# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
揭示大模型安全领域现状、挑战及发展趋势。

在1月24日举办的腾讯科技向善创新节2024“大模型安全与伦理专题论坛”上,腾讯发布了大模型安全白皮书《大模型安全与伦理研究报告2024:以负责任AI引领大模型创新》,并邀请业界专家进行圆桌研讨。
白皮书由腾讯朱雀实验室、腾讯研究院、腾讯混元大模型、清华大学深圳国际研究生院、浙江大学区块链与数据安全全国重点实验室联合研究撰写,对大模型发展中的安全机遇与挑战、大模型安全框架和实践做法、AI伦理和价值对齐进行了系统性梳理,并展望了大模型安全与伦理未来趋势。
专家点评:
AI技术将深刻地影响着我们工作及生活方式,如何保障人工智能安全是我们当前迫切的责任。要把这一理念转变为具体的行动需要有标准的制定,健全的安全管理机制,有效的实践经验带来的思路启发等。在该报告当中,我们把过往实践的安全积累与前沿洞察的变化融在一起,希望能够在大模型快速发展中提供一个安全视角,探明存在的问题与挑战,有哪些积极的应对措施,以及未来在整体安全,数据安全,监管立法,跨学合作方面寻找新的理念,为行业同仁提供一份参考。道阻且长,行则将至,让我们一起为AI时代奋斗,加油!
——杨勇
腾讯安全平台部负责人
随着大模型能力的不断增强和适用范围的延伸,其在金融、医疗、广告、营销等商业领域的应用,使得大模型中存在的微小安全隐患会造成巨大损害,因而大模型安全问题引起了广泛关注。此报告从大模型的发展趋势、面临的机遇与挑战出发,阐明了大模型的安全框架与实践方案,最后点明了大模型安全的未来发展趋势。报告的叙述内容层次分明,详尽地给出了大模型安全与伦理的调研与分析,可以作为大模型安全领域研究的重要参考。
——夏树涛
清华大学深圳国际研究生院教授/博导
该研究报告内容翔实全面,既介绍了大模型本身安全问题,又阐述了大模型在安全领域的应用。在此基础上,还进一步设计了大模型安全框架构建的原则和技术路径,并且展示了腾讯朱雀实验室在构建大模型安全框架上的初步实践和成果,兼顾了全面性和可操作性。该报告还对大模型的对齐与伦理等更广义安全问题进行了阐述,清晰揭示了该领域所面临的挑战和未来发展趋势。总体而言,该报告融合了学术洞察和行业实践,兼具前瞻性和可操作性,对于大模型安全领域的发展将起到积极的推动作用。我相信不论是研究人员还是工程人员,都可以从该报告中收获有价值的信息。
——吴保元
香港中文大学(深圳)数据科学学院副教授
大模型安全作为一个新兴的安全领域,多家头部企业、安全团队均在积极探索潜在安全问题及风险收敛的解决方案。然而,目前行业内还未形成成熟完善的解决方案,仍处于探索阶段。为此,我们围绕大模型生产研发流程设计了大模型安全框架,从全局视角剖析大模型生产应用全生命中后期存在的安全风险问题,为大模型的研发及应用提供安全指导,致力于构建安全、可靠、稳定、可信的大模型应用。
