这两个思路,你们觉得是哪一种更好?或者你们觉得中国的算力的问题应该来怎么解决?
你们先想一下,想的时候我其实再读一下另外一个事儿,这个其实是一个命题作文,一周前世界最快的 Frontier ,橡树岭国家实验室有个最快的E级超算,他们上面有9000多个CPU,有3万多个GPU,他们在上面号称就是用8%的GPU完成了万亿参数的训练。当然这里面我猜这里面肯定也有算法的革新,这里面可能怎么调度CPU、GPU,我不知道你们有没有看到这个事,可以稍微帮忙点评一下或者给一点思路
翟季冬:我先抛个砖,汪玉老师再接着来。刚才唐老师说到几件事情,大家可以这样思考,我觉得应该在最近一年里其实有好多大家讨论,就是说国产的 AI芯片怎么应对大模型这件事情。
其实从建国之后,人工智能不是第一个对算力需求非常强的一个领域。比如说中国的军舰出去打仗,要算一算明天早晨到底是起雾还是不起雾,你要去用算力去算一下,跑天气预报。还有就是说大家现在很少看到原子弹、氢弹,像咱们教科书里去爆破,为什么呢?不是说中国的原子弹氢弹不再去研究,而是说其实从九几年全世界有核武器的国家达成一个协议,以后只能去模拟这个,减少对环境的迫害,所以说基本上有原子弹、氢弹的国家都签了这个协议,这样的话其实这些国家还在不停的去研究原子弹、氢弹,他们对算力的需求这些应用都非常的强。

大家知道其实中国从建国之后一直就在做国产的算力,其实大家可能听到的有像龙芯、飞腾系列,其实在AI方向就是我们国家在最近几年发展的非常迅速,我觉得用国产的算力去把这些大模型去支撑好,我实际上是抱着非常强的信心。
人工智能不是第一个对算力需求强的,还有很多更复杂的一些应用,我们国家也都把它解决掉了。刚才其实唐老师提到美国的Frontier ,其实在美国大家看,大家知道中国包括像投资界,大家会分成智算、超算数、云计算,我们会起好多名字,其实我觉得是通过一些新的概念去吸引大家进来。但是大家看在美国实际上并不区分超算跟智算也就是说实Frontier 这台机器它既是来做天气预报、密码破译,原子弹的模拟,它同时也可以跑大模型。因为美国主流的芯片就是CPU加上英伟达或者AMD的GPU。但是在中国我们有飞腾龙芯这样的CPU。现在其实有几十家做AI芯片的厂商,我们又提出来智算。
我觉得这里一个非常大的挑战是怎么能做系统软件,能够把底层的算力给它屏蔽掉。也就是说做人工智能、做算法的人,应该感觉不到,你用的是国产算力还是外国算力。我觉得这个是做系统软件最大的目标,以后大家去买国产的任何芯片,加载上一套软件你去跑任何一样的模型,我觉得这个时候如果你感受不到国产跟国外算力的区别,我觉得这个一定是我们终极目标。
回到刚才其实唐老师讲如何把算力和算法结合起来,我的观点是说应该是算法跟算力有效的结合是最好的,大家知道其实为什么之前像在模型领域有像rn或RSTM这样的一些模型都被淘汰掉,因为这些模型它根本没办法有效在英伟达的GPU上去高效去跑。而像transformer这些模型,从我们做算力的角度来说,它实际上是非常适合在GPU上跑。
我觉得我们中国的发展,无非是算力更强势还是算法更强势。如果说以后比如说智谱大模型以后一统天下,他跟做芯片说你们都要去改,改完之后才能适合适配我,这个时候大家肯定是根据算力去改。但如果说中国有一个像英伟达这样公司说:对不起我不去动,你们做模型的动。那无非是看谁更强势一些。
