# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
你永远无法精确描述出梵高的笔触或王家卫的光影。AI创作的未来,是让AI直接「看懂」你的灵感,而不是去揣摩你的指令。
AI图像模型杀疯了!
年初,GPT-4o引爆了一股「吉卜力」热潮。
最近,全网更是玩疯了Nano Banana生成的3D手办。

虽然但是,不知道你有没有发现一个「华点」:
这些统一生成与编辑,更多都是在卷指令编辑与实体概念的组合生成;如果想作为智能创作工具,实际上还差着不少。
想象一下,你希望将一张照片中人物的背包,换成另一张照片里裙子的那种图案。你该如何用语言,向AI精确描述那种复杂而不规则的波西米亚风格图案呢?
答案是:几乎不可能。
更进一步,当你想借鉴的不是物体,而是一种抽象的「感觉」——
例如,一张老照片独特的「复古胶片感光影」,或者一种特定画家的「笔触风格」时,那些只擅长提取和复制一个具体的「物体」的模型便会束手无策。
要是AI既能听懂人话,又能精准Get这些抽象的风格,那该多好!
最近,这个瓶颈被港科大贾佳亚带领的AI研究团队给捅破了,Github 两周揽星1.6K,被很多国外创作者分享在YouTube和论坛上,引发大量讨论。
在这一篇名为「DreamOmni2: Multimodal Instruction-based Editing and Generation」的论文中,AI掌握了针对「抽象概念」的多模态编辑与生成能力。

· 论文地址:
https://arxiv.org/html/2510.06679v1
· 项目主页:
https://pbihao.github.io/projects/DreamOmni2/index.html
· 代码仓库:
https://github.com/dvlab-research/DreamOmni2
基于强大的FLUX Kontext模型,DreamOmni2在保留顶尖文生图与指令编辑能力的基础上,被赋予了处理多个参考图像的全新能力,使其成为更加智能的创作工具。
它不仅在传统任务上显著优于现有的开源模型,更在全新的抽象概念处理任务上,展现出超越谷歌最强Nano Banana的实力。
光说不练假把式,我们直接上实测。
首先来个经典的:输入一个产品,然后让角色来「带货」。
Prompt:
The character from the first image is holding the item from the second picture.
让图1里的角色,拿着图2里的物品。
这表情、这头发、这手指的细节,以及衣服的质感,简直完美有没有。
而且,产品本身也得到了很好的融入。

接下来,我们再试试三次元里的效果——让模型把图1中的男子,替换成图2中的女子。

结果出炉!
可以看到,在生成的图片中,背景的山峦和赛博感的光线效果几乎完美继承,人物身前的文字更是毫无影响。
人物方面,衣服和发型基本和原图2一致,面部的光线则模仿了图1中的效果。
可以说是十分惊艳了。

说到光线渲染,我们加大难度,让模型把图2中的红蓝风格,迁移到图1上。
Prompt:
Make the first image has the same light condition as the second image.
让图1的光照和图2保持一致。

没想到,DreamOmni2不仅保持了图1原有的像格栅一样的光照,融合之后的红蓝对比也十分强烈。

相比之下,GPT-4o(下图左)只迁移了色调,光影效果没有保留。Nano Banana(下图右)只能说稍稍变了点色,但不多。

风格迁移更是手拿把掐。
Prompt:
Replace the first image have the same image style as the second image.
将图1处理成与图2相同的风格
像素风的鸡——搞定。

二次元风的小姐姐——搞定。(太美了)

图案、文字,也通通不在话下。


Prompt:
On the cup, "Story" is displayed in the same font style as the reference image.
在杯子上用参考图里的同款字体显示“Story”字样

不仅如此,DreamOmni2也十分擅长对动作进行模仿。
Prompt:
Make the person from the first image has the same pose as person from the second image.
让图1里的人,模仿图2中的姿势

在DreamOmni2生成的结果中,胳膊和腿的动作基本完美复刻了图2。
但有些遗憾的是,人物的方向和手部的细节略有不同。

不过,相比起在语义理解上出了大问题的开源模型FLUX Kontext,那强了可不是一星半点。
如下图所示,显然,Kontext完全没有搞懂什么「第一张图」、「第二张图」,以及还要调整姿势什么的,于是干脆复制了一遍图2完事。