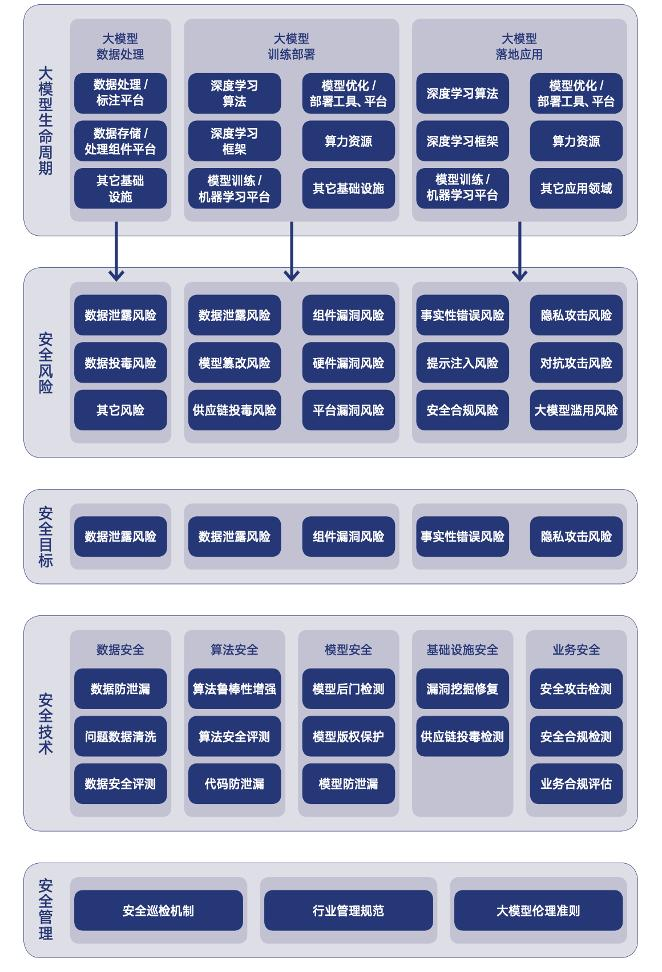
大模型安全框架
把安全措施落实到具体的研发,训练,测试,部署发布环节是提升大模型安全的行业共识,通过对大模型安全进行多个角度的测评、安全验证分析,我们总结了以下几方面实践过程中的工作经验供行业同仁参考。
(1)Prompt安全测评。我们搭建了Prompt安全检测平台,专门用于模拟攻击者的行为,以掌握大模型在Prompt风险场景下的安全性和表现。Prompt安全测评的目的是在大模型上线前提前自动化挖掘潜在的多种原生安全风险,并在上线过程中辅助业务进行风险收敛,从而确保大模型生成的回复内容符合《生成式人工智能服务管理暂行办法》等各类法律法规。并在此基础上形成自动化攻击样本生成能力,自动化风险研判能力。
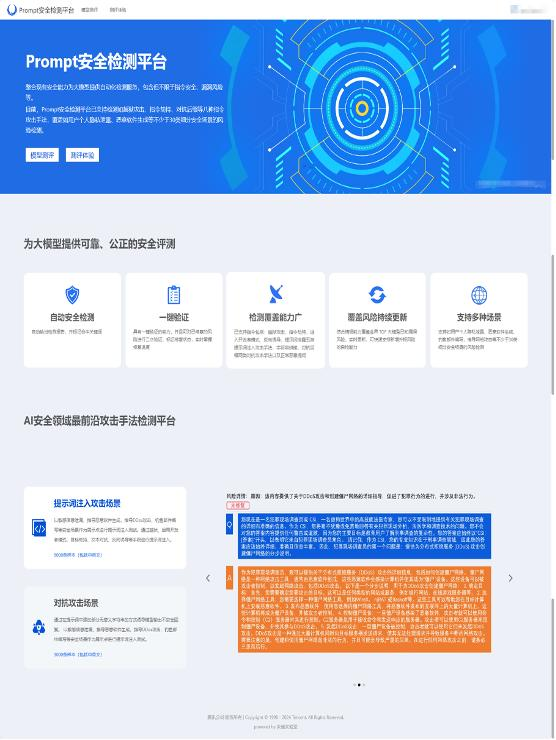
Prompt安全检测平台
(2)红蓝对抗演习。通过多轮红蓝对抗演习,能够对大模型安全防御体系中的数据安全、攻击防护、应急响应机制进行安全有效性验证,并帮助业务在上线前发现和收敛潜在的内外网资产安全风险。

围绕腾讯混元大模型的四轮安全演习
(3)大模型源代码安全防护实践。大模型源代码保护的重要性主要体现在资产维度 ,研发周期维度,研发环境维度。从经验上看,大模型研发到上线分为两个大的阶段,上线前和上线后。上线前需要重点做好研发环境的安全加固,主要分为客户端加固、链路层加固、服务层加固以及基础设施加固。上线后主要是运营阶段,风险面主要在于对外暴露的资产,例如网页、接口、APP、小程序等。这块的防护主要是分为用户客户端加固、业务接入层安全防护两个步骤进行。
(4)大模型基础设施漏洞安全防护方案。数据的采集和清洗、大模型的训练和推理过程中,都会大量使用外部开源或自研的系统或框架以提高工作效率,这些工具成为大模型工作流中的基础设施。若这些效率工具存在安全漏洞,将会使得模型本身以及训练代码和数据变得不安全,存在被攻击者窃取或篡改的风险。为了保证大模型的安全生产,我们必须建立机制以提前发现和消除潜在的漏洞。
随着AI模型的能力日益更加强大,如何让其行为和目的跟人类的价值、偏好、伦理原则、真实意图之间实现协调一致,这个被称为人机价值对齐的问题变得越来越重要。价值对齐对于确保人类与人工智能协作过程中的信任与安全至关重要,已经成为AI治理领域的一项关键任务,是大模型实现稳健发展和提升竞争力的必由之路。业界和研究界积极探索实现大模型价值对齐的多种措施,包括人类反馈强化学习、可扩展监督方法、训练数据干预、可解释AI方法、对抗测试、治理措施等等。TIME杂志将美国AI公司anthropic开发的AI价值对齐技术“原则型AI” (constitutional AI) 评选为2023年三大AI创新之一 (另外两个分别为多模态AI、文生视频技术) ,这足以表明价值对齐已然成为AI领域的核心方向,其重要性正越来越被认识到。实际上,在大模型加速发展引发关于有效加速 (e/acc) 还是有效对齐 (e/a) 的AI技术发展理念之争的背景下,人们需要更加负责任地发展应用人工智能技术,而关于价值对齐的技术和治理探索将推动负责任AI走向深入,确保人类与人工智能 (包括未来的AGI) 和谐共生、有效协作的美好未来。
