# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在 AI 多模态的发展历程中,OpenAI 的 CLIP 让机器第一次具备了“看懂”图像与文字的能力,为跨模态学习奠定了基础。如今,来自 360 人工智能研究院冷大炜团队的 FG-CLIP 2 正式发布并开源,在中英文双语任务上全面超越 MetaCLIP 2 与 SigLIP 2,并通过新的细粒度对齐范式,补足了第一代模型在细节理解上的不足。
这项工作让模型不仅能识别图像中的主体,还能更准确地理解其中的属性、关系与语义,为 AI 的视觉语言理解能力迈向“更清晰、更精准”开启了新的阶段。
OpenAI 的 CLIP 模型是 Foundation Model 的一个里程碑式成就,它成功地证明了通过大规模图文数据的对比学习,可以让 AI 模型掌握跨越视觉和语言的泛化关联能力,为零样本识别、多模态大模型、图像生成,以及搜索、推荐、办公、安防等下游模型和应用奠定了坚实的基础 ,在很大程度上解决了让 AI “看见”并大致理解图文内容的问题。
技术的进步总是伴随着对既有边界的突破。以 CLIP 为代表的第一代跨模态模型,其核心优势在于宏观主体的理解,例如识别出“公园里的一只狗”,但当面对需要精确细节认知的任务时,其局限性便显现出来。它们难以稳定地分辨“一只正在半空中接住红色飞盘的金毛寻回犬”这样的复杂理解场景,因为模型无法分辨物体的细节属性和复杂交互。这种“看得懂,但看不清”的“近视”现象,是第一代模型固有的细粒度理解瓶颈。

为了突破这一瓶颈,由冷大炜博士带领的 360 人工智能研究院视觉团队于 ICML2025 上提出了新一代的图文跨模态模型 FG-CLIP,主打细粒度图文对齐和理解能力。现在,全面升级后的 FG-CLIP 2 正式发布并开源。
FG-CLIP 2 从训练范式、目标函数到数据生态对上一代模型进行了全面革新,从源头解决了 CLIP 的近视和粗粒度词袋效应,补齐了业界亟需的中文能力支
持,在 8 大类多达 29 项的 benchmark 评测上,FG-CLIP 2 超越包括 SigLIP 2 和 MetaCLIP 2 在内的最新强力基线,双语性能达到全球第一。
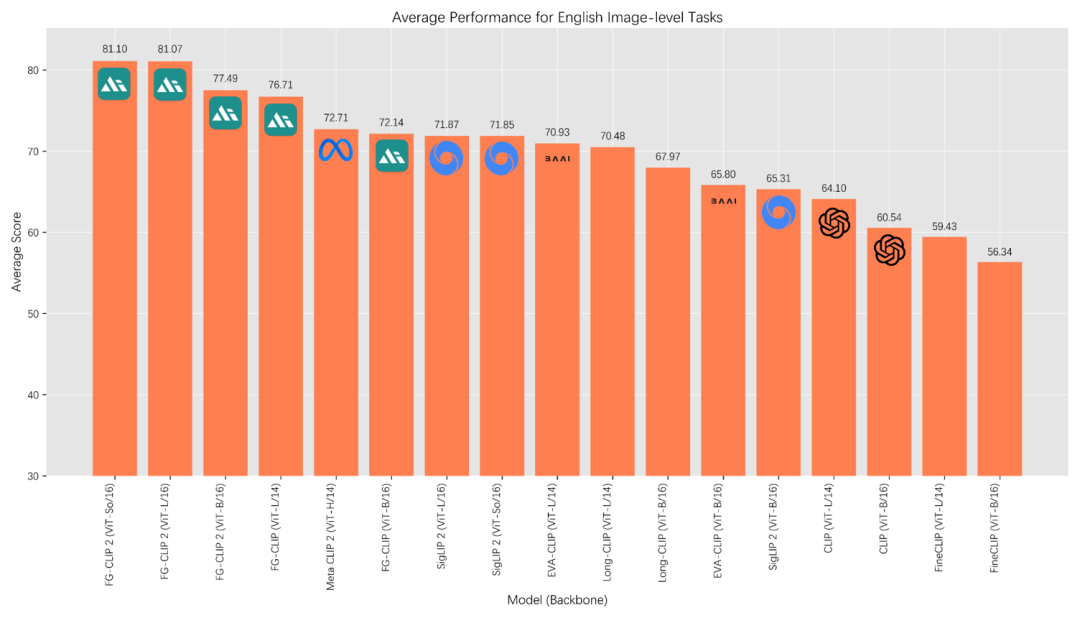
英文 benchmark 综合排名
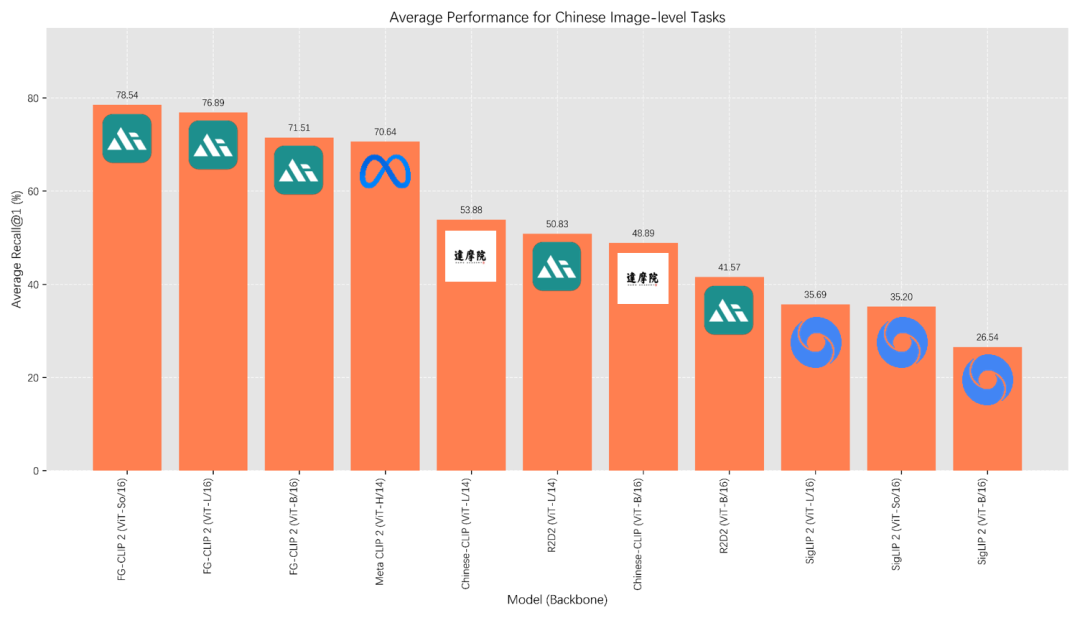
