# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
从英伟达的产品路线来看,在未来1-2 年,AI 芯片市场将再次天翻地覆。
作为人工智能领域的领军企业,英伟达有着强大的技术实力和广泛的应用场景,在过去一年中,生成式 AI 的需求爆发为其带来了巨大的增长机遇。
根据富国银行的统计,英伟达目前在数据中心AI市场拥有98%的市场份额,而AMD仅有1.2%的市场份额,英特尔则只有不到1%。
由于英伟达的AI芯片价格高昂,且存在着供应不足的问题,这也迫使一些客户希望选择其他的替代产品。在竞争对手林立的同时,英伟达也正不断推动产品研发和加快更新迭代速度。
近日,servethehome披露了英伟达的数据中心产品路线图,展示了英伟达面向人工智能市场的产品规划,将推出H200、B100和 X100 等多款GPU。

英伟达正计划增加面向数据中心市场的产品种类,推出多款面向AI计算和HPC的产品,让不同的客户可以有针对性购买产品,降低购买芯片难度。通过架构图可以看到,未来英伟达将会对基于Arm 架构的产品和基于x86架构的产品分开。
H200:2024 年第二季度开始供货
2023年11 月 13 日,英伟达宣布推出 NVIDIA HGX H200,为全球领先的 AI 计算平台带来强大动力。该平台基于 NVIDIA Hoppe 架构,配备 NVIDIA H200 Tensor Core GPU 和高级内存,可处理生成 AI 和高性能计算工作负载的海量数据。H200 将于 2024 年第二季度开始向全球系统制造商和云服务提供商供货。
NVIDIA H200 是首款提供 HBM3e 的 GPU,HBM3e 具有更快、更大的内存,可加速生成式 AI 和大型语言模型,同时推进 HPC 工作负载的科学计算。借助 HBM3e,NVIDIA H200 以每秒 4.8 TB 的速度提供 141GB 内存,与前身 NVIDIA A100 相比,容量几乎翻倍,带宽增加 2.4 倍。
英伟达表示,H200 可以部署在各种类型的数据中心中,包括本地、云、混合云和边缘。
L40S:2023年秋季推出
L40S是英伟达最强大的GPU之一,其在2023年推出,其旨在处理下一代数据中心工作负载:生成式AI、大型语言模型(LLM)推理和训练,3D图形渲染、科学模拟等场景。
与前一代GPU(如A100和H100)相比,L40S在推理性能上提高了高达5倍,在实时光线追踪(RT)性能上提高了2倍。内存方面,它配备48GB的GDDR6内存,还加入了对ECC的支持,在高性能计算环境中维护数据完整性还是很重要的。
L40S配备超过18,000个CUDA核心,这些并行处理器是处理复杂计算任务的关键。L40S更注重可视化方面的编解码能力,而H100则更专注于解码。尽管H100的速度更快,但价格也更高。
GH200/GH200NVL:2024年第二季度投产
2023年8月,英伟达宣布推出新一代GH200 Grace Hopper超级芯片,新芯片将于2024年第二季投产。
NVIDIA GH200,结合了H200 GPU和Grace CPU,将Hopper架构GPU和Arm架构Grace CPU结合,使用了NVLink-C2C将两者连接起来。每个Grace Hopper Superchip包含了624GB的内存,其中有144GB的HBM3e和480GB的LPDDR5x内存。
GH200和GH200NVL将使用基于Arm 的 CPU 和 Hopper 解决大型语言模型的训练和推理问题。GH200NVL采用了NVL技术,具有更好的数据传输速度。
此外,“B”系列GPU也有望在2024年下半年推出,替代之前的第九代GPU Hopper。
