# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
人工智能的未来,在于和人类一起去冒险和发现。
而游戏是为那样的未来准备的“沙盒”。
今天分享的这篇文章来自人工智能研究者 Kevin Lu 的个人博客,他在 Meta 和高频交易公司工作过,后来加入了 OpenAI,在今年又随着 Mira Murati 加入了人工智能实验室 Thinking Machines Lab。
这篇文章当中我最喜欢的一个洞察就是:“人类探索的本质不是随机尝试和暴力破解,我们始终朝着"获得乐趣"的方向优化!人类游戏行为蕴含着以好奇心为核心的美学维度 — 纯粹为了见证新结果而尝试新思路。即使没有奖励信号驱动,人类仍会为了学习和见识新事物而持续探索。这种人和机器的差异在科学发现领域尤为关键。科学家遵循自身美学原则,识别知识空白,提出新假设并通过实验获取新知。”
Intelligence may yield great results, but joy leads to true transformation.
前几天写下了这句话。其实人生大多时候,也是乐趣才会导向伟大的结果。“自动化”的 AI 很显而易见,隐秘的乐趣需要更多有心之人去探索和塑造。
希望今天的文章对你有启发。

《宝可梦》( Pokemon )提供了一个思考虚拟世界的框架。这些世界宛如我们现实世界的微观缩影:它们允许开放式探索,向玩家呈现必须克服的挑战,并最终传递快乐( they allow for open-ended discovery, present the player challenges which must be overcome, and ultimately, should be fun )。自 1996 年以来( 存在时间比我的年龄还长 ),宝可梦系列游戏一直是流行文化的中流砥柱,玩家总数已突破数亿。而如今,人工智能体( AI agents )也开始加入了这场冒险。

随着我们迈向能够在现实世界中与人类互动并为人类执行任务的人工智能— 一个充满开放性、挑战性和趣味性的世界。我们已将智能体从原先的封闭环境( 雅达利游戏、围棋、国际象棋 )迁移到开始展现现实世界广度的游戏中。在让它们迎接科学发现的挑战之前,我们将首先让智能体在充满趣味的童年游戏中探索新奇事物( Before they can take on the challenges of scientific discoveries, we’ll task the agents pursuing exploration and novelty in childhood games of fun )。
Playing Pokemon games
在宝可梦主线游戏中,玩家可能拥有两个主要目标:
完成道馆挑战( Completing the gym challenge ):玩家推进主线剧情——挑战八位道馆馆主、四天王及冠军。同时在此过程中击败邪恶势力并拯救世界。