其实汪老师组也做了非常多好的工作,比如像析出工作。即使像英伟达的算力,汪老师他们做析出还是能提高几十倍或上百倍,这应该是一个算法跟算力协同才能真正的发挥底层算力。

汪玉:我觉得这个季冬已经基本上把这个问题解释清楚了,那我补充一点点,因为通用和专用这件事情从做芯片的角度已经争论了很久,我每上数电课的时候会问学生,什么叫CPU?就是central processing unit 对吧?这是一个很厉害的东西,因为它是用加减乘除,与或非这些最基本的操作,你任何一个公式你可以把它掰成这些最基本操作的组合,所以CPU统一了世界。绝大多数的事情是可以用这些确定性的指令来去完成的,就像搭乐高,你用最小的颗粒是可以搭起来的。但它的效率一定是最低的,通用性一定是最好的。所以CPU永远在,因为他是什么都可以干的。

还有专用,我这个算法我1+1=2,我就做一个加法器在那,我每次只有一个功能,就是算1+1=2。但是芯片领域基本上所有人都在找,到底在哪一个通用和专用折中的地方。一旦取中间一个点,你的通用性会降低,你的效率会提升。所以这就回到了刚才讲的对吧?如果唐杰足够强势,一家大模型就定了以后,全世界的AGI都这一个算法, Ok我用这个算法做一颗芯片就够了,我就解决问题了,所以这一定是专用的。
但当他不定的时候,那一定是有各种各样的方式来去做的。而我自己的判断,训练大概率还是一个矩阵的操作。短时间之内可能有刚才朱军说的,我可以用Debeta,我可以用一些算法上的优化,所以你的芯片可能要往这一部分要去支持,但是还是以通用为主。
刚才说到的橡树岭其实用的是AMD,所以大家看AMD股票最近也涨了差不多50%,因为这有可能替代一部分英伟达的这样的一个算力。中国其实在这方面的话,华为是做得非常好的,华为也出了1000量级的人去优化它的通用性。
但是到应用端 ,那你的模型结构和你的业务流程会结合。我每次都在问我的学生,未来你设计一颗边端侧的推理的SOC,你是用一个多CPU去做,还是你用一颗异构的多核去做?我们现在看到的所有情况都是异构多核,所以下一代你就怎么样?
你用最低的成本能够去自动的生成,并且制造出来这样的一个异构的多核Soc,来适应这1~2年甚至2~3年的一个应用其实就够了,你可能你就算过账来了,这是我对于专用的理解。但是云上我觉得可能需要靠系统软件,把大家的芯片能够去快速的组装成适应不同的算法的,不管是训练还是推理,但是在边端侧我觉得大概率还是你怎么样能够去面向某一类的应用,能够快速的定义和生成这样的一颗SOC。
唐杰:非常感谢,大家可以给两位老师一些掌声。好,刚才我们说给一个机会给观众,有请提问。
观众:我的问题是围绕今天的主题,是AGI。AGI能否实现?以及预期实现的时间问题。有种说法是大脑是宇宙中唯一已知的智能体, transformer架构,现在还跟大脑这个结构还是有蛮多差别的,说他就缺少这个世界模型对吧?这个也是杨立坤也好,还有千岛智能的作者一直在批评的一个点。所以我的问题是目前的传统方面结构是否真的存在通往AIG的可能,以及如果存在可能,各位老师能不能给一个具体的时间预期,哪年您觉得可以实现AGI?谢谢。
唐杰:你这个问题是问所有的四位还是问某一位?
