# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
在大模型内卷的同时,Transformer的地位也接连受到挑战。
近日,RWKV发布了Eagle 7B模型,基于最新的RWKV-v5架构。
Eagle 7B在多语言基准测试中,击败了所有的同级别模型,在单独的英语测试中,也和表现最好的模型基本打平。
同时,Eagle 7B用的是RNN架构,相比于同尺寸的Transformer模型,推理成本降低了10-100倍以上,可以说是世界上最环保的7B模型。
由于RWKV-v5的论文可能要下个月才能发布,这里先奉上RWKV的论文,——也是第一个扩展到数百亿参数的非Transformer架构。

论文地址:https://arxiv.org/pdf/2305.13048.pdf
这篇工作已被EMNLP 2023录用,我们可以看到论文的作者来自不同国家的顶尖高校、研究机构以及科技公司。
下面是Eagle 7B的官图,表示这只老鹰正在飞跃变形金刚。

Eagle 7B使用来自100多种语言的,1.1T(万亿)个Token的训练数据,在下图的多语言基准测试中,Eagle 7B平均成绩位列第一。
基准测试包括xLAMBDA、xStoryCloze、xWinograd和xCopa,涵盖了23种语言,以及各自语言的常识推理。
Eagle 7B拿到了其中三项的第一,尽管有一项没打过Mistral-7B,屈居第二,但对手使用的训练数据要远高于Eagle。
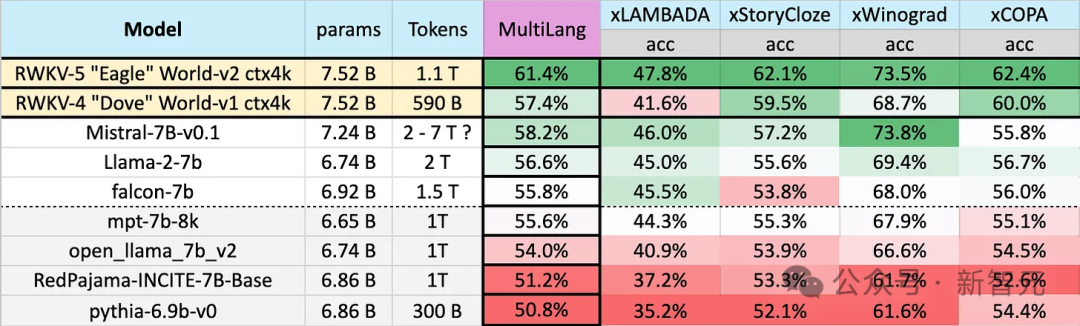
下图的英语测试包含了12个独立的基准、常识推理和世界知识。
在英语性能测试中,Eagle 7B的水平接近Falcon(1.5T)、LLaMA2(2T)、Mistral(>2T),与同样使用了1T左右训练数据的MPT-7B不相上下。

并且,在两种测试中,新的v5架构相比于之前的v4,有了巨大的整体飞跃。
Eagle 7B目前由Linux基金会托管,以Apache 2.0许可证授权,可以不受限制地用于个人或商业用途。
前面说了,Eagle 7B的训练数据来自100多种语言,而上面采用的4项多语言基准测试只包括了23种语言。