B100、B40、GB200、GB200NVL也将在2024推出
英伟达计划推出用基于x86架构的B100接替H200,计划用基于ARM架构的推理芯片GB200替代 GH200。此外,英伟达也规划了B40产品来替代L40S,以提供更好的面向企业客户的AI推理解决方案。
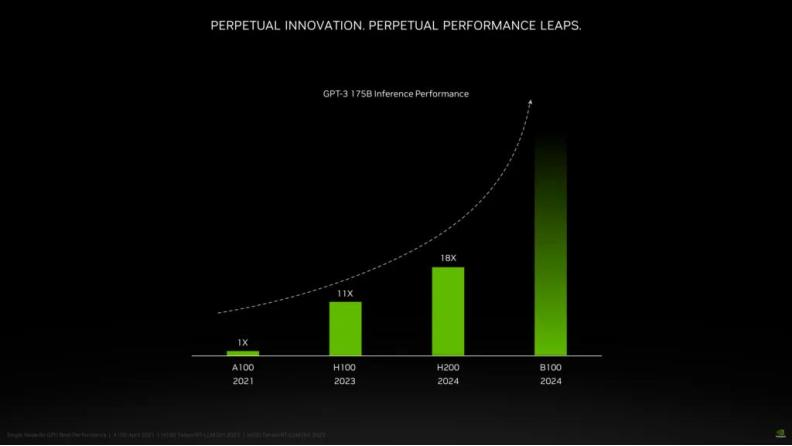
根据英伟达公布的信息,该公司计划于 2024 年发布 Blackwell 架构,而采用该架构的 B100 GPU 芯片预计将大幅提高处理能力,初步评估数据表明,与现有采用 Hopper 架构的 H200 系列相比,性能提升超过 100%。这些性能提升在 AI 相关任务中尤为明显,B100 在 GPT-3 175B 推理性能基准测试中的熟练程度就证明了这一点。
X100计划2025 年发布
英伟达还披露了 X100 芯片的计划,计划于 2025 年发布,该芯片将扩大产品范围,包括企业用途的 X40 和 GX200,在 Superchip 配置中结合 CPU 和 GPU 功能。同样,GB200预计将效仿B100,融入超级芯片概念。
从英伟达的产品路线来看,在未来1-2 年,AI 芯片市场将再次天翻地覆。
在英伟达占据绝对地位的AI芯片领域中,AMD是为数不多具备可训练和部署AI的高端GPU公司之一,业界将其定位为生成式AI和大规模AI系统的可靠替代者。AMD与英伟达展开竞争的战略之一,就包括功能强大的MI300系列加速芯片。当前,AMD 正在通过更强大的 GPU、以及创新的CPU+GPU平台直接挑战英伟达H100的主导地位。
AMD最新发布的MI300目前包括两大系列,MI300X系列是一款大型GPU,拥有领先的生成式AI所需的内存带宽、大语言模型所需的训练和推理性能;MI300A系列集成CPU+GPU,基于最新的CDNA 3架构和Zen 4 CPU,可以为HPC和AI工作负载提供突破性能。毫无疑问,MI300不仅仅是新一代AI加速芯片,也是AMD对下一代高性能计算的愿景。
MI300X 加速卡已在2023年推出
AMD MI300X 拥有最多 8 个 XCD 核心,304 组 CU 单元,8 组 HBM3 核心,内存容量最大可达 192GB,相当于英伟达H100(80GB)的2.4 倍,同时HBM内存带宽高达5.3TB/s,Infinity Fabric总线带宽896GB/s。拥有大量板载内存的优点是,只需更少的GPU 来运行内存中的大模型,省去跨越更多GPU的功耗和硬件成本。
2023年12 月,AMD 在推出旗舰 MI300X 加速卡之外,还宣布 Instinct MI300A APU 已进入量产阶段,预估2024年开始交付,上市后有望成为世界上最快的 HPC 解决方案。
MI300A:预估2024年开始交付
MI300A 是全球首款适用于HPC和AI的数据中心APU,结合了CDNA 3 GPU内核、最新的基于AMD“Zen 4” x86的CPU内核以及128GB HBM3 内存,通过3D封装和第四代AMD Infinity架构,可提供HPC和AI工作负载所需的性能。与上一代 AMD Instinct MI250X5 相比,运行HPC和AI工作负载,FP32每瓦性能为1.9 倍。
能源效率对于HPC和AI领域至关重要,因为这些应用中充斥着数据和资源极其密集的工作负载。MI300A APU将CPU和GPU核心集成在一个封装中,可提供高效的平台,同时还可提供加速最新的AI模型所需的训练性能。在AMD内部,能源效率的创新目标定位为30×25,即2020-2025年,将服务器处理器和AI加速器的能效提高30倍。
综合来看,全球AI热潮在2023年开始爆发,2024年将继续成为业界的焦点。与2023年不同的是,过去在AI HPC领域占据主导地位的英伟达,今年将面临AMD MI300系列产品的挑战。