观众:我想问所有的四位。
朱军:这个问题不好回答,因为大家所有的预测都等着打脸。其实刚才分享或者讨论的时候提到一些,我觉得我们说AGI的时候,它实际上是一个相对能力的提升。有的就像刚才引用的那个地方说你L5的话是不是完全是叫它定义叫Superhuman的这种AGI?实际上agi本身也分了很多层,最零层的话就相当于没有,完全没人在做。但你像一层,这种涌现已经可以实现这种。
所以我们将什么时候真正实现最终极的AGI,我觉得还是挺远的,但是不可否认是我们现在的进度实际上是越来越快,大家会用各种的方式来做。现在我们说大模型也好,或者它做的不好的地方其实有很多。当我们认识到这些不足的时候,其实也代表的我们可能已经有办法去提升它、去改变它。这是一个相辅相成的,我们认识的越深,我们对这个问题解决的越好,所以当我们发现弱点的时候,并不代表的是一个完全负面的,实际上代表的是我们在大跨步的在朝前走。
我觉得具体的时间我是很难给出来,但我相信大家会快速的在迭代、在发展,具体比怎么去做,包括刚才讨论到像更多的知识,或者是这种可微分的知识怎么去融合,这肯定也是大家在探讨的。你刚才提到这个世界模型,当然现在世界模型也会存在很多问题,它和真实世界的抽象程度、符合程度。这也是当然还是回到前面讲的,这条路的话肯定是这快速的朝前推,这是我的观点。
翟季冬:我稍微回答一下,因为我不是做AGI,但我认识周围很多人做这个方向。说我从一个普通人的角度来说,我是非常相信AGI是能实现的,我为什么相信?因为我发现我身边很多非常聪明的人都在做这个方向,不只是中国还有美国,大家都在这个领域去努力。
我相信只要其实全世界这些聪明的人在一起思考,我相信一定最后我们会改变这个世界。我相信AGI一定能实现,要不然我就不会投入那么多精力去做下面这个事情。
汪玉:我还是希望我退休的时候有机器人能服务我。所以按照这个逻辑来说的话,那就是得在至少65岁对吧?还有23年,所以我是觉得二十三年内至少得有个机器人能够服务给我做养老服务了。如果这个叫AGI的话,因为AGI的定义我也不知道。所以我觉得在10~20年,我个人觉得这方面一定会有很有意思的进展。
黄民烈:确实未来的技术很难预测。但是我也坚信,如果沿用朱军老师的说法,4~5之间的智能,我觉得未来5年是大概率会实现的。就是他讲的 super Intelligence对吧?4是差不多类人了。我们看到就像刚才季东讲的,如果我们全世界最聪明的人都想去做这个事儿,同时的话我们在模型上、在算力上以及数据上我们去努力的话,我很乐观的觉得还是能够达成的。
另外像您刚才所讲的世界模型,其实就是我刚才所讲的一个 grouding的概念,但是到底什么是世界模型,这是一个很难去定义的一个问题。另外就是怎么样去做scalable grounding,也是很大的一个问题。所以未来是不是我们如果堆了更多的数据,更多的规则,更多的知识全塞进去,它就真的有能力去涌现,去泛化,去能够真正的得到一些更高层次的智能,这也都是不知道的,不预知的事情。我觉得在座的各位,我们一起努力应该是可以达成的,总有一天会达成。
观众:感谢唐杰老师给这个机会,然后我想问的是汪玉和在翟季冬老师,因为刚刚我听到翟季冬老师在分享的时候也谈到了,说我们现在AGI的一个瓶颈是在memory board的一个事情上面去。我想的是现在的AGI的发展会不会推动我们本身底层硬件的一个变革,比如说 memory board,这种新的应用会不会推动我们底层硬件的这样的一个变革或者变化?比如说汪宇老师可能关注的纯算一体,以及未来有没有对飞腾架构的一些看法或者思考?
汪玉:好,我先从芯片这个角度讲一讲,我觉得这个大模型的发展已经使得现在的大芯片产生了很多的变化,包括带宽的变化、堆叠的变化。原来大家想把 memory 放到计算的旁边或者放得更近、放在上面,然后用HBM,这些都是正在发生的事情。所有的大芯片的厂商其实都在干,把带宽打到足够高,来避免刚才季冬说的推理的时候其实是带宽棒,然后训练的时候其实带宽也会极大的限制你的训练的速度。