必须全部收服( Gotta catch em all ):玩家可以随心所欲!他们可以完成宝可梦图鉴( Pokedex )( 全部收服 )、完成支线任务、训练宝可梦参加奥林匹克大赛、教会宝可梦跳舞、狩猎稀有闪光宝可梦,或是达成任何其他自主设定的目标( self-motivated objective )。
关于目标(1),近期 Gemini 2.5 Pro( 通过大量提示工程塑造 )和 Peter Whidden 等人 2025 年的研究( 通过大量奖励机制塑造 )都已成功实现从零开始游玩原版《宝可梦 红/蓝》并完成道馆挑战:这标志着强化学习领域的一个重要里程碑。
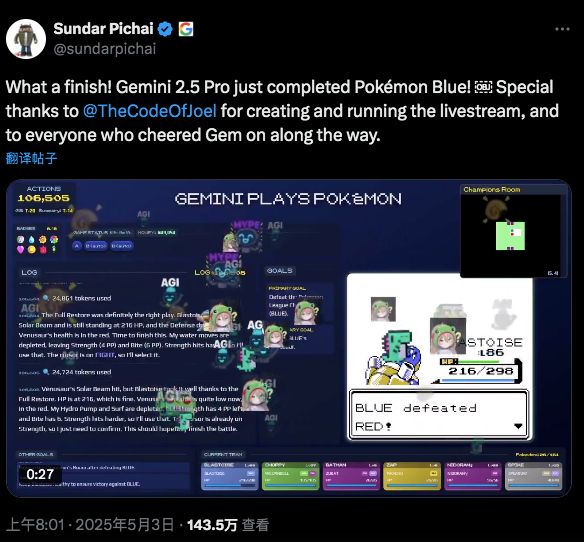
What makes Pokemon hard?
首先且最重要的一点是,《宝可梦》是一个长周期任务( 人类玩家约需 25 小时,而 Gemini 则需要数百小时 ),且具有巨大的行动空间 |A|。在任何给定时间点,玩家可以与任意数量的非玩家角色( NPC )交谈、探索房屋、查看新区域、解决谜题、培养宝可梦等级、购买道具、寻找新宝可梦……可能性层出不穷。由于维度诅咒的影响,随着任务周期长度 T 的增加,难度会立即呈指数级增长 O(|A|^T)。
这就带来了巨大的探索挑战( a significant exploration challenge ):为了推进游戏进程,玩家时常需要完成令人惊异的思维跳跃( the games can require you to be very surprising leaps )。即便对人类玩家而言也是如此!事实上,许多早期游戏发售时往往附带攻略指南。比如在《口袋妖怪绿宝石》( Pokemon Emerald )中,击败橙华道馆的千里后,剧情要求玩家返回 Jagged Pass( 崎岖山道 )中一个容易被忽略的洞口,从而发现熔岩队的秘密基地。这个极易错过的地点玩家可能几小时前就已经过。因此我们的模型必须具备在稀疏奖励信号下推进游戏的能力( Our models must therefore be able to make progress with sparse reward signals )。
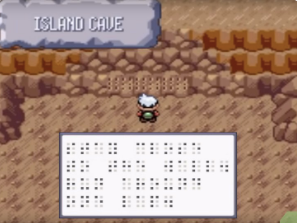
臭名昭著的雷吉三柱解谜( Regi trio puzzle ):玩家需要先在 134 号水路通过特定冲浪路线找到封印之室( 需掌握特殊冲浪技巧 ),破译盲文指令,将吼鲸王( Wailord )置于队伍首位、古空棘鱼( Relicanth )置于末位,随后穿越丰缘地区寻找三处分散的遗迹。在这些遗迹中,玩家必须完成看似毫无逻辑的动作,比如在雷吉艾斯的石门( Regice's door )前静止站立两分钟。
最终,原始的战斗机制本身也极具挑战性( the raw battling mechanic is quite difficult )。对战过程中存在信息隐藏与奖励延迟机制( Within the battles, there is hidden information and delayed rewards ),单是组建战斗队伍( 队伍构筑 )就涉及组合优化的设计空间( Picking Pokemon to even use on the team (team building) is a combinatorial design space )。在更高难度的游戏模式中( 竞技对战、极限挑战模式或激进红改版 ),每场战斗都变成了破解谜题或是与对手的智力博弈,这为玩家提供了广阔的技术施展空间( In more difficult game modes (competitive Pokemon, nuzlockes, or Radical Red), every battle becomes a puzzle or a match against an opponent – presenting a wide avenue for skill expression )。
Learning to try again
面对失败时,传统人工智能方法只会反复尝试相同的策略,仅对细微操作进行调校( traditional AI methods simply try the same approaches again and again, tweaking small actions )。然而在组合爆炸的行动空间 O(|A|^T) 中,随着 T 值增大,这种方法很快会变得不可行。我们可以观察到,智能体会尝试各种不同的思路,每次都与前次不同,却始终无法洞察问题的本质( without ever discerning the true nature of the problem )。
那么人类如何能破解这类谜题?在尝试失败后,人类会采用语义层面完全不同的方法。他们不会仅仅微调某个操作输入( 比如优化运动控制技能或机器人动作 ),而是会探索全新的方向,这通常需要一长串连贯的输入序列。人类会持续尝试新思路,并从过往失败中汲取经验( Humans persistently try new ideas, building off their past failures )。
当前大语言模型的瓶颈之一在于其上下文窗口或"草稿纸"中的情景记忆容量有限( One of the bottlenecks of current LLMs is that they have limited episodic memory in their context window or “scratchpad” )。假设大语言模型能记住最近 n 次尝试记录,但若下一次突破需要基于前 n+1 次记忆才能获得的洞察,模型就无法推导出新思路,最终陷入循环困境,不断重复那些已被验证失败的策略,形成死循环。