中文benchmark综合排名
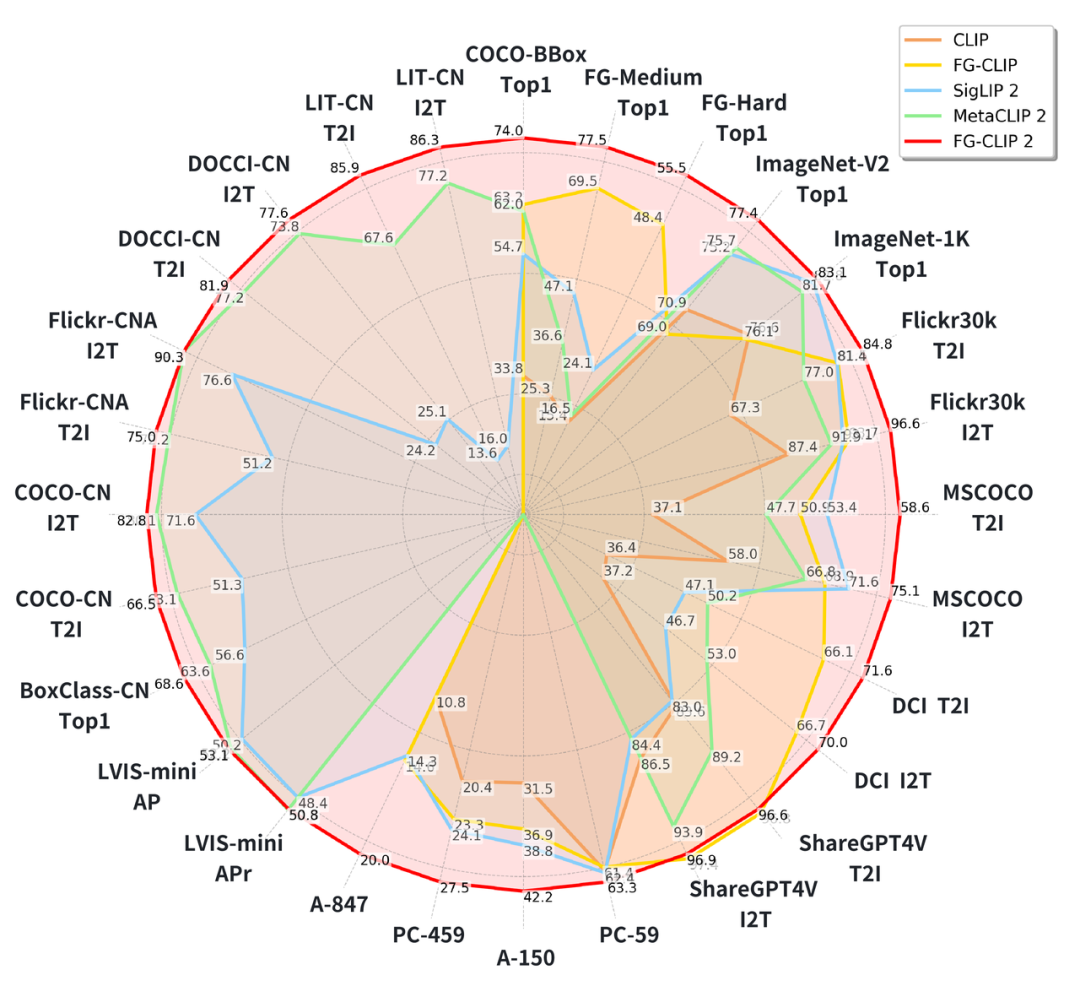
FG-CLIP 2性能雷达图
要理解 FG-CLIP 2 的价值,我们必须首先清晰地认识第一代模型在图文理解任务上所面临的根本性障碍。
1. 粗放的数据与单一的目标
第一代模型的成功很大程度上源于“数量优势”,它们消化了数十亿级的互联网图文对 。然而,这些数据的文本描述质量参差不齐,通常只是与图像内容存在松散的主题关联,而非精确的细节刻画。基于整体特征对齐的训练目标,模型在训练中被反复告知“这张图”和“这段话”是相关的,这种粗粒度的监督信号,激励模型学习一种“主题对齐”。模型因此擅长将“沙滩”、“海洋”的视觉特征与“夏天”、“度假”的文本概念联系起来,但这并不足以支持更深层次的理解。
当任务要求区分“一个穿蓝色T恤的男孩在左边”和“一个穿蓝色 T 恤的男孩在右边”时,依赖全局特征的第一代模型便会感到困惑。因为它从未被系统性地训练去关注“蓝色 T 恤”这一局部区域,也未被要求将“左边”这个空间关系词精确对应到图像的具体坐标。其核心的对比学习目标,旨在拉近匹配图文对的全局特征,而忽略了局部细节的精确对应。