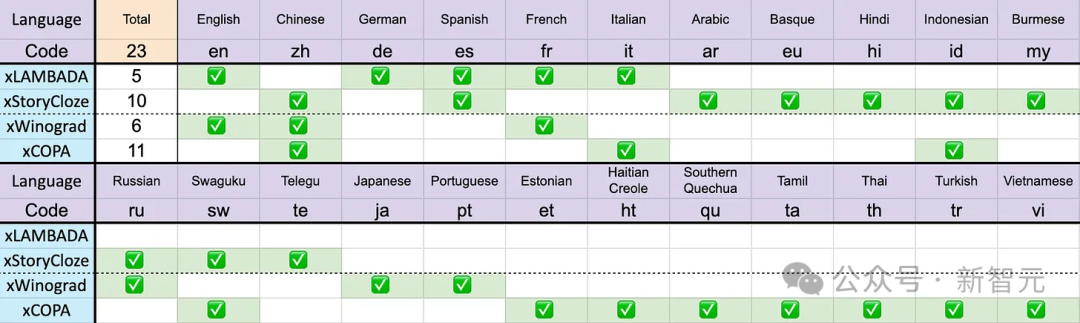
虽然取得了第一名的成绩,但总的来说,Eagle 7B是吃亏的,毕竟,基准测试无法直接评估模型在其他70多种语言中的性能。
额外的训练代价并不能帮助自己刷榜,如果集中在英语,可能会获得比现在更好的成绩。
——那么,RWKV为什么要这么做呢?官方对此表示:
Building inclusive AI for everyone in this world —— not just the English
在对于RWKV模型的众多反馈中,最常见的是:
多语言方法损害了模型的英语评估分数,并减缓了线性Transformer的发展;
让多语言模型与纯英语模型,比较多语言性能是不公平的
官方表示,「在大多数情况下,我们同意这些意见,」
「但我们没有计划改变这一点,因为我们正在为世界构建人工智能——这不仅仅是一个英语世界。」

2023年,世界上只有17%的人口会说英语(大约13亿人),但是,通过支持世界上排名前25位的语言,模型可以覆盖大约40亿人,即世界人口总数的50%。
团队希望未来的人工智能可以为每个人都提供帮助,比如让模型可以在低端硬件上以低廉的价格运行,比如支持更多的语言。
团队将在之后逐渐扩大多语言数据集,以支持更广泛的语言,并慢慢将覆盖范围扩大到世界上100%的地区,——确保没有语言被遗漏。
在模型的训练过程中,有一个值得注意的现象:
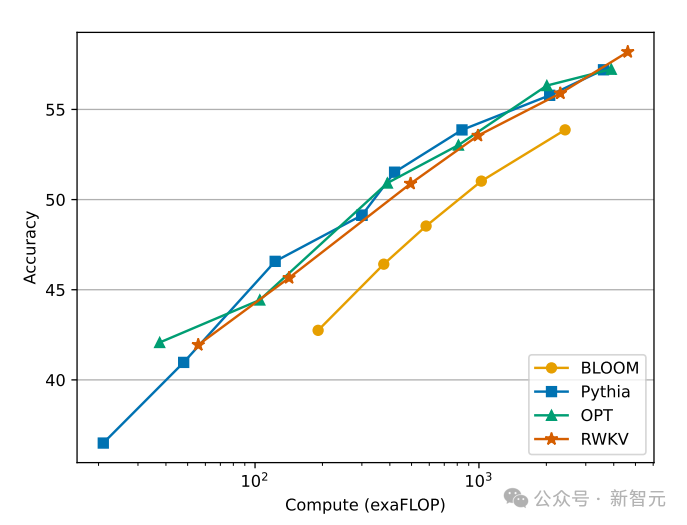
随着训练数据规模不断增加,模型的性能逐渐进步,当训练数据达到300B左右时,模型显示出与pythia-6.9b 相似的性能,而后者的训练数据量为300B。
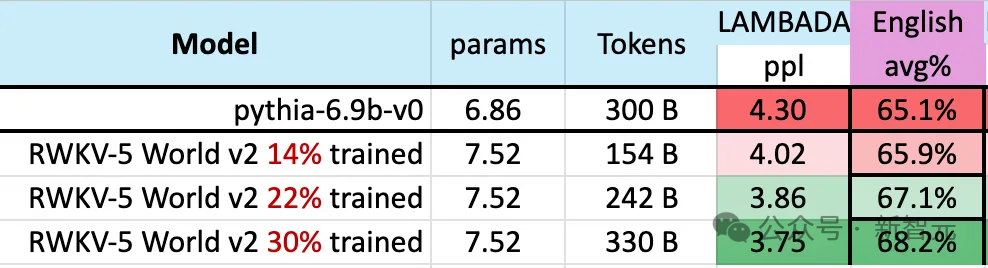
这个现象与之前在RWKV-v4架构上进行的一项实验相同,——也就是说,在训练数据规模相同的情况下,像RWKV这种线性Transformer的性能会和Transformer差不多。
那么我们不禁要问,如果确实如此,那么是不是相比于确切的架构,数据反而对模型的性能提升更加重要?