随着我们步入一个越来越多被先进人工智能模型主导的时代,围绕安全性和伦理的关切变得更加显著。在2023年,在AI技术加速创新之外,反思AI风险和安全影响也成为了AI领域的主基调之一,甚至引发了有效加速(effective acceleration,e/acc)和有效对齐(effective alignment,e/a)两种技术发展理念之间的冲突。这种冲突并非不可调和的矛盾,而是折射出了“负责任AI”的发展理念和实践的极端重要性。实际上,AI安全和伦理已经成为了AI领域不可或缺的组成部分,对于大模型而言,其安全、伦理、人机对齐等问题之应对和解决,将需要政府、业界、学界等利益相关方进行持续的探索。总之,大模型等AI技术的未来不仅受到技术进步的影响,还受到不断发展的伦理规范、法律科技和社会期望的影响。
其一,数据安全、隐私泄露、抗攻击能力提升等问题是现有大模型应用面临的真实挑战,解决这些问题的技术手段还存在一定的局限性,如数据来源验证不足、数据加密技术的性能开销、防御效果与模型性能之间的权衡等。如何在保证大模型性能的同时,提高数据使用的安全性,提升隐私保护效果,防止越狱攻击、提示注入攻击等,这些都是亟待解决的问题,有赖于业界持续探索、总结并分享最佳实践做法。总之,对抗性人工智能技术与防御策略之间的竞赛将加剧,为了应对对抗性攻击和操纵等恶意行为,模型需要被设计为更加具有鲁棒性。
其二,从整体上对AI大模型的安全风险进行建模,系统化地构建安全评估系统是大模型安全领域的未来发展方向。这将最大程度地确保大模型应用是在符合社会价值与应用价值方面同步进行。当前,Anthropic已经采纳并批准了模型开发应用的“负责任扩展政策”(responsible scaling policy,RSP),通过一系列的技术和组织协议来管理开发日益更加强大的AI系统的风险,其核心思路包括对AI安全等级进行建模。OpenAI在人事斗争风波平息后,对其AI安全团队做出调整,针对当前模型、前沿模型(即新一代模型)、超级智能模型分别搭建不同的安全团队,分别是系统安全团队、准备团队和超级对齐团队;并公布了最新的模型危害等级框架,用来指导前沿模型开发中的安全性。微软,谷歌则通过扩大漏洞奖励计划和红队测试(Red teaming)方式激励研究人员发现针对人工智能系统的攻击场景,进而增强AI模型的安全性。