2. 语言的壁垒与评测的缺失
在 FG-CLIP 2 之前,细粒度跨模态模型的研发几乎完全集中在英语世界。尽管部分工作在提升英语细粒度理解上取得了进展,但中文世界却严重滞后鲜有建树。第一代中文跨模态模型的代表如 Chinese-CLIP 和 R2D2,其主要能力仍局限于短文本检索等全局任务,缺乏对区域级别细节和长文本描述的有效支持。
另一个更深层的障碍在于,中文多模态领域甚至缺少一个公认的、能够严格评估细粒度理解能力的综合性基准测试。现有的中文数据集大多仍停留在短文本检索层面,这导致模型开发者缺乏明确的优化方向,也无法准确衡量模型在细粒度任务上的真实水平,制约了整个领域的系统发展。
基于上述关键问题的深入洞察,催生了 FG-CLIP 2 的全新设计——为实现精细化、双语理解而生的第二代模型框架。
FG-CLIP 2 的代际突破,体现在其独特的“两阶段训练、多目标优化、高质量数据”的全新范式中。这一系列设计旨在将模型从一个“宏观观察者”,转变为一个“微观分析师”。
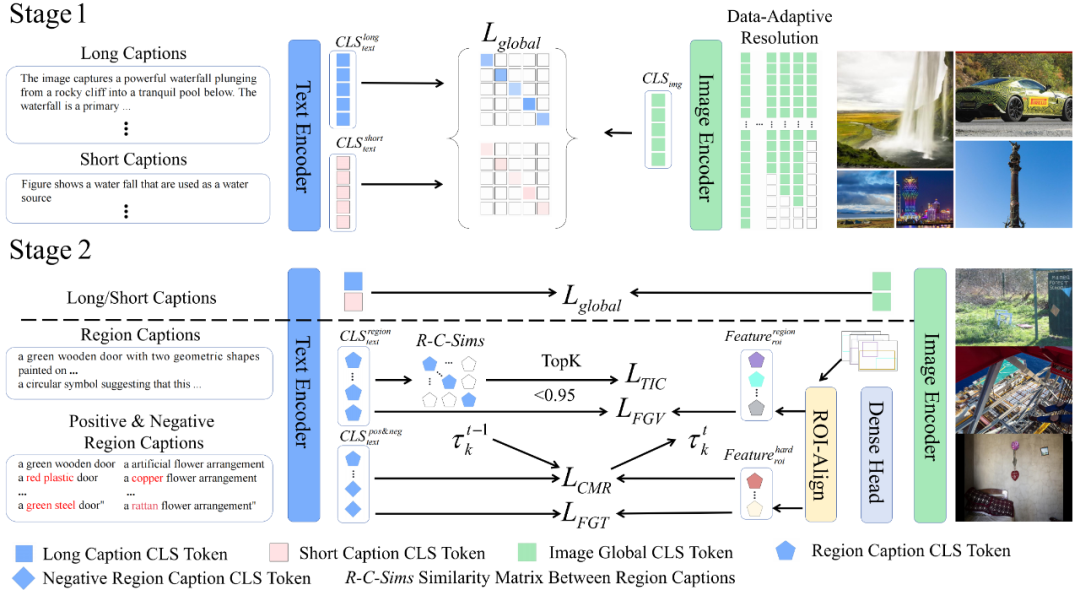
1. 两阶段分层学习:从博学到精通