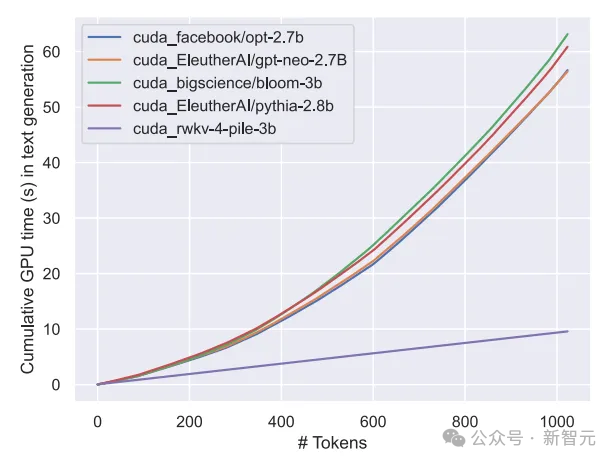
我们知道,Transformer类的模型,计算和存储代价是平方级别的,而在上图中RWKV架构的计算成本只是随着Token数线性增长。
也许我们应该寻求更高效、更可扩展的架构,以提高可访问性,降低每个人的人工智能成本,并减少对环境的影响。
RWKV架构是一种具有GPT级别LLM性能的RNN,同时又可以像Transformer一样并行化训练。
RWKV结合了RNN和Transformer的优点——出色的性能、快速推理、快速训练、节省VRAM、「无限」的上下文长度和免费的句子嵌入,RWKV并不使用注意力机制。
下图展示了RWKV与Transformer派模型在计算成本上的对比:
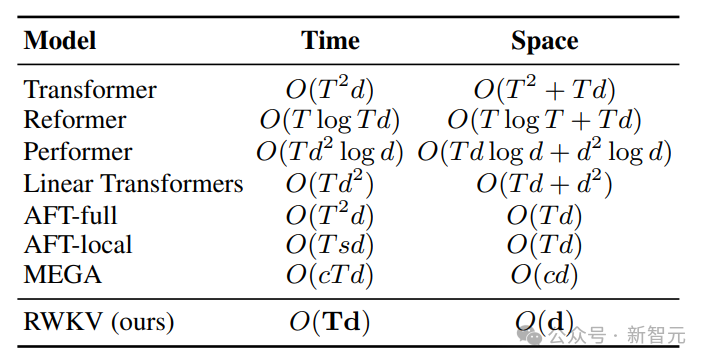
为了解决Transformer的时间和空间复杂度问题,研究人员提出了多种架构:
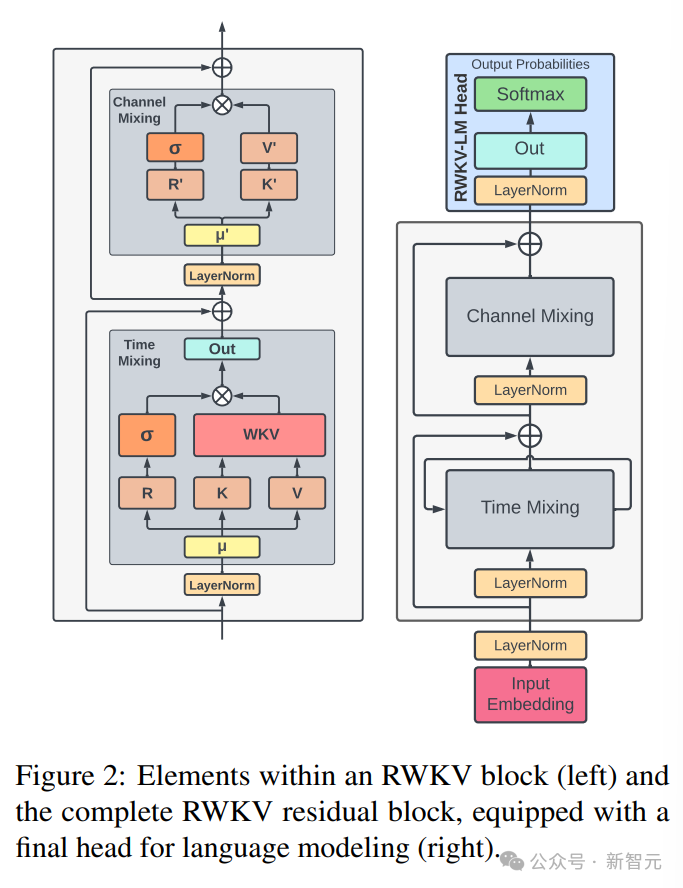
RWKV架构由一系列堆叠的残差块组成,每个残差块由一个具有循环结构的时间混合和一个通道混合子块组成
下图中左边为RWKV块元素,右边为RWKV残差块,以及用于语言建模的最终头部。