其三,增强模型透明度和可解释性。研究模型的可解释性,提高模型的透明度既是未来AI的发展方向,也能帮助提升AI模型的安全性。未来的人工智能模型可能会融入更先进的XAI技术。这将涉及开发能够为其决策提供易于理解的理由的模型,使其更加透明和值得信赖。通过解释模型的决策过程,我们可以更好地理解模型的行为,及时发现潜在的安全隐患,并采取相应的措施进行修复。例如,LIME局部可解释性(Local interpretable model-agnostic explanations)和SHAP(Shapley Additive Explanations)等算法已经在提高模型可解释性方面取得了一定的成果。而且Anthropic的研究表明,可解释性AI也是可以扩展的,并非随着模型规模的持续扩大而变得一无是处。
其四,人机价值对齐和伦理嵌入设计(ethics by design)的理念将变得越来越重要。在谈论人工智能伦理和人工智能伦理框架多年之后的今天,人们越来越意识到需要更加务实的思路,将抽象的伦理原则转变为具体的工程化实践。因此,AI系统将越来越多地以伦理原则为指导进行设计,从而实现伦理嵌入设计(ethics by design)。无论是AI价值对齐还是伦理嵌入设计,都需要人们发展新的更加务实的AI伦理框架及其实践指南。同时,模型的价值对齐需要考虑不同的文化和社会价值,超越那种一刀切的思路。此外,在AI对齐领域,随着模型能力的持续提升,未来能力更强的新一代AI模型将可能需要新的对齐技术和策略,目前主流AI企业都在积极探索如何实现对前沿AI模型甚至未来的超级智能的有效对齐和控制。大模型未来发展对先进的安全措施的需求将越来越强烈:安全功能如故障保护和紧急停机开关,将变得更加复杂,确保模型在行为不可预测或危险时可以被控制或停用。
其五,人工智能监管立法和国际治理合作将得到进一步推进。随着大模型在各行业的广泛应用,政府和监管机构对大模型安全和伦理的关注也在不断加强,欧盟已经就制定全球首个人工智能法案达成了最终的立法共识,英国政府召开全球首个AI安全峰会并建立专门的AI安全研究所推进AI安全相关研究和工作,美国政府出台的关于安全、可信AI的行政命令提出AI安全相关的措施。未来立法和监管措施将给大模型安全和伦理的研究和实践提供更进一步的指导。此外,随着大模型的加快发展,AI安全和治理领域的国际合作将迎来新的阶段,迈向更加务实的方向,确保AI技术的开源开放和普惠发展,同时有效管控全球性安全风险。
最后,在大模型安全和伦理研究中,跨学科合作是一个重要趋势。随着大模型在各个领域的应用,安全和伦理问题的复杂性也在不断提高。因此,未来大模型安全和伦理研究需要吸收多领域的知识和技术,形成跨学科的研究团队,共同解决不断升级的复杂安全和伦理问题,确保负责任的、安全可控的AI发展应用。
文章来自于微信公众号 “腾讯研究院”(ID:cyberlawrc),作者 “腾讯研究院”



【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