FG-CLIP 2 的训练过程被划分为两个递进的阶段,模拟了从宽泛认知到深入理解的学习过程。
2. 五位一体的目标函数矩阵:精细化理解的核心引擎
区别于第一代模型,FG-CLIP 2 的优化目标不再是简单的整体特征对齐,而是一组经过验证过的协同优化函数矩阵。
通过这套精心设计的优化约束和数据生态搭配,FG-CLIP 2 被系统性地塑造成为一个既能把握全局,又能洞察微末,且能驾驭双语复杂性的第二代跨模态模型。
FG-CLIP 2 的先进性最终由横跨 8 大类任务、29 个公开数据集上的实验结果来证明,这些性能指标展示了其作为新一代跨模态模型的优势。
1. 树立中文评测新标杆
在展示性能之前,FG-CLIP 2 团队为弥补中文长文本评测和区域级别分类评测方面的不足,构建并推出了一套新的中文评测基准,包括面向长文本检索的 LIT-CN、DCI-CN 和 DOCCI-CN,以及用于区域级别分类的 BoxClass-CN。
这一贡献补充了中文多模态研究的空白,为后续工作提供了坚实的量化评估基础。
2. 在核心“细粒度理解”任务上取得突破
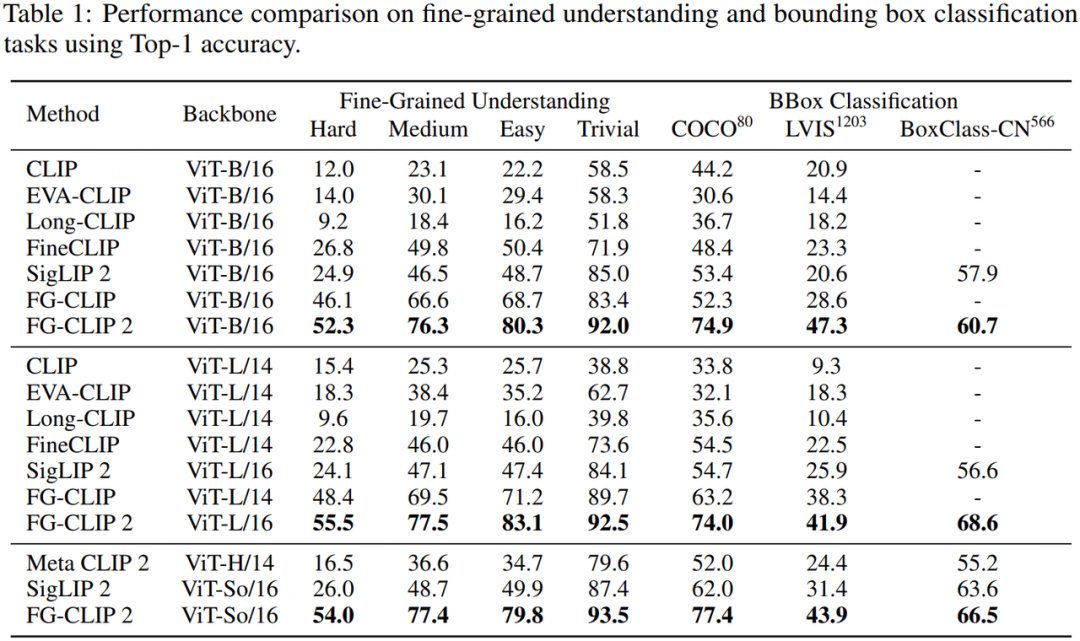