闭源模型这边,GPT-4o(下图左)的动作模仿比较到位,但面部的一致性不太好。
而Nano Banana(下图右)就有点抽象了,生生造出了个「三体人」:)

除了身体上的动作,DreamOmni2在面部微表情,以及发型这块编辑,也是又准又稳。
Prompt:
Make the person in the first image have the same expression as the person in the second image.
让图1里的人,做出和图2相同的表情。
嘴巴张开的大小、眼睛眯成的缝,简直一模一样,可以说是非常灿烂了。
这种效果如果像要靠语言去形容,恐怕是很难做到的。

Prompt:
Make the person in the first image have the same hairstyle as the person in the second image.
给图1里的人换上和图2中一样的发型
不管是背景的沙发,还是人物的动作、衣服,都一点没变;只有头发从黑色短发变成了长长的金色卷发。
注意看脖子,因头发遮挡而带来的阴影,也一并呈现了出来。

值得一提的是,DreamOmni2的多图编辑能力非常强。
比如,让图1的鹦鹉戴上图2的帽子,模仿图3中的氛围与色调。

可以看到,从鹦鹉的羽毛、帽子颜色,到整个背景的氛围都很好的复刻了上图中的火箭图片。

再上点难度:一下子输入4张图,然后让模型把前3张图组合起来,并改成图4的风格。

不管是女生衣服上的条纹、男生脸上的络腮胡,还是小狗的品种,都完美地迁移了过去。
同时,画中的笔触和色彩运用,也得到了比较忠实的呈现。

国外的网友们在体验之后,纷纷表示惊艳。
甚至还有人出了一期教程,直言「别再用Nano Banana了,DreamOmni2 ComfyUI才是最强的免费工作流!」
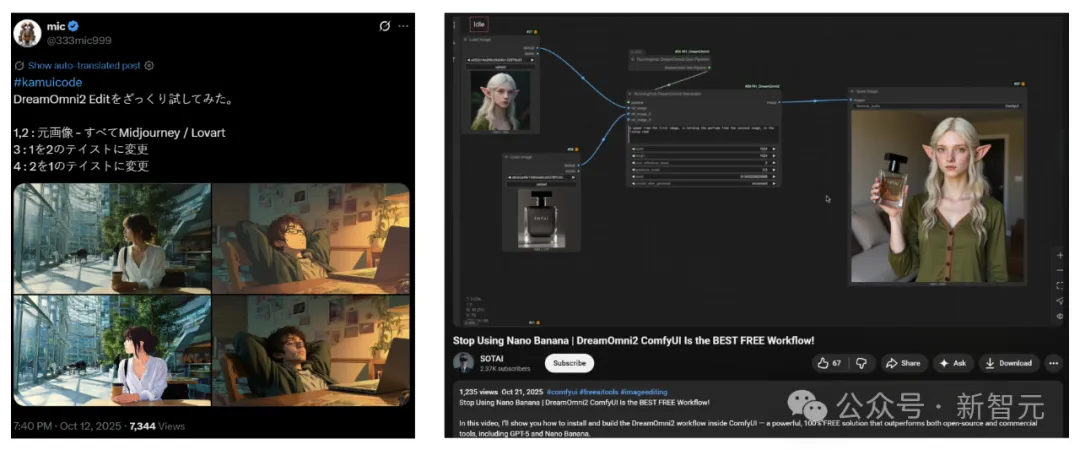
更多实测可见:
· Huggingface Editing Demo:
https://huggingface.co/spaces/wcy1122/DreamOmni2-Edit
· Huggingface Generation Demo:
https://huggingface.co/spaces/wcy1122/DreamOmni2-Gen
· Video Demo:
https://www.youtube.com/watch?v=8xpoiRK57uU
为了真实展现DreamOmni2性能,研究团队专门打造了一个全新的DreamOmni2基准测试集,包括205个多模态指令式编辑测试用例和114个指令式生成测试用例。
考察的重点便是多模态指令生成以及「抽象属性」和「具体物体」的混合编辑。

