
对话Clipto.AI创始人康洪文:没有记忆的AI,只是一个“失忆”的聪明人
对话Clipto.AI创始人康洪文:没有记忆的AI,只是一个“失忆”的聪明人模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。
来自主题: AI资讯
6668 点击 2026-07-01 15:02
 搜索
搜索
模型会升级,Agent会重构,但用户长期积累的记忆不会轻易迁移。

押注 AI 的 Memory Layer。

今天几乎所有主流视觉语言模型(VLM)—— 无论是 Qwen-VL、InternVL,还是 LLaVA 系列 —— 都遵循着同一套经典架构:先用预训练视觉编码器(如 CLIP、SigLIP)将图像压缩为特征,再通过投影层把这些特征送入大语言模型。
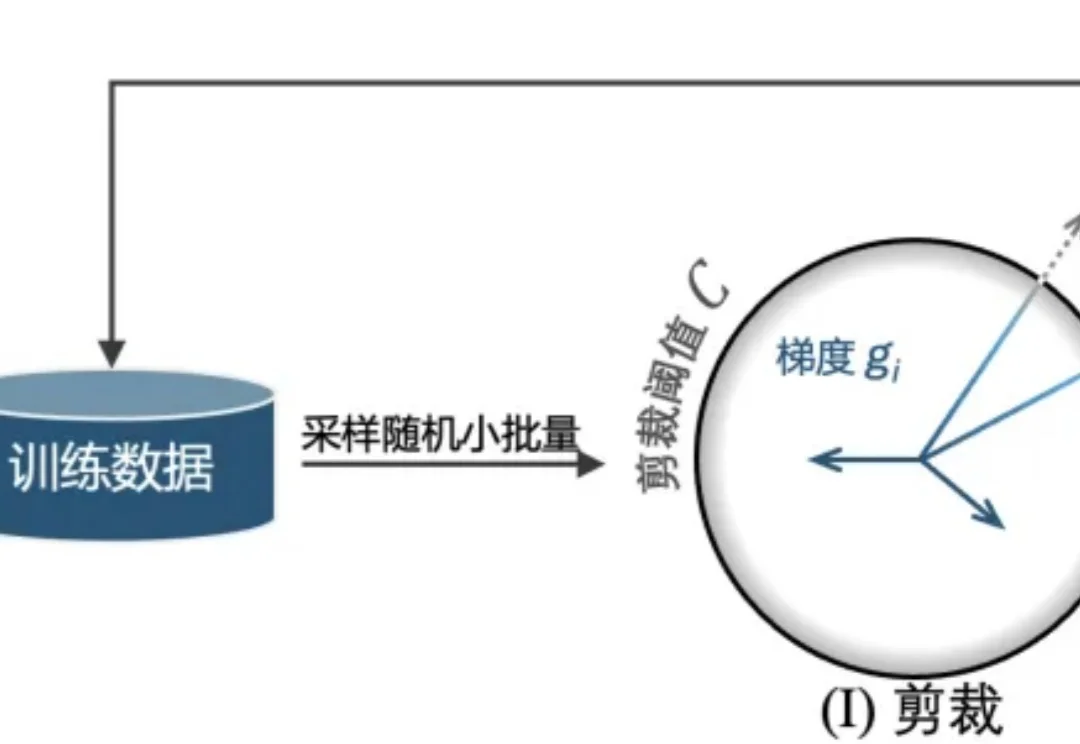
近日,来自英国南安普顿大学(University of Southampton)和广州大学的研究者团队提出 SlaClip,一种用于差分隐私随机梯度下降(DP-SGD)[1] 的自适应梯度剪裁方法。