在最能体现细粒度图文对齐能力的 FG-OVD 基准测试中,FG-CLIP 2 的表现十分出色。在最具挑战性的“hard”子集上,FG-CLIP 2 (ViT-B/16) 的准确率达到了 52.3%,显著优于现有 baseline,展示了其在区分极其相似的视觉-语言对应关系上的卓越能力。
在边界框分类任务上,无论是在英文的 COCO、LVIS 数据集,还是在新构建的中文 BoxClass-CN 数据集上,FG-CLIP 2 都以大幅领先的优势取得了当前最佳(SOTA)成绩,充分展示了其跨语言的、强大的局部内容与语义概念对齐能力。
3. 掌握复杂语言,领跑长文本检索
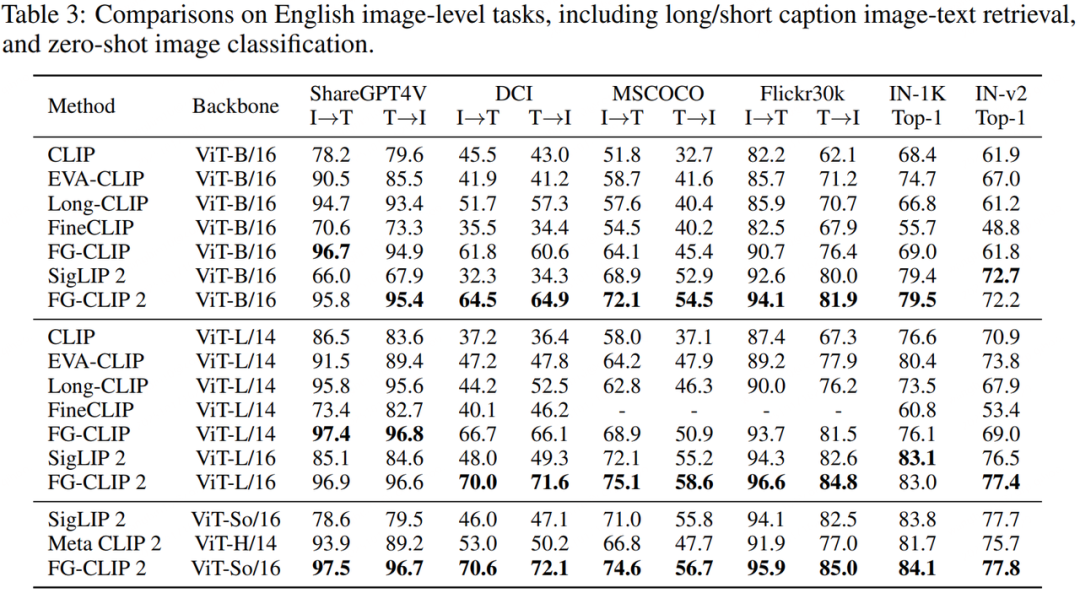
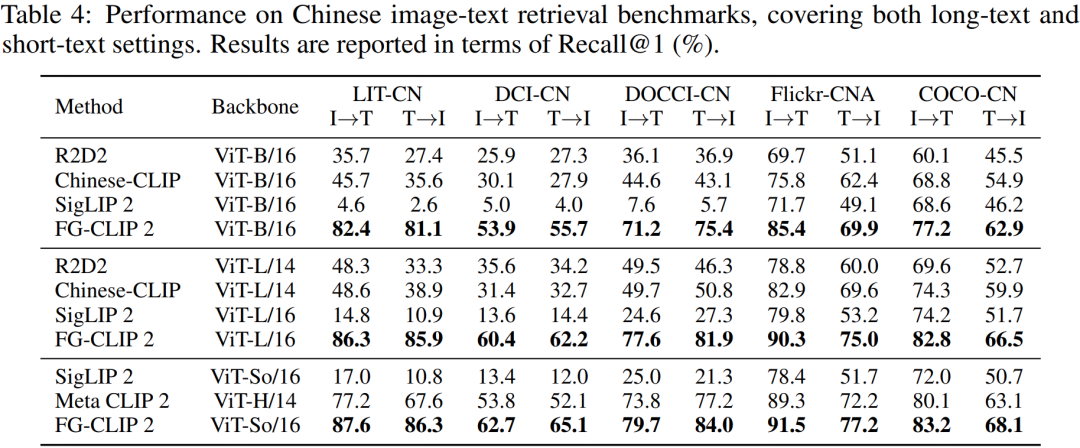
如果说短文本检索考验的是基础匹配能力,那么长文本检索则是对模型细粒度理解能力的综合检验。在中英文的长文本检索任务中,FG-CLIP 2 均展现出巨大的领先优势。特别值得一提的是,在中英文的多个榜单上,FG-CLIP 2 (ViT-L/16, 10亿参数) 的表现甚至超越了参数量更大的 Meta CLIP 2 (ViT-H/14, 18亿参数) 。