由于微软、Meta等云端服务大厂在一两年前就开始陆续预订英伟达的MI300系列产品,并要求ODM厂商开始设计专用的AI服务器,使用MI300系列产品线,以分散风险和降低成本。业界预计,今年AMD的MI300系列芯片市场需求至少达到40万颗,如果台积电提供更多的产能支持,甚至有机会达到60万颗。
AMD的CEO苏姿丰在圣何塞举办的AMD Advancing AI活动上谈到,包括GPU、FPGA等在内的数据中心加速芯片,未来四年每年将以50%以上的速度增长,从2023年的300亿市场规模,到2027年将超过1500亿。她表示,从业多年,这种创新速度比她以往见到的任何技术都快。
根据富国银行的预测,AMD虽然在2023年的AI芯片的营收仅为4.61亿美元,但是2024年将有望增长到21亿美元,将有望拿到4.2%的市场份额。英特尔也可能拿到将近2%的市场份额。这将导致英伟达的市场份额可能将小幅下滑到94%。
不过,根据苏姿丰在1月30日的电话会议上公布的数据显示,AMD在2023年四季度的AI芯片营收已经超越此前预测的4亿美元,同时2024年AMD的AI芯片营收预计也将达到35亿美元,高于先前预测的20亿美元。如果,AMD的预测数据准确的话,那么其2024年在AI芯片市场的份额有望进一步提高。
当然,英伟达也并不会放任其在AI市场的垄断地位受到侵蚀。在目前的人工智能智能加速芯片市场,英伟达的A100/H100系列AI GPU虽然价格高昂,但一直是市场的首选。今年英伟达更为强大的Hopper H200和Blackwell B100也将会上市。而根据一些研究机构的预测,英伟达计划今年销售约 150 万至 200 万个 AI GPU,这可能将是其2023年销量的三倍,这也意味着英伟达将会彻底解决供应的瓶颈问题,面对AMD和英特尔的竞争,届时英伟达的价格策略可能也会有所调整。
英伟达要面对的不仅仅是AMD,如今自研AI芯片的风潮正在科技巨头之间兴起。
今年2月,科技巨头Meta Platforms对外证实,该公司计划今年在其数据中心部署最新的自研定制芯片,并将与其他GPU芯片协调工作,旨在支持其 AI 大模型发展。
研究机构SemiAnalysis创始人Dylan Patel表示,考虑到Meta的运营规模,一旦大规模成功部署自研芯片,有望将每年节省数亿美元能源成本,以及数十亿美元芯片采购成本。
OpenAI也开始寻求数十亿美元的资金来建设人工智能芯片工厂网络。
外媒报道,OpenAI正在探索制造自己的人工智能芯片。并且Open AI的网站开始招募硬件相关的人才,官方网站上有数个软硬件协同设计的职位在招聘,同时在去年九月OpenAI还招募了人工智能编译器领域的著名牛人Andrew Tulloch加入,这似乎也在印证OpenAI自研芯片方面的投入。
不止是Meta和OpenAI,据The Information统计,截至目前,全球有超过18家用于 AI 大模型训练和推理的芯片设计初创公司,包括Cerebras、Graphcore、壁仞科技、摩尔线程、d-Matrix等,融资总额已超过60亿美元,企业整体估值共计超过250亿美元(约合1792.95亿元人民币)。
这些公司背后的投资方包括红杉资本、OpenAI、五源资本、字节跳动等。如果加上微软、英特尔、AMD等科技巨头和芯片龙头的“造芯”行动,对标英伟达的 AI 芯片企业数量最终就将超过20家。
如此来看,尽管英伟达在数据中心、游戏和人工智能加速器等关键增长领域保持着引人注目的技术领导地位,但公司面临越来越多的竞争威胁。2024年英伟达也必然会面临更大的挑战。
文章来自于微信公众号 “半导体产业纵横”(ID:ICViews),作者 “丰宁”