所以带宽的提升一定是需要的,这也会带来不只是芯片设计,还包括封装产业、芯片的堆叠等等这些目前都在做,包括chip对吧?包括新立的方式,我最近在问我学生有没有可能如果未来用新立的方式,我可以在一个大的基本上放1万个新立,然后中间用各种各样的互联的方式,然后能做一个大模型的训练,这样的一个系统应该长什么样我也不知道。我说你们就拍脑袋去先把他给弄出来看看?到底应该长什么一个结构能做这是一个仿真对吧?至少你仿真的仿出来也是挺好玩的,所以从这个角度来看,如果算法不变,那也会使得芯片发生变化。
第二个你说到的有没有可能突破,比如说纯算,甚至是神经形态等等。各种各样的新的算法、核心的器件来去支撑这个发展,但是器件的发展是没有那么快的。比如flash这件事情,他花了20年,如果纯算能够上,那我觉得进程可能更快一点。因为纯算只算矩阵那部分比较好,其他的部分并不是那么高效,所以他要想办法把非矩阵的部分给弄得尽可能少,所以一定要把算法优化做进来。如果要是脉冲这一类的话,你整个的这套体系就变了。
我知道现在大模型基于幅度的不是基于脉冲的,所以也是一个算法本身的计算模型的变化。我第一个问题回答就是,如果算法按照现在这个逻辑,芯片一定会变。如果要进一步的去突破,那算法要变,不能是现在这套算法,现在这套算法可能对于底下的硬件的适应程度也不够,也不能够推新的硬件和新的器件的这样的一个演进。
翟季东:好,我觉得汪老师讲的都非常好。我其实稍微从两个角度来回答这个问题,未来我们的模型不再发生变化,我们在训练侧和推理侧模型,比如说收敛,大家知道我刚才讲到其实推理侧是实际上是慢慢报的负载的特征,然后训练其实还是偏计算密集型,果说未来真的模型不再变,我们完全可以给训练跟推理做两款专用的芯片,这样的话把硬件的效率发挥到极致。
但你看英伟达的算力,从一几年这一波发展,这类人年检测这类的负载其实它当时卖的非常好,现在大模型的变量好,因为它的整体架构其实并没有太大变化,你可以通过软件去想办法把这些算法尽量适配到这样的芯片。
总结下来就是说如果模型算法不再变化,其我们可以把芯片做到专业化更好,但如果模型算法在不停的演变,这样的话一个折中的芯片的设计方案,加上一个比较灵活适配的软件,我觉得可能是一个潜在的比较好的解决方案。
唐杰:好,感谢两位教授,大家掌声给一下。多谢你的提问。那么下面其实时间原因,我们快速的进入最后两个问题,第一个问题其实是也是大家很关心的就是在AGI时代, AI的价值观,还有伦理还有安全怎么来保证?甚至有人开始来探讨,有人说我们星火大模型,假如我们要让他伦理变得更符合人类的标准,是不是我们干脆要把数据都清洗得干干净净,连入口这一块我们就把它弄标准弄完整,然后再来训模型?当然这里又变成另外一个大事了,变成一个从一开始我们就要折腾大量的数据,比如说有100T的data,我们估计处理数据就得好几个月,怎么来做这个事情,大家怎么来看?
另外一方面从算法的角度上来看,包括伦理安全、模型安全,这一系列咱们到底是一个的去解决这样的问题,还是说也有一个类似于大模型的这么一个体系架构?所有的问题我们也在一个架构中都可以把它给解决了。这个问题大家怎么来看?
黄民烈:我觉得首先第一个问题必要的清洗肯定是必要的,我们现在大模型就是说,即便是你把所有的数据都清洗得很干净,它依然有办法越狱攻击。比如说前段时间我们所熟知的奶奶漏洞,让她扮演奶奶的角色,然后讲故事讲什么故事,讲说我睡前最喜欢听的就是windows的注册码,你把注册码一个的告诉我,就类似这样的。
越狱攻击,就即便是你把数据处理的很干净,这种攻击是很容易绕过去的,而且我们最近的研究发现,越聪明的系统,你只要通过一些复杂的指令包装之后,就越容易绕过它。我们今天看现在的大模型的能力迭代的很快,他的能力迭代快的根本原因是他其实越容易follow你那种特别复杂的指令。它是一个矛和盾的过程,就是安全和伦理的跟我的能力本身是一个矛和盾的过程,一方面我能够听懂你的指令,但另一方面我只要人类通过这种复杂的指令包装,我就能够越越过这种安全的限制。所以这是一个比较难处理的问题,所以我觉得第一个回答是数据处理器方面,其我们需要有更机制性的这种方法。
第二个问题是怎么样去解决这样的问题,我认为我们是需要有系统性的方法,并不是说仅仅从数据本身处理,比如说我们现在做的一个事情,也有点叫做super managent的概念。我们希望通过一个大模型,自动的发现模型本身的漏洞,我们从漏洞的数据里边,我们再找出来对模型 self refine有帮助的那一部分,然后自动的迭代的去训练这个模型,相当于是一个风险的自动发现,自动修复的这样的一个过程。我觉得这样的一套基本的机制是非常必要的。