DreamOmni2基准测试中多模态指令生成及编辑示例
在多模态指令编辑测试中,相比于业界顶流GPT-4o和Nano Banana,DreamOmni2显示出了更精确的编辑结果和更好的一致性。
除了编辑指令的执行率之外,GPT-4o和Nano Banana在编辑时还会存在一些小问题,例如,经常引入意料之外的改动或不一致。比如,你让它换个姿势,它连衣服都给你换了。
在纵横比方面,GPT-4o只支持三种输出,而Nano Banana的则难以控制。
更有趣的是,GPT-4o处理过的图片还会「蜜汁发黄」。
相比之下,这些问题在DreamOmni2上都是不存在的。
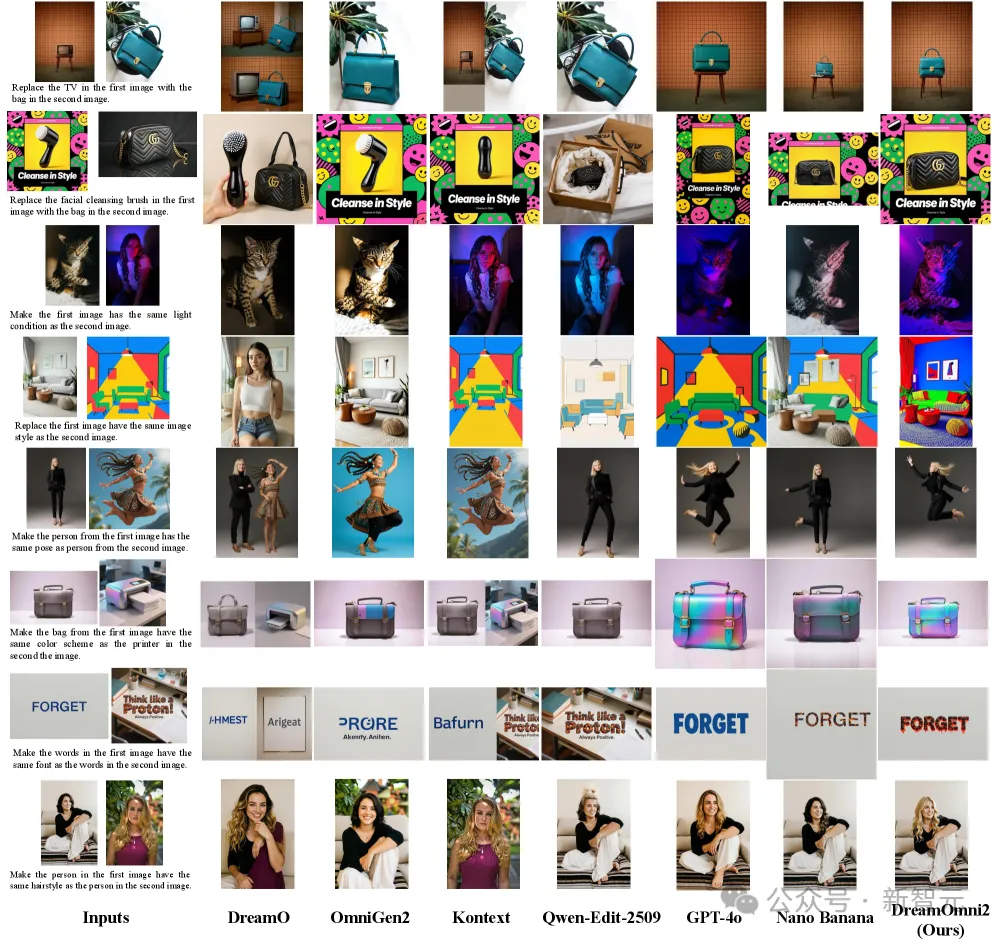
多模态指令编辑的视觉比较
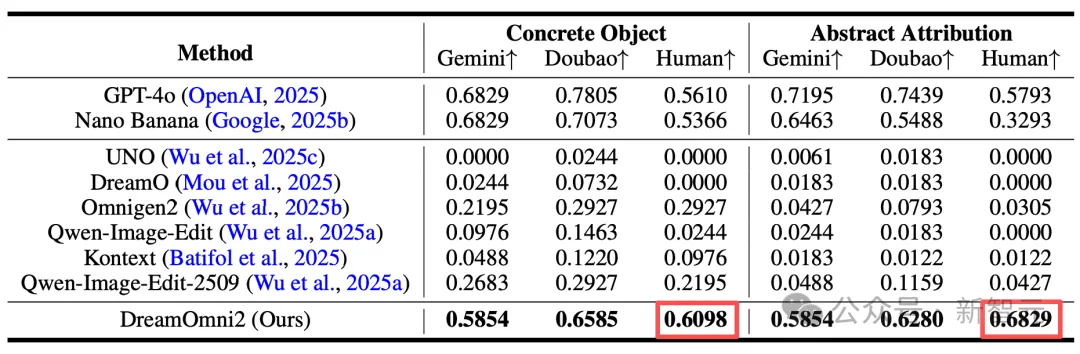
在定量分析的表格里,也反映出了这些问题。
DreamOmni2在「具体物体」和「抽象属性」上的得分都是最高的,一些方面超过了GPT-4o和Nano Banana。
在多模态指令生成方面,DreamOmni2表现同样惊艳。
实测结果表明,此前的开源模型在生成抽象属性方面十分困难。
例如下图第四行,将照片中的狗抽象成右边的素描风格,几个开源模型几乎是「无动于衷」。
相比之下,DreamOmni2不仅显著领先开源模型,而且还达到了与GPT-4o和Nano Banana相当甚至更好的水平。