Claude 4 Opus 会在它的 scratchpad(临时记忆/草稿空间)里记录尝试新方法的策略。
宝可梦速通( Pokemon speedrunning )就是一个极端案例:玩家不仅追求通关,更要争分夺秒地刷新纪录。他们反复尝试,为缩短百分之几秒的成绩不断提出新策略并付诸实践。在宝可梦这类随机性较强的游戏中( In stochastic games like Pokemon ),玩家还需实时应对突发状况,而非机械重复固定操作序列( they also have to adapt on the fly to the situations that arise, not merely overfitting to a specific sequence of button inputs )。这正是我们的模型需要具备的能力:不能只学会"破解谜题",更要拥有屡败屡战的探索精神( they must not simply learn to “solve puzzles”, but to try and try again )。
Learning to explore
强化学习( RL )中的多种探索方法,从熵奖励到ε-贪婪策略和价值集成( from entropy bonuses to epsilon-greedy and value ensembles )都专注于持续尝试新行动以寻求奖励( focus on ways to continually try new actions in search of the reward )。这在奖励密集的场景中效果显著:尝试某个行动,获得奖励,更新价值评估,然后继续新尝试。
但人类的探索行为远非机械重复输入组合以求侥幸成功:我们始终朝着"获得乐趣"的方向优化( humans don’t simply try combinations of inputs over and over again in hope of hitting the jackpot, they are optimizing in the direction of having fun )!人类游戏行为蕴含着以好奇心为核心的美学维度( There is an aesthetic dimension of human play centered around curiosity ):纯粹为了见证新结果而尝试新思路。即使没有奖励信号驱动,人类仍会为了学习和见识新事物而持续探索( simply trying new ideas for the sake of seeing new outcomes. Even in the absence of a reward signal, humans will continually try new ideas for the purpose of learning and seeing new things )( 就像"必须收服所有宝可梦"的信念 )。玩家探索流星瀑布( Meteor Falls )可能不仅为了最大化地图探索度,更因为瀑布景致动人,或者他们直觉上觉得游戏设计师会在美观的地方隐藏秘密。
这种人和机器的差异在科学发现领域尤为关键( Moving towards scientific discovery, this distinction becomes crucial )。科学家遵循自身美学原则,识别知识空白,提出新假设并通过实验获取新知( Scientists will follow their own aesthetic principles, identify gaps in their knowledge, propose new hypotheses, and test them to learn new insights )。他们不会野蛮尝试所有可能组合( 像 AlphaZero 那样 ),而是精心设计实验( craft intelligently designed experiments );不会凭空臆测看似合理的想法( They don’t simply hallucinate ideas that sound right )( 至少人们期望如此 ),而是精确界定已知与未知的边界,从而系统性地探索未知领域。
Building Pokemon games
退一步想:我们如何设计出让人类愿意去玩的游戏( how do we even design games that humans will want to play )?
粉丝自制游戏:《宝可梦 翡翠海璃版》( Pokemon Emerald Seaglass )
游戏创作是一个开放式的设计命题( Game creation is an open-ended design problem )。首先,这个问题本身就充满趣味,因为游戏本身具有娱乐属性,且电子游戏产业已形成数千亿美元的市场规模。但更深层次的意义在于:游戏创作堪称一个微观实验室,既预示着智能体将如何为我们( 人类 )打造感知世界的交互方式( the creation of games is a microcosm for the methods of interaction agents will create for us ),也映射出智能体未来可能如何设计社会结构来最大化人类福祉( the societal structures agents will design for us (the humans) to maximize human utility )。
AI for game development
具体而言,我们可以将智能体参与游戏创作的辅助层级划分为:
素材生成( Asset generation ):生成式 AI 单纯为人类主导开发的游戏制作美术或语音素材。虽然( 在我看来 )缺乏创造性,但这已成为具有实际价值的产业,在电子游戏、好莱坞影视和动漫领域都有应用。
AI 辅助开发( AI-assisted ):人工智能协助传统游戏开发者加速内容生产,本质上是在现有框架下实现"量产的扩充"。就像大语言模型帮助程序员写代码那样,AI 可以参与开发工作。
"氛围编程"( Vibe coding ):AI 让缺乏游戏开发经验的普通人也能实现创意构想,极大拓宽了人类可发布游戏的多样性( broadening the scope of games humans can release )。我们将看到更多元化的创作者推出新游戏,而不仅限于掌握编程技术的群体。
完全自主创作( Fully autonomous ):AI 独立完成整个游戏开发,包括生成故事线、体验设计和创新机制等,为玩家提供前所未有的无限体验。
我认为(1)和(2)缺乏突破性意义,只是"替代"人类而未能拓展创新边界( merely “replacing” humans without extending the frontier of novelty )。在不失普适性的前提下,下文将着重探讨如何实现(3)和(4),即设计新型创意体验来提升人类福祉( designing new creative experiences to improve human utility )。