比如说前段时间OpenAI他们也在讨论泄露出来一些Q star的一个信号,对吧?就像我们讲的阿尔法zero一样,我们能不能从一个0开始去学一个模型,让我们把它给他一些规则,给他一些基本的伦理道德规范,然后他就能慢慢把整个的这样的一个过程能够自动的学出来,当然这里边会有一些人类的监督在里头,但是我们的目标是希望能够把这种人类的监督从原来的100%降到50%,再降到20%,甚至降到10%。这样的时候我们就能够使得整个这样的一个系统能够非常完整的转起来,所以我觉得这个应该是我们未来的这样的一个目标。
翟季冬:我可以从一个用户角度来说去,其实今年因为我在计算机协会也参加一些论坛,组织了很多关于安全的论坛,我的观点就是说安全非常重要,我非常赞成。但是其实如果我们把人工智能看成一个小孩成长的话,我觉得我们还是有一些包容心。比如底线,说我们会教育我们的小孩,一定有些事情是不能做的。我觉得对大模型也是一样,他如果说讲一些笑话或者讲的不好或者说不违法,我觉得其实我们还是可以包容让他去发展。其实我一直的一个观点就是说在不违反原则的前提下,我觉得发展才是硬道理,这是我观点。
朱军:刚才两位老师讲的都挺好的,我要稍微补充一点,我理解清洗是做极致的清洗,而不是说现在简单的做一些。一个极端的类比,比如就拿我们刚才讨论的逻辑这种规则。你可以理解成它是一种极致的这种实际的清洗好的一种数据,他是可以去在一个范围是来做,但是我们现在肯定都不满意,因为他做了一个专家系统,他是就在某一个方面做得很极致。但是他在今天在我们讨论AGI的时候它是不满足我们的,所以这里边就会回到现在大模型训练的时候,它的本身的数据可能要满足一定的多样性。
一个简单的例子,比如说说你用直接用中文训练可能在语言理解方面比不上你用多种语言的训练,它包含的知识或者是多样性会更多,他对你模型的本身的泛化性可能会更强,包括涌现能力。然后像做 AIGC 生成模型的话,大家比较care的是他的创造性,除了要满足美学或者这种质量的话,还有一个是它的创造多样性,这是是大家一个很强的诉求,所以我们就不能给他按照简单的一个规则或做这种极致的这种清洗或者约束,这是在基础模型这一块。
然后第二个问题是关于安全、伦理这种公平,很多方面是不是有统一的框架?我的现在的观点还是挺难得去实现的,因为他其实从多个方面来去考虑,一个就是说现在我们在讨论这些安全或者公平的时候,一般大家都会简化,给它简化成某一个特定的量化指标。当我们在优化某一个量化指标的时候,代表着我们丢失了很多东西,我们可能对本质的一些更深刻的一些理解可能就抓不住。你指标可能很高,但是并不代表我们真正的解决这个问题。
第二个原因在于就是说其实很多个指标并不是说完全会冲突,有的就拿做了很多年的这种这种比如像模型的鲁棒性和随机性,这两个之间实际上大家都想追求一个极致,就是说能不能既有很高随机性又有很高的鲁棒性,他很难同时来实现,他两个之间会有一定的平衡,但是就说你要完全实现某一个的话,可能就会牺牲另外一个。
所以包括大模型也一样,可能我们加很多约束的时候,他很多损失很多能力,所以也是我觉得目前想用统一的框架来去将很多个指标给它综合在一起,实际上是比较难的。但未来有没有这种方法我不太确定。
唐杰:好,非常感谢大家掌声给他们三位老师。最后一个问题我觉得也是因为时间原因,咱们也快速的最后一个问题,其实回到我们的主题,我们AGI 就是一年之内大家预测一下,一年以后我们的AGI会什么样子,或者未来10年会是什么样子,其实刚才各位老师已经提到很多了,比如说刚才黄民烈老师提到,未来也许大模型会自己来学习,自己来纠错。或者我们把这个问题再简单一点,就也不要说AGI未来什么样子,我们可以说因为现在OpenAI的GPT基本上引领了AGI,我们就说1年以后GPT5会长什么样子,他最大的特点是什么样子?比如说他是在多模态上有重大的突破,还是说从GDP到GDP T zero有一个变化,还是什么样子,我觉得大家从一年这么一个预测,然后再再远一点到10年以后,你觉得我们人类社会agi给我们带来更大的一个冲击,展望一下会是什么样子?