多模态指令生成可视化对比
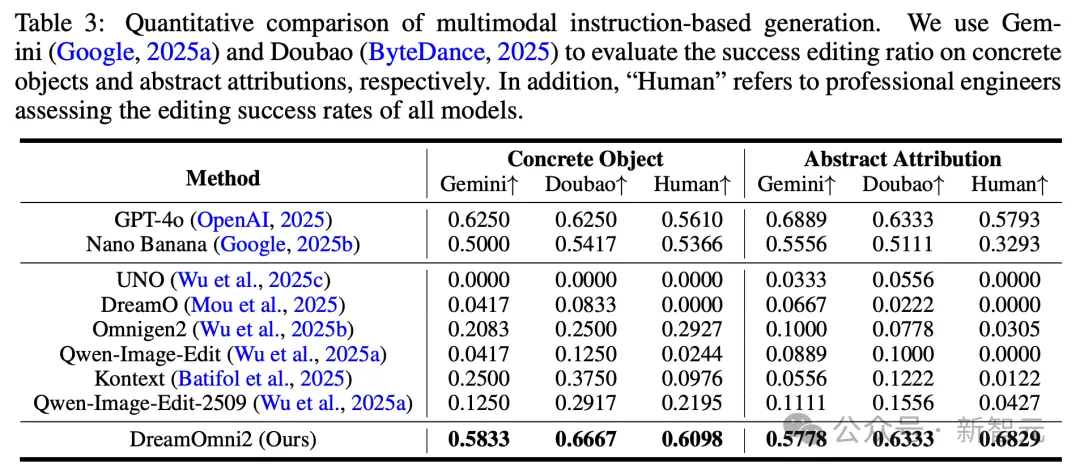
定量评估中,DreamOmni2也在人工评估和AI模型评估中均优于商业模型Nano Banana,取得了与GPT-4o相当的结果。
在生成准确性和对象一致性方面也要优于一众开源模型,即使在这些开源模型的专业领域内也是如此。
要实现如此强大的功能,最大的挑战在于训练数据。
显然,这个世界上并不存在海量的「(源图像+参考图像+指令)-> 目标图像」这样的现成数据对。
为了解决这一问题,研究团队设计了一套的三阶段数据构建范式,为DreamOmni2「量身定制」了高质量的教材。
第一阶段:创造高质量的概念对
团队利用基础模型的文生图能力,提出了一种新颖的特征混合方案。
它可以在生成图像的过程中,交换两个生成分支之间的注意力特征,从而创造出包含相同具体物体或相同抽象属性的高质量图像对。
相比于过去将两张图拼接在一起的方法,这种方案生成的图像分辨率更高,质量更好,且完全避免了边缘内容混淆的问题。
第二阶段:生成多模态「编辑」数据
利用第一阶段的数据,团队首先训练了一个「提取模型」。这个模型能从一张图像中精准「提取」出某个物体或某种抽象属性,并根据指令生成一张新的参考图。
随后,他们利用一个基于指令的编辑模型,对目标图像中提取出的物体或属性进行修改,从而创造出「源图像」。
这样一来,一个完整的编辑训练数据对就诞生了:(源图像 + 编辑指令 + 参考图像)-> 目标图像。
第三阶段:创建多模态「生成」教材
在第二阶段的基础上,团队再次使用「提取模型」,从源图像中提取出更多物体或属性,生成更多的参考图像。
这样,就构成了用于多模态生成的训练数据:(多张参考图像 + 生成指令)-> 目标图像。
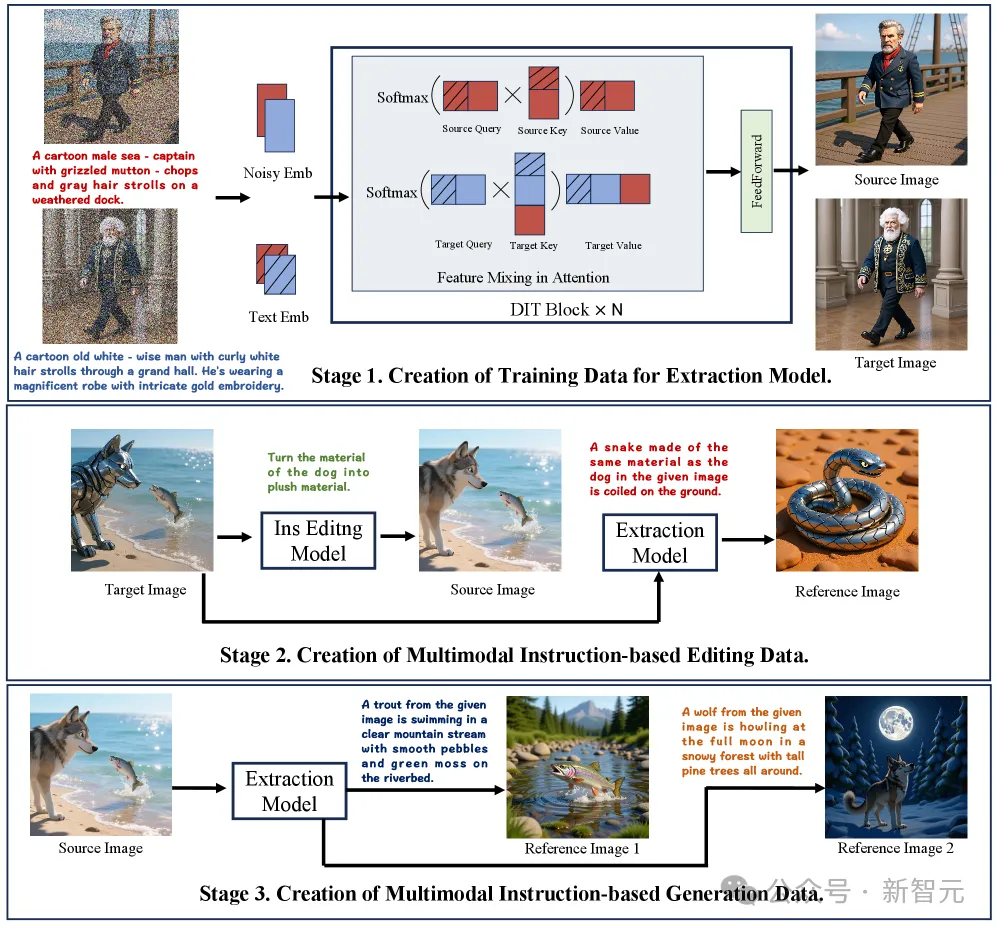
通过这个三阶段流水线,团队成功构建了一个多样化、高质量的综合数据集,涵盖了对具体物体和抽象属性(如局部和全局属性)的生成和编辑,并且支持多个参考图像输入。
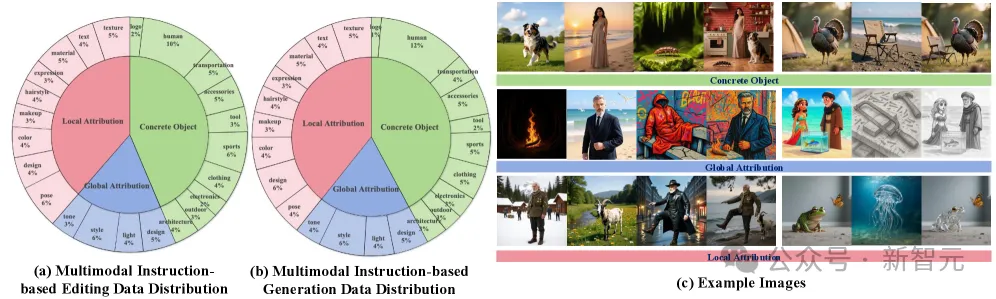
多模态指令编辑和生成训练数据的分布和样本
有了数据,还需要一个能「消化」这些数据的模型框架。
然而,当前SOTA的统一生成和编辑模型(如FLUX Kontext),并不支持多图像输入。
为此,团队对框架进行了两项关键创新,以及相应的训练机制:
1. 索引编码与位置编码移位
为了让模型能够准确区分多个参考图像并理解指令中对它们的引用(例如,图像1、图像2),引入了索引编码(Index Encoding)和位置编码偏移方案(Position Encoding Shift Scheme)。
其中,索引编码可以帮助模型识别输入图像的索引,而位置编码则会根据先前输入的大小进行偏移,从而防止像素混淆和生成结果中出现复制粘贴的伪影。
这两者结合,让模型能够清晰、准确地处理多图像输入。
2. 视觉语言模型(VLM)与生成模型的联合训练
现实世界中,用户的指令往往是不规范、甚至逻辑混乱的;而模型训练时用的指令却是结构化的。
为了弥合这一鸿沟,团队创新性地提出了一种联合训练方案,显著提升了模型理解用户意图的能力,增强了在真实应用场景中的性能。
具体来说,他们让一个强大的VLM(Qwen2.5-VL)先来理解用户的复杂指令,并将其「翻译」成模型能理解的结构化格式,最后再交由生成/编辑模型去执行。
3. LoRA微调
在训练策略上,团队采用了LoRA微调方法。这样做的好处是,可以在不影响模型原有强大能力的基础上,使其多模态能力(多图输入和编辑/生成)能够在检测到参考图像时无缝激活,同时保留了基础模型的原始指令编辑能力。
DreamOmni2的出现,代表了AI创作工具发展的一个重要方向:从单一的语言模态,走向真正的多模态、多概念融合。
研究团队则通过提出两项全新的、高度实用的任务,并为此构建了完整的数据流水线和创新的模型框架,成功地推动了生成式AI的技术边界。
对于设计师、艺术家和每一个热爱创作的普通人来说,一个更加智能、更加全能的创作时代,正加速到来。
参考链接:
https://arxiv.org/html/2510.06679v1
https://pbihao.github.io/projects/DreamOmni2/index.html
https://github.com/dvlab-research/DreamOmni2
https://huggingface.co/spaces/wcy1122/DreamOmni2-Edit
https://huggingface.co/spaces/wcy1122/DreamOmni2-Gen
https://www.youtube.com/watch?v=8xpoiRK57uU
文章来自于“新智元”,作者“犀牛 好困”。