递归可以表述为当前输入和前一个时间步的输入之间的线性插值(如下图中的对角线所示),可以针对输入嵌入的每个线性投影独立调整。
这里还引入了一个单独处理当前Token的向量,以补偿潜在的退化。
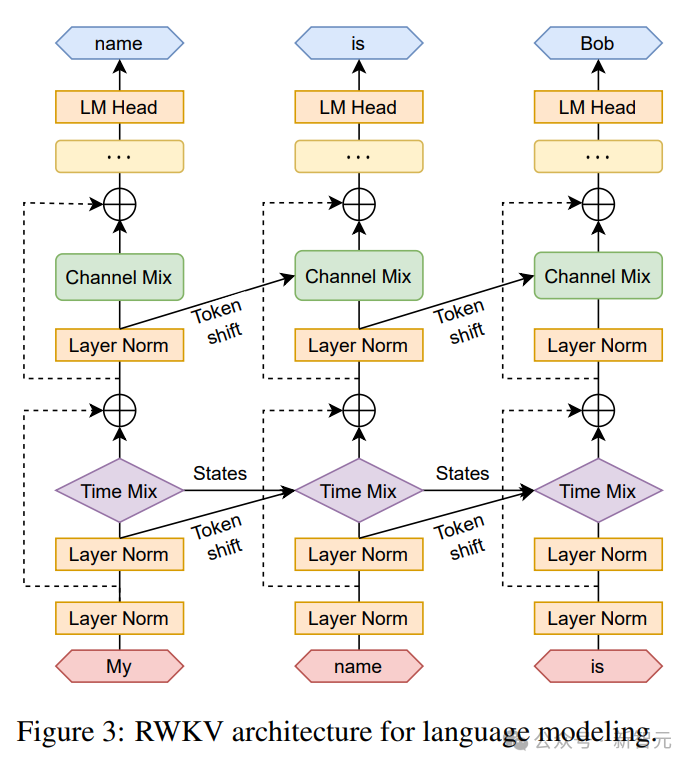
RWKV可以在我们所说的时间并行模式下有效地并行化(矩阵乘法)。
在循环网络中,通常使用前一时刻的输出作为当前时刻的输入。这在语言模型的自回归解码推理中尤为明显,它要求在输入下一步之前计算每个令牌,从而使RWKV能够利用其类似RNN的结构,称为时间顺序模式。
在这种情况下,RWKV可以方便地递归表述,以便在推理过程中进行解码,它利用了每个输出令牌仅依赖于最新状态的优势,状态的大小是恒定的,而与序列长度无关。
然后充当RNN解码器,相对于序列长度产生恒定的速度和内存占用,从而能够更有效地处理较长的序列。
相比之下,自注意力的KV缓存相对于序列长度不断增长,从而导致效率下降,并随着序列的延长而增加内存占用和时间。
参考资料:
https://blog.rwkv.com/p/eagle-7b-soaring-past-transformers
文章来自于微信公众号 “新智元”



【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