乔恩·拉多夫(Jon Radoff)提出的另一种人工智能能力层次模型。
What makes Pokemon fun?
关于游戏乐趣的探讨存在诸多理论,但宝可梦的核心魅力在于:它通过简单的游戏机制,让玩家在奇幻世界中持续获得能力成长与故事发现的满足感( fundamentally Pokemon is a simple game which rewards the player for steadily progressing in competence and discovering new stories in a fantastical world )。你将化身少年生活在这样一个世界 — 所有现实世界的复杂责任都被巧妙抽象化,让你能纯粹享受与宝可梦共同成长的乐趣( You roleplay as a young adult in a world where complex responsibilities are abstracted away and you can focus on the fun of watching your Pokemon grow alongside you )。游戏提供了一条直接且令人满足的进步路径,加深了玩家与宝可梦之间的羁绊( There is a direct, satisfying path to progress that deepens the bond between player and Pokemon ),塑造出那些能够被人铭记几十年的难忘故事。

Twitch 用户共创宝可梦( Twitch Plays Pokemon )团队。
2014年,超百万观众参与了一场名为"Twitch用户共创宝可梦"( Twitch Plays Pokemon )的直播实验。观众通过输入单个操作指令,由脚本程序将这些指令转换为游戏操作。虽然整体效率仅略优于随机输入( 本质上类似通灵板游戏 ),但过程中诞生了许多令人难忘的遭遇战,观众还为捕获的宝可梦创作同人画作和故事线。在这个游戏构建的宇宙中,玩家共同缔造了有深度的叙事和充满意义的集体回忆。
我认为游戏的可重玩性(replayability)值得深入探讨:正如各类Roguelike 游戏总会带来新挑战和新场景,宝可梦玩家始终渴望在全新地区和故事中展开冒险。本质上,最优秀的电子游戏都融合了趣味性、专注的玩法循环与无限的故事可能性 ( the best video games combine a fun, focused gameplay loop with an infinite story ),而人工智能恰恰能帮助扩展这种可能性。
这正是智能体得以超越人类的关键所在
That which enables agents to surpass humans