这有力地证明了 FG-CLIP 2 训练范式的高效性——用更小的模型规模实现了更强的性能,这是“代际领先”而非“参数堆砌”的体现。
4. 赋能下游任务,展现应用潜力
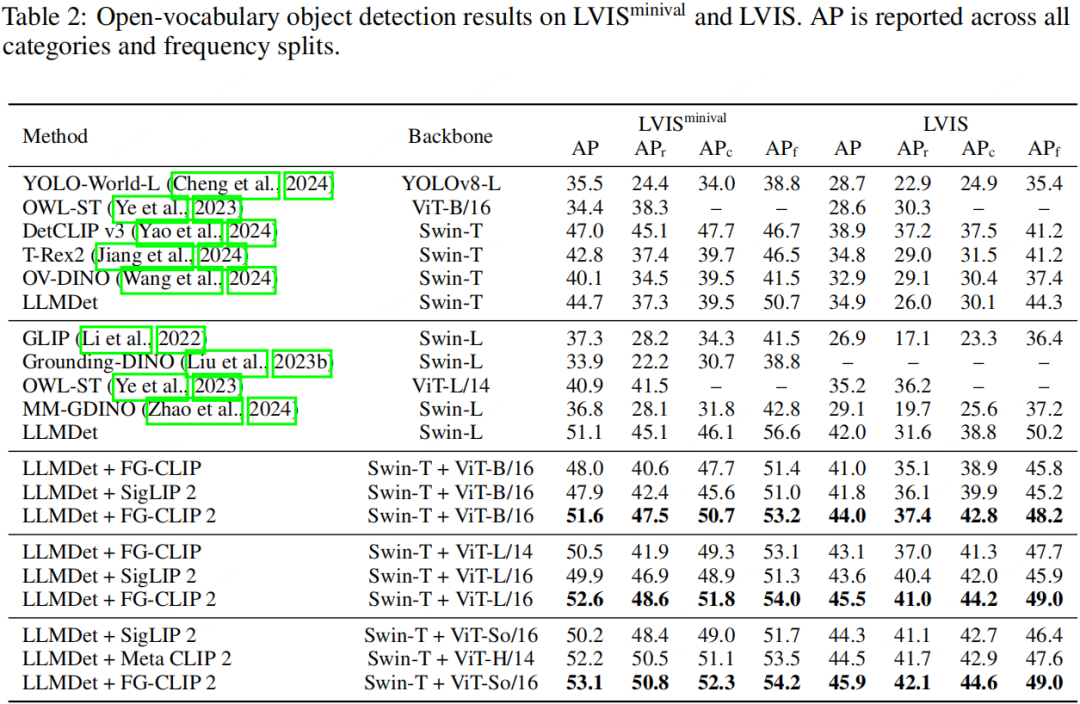
FG-CLIP 2 的价值不止于刷新榜单。在开放词汇目标检测(OVD)场景中,当 FG-CLIP 2 与检测器 LLMDet 结合时,取得了开源方法中的最佳性能,证明其卓越的泛化能力可以有效迁移,提升下游系统的准确性。通过采用 Cat-Seg 作为基础架构,FG-CLIP 2 在开放词汇分割领域同样取得了更优的性能。更重要的是,当 FG-CLIP 2 被用作视觉编码器集成到多模态大模型(LMM)中时,搭载 FG-CLIP 2 的 LMM 在 GQA、MMMU 等多个高级多模态推理基准上,全面超越了使用其他开源视觉编码器的同类模型。这表明 FG-CLIP 2 强大的细粒度和双语能力能够有效传递到更高层次的认知任务中,是构建下一代 LMM 的理想基石。
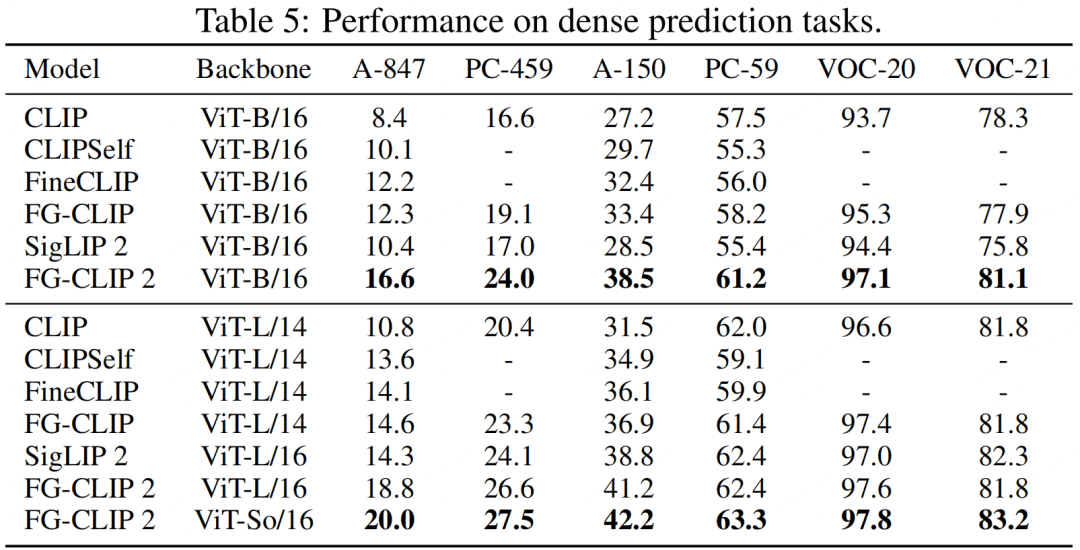