【开源免费】字节工作流产品扣子两大核心业务:Coze Studio(扣子开发平台)和 Coze Loop(扣子罗盘)全面开源,而且采用的是 Apache 2.0 许可证,支持商用!
项目地址:https://github.com/coze-dev/coze-studio
【开源免费】n8n是一个可以自定义工作流的AI项目,它提供了200个工作节点来帮助用户实现工作流的编排。
项目地址:https://github.com/n8n-io/n8n
在线使用:https://n8n.io/(付费)
【开源免费】DB-GPT是一个AI原生数据应用开发框架,它提供开发多模型管理(SMMF)、Text2SQL效果优化、RAG框架以及优化、Multi-Agents框架协作、AWEL(智能体工作流编排)等多种技术能力,让围绕数据库构建大模型应用更简单、更方便。
项目地址:https://github.com/eosphoros-ai/DB-GPT?tab=readme-ov-file
【开源免费】VectorVein是一个不需要任何编程基础,任何人都能用的AI工作流编辑工具。你可以将复杂的工作分解成多个步骤,并通过VectorVein固定并让AI依次完成。VectorVein是字节coze的平替产品。
项目地址:https://github.com/AndersonBY/vector-vein?tab=readme-ov-file
在线使用:https://vectorvein.ai/(付费)
【免费】ffa.chat是一个完全免费的GPT-4o镜像站点,无需魔法付费,即可无限制使用GPT-4o等多个海外模型产品。
在线使用:https://ffa.chat/
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