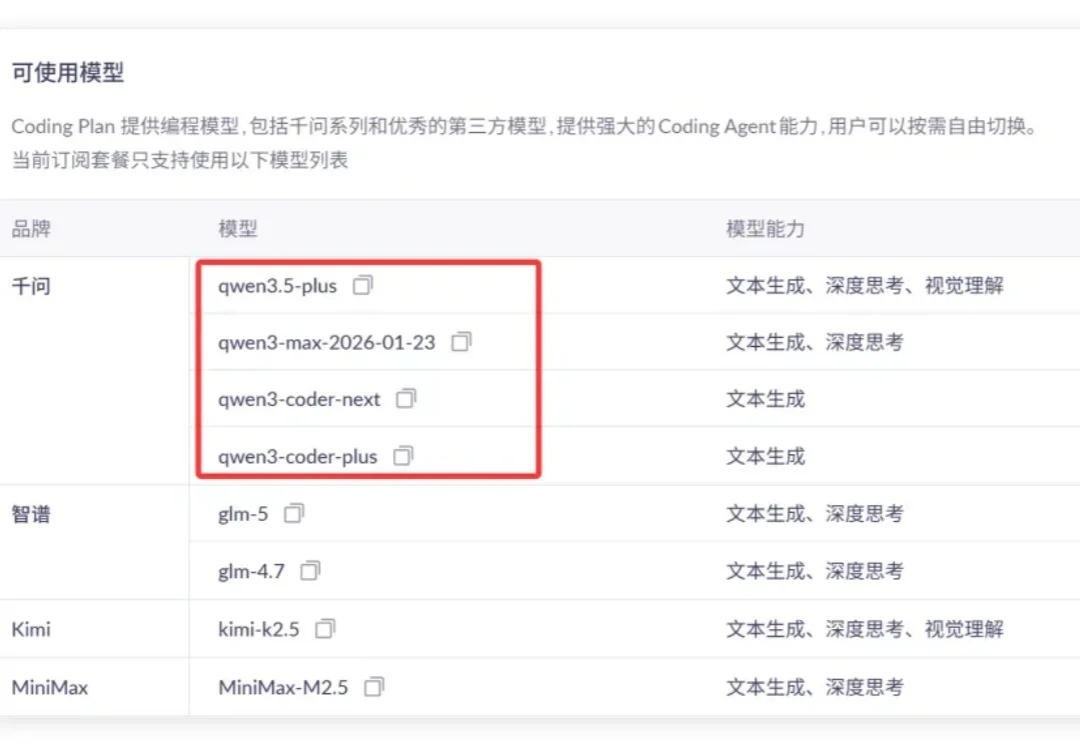
昨天我发现 Qwen3.6“倒反天罡”。
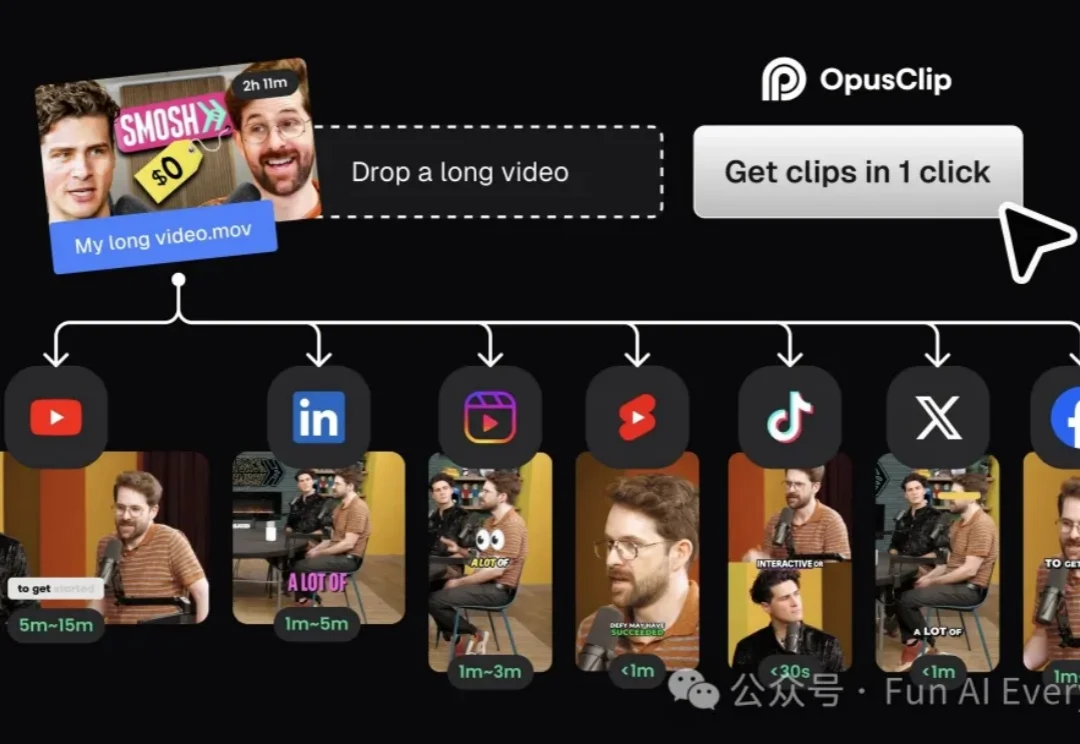
OpusClip 是一款把长视频、长内容自动剪成可发布的短视频片段的 AI 工具,服务内容创作者和企业内容团队。
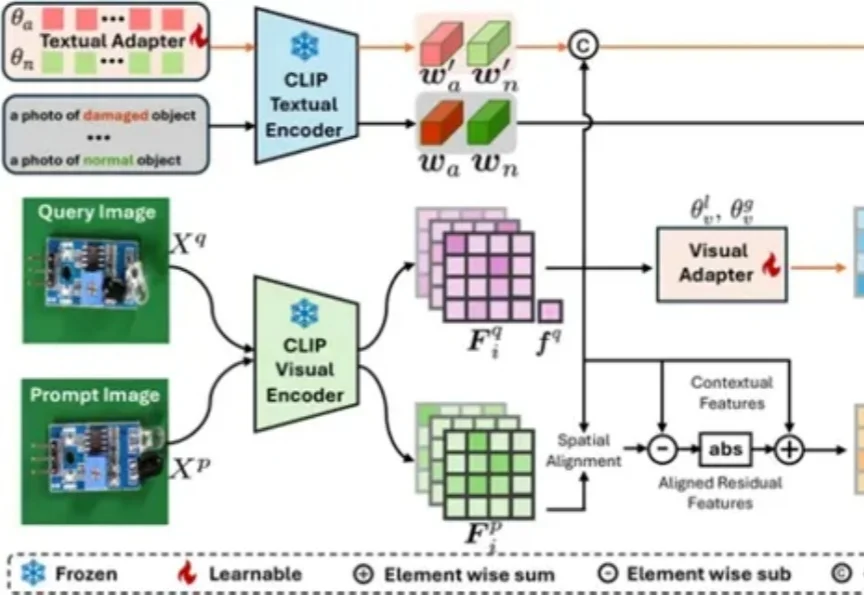
视觉模型用于工业“缺陷检测”等领域已经相对成熟,但当前普遍使用的传统模型在训练时对数据要求较高,需要大量的经过精细标注的数据才能训练出理想效果。
清华大学智能产业研究院(AIR)联合清华大学生命学院、清华大学化学系在Science上发表论文:《深度对比学习实现基因组级别药物虚拟筛选》。团队研发了一个AI驱动的超高通量药物虚拟筛选平台DrugCLIP。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。

这年头,AI 创造的视觉世界真是炫酷至极。但真要跟细节较真儿,这些大模型的「眼力见儿」可就让人难绷了。