我个人对智能体创造全新游戏体验的潜力感到无比兴奋,它们能从底层重塑电子游戏的可能性( the potential of agents to create novel gaming experiences which reshape what video games could look like from the ground up )( 注:不仅限于电子游戏哦 )。我们之所以押注投入人工智能,根本原因不在于它能模仿人类或"仅仅"增强人类能力,而在于完全自主的 AI 能成为新世界的驱动者,让我们体验人类世界中永远无法触及的维度( fully autonomous AI can be the driver of new worlds we could never experience in the human world )。特别是,我认为有三条发展路径特别适合 AI 驱动的范式,令人振奋。
Infinite stories
对像我这样的玩家而言,电子游戏最令人沉浸的部分在于那些有待发现的丰富宏大叙事,这片土地承载着深厚的历史,遍布可相遇的角色和待发掘的往事,每个转角都藏着新的宝藏,没有哪款游戏能像《魔兽世界》那样将这种浩瀚感体现得如此淋漓尽致。但当然,故事终究存在极限( there is a limit to the story )。玩家输入一系列动作 O(A^T) 会映射出某个故事线。作为游戏设计师,要创作 O(A^T) 种不同的故事根本不可行。但如果世界能始终适应玩家呢?如果永远有下一扇门等待开启呢( what if the world always adapted to the player? What if there was always the next door to uncover )?
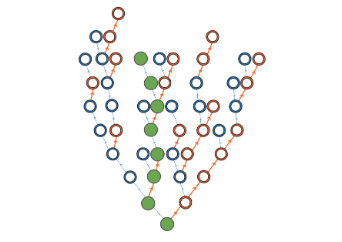
人工智能只需生成玩家实际走过的路径(绿色部分),而人类设计师却必须构建整棵决策树(以指数级增长的规模)。
Infinite action space
电子游戏中最缺乏沉浸感的部分之一,是玩家只能执行设计师预设的 |A| 种动作序列。与现实生活不同,在现实中你可以追逐任何梦想,如果游戏缺乏某种机制,作为玩家你就只能放弃。在《宝可梦》动画( Pokemon anime )中,训练师拥有各式各样的职业道路和与小精灵互动的方式( 从 X 到 Y 不一而足 ),但在游戏中,你只能对小精灵执行有限数量的操作( 主要是对战 )。尽管许多游戏已经提供了无限的世界( infinite worlds )( 如《我的世界》《无人深空》)( Minecraft, No Man’s Sky ),但还没有任何游戏能真正实现"为所欲为"的自由度,而具备响应能力的 AI 可以做到这一点( none have truly offered the ability to do anything in the way a reactive AI could )。
个性化体验
Personalization
最强大的潜力或许在于:AI 智能体不仅能根据玩家偏好,更能基于用户当前情绪状态和技能水平来量身打造体验( Perhaps most powerfully, AI agents could create experiences tailored not just to player preferences but to their current emotional state and skill level )。现有游戏虽然存在动态难度调节功能,但由智能体驱动的个性化体验( agent-driven personalization )可以深入得多。游戏可以识别出玩家何时感到沮丧,并不仅微妙地调整难度,还会改变所提供挑战的类型。喜欢解谜的玩家可能会发现更多隐秘遗迹( cryptic ruins )可供探索,热衷对战的玩家则可能遇到更多训练师对战,并面对 AI 策略愈发精妙的对手。
优化用户参与度
Optimizing for engagement
目前,我们已经开发出能够通关《宝可梦》游戏的智能体,并展现出 AI 在电子游戏开发中的应用潜力。但如今的 LLM( 大语言模型 )仍缺乏实际构建有意义游戏所需的架构和框架( LLMs lack the scaffolding and framework to actually build meaningful video games )。如果我们能解决这些问题,我认为应该开始探索通过强化学习来优化用户参与度。
Designing interesting characters
目前许多 v0 版本的"AI电子游戏"方案仅将 LLM 聊天机器人用于对话生成,但并未从根本上提升游戏体验。这些聊天机器人与游戏本体脱节,其对话内容无法转化为玩家在游戏中的实际可执行行动。相比之下,许多传统优秀游戏角色虽然对话内容单调固定,但他们却是世界构建不可或缺的核心组成部分( many well-designed characters of the past have boring static dialogue – but they represent key pieces of the world building )。
游戏必须在高熵状态( 允许玩家为所欲为,例如与聊天机器人角色扮演 )和低熵状态( 与看电影无异 )之间找到平衡点( Games have to strike a balance between too much entropy (you can do anything, like roleplay with a chatbot) and too little (no different from watching a movie )。即便是人类创作者通常也需要初始灵感( 提示或启发 )才能开始创作。虽然 LLM 对话代理允许玩家进行任意角色扮演,但如果这些互动与核心游戏机制缺乏有意义的关联,角色就会显得虚无缥缈,玩家也会失去继续互动的动力。
尤其值得注意的是,AI 模型容易陷入逢迎谄媚倾向( AI models are prone to sycophancy ),这一点在 GPT-4o 的案例中显露无遗。玩家提出某个建议,AI 就会无条件附和。表面看来这似乎很理想( 这也是GPT-4o 最初设计倾向谄媚的原因 ),但这会立刻导致无用的世界模型( this creates immediately useless world models )。
任何尝试用大语言模型来玩《龙与地下城》( Dungeons and Dragons )的人都遇到过这样的问题:你对 LLM 说你施放了火球术,它就告诉你“你施放了火球术”( you tell the LLM that you cast fireball, and it tells you that you casted fireball )。但我们真正需要的世界模型,是施放火球术后的结果,如果这些结果都要我自己来设定,那我根本不需要电子游戏来扩展我的想象力。关键是:这个法术对世界造成了什么影响?敌人的反应是什么?玩家接下来会遇到什么新的困难( What are the effects in the world? What are the reactions from the enemies? And what are the difficulties the player will encounter next )?
Designing interesting levels
我们需要一个循序渐进的关卡体系,让玩家在过程中不断面对新的挑战,并探索新的故事( We need a curriculum of levels for the player to progress to, continually adding both new challenges and new stories to explore )。不同于柏林噪声( Perlin noise )那种能生成无限但几乎千篇一律的关卡,我们必须引入全新的语义化体验,才能让玩家保持投入并持续游玩( they must instead introduce novel semantic experiences to keep the player engaged and playing )。在《宝可梦》中,关卡设计控制着游戏进度,教授玩法机制,引入新角色,并延续故事 ,就像人类在从童年到成年经历的丰富人生阶段一样。