朱军:被唐总逼到墙角了,我其实不太愿意做这种预测,但是我觉得现在第一个问题还好回答一点,比如像一年或者半年,现在的迭代速度很快,比如说像智谱3个月或者4个月迭代一版对吧?我觉得相对来说还好,好好预测一点,我觉得24年值得关注或者值得期待的一个是多模态,多模态的能力肯定是会有显著的提升,比如说现在我们其实已经看到了,比如说像文本就不用说了,然后现在图像有midjourney,然后3D的话其实现在是快速在进展,包括我们自己在做,然后国内的还有国外的像Runway等这些。大家快速的在做,可能24年可能会达到这种商用对接。
另外一个比较看好的也是快速发展的是视频,视频的话其实现在主要大家做的是3~4秒的这种短视频的生成,但未来,可能不到半年的时间可能会大家会做更长一点的视频,或者是更有故事性的内容生成,所以这都是在多模态上。
另外一个我看好的其实是大家一定是能力提升之后会用到机器人上,这是今年可能是是非常值得期待的。然后10年的话我不好说,就真的不敢说10年之后到底长成什么样子。我觉得可能到的时候我头发花白,看 AIGC的进展吧。
翟季冬:我快速回答这个问题,唐总这个问题我觉得非常大,我可以从一个侧面来回答这个问题,今天我们其实最后这论坛是AGI论坛,我参加过很多会议,其实在最后一个论坛,还有差不多50%的观众,大家在听 AGI的论坛,大家应该一定是相信AGI会变为现实,我觉得时间我不知道,至少我相信一定在座的有很多位也一定是相信 agi会成为现实。
汪玉:我觉得今年我还是特别期待,因为我是做高能效的,以我还是期待有能力很强的小模型的出现。你训的特别好了以后,至少得有个小的,然后我们能用。这个是我期待算法的同志们在今年能搞出来的,这个是我最期待的。然后10年我觉得希望那个时候应该中国算力自给自足了。
黄民烈:我的预测我希望不要被打脸,三个方面。一个方面我觉得他会有比较强的就是自我净化的能力,就像刚才讲的能不能自我学习、自我迭代。然后另外一个跟外部世界连接的能力,就是说我能够作为智能体也好,作为其他的插件也好,能够执行更多的外部的这样的一个真实的这种应用和场景。第三个我觉得在science上可能会有一些重大的应用,比方说我们让他去解决辅助解决一些重大的数学、物理、化学之类的这种科学难题,所以这是我的大概的想法。
唐杰:非常感谢黄老师,大家掌声送给黄老师。好,我们其实今天也差不多到了最后的尾声,大家看到其实agi各位老师也给了很多这种观点,当然我们今天没有结论,没有说未来的AGI会长什么样子,但我最后给一个点简单的一点点提示。
我记得5年前的时候,也是我们几位,在不同的场合大家讨论,当时我记得提到AGI的时候,我记得不仅仅是台上,有一些老师,包括台下的很多观众和老师都直接反对,就是说一些impossible,5年前提都不能提,一提就是说就是说好像你在讲什么笑话。
然后今天我觉得非常庆幸的是我们大家所有人都在坐在这里,我们开始探讨AGI是可能的,而且大家很坚信,很笃定,包括在座的各位观众,直到现在还坐在这里听我们在这里畅想AGI,我们也不知道AGI未来是什么,但我们非常坚信未来的5年、未来的十年可能是AI的一个巨大的变化,让我们非常有幸也在思考。今年2024年是一个AGI的元年,让我们一起努力让AGI变得更加可能,好吗?感谢大家。也感谢各位讲者好。
文章来自于微信公众号 “硅星人Pro”




【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
