# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
AI读不懂HTML、Markdown长文档的标题和结构,找信息总踩坑?
解决方案来了——
SEAL全新对比学习框架通过带结构感知+元素对齐,让模型更懂长文。

该方法创新性地将文档的宏观层级结构和微观元素语义同时融入到统一的Embedding空间中,显著增强了预训练语言模型对结构化数据的理解和表示能力。
在BGE-M3模型上将MRR@10(信息检索能力评估集)指标从73.96%提升到77.84%,并在真实的线上A/B测试中验证了其有效性。

团队不仅提升了长文档检索准确率,还开源了万级字数长文档数据集。
下面具体来看。
结构化长文档检索中的常见挑战
在日常工作和学习中,我们常常需要从篇幅浩繁的文档中寻找特定信息,例如技术手册、法律文书或研究报告。面对这些结构复杂的长文本,即便是先进的Embedding模型,也可能在信息检索时表现不佳。
一个关键原因是,现有方法在处理结构化长文档时,大多将其视为一长串无差别的纯文本,忽略了标题、段落、列表等固有的结构信息。
这种对文档层次脉络的“视而不见”,可以称之为结构性失明(Structural Blindness),它限制了Embedding模型对文档深层语义的理解能力。
针对这一挑战,团队提出了名为SEAL (Structure and Element Aware Learning) 的对比学习框架,尝试让Embedding模型更好地理解和利用文档的结构信息。
核心解读:SEAL框架的设计思路
该研究旨在解决长文档检索中的两个具体问题:
SEAL框架为此设计了两种相辅相成的训练策略。可以将其理解为对Embedding模型进行的两项专门“辅导”。
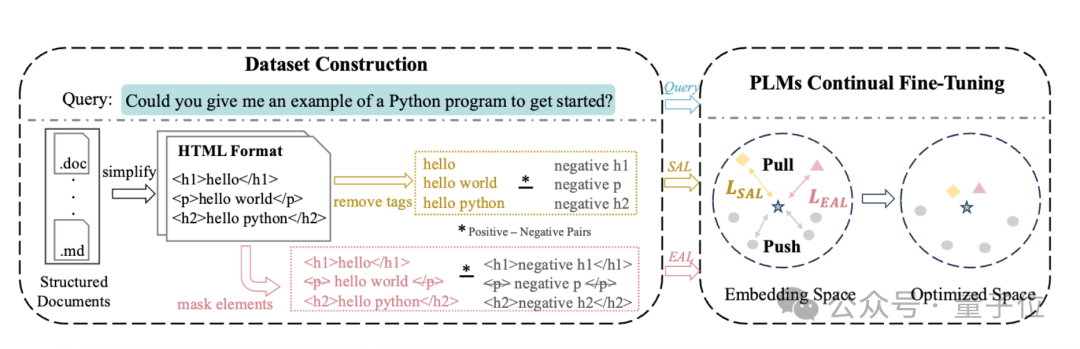
传统的Embedding模型在读取HTML等格式的文档时,往往会剥离等结构标签。SAL的核心思路则有所不同。
它在训练时会向模型同时展示一份文档的两个版本:一个保留了结构标签,另一个则去除了标签。
通过对比学习的任务,模型被鼓励去发现,即使没有明确的标签,某些文本片段(如标题)的内容和位置也蕴含着其结构功能。通过这种方式,模型能够逐步学习到文档的内在”骨架”,区分不同部分的逻辑功能。
为了进一步提升模型对细节的把握,EAL策略引入了一种基于元素(如一个标题或一个段落)的Mask机制。在训练中会按照固定比例随机Mask文档中的一小部分元素,然后要求模型判断这份信息不完整的文档是否与给定的Query相关。
为了完成任务,模型必须更依赖文本内容本身以及周围未被遮盖的元素来推断文档的整体相关性。这个过程促使模型更深入地理解每个文本片段的语义角色及其在上下文中的作用。
实验结果表明,这两种训练策略的结合能够带来积极效果。
在BGE-M3模型上的测试显示,应用SEAL框架后,衡量检索排序质量的关键指标MRR@10从73.96%提升至77.84%。
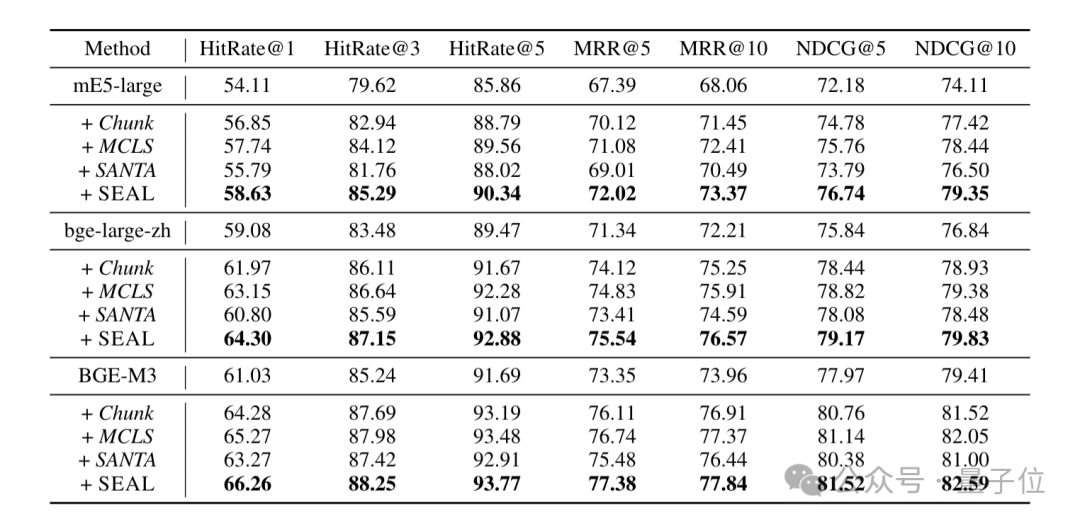
这一数据表明,模型在将更相关的结果排在靠前位置的能力上有所增强。同时,线上A/B测试的结果也初步显示了该方法在实际应用场景中的积极影响。
同时,该团队还发布了一个名为StructDocRetrieval的新数据集,其中包含带有结构标注的万词级别长文档。
该数据集的文档词数远超MS MARCO等典型短数据集(MS MARCO大多文档不到700字,最长1670字 ),填补了该领域的数据空白。
并且,它利用HTML格式来表示文档,包含了丰富的结构语义标注。

△StructDocRetrieval的一个数据样例
这个资源的公开,为社区评估和开发面向长文档的检索模型提供了一个新的Benchmark。
总的来说,通过SEAL方法这种对结构信息的精细理解,不仅能为RAG等下游任务提供更可靠信息来源(如助力AI助手精准定位技术文档答案),也在企业知识库、法律科技等专业领域展现出广阔应用前景。
感兴趣的朋友可以到原文查看更多内容~
论文地址:https://arxiv.org/abs/2508.20778
文章来自于微信公众号“量子位”。


【开源免费】FASTGPT是基于LLM的知识库开源项目,提供开箱即用的数据处理、模型调用等能力。整体功能和“Dify”“RAGFlow”项目类似。很多接入微信,飞书的AI项目都基于该项目二次开发。
项目地址:https://github.com/labring/FastGPT
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