《无人深空》因其无限的程序生成技术而受到批评,该技术反复创造出大体相似的世界,在发售之初被视为失败之作。
与传统上采用均匀噪声或柏林噪声进行熵注入的方法不同,人工智能现在能够以定向方式注入熵:它可以持续扩展故事剧情,引入与玩家共同成长的新角色,并精准调节难度以匹配玩家水平。通过这种方式,模型能够生成近乎无限个真正有趣的游戏关卡(堪称"终极肉鸽游戏")( the “ultimate roguelike” )。
一种有趣的建模难度的方法是事后回溯( A fun method for modeling difficulty is hindsight )。模型先创建关卡并进行测试:玩家提供关卡难度反馈,或者我们可以将其概括为玩家群体的平均"通关率"( the average “pass rate” )。至此我们建立了从"关卡到难度"的映射关系。下一次设计时,我们运用后见之明:若需要特定难度的关卡,就训练人工智能逆向运作——从"难度到关卡"进行推导。通过这种方式,我们能够精准生成符合预期进程难度的游戏关卡。
Designing for fun
当然,虽然我们希望拥有所有这些特性( 无限重玩性、个性化…),但最终我们最关心的是如何优化乐趣。我们已经看到,像 TikTok 和 YouTube 这样的推荐系统在优化用户参与度指标( optimizing engagement metrics )方面取得了巨大进展( 它们非常清楚要给你推送什么视频才能让你继续观看 )。那么,我们如何训练模型去直接优化乐趣呢( how can we train the models to directly optimize fun )?
几乎总是存在一种脱节:反馈机制( 例如点赞按钮 )和我们真正期望的结果( 效用或乐趣 )之间并不一致( there is some disconnect between the feedback mechanism (eg, a thumbs up button) and the desired outcome (utility or fun) )。就像“回形针最大化器”( paperclip maximizer example )的思想实验里,如果 AI 的目标是制造回形针,它最终可能会把所有人类原子都转化为回形针。但我们真正想要的是通过回形针来最大化人类效用( 为人类造福 ),而不是为了回形针本身。我们已经看到,这在现代成为了一个真实的问题,如上文所述的谄媚逢迎现象。

在《推理时间成本分析》这篇前文中,我探讨了"upscale"功能如何成为连接用户反馈( 用户从语义层面喜欢某图像 )与预期成果( 用户实际需要高质量版本图像以供使用 )的直接桥梁。
最终,我对于能够最小化反馈与效用之间差距的创新产品界面充满期待( novel product surfaces which minimize this gap between feedback and utility )。若能精准提供我们真正期望的反馈(乐趣),并运用基于此训练的强化学习优化器( If we could provide exactly the feedback we desire (fun), and use powerful reinforcement learning optimizers trained against it ),我们终将开创全新的游戏类型,它们不仅能拓展创意边界,更将创造前所未有的人类体验( we can ultimately produce new genres of games that expand the creative frontier and create novel human experiences )。
当然,在攻克电子游戏领域之后,我们自然会将目光投向更广阔世界的挑战( once we’ve solved video games, we then want to tackle the problems in the wider world )。

文章来自于微信公众号 “范阳”,作者 “范阳”



【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】VideoChat是一个开源数字人实时对话,该项目支持支持语音输入和实时对话,数字人形象可自定义等功能,首次对话延迟低至3s。
项目地址:https://github.com/Henry-23/VideoChat
在线体验:https://www.modelscope.cn/studios/AI-ModelScope/video_chat
【开源免费】Streamer-Sales 销冠是一个AI直播卖货大模型。该模型具备AI生成直播文案,生成数字人形象进行直播,并通过RAG技术对现有数据进行寻找后实时回答用户问题等AI直播卖货的所有功能。
项目地址:https://github.com/PeterH0323/Streamer-Sales