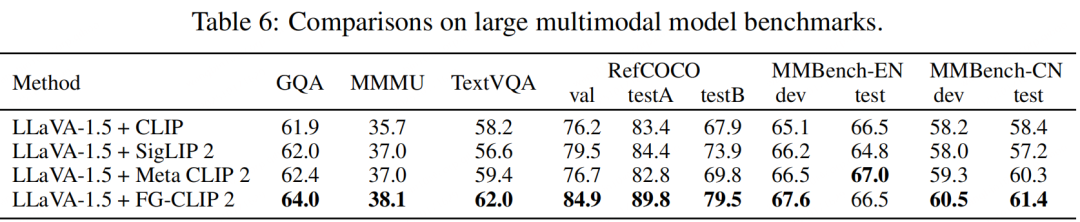
5. 消融实验
为了验证创新模块的有效性,研究团队进行了严格的消融实验。结果显示,当移除其独创的文本域内对比损失 L_TIC 后,模型在 COCO 分类任务上的 Top-1 准确率骤降 4.8 个百分点。当同时移除 L_TIC 和跨模态排序损失 L_CMR 后,准确率更是大幅下跌。这些数据清晰地证明了,正是这些针对细粒度任务精心设计的模块,构成了 FG-CLIP 2 成功的核心。
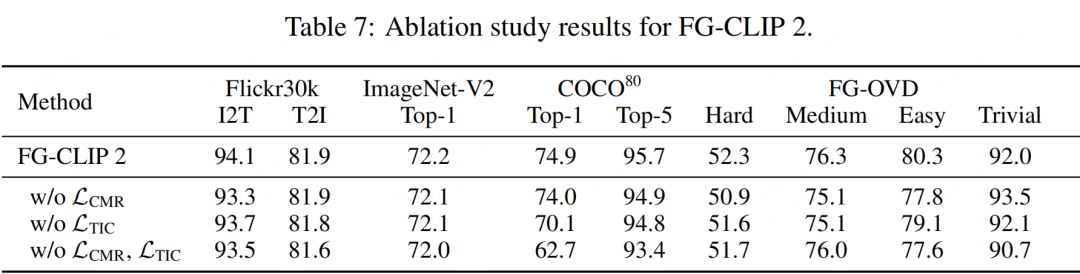
CLIP 开启了跨模态学习的时代,解决了“图文能否对齐”的问题;而 FG-CLIP 2 引领的第二代能力跃迁,则致力于解决“能否深入理解”的核心难题。FG-CLIP 2 的贡献包括:
FG-CLIP 2 用扎实的实验数据,证明了自己是当之无愧的第二代细粒度视觉语言对齐模型的代表。随着 FG-CLIP 2 的模型、代码和基准的全面开源,更精准的以图搜图、更智能的人机交互、更可靠的机器人场景理解、更强大的多模态内容创作,都将拥有一个值得信赖的坚实技术底座。
文章来自于“CSDN”,作者 “梦依丹”。



